Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Программное обеспечение АРМ медицинского специалиста в области сосудистой патологии
Аннотация:
Abstract:
| Авторы: Бурцев Е.В. () - , Сасорова Е.В. () - , Райков А.Н. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 16926 |
Версия для печати |
В этой работе рассматривается программно-аппаратный комплекс, предназначенный для медицинских исследований и динамического контроля сердечно-сосудистой системы (ССС) человека в автоматическом и диалоговом режимах на базе анализа шестиканальной тахоосцил-лограммы (ТОГ). В предлагаемом комплексе у обследуемого пациента с 6 точек (2 на руках, 2 на ногах, 2 на висках) снимаются показания изменения давления в манжетах при прохождении пульсовой волны. Регистрируемые кривые (тахоосцилло-граммы) являются интегральным показателем работы сердца, сосудов, степени утомления человека; они дают возможность обнаруживать специфические нарушения в ССС человека, наблюдать за динамикой изменений ССС, обеспечивать индивидуальный подбор лекарственных средств и других воздействий в ходе лечения. Это не дорогостоящий, не опасный для здоровья метод, допускающий многократные повторения.
- шестиканального тахоанализатора с программно-управляемым процессом съема данных; - персонального компьютера (достаточно IBM PC 286); - платы сопряжения тахоанализатора и ПК; - системы программных средств, обеспечивающих прием, хранение, удобный пользовательский интерфейс и многоуровневую обработку данных. Отличительными чертами настоящей разработки являются: - возможность ее использования как для клинической диагностики, так и в исследовательских целях; - блочная структура системы; - наличие встроенной базы данных; - наличие подсистемы распознавания образов. В данной работе мы остановимся только на принципах построения программного обеспечения и особенно на методах и алгоритмах, применяемых в подсистеме распознавания образов. Другие составляющие комплекса подробно описаны в [1, 2]. Остановимся сначала на некоторых особенностях подсистемы распознавания, которые связаны с медицинской природой исследуемых данных. Врач, имеющий достаточный опыт, анализируя ТОГ, в некоторых случаях может четко формализовать ход своих диагностических рассуждений; в других случаях формализация не представляется возможной. Чаще всего она возможна для наиболее четких, острых форм заболеваний. При отсутствии возможности формализации врач дает заключение по совокупности данных на основании собственного опыта и интуиции. Поэтому мы пошли по пути параллельного применения двух методов: распознавания с учителем и логического распознавания. Во втором случае исследователем определяется совокупность правил, по которым тот или иной объект относится к какому-либо классу. КЛАССИФИКАЦИЯ С УЧИТЕЛЕМ. ПОСТАНОВКА ЗАДАЧИ Входной информацией для задачи распознавания образов является матрица "ОБЪЕКТЫ-ПРИЗНАКИ" (М х N), в которой каждой строке соответствует некоторый ОБЪЕКТ (пациент), а каждому столбцу - некоторый ПРИЗНАК (параметр) объекта. Задается КЛАССИФИКАЦИЯ - набор из К классов, к которым могут принадлежать объекты. Объекты, для которых принадлежность к тому или иному классу известна, составляют обучающую выборку. Задача распознавания образов заключается в отнесении некоторого нового объекта, заданного соответствующей строкой признаков и не принадлежащего к обучающей выборке, к одному (или нескольким) классам в рамках заданной классификации. В общем случае объект может принадлежать нескольким классам одновременно. Хотелось бы отметить, что любая классификация, как правило, не является единственно возможной, т.е. на одной и той же матрице данных всегда можно выделить несколько содержательных классификаций; выбранная классификация может не отражаться в выбранном наборе признаков, т.е. не существует способов отличить объект одного класса от объекта другого по значениям выбранных признаков. Наряду с основной задачей распознавания (классификация новых объектов в рамках заданной классификации), а зачастую ранее, исследователю приходится решать следующие проблемы: - выделение набора возможных классификаций, - проверку обоснованности классификации, - уточнение количества и границ классов в рамках выбранной классификации. В связи с этим и возникло два направления, по которым производились работы, и соответственно две различные подсистемы рассматриваемой системы: для скриннинг-анализа (ССА) и для медицинских исследований (СИА). Врачи применяли ТОГ для диагностики сосудистых заболеваний конечностей и состояния сердечно-сосудистой системы. Они пользовались в основном интегральными площадными характеристиками, вычисленными вручную (площади под кривыми ТОГ, соотношения площадей, форма огибающих, характеристики асимметрии). В предлагаемой системе вычисление характеристик по кривым ТОГ проводится автоматически, их перечень значительно расширен и может расширяться далее. В настоящее время их 138 (для 6 кривых); используются площади под кривыми и огибающими ТОГ для всех составляющих, суммарные площадные характеристики, соотношения площадей для разных точек отведения, для систолической и диасто-лической составляющих ТОГ, положения и величины экстремумов, характеристики асимметрии и др. (рисунок 2). Каждая характеристика имеет уникальное имя. Количество вычисляемых характеристик может быть изменено; система открыта для расширения.
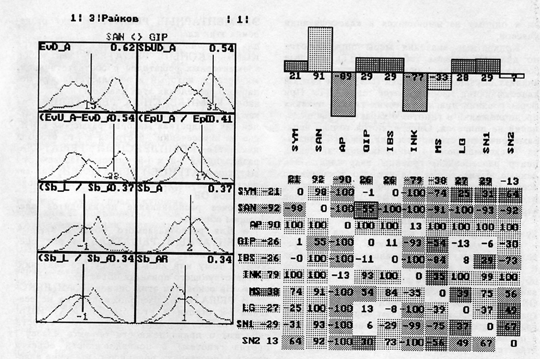
Рис.2. Каждый признак вычисляется по всем шести каналам, по различным уровням (голова, руки, ноги) и по сторонам тела (правая, левая).. Проанализируем наши исходные данные с точки зрения задачи классификации. Количество объектов в каждом классе, которое может быть предъявлено для обучения, неодинаково для всех классов, сравнительно невелико для некоторых классов и явно недостаточно для оценки плотности вероятности многомерного распределения. Анализ распределений по отдельным признакам показывает, что многие из них весьма далеки от нормальных. И в довершение всего один пациент может быть носителем нескольких заболеваний, т.е. классы пересекаются. В связи с этим был предложен следующий подход. Предположим, что существует к-мер-ное пространство решений, где к - количество классов в заданной классификации. Каждой точке этого пространства соответствуют координаты xi (К = i < = к). Значение координат по каждой оси - это мера принадлежности данного состояния испытуемого к базовому диагнозу. Пространство решений непрерывно; каждой классификации будет соответствовать свое пространство решений. Таким образом, результатом решения является не отнесение объекта к одному классу (как обычно принято в задаче распознавания), а оценка степени похожести иди непохожести на объекты того или иного класса. В нетривиальных задачах типа медицинской диагностики, где последнее слово всегда остается за человеком, информация такого рода воспринимается им менее агрессивно, чем категорические однозначные заключения, и, следовательно, будет более адекватно им использована. Кроме того, в такой сложной системе, как человеческий организм, четко детерминированные состояния менее вероятны, чем составные, и переход из одного состояния в другое чаще всего бывает плавным, а не скачкообразным. Пространству решений по заданной классификации можно поставить в соответствие множество заключений. Пространство решений разбивается на совокупность подпространств, для каждого из которых существует свое заключение. Эти подпространства могут не покрывать все пространство решений, тогда для оставшихся "непокрытыми" областей пространства решений заключение составляется перечислением базовых диагнозов и их мер, соответствующих ненулевым координатам точки пространства решений. Таким образом, каждой точке пространства признаков будет поставлена в соответствие точка в пространстве решений и затем одно из заключений из заданного для данной классификации множества заключений. Если анализ производится сразу по нескольким классификациям, то решение по каждой из рассматриваемых классификаций выносится автономно. МЕТОДЫ КЛАССИФИКАЦИИ Остановимся подробнее на методах распознавания, которые используются в системе. В связи с отмеченными особенностями исходных данных становится ясно, что использование какого-нибудь из "классических" методов распознавания в наших условиях не представляется возможным. В настоящее время в системе используются два альтернативных метода распознавания с учителем, разработанных нами для задач медицинской диагностики: метод, основанный на использовании аппарата нечетких множеств, и метод, использующий иерархические решающие правила; а также метод, построенный на логическом распознавании. КЛАССИФИКАЦИЯ С ИСПОЛЬЗОВАНИЕМ НЕЧЕТКИХ МНОЖЕСТВ Каждому объекту ставится в соответствие точка в пространстве признаков. Объекты одного класса (ki) образуют компактную область в пространстве признаков. Поскольку из-за недостаточной полноты обучающей выборки мы не можем уверенно обозначить границы этой области, постольку считаем, что объекты любого класса образуют в пространстве признаков нечеткое множество, а каждой точке пространства ставится в соответствие мера ее принадлежности данному нечеткому множеству. Рассмотрим пространство признаков, содержащее два класса, - ki и не ki - и определим меру ( mi) принадлежности данной точки классу ki. Мера - это число, изменяющееся от 0 до 1 (при mi = 0 объект не принадлежит к классу ki). Мы имеем К классов в заданной классификации. Каждому из предъявленных для экзамена объектов определяется мера его принадлежности к каждому из К заданных классов. Если для объекта все меры оказываются нулевыми, это означает, что данный объект нельзя приписать ни к одному из имеющихся в классификации классов. Конкретные значения меры определяются по диагностическим таблицам (ДТ), которые составляются на основе статистического анализа обучающей выборки (ОВ). Для каждой классификации формируются свои ДТ. При формировании диагностических таблиц никаких предположений и гипотез о характере распределения не делается. Определяются только непараметрические статистики для каждого признака (максимальное и минимальное значения, центр рассеивания, границы квартилей). Эти данные вычисляются для каждого признака по всей выборке в целом и по каждому классу отдельно. Все полученные статистические характеристики запоминаются. Далее выделяем и запоминаем границы следующих подмножеств каждого класса (пусть ti-число членов i-oro класса): ядра распределения (область, куда попадает ai объектов из ti заданных); приядерной зоны (оставшиеся объекты из обучающей выборки) и зоны рассеивания (в нее не попадает ни одного объекта из ОВ, она прилегает к приядерной зоне, а ее границы определяются путем обработки гистограммы адаптивным фильтром высоких частот с последующим нормированием). Каждой зоне ставится в соответствие мера. Границы зон запоминаются. После расчета статистик происходит оценка информативности каждого признака с точки зрения заданной классификации. Неинформативные признаки не включаются в ДТ и не используются в процессе принятия решения. Информативными считаются признаки, которые разделяют хотя бы два класса из заданной классификации. КЛАССИФИКАЦИЯ ПО МЕТОДУ ИЕРАРХИЧЕСКИХ РЕШАЮЩИХ ПРАВИЛ Предлагаемый подход к решению поставленной задачи предполагает, что все признаки объектов являются метрическими значениями в шкале не ниже шкалы порядка. Это предположение означает, что чем сильнее различаются между собой значения признака у двух объектов, тем более различными (по этому признаку) мы можем считать и эти объекты. Для результатов инструментальных исследований допущенное предположение, как правило, не является ограничительным. Описываемый метод использует основные идеи, изложенные в [3], несколько изменяя и дополняя их для работы с метрическими признаками. Основные этапы решения задачи распознавания: - рассматриваются распределения значений признаков в обучающей выборке для каждого из классов (оценивается дифференциальная функция распределения вероятности); - для каждой пары классов выделяются признаки, в некотором смысле хорошо разделяющие эти классы, и на их основе формируются ЭЛЕМЕНТАРНЫЕ РЕШАТЕЛИ для разделения этих классов; - для каждой пары классов формируется КОМПЛЕКСНЫЙ РЕШАТЕЛЬ как набор элементарных решателей с соответствующими весами, который и используется для попарного разделения этих классов; - набор КОМПЛЕКСНЫХ РЕШАТЕЛЕЙ для каждой пары классов может быть представлен как квадратная матрица размером К х К, где на пересечении i-й строки и j-ro столбца находится КОМПЛЕКСНЫЙ РЕШАТЕЛЬ, разделяющий i-й и j-й классы. Назовем эту матрицу МАТРИЦЕЙ РЕШАТЕЛЕЙ; она является результатом обучения на основе заданной ОВ. Рабочее распознавание производится следующим образом. • Для распознаваемого объекта каждый ЭЛЕМЕНТАРНЫЙ РЕШАТЕЛЬ может оценить вероятность гипотезы о принадлежности объекта тому или иному классу (по значению соответствующего признака объекта). • На основании этих оценок КОМПЛЕКСНЫЙ РЕШАТЕЛЬ, расположенный на пересечении i-й строки и j-ro столбца МАТРИЦЫ РЕШАТЕЛЕЙ, формирует оценку вероятности гипотезы о принадлежности объекта классу i против гипотезы о принадлежности объекта классу j (производит попарное разделение классов i и j). Эта оценка формируется, например, как взвешенная сумма оценок ЭЛЕМЕНТАРНЫХ РЕШАТЕЛЕЙ, входящих в соответствующий КОМПЛЕКСНЫЙ РЕШАТЕЛЬ. • Таким образом рассчитанные вероятности дают квадратную матрицу S размерности К х К, содержащую результаты распознавания объекта для каждой возможной пары классов. Сумма элементов i-ro столбца этой матрицы дает нам оценку похожести объекта на i-й класс, а сумма элементов i-й строки - оценку непохожести. Отношение суммы элементов i-ro столбца к сумме элементов i-й строки есть главный результат алгоритма — оценка принадлежности объекта классу i. • Результат удобно представлять в виде гистограммы принадлежности для всех классов, причем положительные значения означают голосование за принадлежность классу, отрицательные - против, близкие к нулю - отказ от суждения по соответствующему классу. В качестве побочного эффекта предлагаемый подход к формированию решателей позволяет исследователю проанализировать распределения отдельных признаков, выделить артефакты, увидеть неоднородность классов или их идентичность, переосмыслить классификацию отдельных объектов (выявить неверно классифицированные), т. е. помогает в решении перечисленных проблем, сопутствующих задаче распознавания. ЛОГИЧЕСКОЕ РАСПОЗНАВАНИЕ Остановимся далее на способах реализации диагностических рассуждений врача в подсистеме распознавания нашего комплекса. Мы посчитали целесообразным предоставить медикам возможность самим конструировать эти правила. Для этого разработан простой язык, позволяющий записать совокупность формализованных правил любому врачу, не имеющему опыта программирования, а также интерпретатор с этого языка. Совокупность правил записывается в пользовательский диагностический файл (ПДФ), так что любой практикующий врач может пользоваться своими правилами (или правилами, принятыми в данной школе). Перед использованием ПДФ необходимо провести его проверку на непересекаемость правил. ПДФ состоит из последовательности диагностических правил, количество которых не ограничивается. Каждое правило состоит из трех частей: маркера начала правила и имени, совокупности условий, составляющих данное правило, и диагноза, соответствующего этим условиям. Диагноз устанавливается только в том случае, если для данного пациента соответствующее правило выполняется. В противном случае данный диагноз в итоговое заключение не попадает. Можно получить также и описание ТОГ каждого пациента на понятийном уровне, подобно тому как медики делают описание ЭКГ и данных других инструментальных исследований. Описания используются для формирования обобщенных характеристик кровотока в конечностях, симметричности распределения потока крови в правой и левой частях тела и т. д. По желанию врача для описания можно использовать любые доступные системе характеристики. Описания составляются точно так же, как и диагностические правила, и так же помещаются в ПДФ. С точки зрения интерпретатора описания и диагностические правила равноправны. Различным классификациям могут понадобиться и разные ПДФ. ОСОБЕННОСТИ ПРОГРАММНОЙ РЕАЛИЗАЦИИ КОМПЛЕКСА Программная часть системы конструктивно выполнена как набор взаимосвязанных модулей. Базой такого набора являются: - монитор поддержки пользовательского интерфейса, построенный по принципу меню и снабженный контекстной подсказкой; - программа управления приемом данных и их визуализации в реальном масштабе времени; - система архивации и хранения; - встроенная база данных; - система расчета характеристик (признаков) каждой ТОГ и сохранения их в базе данных; - система, обеспечивающая статистический анализ накопленных данных для заданных групп пациентов; - система оценивания ТОГ и получения формализованного заключения. Подсистемы архивации и хранения, а также база данных обеспечивают сохранение и возможность использования в любой подсистеме следующих данных: - учетные данные каждого испытуемого; - данные о проводимом обследовании; - кривые ТОГ для каждого испытания (около 36 kb каждая); - характеристики (признаки), вычисленные по кривым ТОГ; - групповые характеристики по всем выделенным группам испытуемых, или по одному пациенту; - результаты каждого обследования. Функционально работа системы подразделяется на три основных этапа: - получение информации о пациенте - как учетной, так и самой нативной тахоосциллограм-мы; - обработка полученной информации с помощью различных программных модулей системы; j визуализация данных на всех этапах обработки в наглядной для исследователя форме. Структура программного обеспечения представлена на рисунке 3.
В настоящий момент разработана первая версия предлагаемого комплекса, которая может работать как в исследовательском режиме, так и в режиме скриннинг-анализа для следующих базовых диагнозов: практически здоров; ишемическая болезнь сердца; митральный сте-н*оз, мерцательная аритмия; тромбоокклюзион-нре поражение артерий нижних конечностей; ишемия нижних конечностей у больного с артериальной гипертонией; артериальная гипертония; аортальный порок с преобладанием недостаточности аортального клапана. J Результаты классификации по ДТ и логическим правилам записываются в текстовой файл с уникальным именем, сохраняются в архиве и выдаются на экран монитора и принтер. В режиме ССА после ввода ТОГ заключение выдается в течение 40-50 сек. В настоящей версии в исследовательском режиме дается возможность построить и в удобном графическом представлении на экране монитора просмотреть распределения для каждого признака по всем исследуемым группам пациентов. Разработана система диаграмм для отдельных комбинаций признаков, которые в наглядном виде позволяют наблюдать как нормальные, так и патологические соотношения между признаками для конкретного пациента. В заключение можно сделать вывод, что программная часть комплекса является системой открытого типа, она легко расширяется и модифицируется, работает на персональном компьютере самой простой конфигурации. Предлагаемая система может быть использована как для диагностики и анализа динамики состояния испытуемого, так и для исследований. В диагностических целях она использует параллельно пользовательский продукционный файл и подсистему распознавания образов. Последняя предлагает на выбор два альтернативных метода для решения задачи классификации, что также дает большие возможности для исследователя. Предложенные методы распознавания работают практически в реальном масштабе времени. Все работы, кроме опроса и надевания манжет на пациента, производятся в автоматическом режиме нажатием на компьютере клавиши готовности к приему данных. Система проста в эксплуатации, не занимает много места, не требует специального обслуживания; в режиме скриннинг-анализа за комплексом может работать лаборант. Система может быть поставлена на любой PC-совместимый компьютер, программы реализованы на языках С++ и Borland С. Программная часть комплекса не ориентирована жестко на обработку только данных шестиканальной тахоосциллографии - она является достаточно универсальной, может применяться в обработке данных инструментальных медицинских исследований широкого класса и рассматриваться как самостоятельная система. Список литературы 1. Е.В. Бурцев. Автоматизированное рабочее место медицинского специалиста в области сосудистой патологии. - М., 1993. - (Препр./РАН. Выч. центр коллект. пользования; №43). 2. Е.В. Бурцев, А.Н. Райков, Е.В. Сасорова, Принципы разработки распознающих систем для медицинской диагностики на примере тахоосциллографического обследования. - М., 1993. - (Препр./РАН. Выч. центр коллект. пользования; №44). |


| Постоянный адрес статьи: http://swsys.ru/index.php?id=1159&like=1&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 2 за 1994 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Компьютерная интеграция и интеллектуализация производств на основе их унифицированных моделей
- Разработка загрузчика программного обеспечения встроенной системы управления
- Учебно-исследовательский программно-лабораторный комплекс NET_LAB
- Унифицированный информационный интерфейс и его реализация в комплексной САПР
- Схемотехнические САПР для персональных компьютеров
Назад, к списку статей