Информационные системы: гибкость и простота
| Рубцов С.А. () - , Рубцова Э.Е. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
|
|
|
В настоящее время широкое распространение получили специализированные информационные системы (ИС) для персональных компьютеров на базе реляционных СУБД (FoxPro, dBase IV, Clipper и пр.). Разработчик такой ИС должен решить две взаимосвязанные проблемы. Во-первых, необходимо обеспечить комфортные условия работы с системой для пользователя-непрофессионала в области вычислительной техники. Во-вторых, при эксплуатации системы требования к ней пользователя неизбежно растут и поэтому необходимо предусмотреть возможность ее модификации и расширения. Удобство ИС в первую очередь означает возможность выполнения пользователем всех работ с системой с использованием понятийного аппарата его собственной предметной области, а также небольшого числа интуитивно понятных действий над базой данных. Легкость расширения системы предполагает как наличие простых и гибких средств формирования запросов, так и продуманную структуру И С, позволяющую добавлять к ней недостающие функции без необходимости перегенерации всего программного продукта. Существующие разработки, на наш взгляд, в неполной мере решают две рассмотренные проблемы, к тому же во многом противоречащие друг другу. Специализированные ИС, как правило, имеют жесткую структуру с фиксированным набором запросов к базе данных и строго заданным множеством реализуемых функций. Универсальные СУБД обладают необходимой гибкостью и в той или иной форме реализуют интерактивный язык QBE (Query By Example) - запросов по образцу. В то же время стремление к универсальности приводит к тому, что пользователь вынужден оперировать именами полей и файлов баз данных, функциями включающего языка, а также четко представлять логическую структуру базы данных. На наш взгляд, мощные интегрированные среды современных СУБД не предназначены ни для кого, поскольку для профессиональных программистов их сервис слишком навязчив, а конечные пользователи могут утонуть в океане открываемых ими возможностей. Так, например, в интерактивной среде FoxPro [3] реализация запросов Locate For осуществляется на четвертом уровне вложенности, часто требует открытия большого количества окон, допускает дублирование операции не менее чем тремя способами. Авторы вовсе не являются принципиальными противниками интегрированных сред, однако считают необходимым их использование только там, где это оправдано (например при программировании тех же ИС), и лишь в той степени, в какой многооконность не превращается в самоцель. Правильно построенная ИС должна в разумной мере сочетать простоту и понятность специализированных систем с гибкостью универсальных СУБД. Такой вывод, возможно, покажется тривиальным, однако нигде в литературе по базам данных [1-3] не делается специального акцента на ориентацию ИС на конечного пользователя. Очевидно, поэтому прикладные системы бывают столь насыщены специфической терминологией типа "файл dbf", "упаковка" и даже "реиндексация". В настоящей работе изложен опыт авторов по созданию информационной системы, структура которой позволяет легко настраивать ее на предметные области и модифицировать в соответствии с изменяющимися запросами пользователя. ИС содержит простой, интуитивно понятный язык запросов, который позволяет осуществлять поиск по условиям произвольной сложности, оперируя лишь близкими пользователю понятиями.
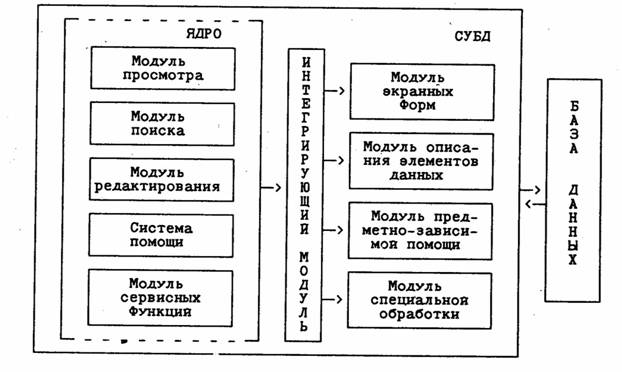
Рис. 1. Структура настраиваемой информационно-поисковой системы СТРУКТУРА НАСТРАИВАЕМОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ Предлагаемая настраиваемая ИС состоит из СУБД и БД для конкретной предметной области (рис.1). . На физическом уровне БД включает основную базу данных и ряд вспомогательных файлов (индексов, баз данных, справочников, таблиц и пр.), образующих среду системы. На логическом уровне БД представляет собой совокупность элементов данных, которые могут быть произвольными функциями от информации, хранящейся в БД. В простейшем случае элемент данных — это поле БД. Сложный элемент данных требует программирования функции на включающем dBase-подобном языке. Для конечного пользователя оба описанных уровня БД являются прозрачными, поскольку он имеет дело лишь с концептуальной моделью, которая строится с помощью псевдонимов элементов данных. Под псевдонимами понимаются более или менее подробные расшифровки имен элементов данных в понятиях предметной области БД. Конечный пользователь реализует все операции с ИС, оперируя только псевдонимами, он не должен знать ни форматов записей БД, ни логических связей между ними. Такая модель данных является достаточно гибкой, поскольку допускает расширение набора запросов к БД путем введения новых элементов данных. СУБД включает набор реализующих ее функции модулей, которые, делятся на инвариантные к приложению, составляющие ядро системы, и предметно-зависимые, осуществляющие настройку на данное приложение. Состав ядра системы (модули, инвариантные к приложению): Модуль просмотра БД реализует функцию просмотра и печати информации из базы данных. Просмотр осуществляется: - в табличной форме. Объектом просмотра может служить произвольное сочетание элементов данных из заданного набора. Пользователь формирует таблицу просмотра с помощью меню псевдонимов элементов данных (рис. 2); - по отдельным логическим записям ("карточкам" в терминах описываемой системы).
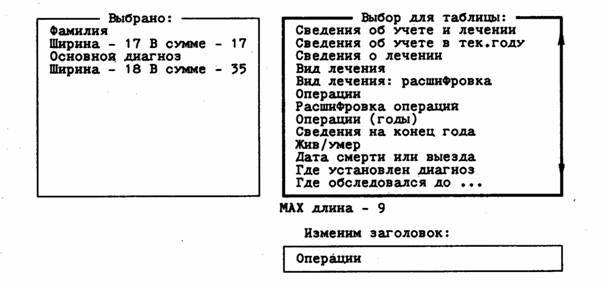
Рис. 2. Меню псевдонимов элементов данных Модуль поиска включает оригинальный язык интуитивно понятных запросов системы. Запрос формируется для любых элементов данных из упомянутого набора в произвольном их сочетании. Результаты поиска выводятся на экран и (или) печать с помощью средств модуля просмотра. Модуль редактирования обеспечивает занесение информации в БД и ее модификацию. Функция добавления информации для облегчения ввода записей потоком выделена в отдельный вид работ. Модификация данных возможна в любом из режимов просмотра. Система помощи реализует функции поддержки пользователя: работу со справочником по ИС и вызов контекстно-зависимых подсказок. Модуль сервисных функций дает возможность создавать, удалять, архивировать БД, осуществлять настройку аппаратуры компьютера (экрана, принтера), а также взаимодействовать со средой системы. В настраиваемой части СУБД имеются модуль экранных форм и модуль предметно-зависимой помощи. Первый задает формат карточки для просмотра и редактирования записей, второй содержит ту часть системы помощи, которая поясняет специфические для данной предметной области функции ИС. Эти специфические функции при необходимости должны быть реализованы в модуле специальной обработки. Как правило, этот модуль содержит алгоритмы статистической обработки данных и подпрограммы визуализации результатов разработки средствами деловой графики (и тому, и другому нетрудно придать достаточно универсальный характер, применимый во многих предметных областях). Особый интерес, на наш взгляд, в рассматриваемой структуре представляет модуль описания элементов данных. Он предназначен для создания объектов поиска и просмотра информации в БД и состоит из двух частей -информационной и программной. Информационная часть формируется в виде таблицы (базы данных), которая определяет имена, псевдонимы имен элементов данных и их тип: константа, переменная, поле, функция. Вторая часть модуля содержит программный код элементов данных - функций. Интегрирующий модуль является связующим звеном между ядром и настраиваемой частью СУБД. Объем модуля невелик, он лишь передает ядру имена предметно-зависимых модулей с помощью механизма макроподстановок включающего языка [1]. Описанная структура ИС обеспечивает легкую настройку на любое положение, а также внесение изменений в процессе эксплуатации путем добавления функций специальной обработки и новых элементов данных. Даже последующее изменение структуры основной БД, представляющее катастрофу для специализированных ИС, в такой системе не вызывает никаких осложнений. Система может быть реализована на любом dBase-подобном языке реляционных баз данных. Авторы выбрали в качестве языка реализации Clipper 5.O. Размер ядра СУБД получился порядка 500 Кб, что составляет от 90 до 70 процентов от общего размера программного кода в зависимости от сложности приложения. Легкость перенастройки оказалась впечатляющей: одному из авторов удалось перенастроить сложную ИС для онкологических медицинских учреждений в электронный словарь английских компьютерных терминов за 4 часа не слишком интенсивной работы. ЯЗЫК ИНТУИТИВНО ПОНЯТНЫХ ЗАПРОСОВ Язык интуитивно понятных запросов (ЯИПЗ), предлагаемый в настраиваемой информационной системе, позволяет пользователю (врачу, конструктору, бухгалтеру и т.д.), не знакомому с языками запросов универсальных систем баз данных, формировать произвольные запросы в терминах своей предметной области. Язык интуитивно понятных запросов является непроцедурным языком. Каждая строка S ЯИПЗ представляет собой конкретный запрос и может быть построена в соответствии со следующим правилом вывода: S à < элемент данных > | S < оператор > < элемент данных >. Элемент данных в общем случае является функцией от полей основной и вспомогательных баз данных, переменных, констант, возвращающей значение одного из стандартных типов данных. Напомним, что элементы данных известны пользователю под псевдонимом -поясняющими расшифровками имен на русском языке: < элемент данных > à F(X,V,C), где X - множество полей баз данных рассматриваемой СУБД, V - множество переменных, С - множество констант. Оператор является одним из элементов конечного множества операторов: < оператор > à {Содержит| Не содержит! Равно| Не равно| Пусто| Не пусто| Больше| Меньше| Больше-равно| Меньше-равно| Начинается с| И| ИЛИ} Указанное множество операторов не включает скобок. Это обусловлено особенностями формирования интуитивно понятных запросов. Пользователь, как правило, не формирует сложных логических условий в скобочной форме. Для построения сложных условий пользователю предлагается возможность пошагового уточнения первоначально сформированного условия с использованием операции И. В результате выделяется новое подмножество записей базы данных. Язык интуитивно понятных запросов реализован с использованием стандартных компонентов пользовательского интерфейса: меню, окон, текстовых блоков (рис. 3). Запрос формируется в текстовом блоке запросов, а элементы данных выбираются из меню псевдонимов. Элементы данных, представляющие собой константы, могут быть введены пользователем в текстовой блок с терминала. Операторы выбираются из меню операторов. Если в качестве элемента данных выбираются переменная, поле или функция, то в текстовом блоке запрашивается их значение.
Рис. 3. Окна формирования запросов настраиваемой ИС Результатом любого запроса является подмножество записей (отношение) основной базы данных, или множество записей, образованных при выделении некоторых полей в базе данных, или множество записей, образованных из полей нескольких баз данных. Элементы строки языка интуитивно понятных запросов интерпретируются как логические выражения (фрагменты команд) на dBase-подобном языке универсальной СУБД. Например, если необходимо выбрать всех пенсионеров мужского и женского пола, то в блоке запросов будет сформировано условие, представленное на рисунке 3. Элемент данных Пол является псевдонимом поля БД, а элемент данных Возраст есть функции от даты рождения (поле БД) и текущей даты (переменная среды). Соответствующее логическое выражение после интерпретации будет иметь вид: "M''$POL.and.age()>60.or."Ж"$POL.and.ageO>55. В последнем выражении присутствуют строковые и числовые константы, поле БД (POL), а также функция age(), запрограммированная в модуле описания элементов данных. Покажем, что язык интуитивно понятных запросов полон, то есть реализует операции реляционной алгебры [4]. Операция объединение отношений R1UR2, то есть подмножеств записей базы данных, реализуется с использованием операции ИЛИ меню операций. Каждая строка языка интуитивно понятных запросов выделяет из умалчиваемого отношения (основной базы данных) подотноше-ние Ri, объединение таких подотношений получается при использовании в запросе операции ИЛИ. Объединение также может быть реализовано средствами модуля (функции) дополнения базы данных, который для удобства пользователя выделен в отдельный пункт меню и не включен в меню элементов данных. Разность отношений R1-R2 обеспечивается в ЯИПЗ наличием взаимоисключающих операторов (содержит, не содержит; равно, не равно ...). Для реализации операции пересечение отношений R10R2 используется оператор И. Операция селекция σf (R) - это операция, операндами которой являются константы и компоненты отношения (элементы данных в терминах рассматриваемого языка), операторами являются операторы сравнения <,=,>,≤,≥,≠ и логические операторы &, V, ⌐. Множество операторов операции селекции является подмножеством множества операторов ЯИПЗ. Всем операторам этой операции, кроме отрицания, поставлены в соответствие операторы языка интуитивно понятных запросов. Отрицание элементов запросов не включено в перечень операторов ввиду отсутствия семантической интерпретации объектов типа -<Е (что означает "не имя поля", "не 10", "не строка"). Отрицание неявно присутствует во взаимоисключающих операторах ЯИПЗ: < Содержит >, <Не содержит >, < Равно >, <Не равно >, < Пусто >, < Не пусто >, учитывающих особенности символьных полей. Операторы < Содержит >, < Не содержит > означают соответственно наличие, отсутствие подстроки в символьном поле, или с использованием операции поиска подстроки Е1 в строке Е2 в базовом языке, Е1 $ Е2 = .Т., E1 $ E2 = .F. Операторы < Пусто >, <Не пусто > соответствуют проверке "пусто ли символьное поле Е": Е = nil, E ≠ nil. Оператор < Начинается с ... > соответствует проверке "начинается ли символьная строка с заданной подстроки", или АТ(Е)= 1, где АТ( ) -функция базового языка. Проекция πx (R) - это операция, при которой из отношения R удаляются либо переупорядочиваются некоторые компоненты. Проекция реализуется средствами модуля (функции) просмотра БД с использованием таблицы описания элементов данных. Операция естественное соединение R1> Таким образом, язык интуитивных запросов реализует операции реляционной алгебры и является полным. Опыт практической эксплуатации ИПС на базе языка интуитивно понятных запросов показал его гибкость, а также легкость освоения пользователями-непрофессионалами. Список литературы 1. Канатников А.Н., Ткачев СБ. Программирование в среде Clipper. Версия 5.0 и особенности версии 5.01. - М.: Финансы и статистика, 1994. - 240 с. 2. Попов А.А. Программирование в среде СУБД FoxPro 2.0. Построение систем обработки данных. -м.: Радио и связь, 1993. - 352 с. 3. Справочное руководство по FoxPro 2.0: В 3 т. - М.:И.В.К.-Софт, 1992. - Т.1. - 632 с. 4. Ульман Дж. Основы систем баз данных. - М.: - Финансы и статистика, 1983. - 334 с. |

http://swsys.ru/index.php?id=1165&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Основные характеристики методики АДЕСА-2 для разработки информационных систем и возможности ее практического применения
- Зарубежные базы данных по программным средствам вычислительной техники
- Оптимизация структуры базы данных информационной системы ПАТЕНТ
- Место XML-технологий в среде современных информационных технологий
- Исследовательское проектирование в кораблестроении на основе гибридных экспертных систем