Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Элементы искусственного интеллекта в программах дистанционного обучения
Аннотация:
Abstract:
| Авторы: Красильников И.В. () - , Шумакова О.П. () - , Капустин Ю.И. () - , Бобров Д.А. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 10888 |
Версия для печати Выпуск в формате PDF (1.18Мб) |
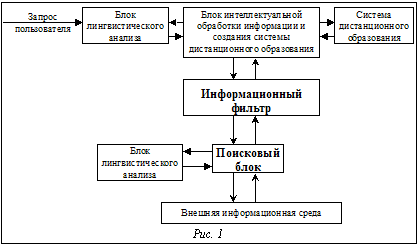
Накопленная информация практически по всем дисциплинам, изучаемым сегодня при помощи дистанционного обучения, достигла колоссальных размеров. Следовательно, специалисты, занимающиеся как разработкой, так и применением систем дистанционного образования, не в состоянии охватить весь объем этой информации, что существенно снижает эффективность программ дистанционного образования. Назрела необходимость применять в системе дистанционного компьютерного обучения программы, основанные на использовании искусственного интеллек- та [1]. Системы искусственного интеллекта могут применятся как при непосредственной разработке программ дистанционного обучения, помогая в разработке структуры информационного наполнения образовательной программы, в поиске, накоплении и анализе необходимой информации (то есть в создании банков методической и педагогической информации). Так как спектр источников информации для подобных систем очень широк (информация поступает непосредственно от разработчика, из различных сетей и баз дан- ных и т.п.), применение для ее обработки систем интеллектуального анализа данных существенно ускоряет разработку систем дистанционного обучения и позволяет сделать их информационную составляющую более адекватной современному уровню знаний [1]. Интеллектуальная составляющая может быть очень полезной и в составе самой программы дистанционного обучения. Система интеллектуального анализа может помочь в создании процедур эффективного контроля процесса обучения. Создав базу данных наиболее часто задаваемых вопросов, можно частично автоматизировать процесс ответов на вопросы учащихся, и в случае необходимости облегчить поиск ответа на нестандартный вопрос (в базах данных и компьютерных сетях), что позволит преподавателю, координирующему процесс обучения, сосредоточиться на более важных методических задачах. В процессе работы с программой эта база данных будет пополняться, то есть будет происходить процесс самообучения системы. Кроме всего, на интеллектуальную составляющую можно возложить все задачи, не связанные непосредственно с процессом обучения (заполнение необходимой доку- ментации – отчетных ведомостей, сертифика- тов и др.). Следует отметить, что частичная автоматизация всего процесса обучения позволит преподавателю уделять больше времени наиболее слабым учащимся. Интеллектуальная составляющая программы может существенно облегчить процесс изменения структуры курса в зависимости от конкретных потребностей и способностей обучаемого и сделать его более гибким. При необходимости позволит создать в максимально короткие сроки учебный курс, наиболее полно отражающий как способности обучаемого, так и возможности преподавателя, не создавая проблем для остальных обучающихся. Как следует из всего вышесказанного, процедуры интеллектуального анализа и искусственного интеллекта одинаково необходимы и в программе, автоматизирующей процесс разработки и создания системы, предназначенной для дистанционного обучения, и в структуре самой системы. По своей структуре и назначению программа разработки систем дистанционного обучения наиболее всего похожа на систему автоматизированного проектирования. Ее задача – создание под руководством разработчика готового учебного курса из имеющихся типовых блоков (электронных учебников, тестов). Так как информационная составляющая программы, предназначенной для обучения конкретному предмету, и совокупность тестовых вопросов к ней идентичны (отличие только в количестве информации для курсов различной степени сложности), работа системы автоматизированного проектирования курсов дистанционного обучения существенно упрощается. Курс дистанционного обучения может быть предназначен как для индивидуального, так и для группового обучения. Доступ к ресурсам курса осуществляется через локальную компьютерную сеть образовательного учреждения или через Internet. Различны способы распределения вычислительных мощностей (рабочий сервер, персональный компьютер обучаемого) и способы контроля за текущей успеваемостью обучаемых. Следовательно, наиболее сложным является не объединение в один учебный курс необходимой информации, а настройка программного обеспечения для конкретной ситуации. Самым рациональным способом в данной ситуации представляется использование модульного принципа программирования. Создав же систему конструирования программ дистанционного обучения в виде САПР, можно не только формировать новые программы из уже имеющихся модулей, но и достаточно быстро модернизировать уже существующие программы. Причем интеллектуальная составляющая САПР позволит сделать этот процесс максимально эффективным [2]. Рассмотрим более подробно интеллектуальную составляющую программ дистанционного образования. Система искусственного интеллекта как САПР в дистанционном образовании Система искусственного интеллекта должна строиться по тому же принципу, что и САПР. То есть она должна иметь возможность построения экспертной или любой другой интеллектуальной системы при помощи набора имеющихся в ее распоряжении алгоритмов, получая и анализируя поступающие извне данные. Исходя из этого система искусственного интеллекта (СИИ) будет иметь структуру, изображенную на рисунке 1. Блок лингвистического анализа (лингвистический процессор) Блок лингвистического анализа предназначен для обработки поступающей извне информации от пользователя и других внешних источников (компьютерных сетей, баз данных, баз знаний, информационных хранилищ) и преобразования ее к виду, пригодному для дальнейшей обработки системой. Информация, которая необходима данной системе, поступает, как правило, на естественном языке (ЕЯ) или ограниченном естественном языке (ОЕЯ). Лингвистическое обеспечение процессора включает словари лексем и грамматических форматов, а так же комплекс алгоритмов семантического и синтаксического анализа и синтеза текстов на ЕЯ [3]. В результате работы алгоритма анализа возникает семантическое представление текста. На схеме два блока лингвистического анализа. Это связанно с тем, что функции, которые выполняют эти блоки, различны. Первый предназначен для обработки пользовательского запроса как в момент формирования системы, так и во время ее работы. Второй обрабатывает информацию, поступающую извне в процессе создания системы и во время ее работы. Информация, которую обрабатывает этот блок, более разнообразна и сложна по своей структуре. Таким образом, оба лингвистических блока используются на этапе создания (проектирования) системы и в процессе ее функционирования. Причем в обоих случаях они выполняют одни и те же функции, что позволяет использовать исходные блоки САПР в формируемой СИИ. Аналогичная ситуация и с другими исходными блоками. Информационный фильтр
В нашем случае сигналом является информация, поступающая от пользователя (разработчика системы), из баз данных, информационных сетей. Шум – это информация исключения, искажающая входной сигнал, избыточная при дальнейшей обработке. Следовательно фильтр можно назвать информационным фильтром (фильтром данных), предназначенным для обработки информации. Так как обработка конкретной символьной информации – очень специфичный процесс, то с целью его упрощения, а также для того, чтобы сделать этот процесс более универсальным, будет целесообразно ввести маркировку информации и дальнейшую интеллектуальную обработку проводить на ее основе. Маркировка – способ описания информации, применяемый для удобства программной реализации интеллектуальной обработки информации. Это строка, состоящая из некоторого набора символов. Первые две позиции в этой строке определяют источник, из которого поступила информация, а вторые две – тип поступившей информации. Следующие позиции позволяют получить некоторую специфическую информацию, необходимую для работы программы. Последние позиции в маркере могут использоваться самой программой для хранения временной рабочей информации, полученной в результате работы отдельных блоков программы и необходимой другим блокам или частям программы. Две последние позиции при необходимости содержат информацию о том, в какой из блоков должна быть направлена для дальнейшего анализа исследуемая величина. Используя правила маркирования информации, мы можем применять разработанные на их основе процедуры интеллектуального анализа данных для любых типов исходной информации. Фильтр состоит из двух основных блоков (рис. 2): информационного фильтра и подготовки и изменения рабочих настроек фильтра.
Информационный фильтр состоит из двух частей: рабочего блока, непосредственно осуществляющего процесс фильтрации информации и кэширование данных, и файла настроек фильтра (ФНФ), в котором содержится описание данных, необходимых для дальнейших расчетов (он формируется блоком подготовки и изменения рабочих настроек фильтра). В рабочем блоке происходит сравнение маркера поступившей информации с маркерами, хранящимися в файле настроек фильтра. В случае совпадения соответствующих позиций маркеры данных, поступивших в рабочий блок фильтра извне, дополняются информацией, хранящейся в маркерах ФНФ. Эта информация указывает на способы дальнейшей обработки данных (если в этом есть необходимость). После проведения анализа маркировки сравниваются соответствующие значения данных, определенных фильтром как необходимые для дальнейшего анализа, с данными, хранящимися в кэше фильтра. Блок подготовки и изменения рабочих настроек фильтра предназначен для формирования ФНФ. Этот блок срабатывает автоматически при первом запуске системы. В дальнейшем запуск блока происходит по инициативе пользователя в случае изменений требований к системе. Блок настроек фильтра производит анализ соответствующих баз данных и баз знаний, а также требований пользователя, вводимых при помощи специальной панели, и формирует ФНФ. Он состоит из трех блоков: анализа маркировки (в нем происходит удаление дублируемой и анализ резервной информации); выбора необходимой информации; анализа дублируемой информации. Блок анализа маркировки: информация поступает в виде списка маркеров, описывающих все виды данных, которые могут поступить в программу. Часто случается так, что эта информация дублирует друг друга. Согласно приоритету, установленному пользователем, происходит удаление дублируемой информации (той, чей приоритет ниже). Затем анализируется резервная информация и идет соответствующая ее обработка. В конце работы данного блока формируется список маркеров, который поступает для обработки во второй блок. Блок выбора необходимой информации. В соответствии с требованиями программе необходимы определенные данные. Эти данные мы можем получить как от самого разработчика, так и из различных указанных им внешних источников. Необходимо установить приоритет между этими источниками. Это означает, что, имея два списка маркеров данных, программа должна произвести выборку информации сначала по одному списку. И только в том случае, если в нем нет необходимой информации, перейти к другому списку. В конце работы блока формируется ФНФ. Блок анализа дублируемой информации осуществляет контроль над ошибками. После формирования файла настроек фильтра он проверяет этот файл на наличие дублируемых записей, появившихся в результате сбоя в работе предыдущих блоков, и, прежде чем стереть их, выдает сообщение об их существовании. В случае отсутствия ошибок этот блок сигнализирует о завершении формирования файла настроек фильтра и инициирует дальнейшее выполнение программы. На основании сказанного можно сделать вывод о том, что рабочий блок фильтра и блок формирования и изменения настроек фильтра являются универсальными. Так как они работают не непосредственно с данными, а с их описаниями, то не зависят от вида поступающей информации и, следовательно, могут применяться в любых системах переработки информации. Необходимые этим блокам базы данных и базы знаний могут легко заменяться, так как реализованы отдельно. Фильтрация информации – процедура интеллектуального анализа данных, необходимая для подготовки информации к дальнейшей обработке. Рабочий блок и блок настроек являются универсальными и могут применяться в любых системах переработки информации. Список литературы 1. Бузук Г.Л. Логика и компьютер. - М.: Финансы и статистика, 1995.- 207с., ил. 2. Брейер М. Автоматизация проектирования вычислительных систем. Языки, моделирование и базы данных. - М.: Мир, 1979. – 461с. 3. Словарь по кибернетике.- К.: Гл. ред. УСЭ им. М.П.Бажана, 1981.- 751 с. |
 Фильтр – устройство, осуществляющее определенное преобразование (фильтрацию) входного сигнала. Фильтры выполняют функции корректирующих устройств и служат для выделения полезного сигнала на фоне помех (шума). Фильтрация информации – процедура интеллектуального анализа данных, необходимая для подготовки информации к дальнейшему анализу [3].
Фильтр – устройство, осуществляющее определенное преобразование (фильтрацию) входного сигнала. Фильтры выполняют функции корректирующих устройств и служат для выделения полезного сигнала на фоне помех (шума). Фильтрация информации – процедура интеллектуального анализа данных, необходимая для подготовки информации к дальнейшему анализу [3].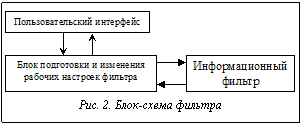 Через первый блок пропускается информация с целью удаления шума. Ко второму блоку для работы необходимо подключить две базы данных: технологический регламент и регламент безопасности для данной установки, а также набор алгоритмов первичной обработки информации (ПОИ).
Через первый блок пропускается информация с целью удаления шума. Ко второму блоку для работы необходимо подключить две базы данных: технологический регламент и регламент безопасности для данной установки, а также набор алгоритмов первичной обработки информации (ПОИ).| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=846 |
Версия для печати Выпуск в формате PDF (1.18Мб) |
| Статья опубликована в выпуске журнала № 3 за 2001 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Знания в интеллектуальных системах
- Общедоступные математические САПР для персональных компьютеров класса IBM PC
- Интеллектуальная поддержка реинжиниринга конфигураций производственных систем
- Расчет нечеткого сбалансированного показателя в задачах взвешивания терминов электронных документов
- Механизм контроля качества программного обеспечения оптико-электронных систем контроля
Назад, к списку статей