Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Извлечение данных как наиболее важное приложение технологии информационных хранилищ
Аннотация:
Abstract:
| Авторы: Вагин В.Н. (vagin@appmat.ru) - Московский энергетический институт (технический университет), г. Москва, Россия, доктор технических наук, Загорянская А.А. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 18036 |
Версия для печати Выпуск в формате PDF (1.43Мб) |
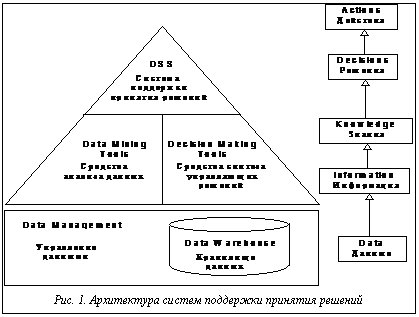
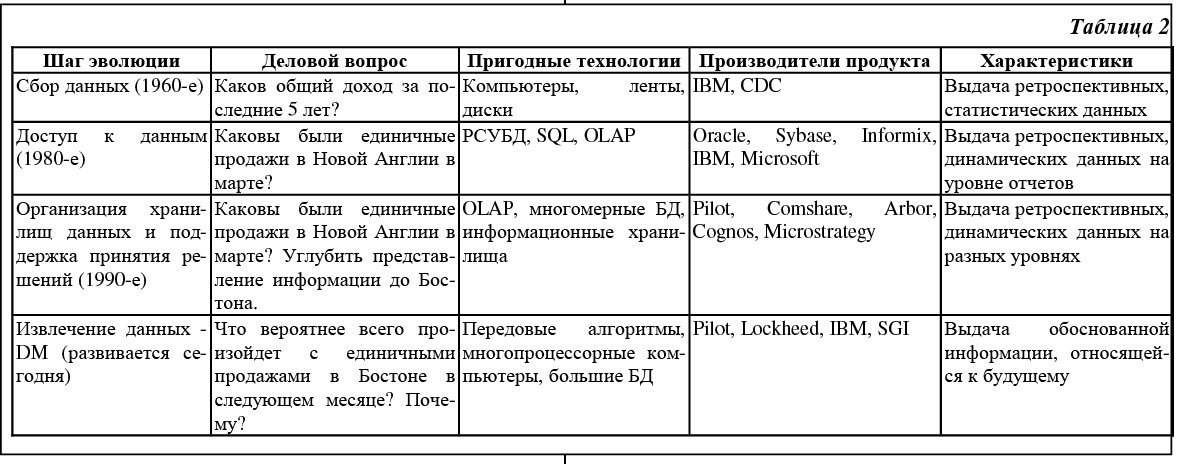
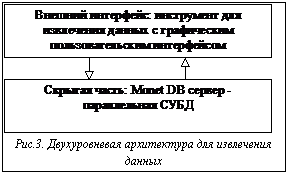
Специалисты в области информационных технологий решают проблемы создания систем поддержки принятия решений (СППР, систем ППР) уже около 20 лет. Так, в начале 80-х гг эти проблемы решались с помощью информационного центра. При этом сотрудники информационного центра занимались подготовкой для ЭВМ копий данных организации в соответствии с фиксированным форматом и запуском специализированных программ, формирующих отчеты по запросам конечных пользователей. Этот метод был достаточно успешным и применялся до тех пор, пока не появились реляционные СУБД (РСУБД) и их навигационный язык - структурированный язык запросов SQL. С помощью РСУБД очень легко обрабатывать запросы, а SQL позволяет пользователю напрямую обращаться к БД и получать необходимую информацию тогда, когда это требуется. Теперь нет необходимости договариваться с информационным центром о том, какие данные можно было бы получить и какой протокол экспорта возможно использовать. Недостатком данного подхода является требование хорошей подготовки пользователя, так как для выполнения неудачно сформулированного запроса могут потребоваться многие часы машинного времени. Чтобы удовлетворить непрерывно растущие потребности в информации, усиливается инвестирование в область создания БД, отделенных от оперативных БД производства, для выполнения запросов, требующих аналитической обработки больших массивов данных. Понятие отдельной БД для поддержки работы инженера по знаниям было новым и получило название «информационного хранилища» (по терминологии IBM) или «хранилища данных» (терминология W.H. Inmon [1]). Хранилище данных - это ориентированное на предметную область, интегрированное, устойчивое собрание данных для процесса поддержки принятия решений. На основе хранилища может быть легко получен репозиторий непротиворечивых исторических данных, пригодный для поддержки принятия решений. Как правило, жизненный цикл технологии составляет примерно 9 лет и включает 3 основные стадии [2]: нововведение, развертывание и завершенность. На протяжении первых трех лет - фазы нововведения - потребителями новой технологии становятся лишь немногие энтузиасты и сторонники. Для технологии хранилищ данных эта фаза началась с публикации в 1991 г. книги Билла Инмона «Построение хранилища данных» [1]. Он создал теоретический фундамент для хранилищ данных, определив их характеристики и подходы к построению. Сегодня технология хранилищ данных переживает фазу развертывания и подходит к началу третьей фазы развития, когда технология становится общепризнанной. Основная проблема при переходе к третьей фазе состоит в дороговизне проектов хранилищ. Так, обзор консалтинговой компании META Group за 1998 г. показал, что, в среднем, для поддержки хранилищ данных требуется около 1.8 млн. долл. на технические средства и около 1.4 млн. долл. на программные средства. Если ситуация не изменится, то большой сегмент рынка останется неохваченным и технология хранилищ данных никогда не достигнет третьей фазы развития. Возможно, выход будет найден. Например, специалисты из исследовательской компании Gartner Group утверждают, что «Наибольшая выгода от использования технологии хранилищ данных достигается тогда, когда Вы можете поддерживать 20 различных приложений ППР на одной и той же архитектуре». Некоторые эксперты утверждают [3], что извлечение данных (data mining, DM) - наиболее важное приложение технологии информационных хранилищ. Извлечение данных предполагает выявление скрытой предсказывающей информации из больших БД [4]. В своем отчете [5] специалисты из Gartner Group относят DM к 5 передовым технологиям, которые будут оказывать существенное влияние на широкий спектр областей промышленности в течение ближайших 3 - 5 лет. В свою очередь, META Group предсказывает рост дохода от внедрения новых инструментов DM от 3.3 билл. долл. в 1996 году до 8.4 билл. долл. в 2000 году. В настоящем обзоре, посвященном извлечению данных, рассматриваются как вопросы, касающиеся самой технологии DM (архитектура СППР, алгоритмы DM, основные направления исследований), так и связи ее с другими технологиями (OLAP). Так как технологии DM и хранилищ данных являются передовыми и бурно развивающимися, то на сегодняшний день еще не определена устоявшаяся терминология. Более того, продолжаются споры исследователей о связи DM и СППР, DM и OLAP [6]. Поэтому, не претендуя на полноту изложения, попытаемся нарисовать общую картину, сложившуюся в области DM, используя последние данные зарубежных исследований. Технологические критерии Так как DM работает с данными из хранилища, рассмотрим сначала технологические критерии, которые необходимо учитывать при разработке системы хранилища данных. Они включают следующие [7]: 1. Масштабируемость - это способность системы увеличивать производительность при росте требований пользователя, наращивать объем хранимых данных при увеличении количества пользователей системы и приложений, использующих хранилище. 2. 3. Исполнение. От того, насколько хорошо будет реализована система, главным образом, зависит успех проекта. Существует несколько областей, накладывающих непосредственный отпечаток на представление системы: архитектура технических средств и базы данных. Технические средства предполагают использование архитектур симметричной мультиобработки (SMP) и массово-параллельной обработки (MPP). Тем не менее, существует много приложений, которые могут удовлетворительно работать на непараллельных системах. Некоторые разработчики баз данных решили поддержать архитектуру технических средств, введя параллелизм в функции БД. 4. Гибкость. Технология хранилищ данных должна быть гибкой, чтобы своевременно реагировать на изменяющиеся условия. 5. Соотношение ‘простота - скорость’ для реализации. Средства развития и поддержки, используемые вместе с хранилищами данных, являются ключом к успеху проекта. Хорошо ли интегрированы эти средства, или группе сопровождения придется бороться с их несовместимостью? Являются ли интерфейсы пользователя графическими или командными? Генерируется ли автоматически состав метаданных? Эти вопросы касаются не только исходной разработки, но и последующего сопровождения системы. 6. Интеграция инструментов предполагает хорошее и бесперебойное взаимодействие различных архитектурных компонентов. Как утверждается в журнале Datamation, «иметь хорошо и глубоко интегрированные друг с другом инструментальные средства - это необходимость, а не роскошь». 7. Полнота решения говорит о наличии всех архитектурных компонентов. Это означает, что все элементы архитектуры, необходимые для работы, реализованы и функционируют: извлечение, преобразование и хранение данных; метаданные, определяющие основные данные; требуемые аналитические и управляющие процессы. Архитектура систем ППР Основу систем ППР составляют средства для быстрого и надежного анализа и визуализации деловой информации, а также набор инструментов, необходимых для синтеза информации с целью получения новых знаний об управляемой системе и выработки управляющих решений. Системы ППР состоят их следующих архитектурных элементов (Рис. 1): · хранилище информации (массив данных и знаний); · средства управления данными (накопление, хранение, оперирование, защита и т.д.); · средства анализа (извлечения) данных - Data mining (аналитическая обработка данных); · средства синтеза управляющих решений (моделирование, прогнозирование, оптимизация, анализ альтернатив и т.д.). Базовый набор инструментов систем ППР обычно включает в себя широкий ассортимент Так как организация хранилища данных очень важна как для успешной реализации всей СППР в целом, так и для проведения анализа данных, то рассмотрим более подробно архитектуру хранилища. По утверждению Билла Инмона [8], существует два наиболее общих типа информационных хранилищ: текущее хранилище с подробными данными и витрина (datamart). В текущем хранилище собираются разрозненные атомарные данные, и оно имеет очень большой объем. Для витрины характерно хранение специальных данных, необходимых для решения конкретных задач (например, одного департамента). В [9] отмечается, что для большинства проектов разработка многоуровневого хранилища уже стала общепризнанным архитектурным решением. Многоуровневость - это архитектурное решение проблемы контроля стоимости управления хранилищем в условиях неустойчивого информационного окружения. Базовая структура хранилища (Рис. 2) включает три составляющие: 1. Система записи (слой-источник) - это исходная система, из которой извлекаются ряды данных для хранилища. Обычно эти источники либо вертикальные интегрированные OLTP-системы, либо данные третьей стороны. 2. Базовый слой хранилища - это общий фонд данных, содержащий интегрированные и рационализированные данные из системы записи. Данные здесь хранятся в соответствии с семантикой и представляются в исторической последовательности. 3. Слой доступа к хранилищу - это слой выдачи данных, где система хранилища встречается с пользователями и их ППР-приложениями. Структуры данных могут варьироваться от стратегических данных для очень устойчивых предметных областей (домен схем типа ‘звезда’) до многомерных БД, определяемых спецификой проекта. Основные свойства уровня - понятность для делового пользователя и легкость доступа. Как утверждается в [5], существует все увеличивающаяся пропасть между мощными системами хранения данных и способностью пользователей эффективно анализировать и воздействовать на информацию, которую они содержат. Требуется новый технологический скачок для структурирования и упорядочения информации в соответствии со специфическими задачами пользователя. Для этого и предназначены инструменты DM, которые наиболее эффективны при наличии интеграции с существующими информационными системами. К сожалению, сегодня многие инструменты DM действуют вне информационных хранилищ, требуя выполнения дополнительных шагов извлечения, импорта и анализа данных. В [5] предлагается интегрированная архитектура для анализа данных из хранилища. Она связывает на основе тесного взаимодействия хранилище, OLAP-сервер и систему DM. Такая архитектура сильно отличается от традиционных СППР. Вместо того, чтобы просто направлять данные к конечному пользователю через программы подготовки отчетов и запросов, модели применяются непосредственно к данным хранилища и возвращаются результаты анализа наиболее подходящей информации. Эти результаты позволяют улучшить метаданные в OLAP-сервере, создавая слой динамических метаданных. Отчеты и визуализация оказываются полезными при планировании будущих действий. Извлечение данных: определения, назначение По существу, процесс извлечения (анализа) данных является частью более общего процесса, называемого принятием решений, и в силу этого служит для трансформации данных, хранимых в информационных хранилищах или витринах, в информацию, помогающую принять правильное решение. DM получило свое название благодаря сходству поиска значимой информации в больших БД и добычи в горе жилы ценной руды [5]. Оба процесса требуют либо ‘просеивания’ огромного количества материала, либо ‘зондирования’ для определения точного местоположения искомого объекта. Приведем несколько определений процесса извлечения данных. Традиционно цель определения и использования информации, скрытой в данных, достигалась с помощью генераторов запросов и систем, интерпретирующих данные. В этом случае необходимо было сформулировать предположение о возможном отношении в БД и перевести эту гипотезу в запрос. Данный подход к анализу данных являлся ручным, управляемым пользователем, нисходящим. В процессе DM запрос выполняется самим алгоритмом, а не пользователем, то есть извлечение данных - это управляемый данными, самоорганизующийся, восходящий подход к анализу [10]. Более развернутое определение можно найти в [11]: «В ходе извлечения данных осуществляется попытка сформулировать, проанализировать и выполнить основные процессы индукции, упрощающие извлечение содержательной информации и знаний из неструктурированных данных». DM полуавтоматически извлекает образцы, изменения, ассоциации и аномалии из больших массивов данных. Таким образом, DM пытается извлечь знания из данных. Заметим, что под большими массивами данных понимаются такие множества, которые слишком велики, чтобы находиться в памяти одной рабочей станции. По сути, DM обнаруживает образцы и связи, скрытые в данных. DM - часть процесса обнаружения знаний, которая состоит в применении к данным методов статистического анализа и моделирования, чтобы найти полезные образцы и связи. Процесс обнаружения знаний описывает шаги, которые необходимо предпринять, чтобы получить результаты, имеющие смысл. Средства извлечения данных используют данные для построения модели реального мира. В результате моделирования создается описание образцов и связей данных. Пользователь может использовать эти модели двумя способами: 1) описание образцов и связей в БД может предоставлять знания, направляющие действия пользователя (ассоциативные модели); 2) образцы могут быть использованы для предсказаний. Извлечение данных применяется для построения моделей шести типов [3]: 1) классификация; 2) регрессия; 3) временные ряды; 4) кластеризация; 5) анализ ассоциаций; 6) обнаружение закономерностей. При этом модели типов 1, 2 и 3 применяются прежде всего для предсказания, модель 4 используется как для прогнозов, так и для описания, а модели 5 и 6 - прежде всего для описания поведения, определяемого данными БД. Приведем краткое описание этих моделей в соответствии с [3]. Классификация назначает примеры (типы) группе или классу. Существующие типы, используемые для поиска классификационного образца, могут находиться в исторической БД. Они также могут быть получены в ходе эксперимента, в котором часть исходной БД тестировалась в реальном мире, и результаты используются для создания классификационного множества данных, по которому может быть разработана модель. Регрессия использует ряды существующих значений и их атрибуты для предсказания последующих значений. Предсказание временных рядов, подобно регрессии, использует ряды существующих значений и их атрибутов для предсказания будущих значений. Отличие же состоит в том, что эти значения зависят от времени. Инструменты могут использовать различные свойства времени, особенно иерархию периодов, сезонность, календарные эффекты, арифметику дат, специальные соглашения вроде того, какой период прошлого влияет на будущее. Кластеризация разбивает БД на различные группы. В отличие от классификации, заранее не известны кластеры, с которых начнется процесс, или вокруг каких атрибутов будут собираться данные. Следовательно, аналитику необходимо интерпретировать смысл кластеров. Ассоциации - объекты, появляющиеся одновременно в данном событии или записи. Инструменты ассоциаций и упорядочения обнаруживают правила вида: «Если объект А - часть события, то в x процентах случаев объект B - часть этого события». Обнаружение закономерностей тесно связано с анализом ассоциаций за исключением того, что связанные объекты имеют протяженность во времени. Чтобы обнаруживать эти последовательности, должны учитываться детали каждой транзакции наряду с идентификацией участников транзакций. Средства и методы извлечения данных С появлением информационных хранилищ анализ данных потребовал систематического подхода. По мнению Gartner Group, извлечение данных не есть некий аналитический метод, а скорее процесс, вбирающий в себя много методов и приемов, подобранных под специфику прикладной области. Как отмечается в [12], из-за сложности и разнообразия данных, находящихся в разработанных хранилищах, единственный метод извлечения данных недостаточен для решения каждой задачи, даже связанной с построением одной конкретной модели. Поэтому приходится комбинировать несколько методов анализа. Алгоритмы и методы DM включают [5, 13, 14]: нейронные сети, деревья решений (алгоритмы CART - классификационные и регрессионные деревья, и CHAID - автоматическое c2-выявление взаимосвязей), индукция правил (извлечение полезных ‘если - то’ правил из данных, основанное на статистической значимости), генетические алгоритмы, метод ближайшего соседа (классифицирует каждую запись из множества данных по основным комбинациям классов из k-записей исторической БД, наиболее похожих на нее), кластеризация, регрессия (линейная и логистическая), анализ временных рядов, обнаружение ассоциаций, сегментация БД. Кроме того, активно используются алгоритмы визуализации как самостоятельно, так и для улучшения результатов, полученных с помощью других алгоритмов.
Для любой конкретной задачи природа самих данных влияет на выбор метода анализа. Поясним это на примере решения задач классификации и кластеризации [3, 10]. Для этих задач широко используются как нейронные сети, так и символьные классификаторы, известные также как программы индукции правил или деревьев решений. Оба метода автоматически исследуют данные для поиска кластеров или образцов. Оба разбивают множество данных на значимые группы или классы. Различные по построению, оба типа основываются на индуктивной теории (обучение на примерах) и выполняют сходную работу над БД. Они разбивают или классифицируют независимые переменные по отношению к зависимым переменным или требуемому результату. Эти инструменты основываются на понятии, известном как управляемое обучение. Но в то же время можно заметить существенные различия в применении методов. Нейронные сети требуют большого количества экспериментов и проверок, таких как установка верного числа узлов, критерия останова, обучающей выборки, импульсных коэффициентов и скрытых весов. Однако с помощью использования генетических алгоритмов для оптимизации этих установок можно повысить точность выходных данных для нейронных сетей. Другое ограничение, касающееся нейронных сетей, состоит в том, что они работают только с числами или бинарными данными. Часто требуется, чтобы данные были нормализованы и промасштабированы, включая предварительные преобразования. Результаты представляются в виде формул или массива весов. Существует еще ряд аргументов против использования нейронных сетей, например, их непрозрачность (факторы, приводящие к результирующему предсказанию, не являются очевидными) и потеря точности выходных данных. Символьные классификаторы из области алгоритмов машинного обучения и статистические алгоритмы CHAID и CART предлагают более подходящее средство для DM, когда требуется объяснение смысла образцов. Деревья решений представляют правила, определяющие класс или значение. Такие деревья очень популярны благодаря разумной точности и понятности. Они строятся быстрее, чем нейронные сети. Но существуют и недостатки, например, стандартные алгоритмы для деревьев решений не могут обнаруживать правила, основанные на сочетаниях переменных. В ходе международных четырехлетних экспериментальных исследований (StatLog) по сравнительному тестированию статистических алгоритмов и алгоритмов машинного обучения на масштабных приложениях для классификации, предсказания и управления был выполнен сравнительный анализ ряда классификационных систем, включая статистику, нейронные сети и символьные классификаторы, на 12 больших реальных множествах данных из областей распознавания образов, медицины, инженерии и финансов. Было обнаружено, что не существует наилучшего метода для классификации или предсказания, и исследователи пришли к заключению: точность любого метода извлечения данных, будь то нейронные сети, регрессионная статистика или символьные классификаторы, сильно зависит от структуры анализируемого множества данных. Обнаружено, что символьные классификаторы превосходят по точности нейронные сети на непараметризованных множествах данных и базах данных, содержащих большое количество нечисловых полей данных типа: Женат - да / нет Уровень потребления - низкий / средний / высокий Номер по каталогу - 8M79Y. Помимо основных, существуют еще алгоритмы и методы, являющиеся вспомогательными для извлечения данных. Чтобы лучше представить диапазон таких алгоритмов, приведем результаты последних достижений исследований по материалам трех конференций, посвященных извлечению данных [11] (информация сгруппирована по областям и методам, связанным с извлечением данных): Согласованное обучение. Вместо того, чтобы использовать DM для построения единственной предсказывающей модели, часто лучше построить набор или ансамбль моделей и комбинировать их, скажем, по эффективности стратегии голосования. Эта простая идея применяется в настоящее время в широком спектре контекстов и приложений. Известно, что при некоторых условиях этот метод позволяет сократить разброс в предсказаниях и, следовательно, уменьшить общую ошибку модели. Линейная алгебра. Масштабирование (scaling) алгоритмов извлечения данных часто критически зависит от масштабирования лежащих в основе вычислений линейной алгебры. Последние работы в области параллельных алгоритмов для решения линейных систем и алгоритмов для решения разреженных линейных систем большого порядка важны для ряда приложений DM: от извлечения текстов до определения незаконного доступа в сеть. Широкомасштабная оптимизация. Некоторые алгоритмы извлечения данных могут быть представлены как широкомасштабные, часто невыпуклые, задачи оптимизации. Разработаны параллельные и распределенные методы для задач непрерывной и дискретной оптимизации, включая методы эвристического поиска. Эффективные вычисления и взаимодействия. Извлечение данных требует статистически интенсивных операций над большими множествами данных. Эти типы вычислений не могут быть практически осуществлены без появления мощных SMP-рабочих станций и высокопроизводительных кластеров рабочих станций. Кроме того, распределенное извлечение данных требует перемещения огромных объемов информации между географически удаленными точками, что возможно благодаря развитию сетей. Базы данных, информационные хранилища и цифровые библиотеки. Наиболее длительной по времени частью процесса извлечения данных является их подготовка. Время выполнения этого шага может быть частично линейным по отношению к объему данных, если они находятся в БД, хранилище или цифровой библиотеке, тогда как извлечение данных из различных БД представляет собой сложную задачу. Некоторые алгоритмы, например, ассоциативные, жестко связаны с БД. В то же время существуют примитивные операции, которые при встраивании в хранилище делают реальным выполнение ряда приложений DM. Визуализация массивных множеств данных. Визуализация - это метод для исследования тенденций (трендов) в БД, дополняемый обычно навигацией массивов данных, и визуально ориентированный на данные, чтобы обнаружить скрытые зависимости. Методы визуализации используют абстрактное представление в интерактивных, 3-D, виртуальных средах, чтобы отобразить большие объемы данных. Системы визуализации приспособлены для поддержки приложений реального времени, так как значения параметров могут быть отображены как движущееся или имитационное измерение данных. Последние достижения в многомерной визуализации позволяют выполнять ее параллельно, и, следовательно, делают практически выполнимыми задачи визуализации. В заключение отметим, что сегодня для пользователя процесс выполнения DM включает 5 шагов [15]: 1. Выбрать и подготовить данные для анализа. 2. Квалифицировать данные с помощью кластерного анализа или анализа характеристик. Кластеризация и сегментация данных предназначена для снижения их сложности, чтобы облегчить выполнение анализа. 3. Выбрать один или несколько инструментов DM. 4. Применить выбранные инструменты для обнаружения знаний. 5. Использовать обнаруженные знания для достижения цели исследования. Сравнительный анализ технологии извлечения данных и других технологий и методов Сегодня многие исследователи склонны считать, что DM связано, главным образом, с процессами индукции и в отличие от предшествующих технологий впервые позволяет получать обоснованную предсказывающую информацию по большим БД. Те, кто разделяют это мнение, представляют процесс эволюции извлечения данных примерно так, как это показано в Таблице 2 на примере решения задач маркетинга [5].
В то же время в [15] отмечается, что извлечение данных может пониматься и более упрощенно и предлагаются отличительные характеристики подлинного средства DM: 1) процесс извлечения должен быть автоматизированным; 2) должен быть хороший статистический базис для отделения интересующей пользователя информации от нерелевантной. В настоящее время наблюдается тенденция к слиянию технологий извлечения данных, OLAP и СППР [15]. DM тесно взаимодействует и повышает эффективность применения ряда технологий [16]: 1. Реализация запросов и генерация отчетов. DM позволяет сосредоточиться на использовании этих систем и методов, так что релевантная информация получается быстрее и экономится время аналитика. 2. Многомерные таблицы и базы данных. DM обеспечивает автоматический анализ, помогающий повысить эффективность использования данных, поддерживаемых многомерными инструментами. 3. Визуализация данных позволяет аналитику получить глубокое понимание результатов анализа данных. В то же время методы визуализации могут не справиться с огромными объемами информации базы данных, а DM дает начальные данные для продуктивного использования визуализации. Остановимся теперь более подробно на сравнении методов DM и статистики, а также технологий извлечения данных и OLAP. 6.1. Методы статистики и извлечение данных Традиционно цель определения и использования информации, скрытой в данных, достигалась с помощью генераторов запросов и систем, интерпретирующих данные (пакеты статистической обработки SPSS, SAS и др.). Согласно [11], формальный статистический вывод - это предположение, выводимое в том смысле, что гипотеза сформулирована и доказывается на основе данных. Извлечение данных, напротив, управляется открытием в том смысле, что образцы и гипотезы автоматически извлекаются из данных. Другими словами, DM управляется данными, а статистика - человеком. Исследовательский анализ данных - область статистики, наиболее близкая к извлечению данных, работает с меньшими множествами данных, чем DM. DM также отличается от статистики тем, что иногда цель состоит в извлечении качественных моделей, которые могут быть легко переведены в логические правила или визуальные представления; в этом смысле DM ориентируется на человека и иногда дополняется использованием человеко-машинных интерфейсов. DM - является интерактивным, полуавтоматическим процессом, начинающимся с рядов данных. Процесс DM предназначен для обнаружения скрытых данных, его результат - правила или предсказывающие модели. Как справедливо отмечается в [10], DM расширяет статистические подходы, допуская автоматизированную проверку большого количества гипотез и сегментацию БД. DM приобретает огромные преимущества по сравнению со статистикой при росте объема БД. В то же время следует подчеркнуть, что технология DM возникла из нескольких направлений: статистики, машинного обучения, баз данных и эффективных вычислений. 6.2. Технология OLAP и извлечение данныхfcibhztn cnfnbcnbxtcrbt gjl[jls?ра Технология OLAP (Online Analytical Processing) обеспечивает интерактивную обработку сложных запросов и последующий многопроходный анализ, предоставляя тем самым пользователям возможность анализировать в оперативном режиме большие массивы разнообразных данных, выявлять взаимосвязи, определять тенденции развития и предсказывать будущее состояние. Можно выделить два фундаментальных отличия технологий OLAP и DM. 1. Обработка данных. Как утверждается в [10], главное отличие между OLAP и DM в том, как они обрабатывают данные. OLAP-инструменты обеспечивают многомерный анализ данных, то есть они могут работать с распределенными данными. OLAP обычно выполняет объединение множества баз данных в очень сложные таблицы. OLAP-средства работают с агрегированными данными, то есть OLAP-технология приходит к обработке данных через добавление. DM, напротив, связано с соотношениями, образцами и связями во множестве данных. В то же время обе технологии могут быть использованы совместно. Фактически, агрегирование и индуктивный анализ дополняют друг друга. Например, анализ данных может обнаружить существенную взаимосвязь во множестве атрибутов. OLAP может затем обобщить результат и сгенерировать отчет, показывающий детально влияние этого открытия. 2. Происхождение гипотезы. В [3] отмечается, что ключевое отличие этих технологий состоит в следующем: OLAP направляется пользователем; аналитик строит гипотезу и использует OLAP-средство, чтобы ее подтвердить. Напротив, при DM инструмент обрабатывает данные, чтобы сгенерировать гипотезу. Аналогично, когда пользователи используют OLAP и другие средства запросов для исследования данных, они направляют исследование. При применении DM-средств, эти средства сами выполняют исследование. Рассмотрим пример, приведенный в [3]. Аналитик может предположить, что людям, имеющим большой долг и низкие доходы, рискованно предоставлять кредит (высокий риск кредита). Аналитик мог бы использовать OLAP различными способами, чтобы доказать или опровергнуть эту гипотезу. DM-средство может использоваться, чтобы обнаружить факторы риска для предоставления кредита: например, оно может обнаружить, что люди, имеющие большой долг и низкие доходы, имеют высокий риск кредита. Но DM может также обнаружить образец, который аналитик даже не мог предположить: например, соотношение долга, дохода и риска, связанного с возрастом. Здесь DM и OLAP дополняют друг друга: перед тем, как работать с образцом, аналитик должен знать финансовые предпосылки использования обнаруженного образца для определения тех, кто получает кредит. OLAP помогает ответить на такие вопросы. Более того, OLAP может улучшить ранние стадии процесса обнаружения знаний, помогая понять данные, фокусируя внимание на важных переменных, указывающих исключения, или при поиске взаимосвязей. Эти операции важны, так как чем лучше пользователь понимает данные, тем эффективнее будет процесс обнаружения знаний. Применение методов извлечения данных для обнаружения продукционных правил в базе данных Одно из главных препятствий в применении методов извлечения данных к большим реальным базам данных - недостаточная эффективность управления данными. В [17] выделяют следующие виды методов для работы с большими множествами данных: ·Выборочные методы используют небольшое подмножество БД, такое что могут быть применены методы нейросетей и традиционные алгоритмы машинного обучения. При этом неизбежна потеря информации. ·Инкрементные методы предполагают единственный просмотр всей БД. При этом необходима оперативная память достаточно большого объема для поддержки алгоритмов обучения и классификационных деревьев. ·Итерационные методы выполняют пошаговое усовершенствование начального множества правил путем получения дополнительной информации из БД. В [17, 18, 19] рассматривается система Monet с двухуровневой архитектурой (Рис. 3) для поддержки DM, включающей инструментальное средство для DM и параллельный cервер СУБД. Эта система использует итерационные методы при работе с БД. Отличительные черты Monet: использование простых и быстрых операций с БД; повторное использование результатов, полученных в предыдущих запросах; максимальное использование основной памяти для хранения наиболее часто требующегося подмножества БД; параллельная обработка запросов. В [18] выделяют следующие проблемы, возникающие при выявлении скрытых связей между данными: ·Велико количество возможных связей в БД (требуются алгоритмы эффективного поиска, но прямое их применение к большим БД влечет появление проблемы оптимизации и, как правило, многократные просмотры БД). · 7.1. Применение DM для классификационных правил Требуется найти правила, определяющие принадлежность объекта конкретному подмножеству, называемому классом. На практике пользователь разбивает БД на два подмножества: 1) P - положительные примеры для класса; 2) N - отрицательные примеры для класса. Затем система ищет классификационные правила, которые предсказывают, будет ли конкретный объект принадлежать множеству P или N, основываясь на значениях его атрибутов. Классификационные правила имеют вид: ®, где C - класс, D - «условие» - конъюнкция условий на значениях атрибутов. Условия на значениях атрибутов представляются в виде равенств в случае категориальных атрибутов и неравенств для числовых атрибутов. Фактически, условие D описывает выборку из БД, а так как БД разбита на подмножества P и N, то образуются две выборки Стратегия поиска. Для нахождения вероятных правил высокого качества используется итерационная стратегия поиска, управляемая метрикой качества. Начальное правило R0 имеет пустое условие: R0: ® (все объекты в БД принадлежат классу C). Тогда Q(R) - число положительных примеров, деленное на размер БД. В процессе DM правило расширяется добавлением условий на значения атрибутов. Применяется эвристика, состоящая в том, чтобы выбирать такие расширения правила, которые сохраняют его высокое качество. Для этого вычисляется качество всех возможных расширений правил. Комбинаторный взрыв правил-кандидатов сдерживается специальным алгоритмом лучевого поиска: дальнейший поиск и порождение расширений осуществляется только для правил, имеющих высокое значение качества из заданного диапазона. Процесс продолжается до тех пор, пока качество правил продолжает улучшаться и длина правил не превышает заданного предела. Для вычисления качества расширений правила Ri требуется рассмотрение только подмножества, описываемого Ri, а не всей БД. Все же основная задача - эффективное вычисление качества всех возможных расширений правила. Могут быть следующие решения: 1. Расчет качества для каждого расширения отдельно. При этом требуется два запроса: первый - подсчет числа объектов в 2. Вычисление приращения качества для множества правил (к каждому правилу добавляется счетчик). Предполагается, что последовательность просмотра БД не приводит к сокращению количества классификационных правил. 3. Модификация 1, в которой результаты запросов Функции сервера БД Monet: 1. Хранение и обеспечение доступа к данным. Преобразование сложных объектов и таблиц отношений в бинарные ассоциативные таблицы (BAT). Каждый атрибут хранится в отдельной таблице: 1-я колонка - заголовок - содержит уникальный идентификатор объекта, а 2-я - значения атрибутов. В результате улучшается доступ к БД для инструментов DM. Кроме того, используется вертикальное разбиение БД, при котором в основную память загружаются только те атрибуты, которые соответствуют текущей задаче DM. 2. Сбор статистики. Качество расширений правил вычисляется с использованием гистограмм. Гистограмма H для BAT A есть новая таблица, содержащая пары <значение, частота>: H(A)={,...,}, где fi - количество появлений значения vi в A для категориальных условий (вычисляется на основе специального SQL-запроса) и сумма частот для значений, меньших vi для числовых условий. 3. Вычисление выборок. Для определения множества объектов, описываемых правилом R1, то есть таких, что A=v строятся две таблицы P1 и N1. Сначала производится выборка для A=v из таблицы A. Заголовки результирующей таблицы T содержат идентификаторы всех объектов, для которых A=v. P1 находится как полуобъединение P0 и T. Аналогично находится и N1. Благодаря сжимающему характеру используемого алгоритма размер буфера в основной памяти, необходимый для хранения промежуточных результатов, стабилизируется после нескольких итераций. 4. Управление промежуточными результатами. После каждой фазы работы сервер уничтожает временные данные и их имена будут вновь использоваться. 5. Параллелизм. Можно параллельно вычислять BAT и их гистограммы. Алгоритм лучевого поиска также допускает параллельную реализацию. 7.2. Применение DM для ассоциативных правил Ассоциативное правило - выражение X®Y, где X и Y - множества атрибутов, означающее, что если атрибут в X - истина, то атрибут в Y, как правило, тоже истина. Для заданного множества атрибутов X носитель s(X) - количество транзакций, которые содержат все элементы X. Все ассоциативные правила X®Y, для которых s(XY)³s могут быть найдены в два этапа: 1. Поиск в БД всех больших предметных множеств, то есть множеств атрибутов, которые появляются вместе по крайней мере в s-транзакциях в БД («тяжелый» с вычислительной точки зрения этап). 2. Генерация ассоциативных правил по найденным предметным множествам («легкий» этап). В [19] рассматривается первый этап. Отмечается, что большинство алгоритмов, реализующих его, работают по схеме: ·находятся носители для отдельных объектов и строятся большие одно-предметные множества; ·осуществляется итерационный процесс для s=2,3,..., в котором 1) по большим (s-1)-предметным множествам генерируются s-предметные множества - кандидаты; 2) вычисляются носители для множеств-кандидатов по БД и те из них, которые оказываются большими, используются на следующем шаге (в результате происходит сокращение области поиска). Подчеркивается, что такие алгоритмы не поддерживают напрямую иерархии объектов. Новые направления исследований в области извлечения данных и приложения задач анализа данных Итак, подведем итоги. Рост объема цифровых данных за последние 10 лет приобрел взрывной характер, тогда как количество ученых, инженеров и аналитиков, способных анализировать эту информацию, остается постоянным. Чтобы преодолеть этот разрыв, необходимо решить фундаментальные новые исследовательские проблемы, которые могут быть сгруппированы следующим образом [11]: 1) разработка алгоритмов и систем для извлечения больших, объемных и многомерных множеств данных; 2) разработка алгоритмов и систем для извлечения новых типов данных; 3) fрарараразработка алгоритмов, протоколов и другой инфраструктуры для извлечения распределенных данных; 4) повышение легкости использования систем извлечения данных; 5) разработка подходящей модели обеспечения безопасности для DM. Рассмотрим подробнее проблемы, которые требуется решать в каждом случае. Масштабирование алгоритмов извлечения данных. Большинство алгоритмов предполагает, что данные размещаются в основной памяти. Фундаментальная задача состоит в том, чтобы выполнить масштабирование DM-алгоритмов для увеличения: · количества записей или наблюдений; · количества атрибутов, приходящееся на наблюдение; · количества предсказывающих моделей или множеств правил, используемых для анализа набора наблюдений; · скорости реакции системы. Кроме того, требуются не только распределенные и параллельные версии существующих алгоритмов, но и совершенно новые алгоритмы. Например, сегодня ассоциативные алгоритмы могут анализировать данные, не помещающиеся в памяти, за 1 или 2 прохода, требуя, чтобы лишь часть дополнительных данных находилась в памяти. Распространение DM-алгоритмов на новые типы данных. Сегодня большинство алгоритмов работает с векторными данными. Важная задача - распространить работу DM-алгоритмов на другие типы данных: временные ряды и процессы, неструктурированные данные (текст), полуструктурированные данные (HTML- и XML-документы), мульти-медиа, иерархические и многомерные данные и т.п. Развитие распределенных DM-алгоритмов. Большинство алгоритмов требуют, чтобы данные были собраны вместе в централизованном информационном хранилище. Фундаментальная задача - выполнять извлечение данных так, чтобы часть данных оставалась на своих местах. Кроме того, требуются подходящие протоколы, языки и сетевые услуги для извлечения распределенных данных, обработки метаданных и соответствий, необходимых при распределенном хранении данных. Простота использования. Извлечение данных сегодня в идеальном случае - полуавтоматический процесс и, возможно, навсегда останется таким. С другой стороны, проблема заключается в том, чтобы развивать DM‑системы, которые легко использовать даже случайным пользователям. Соответствующие методы включают: улучшение пользовательского интерфейса, развитие методов и систем для управления метаданными, требующимися для DM, и разработку подходящих языков и протоколов для обеспечения случайного доступа к данным. Кроме того, развитие сред DM и обнаружения данных, которые связаны с процессами сбора, обработки, извлечения и визуализации данных наряду с аспектами подготовки отчетов и объединения результатов при работе с данными и информацией, получаемыми в этих средах, представляет другую фундаментальную проблему. Защита и безопасность. Извлечение данных может быть мощным средством для получения полезной информации из данных. Так как становится доступно все больше и больше цифровых данных, то возрастает возможность злоупотребления средствами извлечения данных. Задача заключается в том, чтобы развивать модели и протоколы обеспечения безопасности, подходящие для извлечения данных, и добиться того, чтобы следующие поколения DM-систем использовали эти модели и протоколы. Заключение На сегодняшний день разработан ряд коммерческих продуктов для извлечения данных. В результате их внедрения уже получены первые уроки по применению технологии DM [14]: · Успешная работа DM-продуктов зависит от поддержки специалистов в области информационных технологий. · Развитие проекта DM направляется задачами предметной области. · DM чаще вырабатывает специфические результаты, чем общие правила. · Дружественный графический интерфейс маскирует сложность систем. · Сложные результаты не всегда удается интерпретировать или понять. · Для успешного использования требуется знание статистики, БД и предметной области. · Результаты критически зависят от качества данных. Технология извлечения данных поддерживается в настоящее время отчасти благодаря появлению новых приложений, требующих новых возможностей, не предоставляемых существующими технологиями. Эти новые приложения естественным образом могут быть разделены на три широкие категории по типу обрабатываемых данных [11]: 1. Деловые, экономические и коммерческие данные. Сюда включаются офисные и сетевые приложения, порождающие большие объемы данных о деловом процессе. Использование этих данных для эффективного принятия решений остается фундаментальной проблемой. 2. Научные и инженерные данные. Научные данные и метаданные имеют более сложную структуру, чем деловые. Кроме того, ученые и инженеры все активнее используют имитацию и системы с базой знаний из прикладной области. 3. Сетевые данные. Объем данных в сети увеличивается и возрастает их сложность: используются тексты, образы, числовые данные. Список литературы
|
 Управляемость. Технология хранилищ данных требует развития и реализации новых процессов, инструментов и рабочих систем для управления извлечением, трансформацией оперативных данных, администрированием пользователей и т.п. Необходимо определить условия для поддержки управления.
Управляемость. Технология хранилищ данных требует развития и реализации новых процессов, инструментов и рабочих систем для управления извлечением, трансформацией оперативных данных, администрированием пользователей и т.п. Необходимо определить условия для поддержки управления.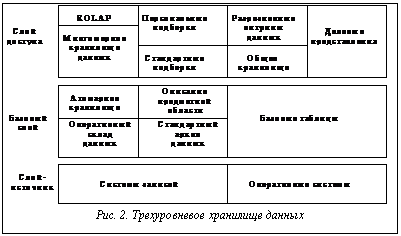 средств статистического анализа данных, средства выявления тенденций и прогнозирования, а также функции моделирования, агрегирования и объединения данных, и, наконец, средства оптимизации управляющих решений.
средств статистического анализа данных, средства выявления тенденций и прогнозирования, а также функции моделирования, агрегирования и объединения данных, и, наконец, средства оптимизации управляющих решений.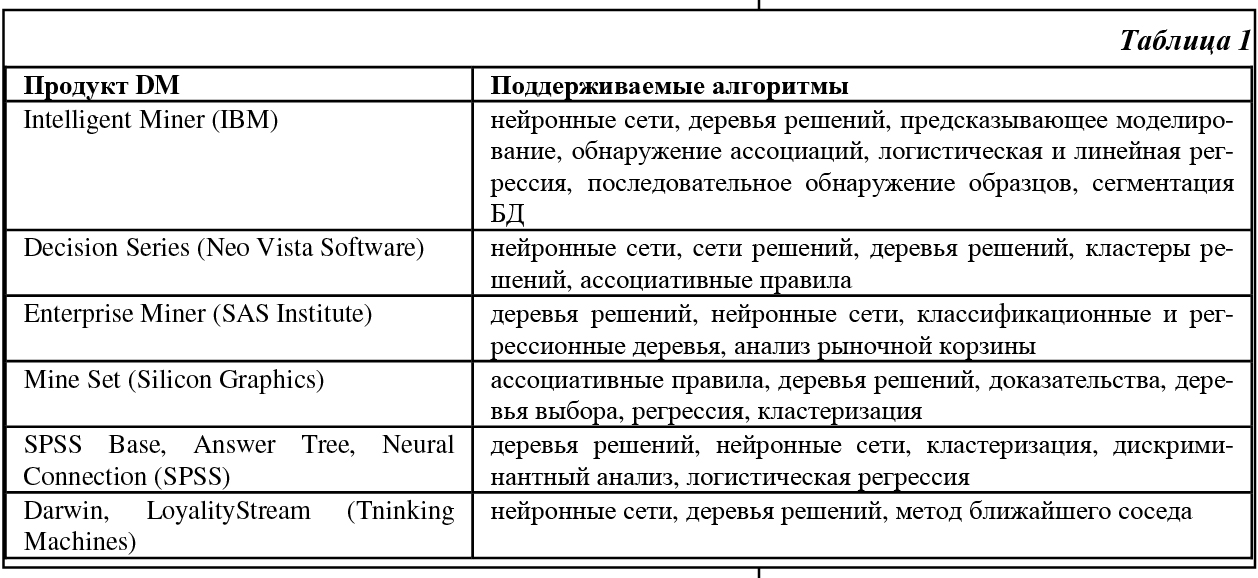
 Возможность пропуска интересных связей между данными, если используется не вся БД, а некоторое ее подмножество - образец (то есть такое подмножество должно быть также очень большого объема).
Возможность пропуска интересных связей между данными, если используется не вся БД, а некоторое ее подмножество - образец (то есть такое подмножество должно быть также очень большого объема). и
и  . Правило корректно по отношению к БД, если его условие описывает все положительные примеры (
. Правило корректно по отношению к БД, если его условие описывает все положительные примеры ( ). В общем случае существует мало корректных правил, так как принадлежность классу часто определяется информацией, отсутствующей в БД. Следовательно, имеет смысл искать вероятные правила. Для этого с каждым правилом R связывается характеристика качества или силы:
). В общем случае существует мало корректных правил, так как принадлежность классу часто определяется информацией, отсутствующей в БД. Следовательно, имеет смысл искать вероятные правила. Для этого с каждым правилом R связывается характеристика качества или силы: 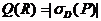 /(|
/(|| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=858 |
Версия для печати Выпуск в формате PDF (1.43Мб) |
| Статья опубликована в выпуске журнала № 1 за 2000 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Правовая охрана программного обеспечения с точки зрения международного сотрудничества стран-членов СЭВ
- О выборе числа процессоров в многопроцессорной вычислительной системе
- Система поддержки принятия решений по планированию профессиональной структуры подготовки специалистов
- Комплекс программных средств для аналитических иерархических процессов экспертного оценивания
- Функционально-информационные модели бухгалтерского учета
Назад, к списку статей