Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Можно ли построить универсальную экспертную систему?
Аннотация:
Abstract:
| Автор: Ежкова И.В. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 13281 |
Версия для печати |
Можно ли построить универсальную экспертную систему? Почему возник этот вопрос и что нам даст ответ на него? Может быть, это традиционное стремление математиков все на свете формализовывать и облекать в универсальные схемы? Более того, не является ли этот вопрос противоестественным по отношению к самому понятию "экспертная система"? По своей природе экспертные системы возникли как системы, ориентированные на узкую проблемную область, где уникум-эксперт от-г дает свои знания о конкретной области искусственной системе, которая затем использует их в конкретных задачах принятия решений. Однако если мы останемся на такой позиции в отношении понимания экспертных систем (ЭС), то можно считать, что век ЭС закончился не начавшись. Почему же так мало существует реально действующих ЭС и какие в действительности нам нужны ? Примитивно современную ЭС можно представить как совокупность двух блоков: базу знаний (БЗ) о проблемной области и блок-решатель, обрабатывающий эти знания. Блок-решатель, как правило, практически без изменений может быть применен для многих проблемных областей. Кроме того, в последнее время все чаще стали появляться так называемые SHELL'd — программные оболочки для конструирования универсальных механизмов поддержки и обработки знаний. Сложность при разработке ЭС заключается в добывании априорных знаний о проблемной области. В современных ЭС источником знаний является эксперт. Процесс извлечения знаний из экспертов исключительно трудоемок и составляет не менее 90% от трудоемкости всего процесса создания ЭС. Несмотря на бесчисленное множество разработанных методик и тактик, процесс извлечения- знаний по-прежнему скорее искусство, чем наука. Не случайно, например, в ведущих фирмах по разработке и внедрению систем, основанных на знаниях, в том'числе ЭС, больше всего ценятся такие специалисты, - которые занимаются извлечением знаний из экспертов. Итак, исключительная трудоемкость процесса построения БЗ является серьезным препятствием на пути внедрения традиционных ЭС. Но этого мало. Но этого мало. Во-первых, на практике всегда оказывается, что в БЗ не учтены какие-то параметры или понятия. Во-вторых, часто возникает необходимость взглянуть на проблемную область с другой точки зрения, изменив постановку задачи. Предположим, что вы построили ЭС для диагностики неврологических заболеваний и передали ее в больницу. Пациент, больной менингитом, не сможет получить помощь от вашей ЭС, если в ее базу знаний не были включены знания о менингите. Казалось бы, отсутствие в БЗ каких-то знаний не может являться проблемой, поскольку их можно туда добавить. Однако этого делать нельзя, так как при этом мы можем нарушить весь "строй" БЗ: все оценки в БЗ должны теперь интерпретироваться в соответствии с новой проблемной областью и, следовательно, некоторые знания (а может быть, и все) могут стать неверными. Если в БЗ для неврологических заболеваний содержалась экспертная оценка "высокая температура", которая подразумевала значение порядка 37,5°, то при добавлении в ряд дифференцируемых заболеваний понятия "менингит" эта оценка может интерпретироваться щире, например, как значение 38,5°. Кроме того, значимость самого симптома "температура" в новом контексте намного возрастет; то, что было важно в одной проблемной области, может стать "шумом" в другой н наоборот. В итоге даже при незначительной переориентации ЭС придется заново составлять всю БЗ, т.е. повторять этот исключительно трудоемкий процесс, что фактически равносильно построению новой ЭС. Таким образом, основная причина, по кото* рой экспертные системы не нашли широкого применения, заключается в том, что они оказались не способными самостоятельно формировать знания и перестраивать их при изменении проблемной области. Традиционный способ разработки ЭС с ориентацией на узкую проблемную область (узкую в том смысле, что как бы широко мы ни зафиксировали проблемную область, на практике всегда возникает необходимость ее расширения) напоминает нашу кабинетную систему здравоохранения, когда больной, попадая в специализированный кабинет, например, к нефрологу, рассматривается только как "а нет ли у него болезни данного типа", и Ни в одном из кабинетов не анализируется организм больного в целом. Если мы хотим решать такие задачи, как, например, задачи интегральной оценки состояния человека, нам необходимы универсальные экспертные системы (УЭС), способные самостоятельно строить знания о проблемной области и при ее изменении перестраивать их. Причин, по которым необходимо разрабатывать концепцию УЭС, существует много. В связи с широким распространением компьютеров мы вправе надеяться, что они будут хорошими помощниками не только в различных производственных сферах, но и в быту: планировать ведение домашнего хозяйства, помогать в выборе меню, фасона платья и т.д. Одним словом, в век компьютеризации мы рассчитываем, что машины возьмут на себя львиную долю задач, аналогичных тем, которые решает ЭС в конкретных проблемных областях. Проект создания компьютеров пятого поколения и предназначен для решения такой задачи — внедрить интеллектуальные подсказки в различные проблемные области. Но для каждой проблемной области строить свою ЭС невозможно: во-первых, у человечества на это просто не хватило бы времени, и, во-вторых, всегда найдется такая проблемная облость, которую мы еще не предусмотрели (имеется в виду, конечно, не разработка тела самой ЭС, а лишь тот этап, который предусматривает построение БЗ). Представляет интерес другой вариант — использование универсальной ЭС, которая сначала обучается "на все случаи жизни", запоминая множество обучающих примеров, а затем при настройке на конкретную задачу самостоятельно формирует знания о соответствующей проблемной области. При любом, даже незначительном изменении постановки задачи УЭС должна самостоятельно перестроить свои знания, опираясь на другое множество обучающих примеров. Распараллеливание вычислений предоставит нам прекрасную возможность для реализации УЭС, работающих параллельно с традиционными вычислительными процессами. Такая УЭС могла бы автоматически обучаться, время от времени считывая определенную информацию с основных вычислительных каналов и рассматривая ее как пример обучения для формирования знаний относительно концептуальных структур основного вычислительного процесса. Используя полученный опыт, система могла бы в дальнейшем генерировать подсказки, воспринимаемые ЭВМ как эвристики, управляющие процессом основных вычислений. Такой вариант использования УЭС можно вполне реализовать и на современных последовательных ЭВМ, предусмотрев заранее точки ввода УЭС в основной процесс вычислений для формирования Множества обучающих примеров. УЭС может формировать бесчисленное множество баз знаний, относящихся к совершенно разным проблемным областям. В частности, ока может генерировать знания относительно собственного поведения. Понятиями такой специальной проблемной области могут быть методы, тактики и стратегии, используемые УЭС. База знаний, содержащая оценки поведенческой деятельности УЭС, может использоваться для корректировки ее будущей активности. Если ввести обратную связь, т.е. в память УЭС досылать верифицированные результаты ее работы и рассматривать их в качестве новых обучающих примеров, то УЭС сможет адаптировать свой опыт и поведение за счет постоянной корректировки собственных знаний. Такая адаптация позволит УЭС эффективно функционировать в динамически изменяющемся внешнем мире. Развитие концепции УЭС интересно также и с других позиций. Одна из них — необходимость более пристального изучения процесса формирования и преобразования знаний с учетом их понимания. Известно, что человек в процессе принятия решений, активно используя знания из других областей, образует метафоры, аналогии, ассоциации. Такой тип обработки знаний требует формирования метавзгляда на совокупность знаний о проблемной области, в частности, формализации контекста проблемной области. Но чтобы подняться на мета-уровень относительно проблемной области, необходимо выяснить глубинные механизмы формирования и понимания самих знаний. Изучение этой проблемы необходимо также для формирования более обоснованных схем обработки знаний внутри контекста каждой проблемной области (вспомним, что сходство между понятиями, лежащее в основе таких схем, во многом зависит от контекста проблемной области: два понятия, близкие в одном контексте, могут быть диаметрально противоположными в другом. Исследования в области формализации контекста проблемной области позволят улучшить работу многих других систем, основанных на знаниях. К ним, в частности, следует отнести интенсивно развиваемое в мире направление по построению гиперкниг (гипертекстов). Один из ожидаемых эффектов от формализации контекста проблемной области и межконтекстных операций (расширения, сужения контекста проблемной области, построения метафоры, ассоциаций, аналогий) — это теоретическое обоснование многих иллюстративных эффектов в задачах интерфейса человека с компьютером. До сих пор при разработке интерфейсов вопрос визуализации смысла решался интуитивно. Вам повезло, если вы смогли найти удачную форму иллюстрации того, что делает ваша программа. Механизм работы с контекстами позволит обосновать, почему эта форма является удобной, и автоматически найти оптимальную форму иллюстрации (например визуализацию). Действительно, удачная иллюстрация является ;в конечном счете хорошей метафорой, аналогией или ассоциацией. Операции отображения на множестве контекстов, лежащие в основе построения метафор, аналогий и ассоциаций, позволят автоматически находить удачные иллюстрации концептуальных основ проблемных областей. Наконец, разработка концепции УЭС будет способствовать созданию био- и нейрокомпьютеров. Механизмы формирования и обработки знаний, используемые в УЭС, предназначены для решения тех же задач, какие решает человек, выступая в роли универсального эксперта в различных проблемных областях. Такие механизмы можно рассматривать в качестве модели того, что и как должен уметь делать био- и нейрокомпьютер. Итак, делаем вывод: УЭС нужны, так как с их помощью можно будет решить многие принципиальные вопросы создания и внедрения современных ЭС; они также будут способствовать развитию теоретических и практических разработок систем, основанных на знаниях. Построение УЭС Предлагаем одно из возможных решений. Напоминаем, что УЭС должна: — самостоятельно формировать знания о проб лемной области, — изменять знания при изменении проблемной области, — обрабатывать знания с учетом их принад лежности к контексту конкретной проблемной области по внутриконтекстным и межконтекст ным схемам. Одной из основных проблем, возникающих при создании УЭС, является формализация контекста проблемной области. Явное выделение контекста лежит в основе понимания знаний в процессе их формирования и дальнейшей обработки (контекст является метапонятием по отношению к БЗ). Операции над контекстами лежат в основе межконтекстных схем преобразования знаний. Данная концепция УЭС предполагает наличие базы данных, в которую на этапе обучения записываются обучающие примеры для бесчисленного множества понятий. При настройке на конкретную задачу из базы данных выбираются примеры, имеющие отношение к данной проблемной области. По этим примерам строятся функции опыта, которые используются в процедуре вербализации для получения лингвистических описаний базовых понятий проблемной области. Описания подобны тем, которые обычно получают в результате извлечения знаний из экспертов. Фактически множество таких описаний определяет традиционную БЗ. Однако в рассматриваемой концепции УЭС процесс формирования знаний не заканчивается построением БЗ. Целью этапа настройки на конкретную задачу является формирование контекста проблемной области. Контекст формализуется в виде кортежа из пяти элементов, одним из которых является БЗ, а остальные четыре элемента лежат в основе более глубокого понимания знаний о данной проблемной области. При настройке на другую проблемную область создается другой контекст. УЭС может хранить несколько контекстов или динамически их порождать. На рис.1 приведены те блоки схемы УЭС, которые отличают ее от традиционных ЭС.
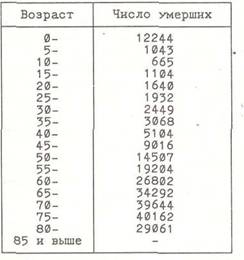
схемы УЭС, которые отличают ее от традиционных ЭС. Блок-решатель состоит из двух блоков: внутри- и межконтекстной обработки знаний. Внутриконтекстная обработка знаний основана на использовании расстояния между понятиями s контекстном пространстве. Межконтекстная обработка знаний использует алгебру и логику контекстов. Алгебра контекстов позволяет организовать такие процессы, как сужение и расширение контекстов, погружение заданного контекста в более широкий (вспомним задачи герменевтики), объединение и пересечение контекстов, имеющих интересную интерпретацию и формализующих различные нетрадиционные схемы обработки знаний. Логика контекстов рассматривает отображения одного контекста на другой и позволяет формализовать такие меж контекстные схемы обработки знаний на вывод по аналогии, метафоре и ассоциациям. Обучение На этапе обучения накапливается опыт УЭС, формируется база данных (БД), в которую записываются обучающие примеры для множества понятий. Каждый обучающий пример Y0 для понятия О представляется в виде вектора признаков: где у — значение i-ro признака, измеренного по абсолютной, интервальной или порядковой шкале. Множество всех признаков, используемых на этапе обучения, образует исходное семантическое пространство признаков S. В дальнейшем знак R будем использовать для обозначения операции описания в пространстве R. Источником обучающих примеров может быть аналоговое устройство, эксперт, литература или какая-то специальная процедура формирования обучающих примеров. Например, вектор Y'1"""1^ = <38°, 30, ясное, ...> задает обучающий пример для определения понятия "грипп" через следующие признаки: температура (38°), возраст (30 лет), состояние сознания (ясное) и т.д. Такой пример взят из конкретной истории болезни пациента, больного гриппом. Настройка на конкретную проблемную область После постановки задачи УЭС формирует знания о данной проблемной области (ПО). Исходной информацией для УЭС является множество имен базовых понятий данной ПО (например, в случае медицинской диагностики это может быть подмножество имен неврологических или инфекционных заболеваний, либо какое-то другое специальным образом выделенное множество заболеваний). При построении БЗ о данной проблемной области УЭС находит в БД обучающие примеры, относящиеся к выделенным понятиям. На данном этапе УЭС работает только с этим множеством обучающих примеров, и основная задача УЭС — распознать контекст ПО и на его основе построить БЗ относительно данной ПО. Каждое базовое понятие в такой БЗ будет описано с помощью лингвистических оценок его признаков, при этом будут использоваться только те признаки, учет которых важен в данном контексте. Значимость признаков является контекстуально зависимой и может определяться с помощью лингвистических оценрк. Процесс формирования БЗ основан на процедуре вербализации, позволяющей антомати-чески строить лингвистические оценки по значениям признаков на семантических шкалах (числам, баллам, любым упорядоченным значениям). Процедура вербализации использует функцию опыта, представляющую собой интегральную характеристику опыта УЭС по данному признаку в данном контексте. Функция опыта строится по распределению значений признака в множестве обучающих примеров, относящихся к данному контексту. Функция опыта Пусть Е — множество базовых понятий данной ПО. Зафиксируем некоторый признак как р , построим распределение значений признака р в данной ПО. С этой целью возьмем обучающие примеры для всей группы понятий Е в целом, рассматривая ее как единое целое. Анализ полученной функции DE позволяет сделать некоторые выводы относительно того, насколько подходит признак р для описания данного контекста. Наиболее удачным является случай, когда DE является унимодальной, т.е. имеет один максимум. Этот максимум определяет норму как наиболее типичное значение признака р для данной группы понятий Е в данном контексте. Только в том случае, когда существует один максимум DE и, соответственно, одна норма, относительно которой можно дать лингвистическую оценку типа "высокий", "легкий" и т.д., можно считать, что выполнены необходимые условия для использования лингвистических оценок. В противном случае необходимо разбить признак р на множество признаков р fc , ..., pm fc , по каждому из которых функция DE является унимодальной. Как показывает опыт, этот прием соответствует представлению экспертов о данном признаке. В таблице приводятся данные о смертности мужчин в зависимости от возраста (Великобритания, 1953 г.) [9]. Таблица Смертность мужчин в зависимости от возраста
Фактически два пика смертности приходятся на детский и старческий возраст. В результате вместо одного признака появляются два: "детская смертность" и "старческая смертность", каждый из которых имеет одногорбые распределения и соответственно одну норму и по каждому из которых мы теперь вправе дать лингвистическую оценку типа "рано", "очень рако" и т.п. Приемы, аналогичные приведенному, позволяют УЭС откорректировать исходное семантическое пространство признаков S. В новом пространстве признаков S данный контекст характеризуется унимодальными распределениями возможных значений признаков. В [13] (относительно частотных оценок) и в [10, 11, 12] (относительно общего случая) показано, что для измерения признака с помощью лингвистической оценки типа "часто", "высокий", "сильный" и т.д. нужно построить функцию опыта субъекта по частоте разных значений признака и с помощью этой функции отобразить конкретное значение с семантически окрашенной шкалы, измеряющей признак в м, кг, час, "попугаях" и т.д. на некоторую универсальную шкалу. На универсальной шкале лингвистические оценки могут быть формализованы в виде нечетких подмножеств интервала [0, 1], не зависящих от субъекта и семантики оцениваемого признака. В роли субъекта, генерирующего оценки, может выступать и УЭС. Ее опыт по оценке признака р в рамках контекста С задается функцией опыта DE , построенной из распределения DE в результате следующего преобразования:
где PNOHM — "нормальное" значение признака (норма), при котором D максимально. Построенная по контексту функция опыта позволяет переводить значения признака с семантической шкалы в лингвистические оценки на универсальной шкале. Вектор функций опыта FE = для признаков откорректированного пространства S* будем называть вектором опыта. Вектор опыта задает перевод (отображение) семантического пространства S в универсальное пространство U. Шкалы пространства U являются универсальными для измерения признаков с помощью лингвистических оценок. Этот перевод является кок-текстуально зависимым, а вектор опыта формирует контекст. Процедура вербализации Процедура вербализации позволяет построить по известным семантическим значениям признака лингвистические оценки с учетом контекста ПО. Эта процедура может быть использована, например, в такой задаче: известен урожай пшеницы в нашей стране в этом году, требуется оценить этот урожай с помощью лингвистической оценки типа "плохой, богатый, очень богатый" и т.п. по отношению к урожаям в нашей стране в прошлые годы. Из статистического распределения урожаев по прошлым годам можно построить функцию опыта в данной ПО. В результате процедуры вербализации будет найдена лингвистическая оценка урожая в этом году на фоне данного контекста. Задача может быть изменена: найти лингвистическую оценку урожая пшеницы в нашей стране в этом году по отношению к урожаям пшеницы в других странах в этом году. В новом контексте процедура вербализации будет использовать новую функцию опыта, построенную с учетом статистического распределения урожаев пшеницы по всем странам в этом году. В результате будет получена совершенно другая лингвистическая оценка того же урожая. Пусть Z — значение признака р по семантической шкале. В качестве общего рассмотрим случай, когда Z является нечетким множеством, т. е. определяется с помощью функции принадлежности ц.(х), хеДр, где Др — множество возможных значений признака р, измеренных по заданной семантической шкале. В частном случае Z может быть нечетким множеством специальной упрощенной формы, нечетким числом, просто числом или любым значением на порядковой шкале. Пусть F — функция опыта по значениям признака р в данном контексте, V — набор лингвистических оценок, принятый для измерения признака р. Каждая лингвистическая оценка из V представляется в виде нечетких подмножеств, построенных на основе психологических экспериментов или аналитических соображений (специальной интервальной, треугольной, трапециевидной и т.п. формы). Суть процедуры вербализации в следующем. Отображаем нечеткое значение Z с помощью функции опыта F на универсальную шкалу. Пусть R — нечеткое подмножество интервала [0,1], полученное в результате этого отображения: значение признака х с семантической шкалы переводится в значение у = F(x) из интервала [0,1] универсальной шкалы и берется со степенью возможности ц,(х). Обозначим функцию принадлежности нечеткого множества R через г(у) уе[0,1]. Из набора V выбирается та лингвистическая оценка L, связь с которой нечеткого подмножества наилучшим образом из V приближает нечеткое подмножество 1° . Процедура вербализации:
Шаг 1. Отображаем значение Z с семантической шкалы в значение R универсальной шкалы с помощью функции опыта F: Здесь М — лингвистическая оценка из набора V , связь с которой нечеткого подмножества с функцией принадлежности т(у) наилучшим образом из набора V приближает нечеткое подмножество R (процедура наилучшего приближения определена в [10]. Результатом процедуры вербализации является лингвистическая оценка М, найденная с учетом заданного контекста. Лингвистическое описание базовых понятий ПО Используя процедуру вербализации УЭС, можно построить лингвистическое описание базовых понятий ПО. Прежде всего построим описание базовых понятий данной ПО в откорректированном семантическом пространстве S". Фиксируем признак р и понятие О из множества Е (например, р = температура, О = менингит). Пусть Ъ° — множество обучающих примеров в БД, относящихся к понятию О. Построим распределение f числа этих примеров по значениям признака р . Например, f — распределение больных менингитом в группе обучения по значениям температуры. Функцию jj,0 , полученную из f в результате нормирования до 1, можно рассматривать как функцию принадлежности нечеткого значения Т признака р , характеризующего понятие О. Тогда каждое понятие О из множества базовых понятий данной ПО может быть описано в откорректированном семантическом пространстве S* в виде вектора
Пусть F = — вектор функций опыта по признакам р , ..., р . Пусть V , ..., V — множества лингвистических оценок, обычно используемых для признаков р , ..., р соответственно. Применяя процедуру вербализации к каждому признаку в отдельности, УЭС может определить лингвистические оценки L0 , i = l, . . ., m для признаков р , „., р соответственно с vveTOM контекста панной ПО'
здесь входными параметрами процедуры Verb являются: Т ° — значение признака р для понятия О, F — функция опыта по признаку р в данном контексте, V( — набор традиционно используемых лингвистических оценок для измерения признака р . В итоге УЭС строит описание понятия 0 через лингвистические оценки признаков р , ... , р в универсальном пространстве U:
Такое описание УЭС строит для всех базовых понятий ПО. Следует вспомнить, что при изменении контекста ПО задается другое множество базовых понятий, строится новый вектор опыта и, следовательно, новые лингвистические описания понятий, т.е. одно и то же понятие на фоне разных контекстов будет иметь разные описания [1, 4, 14]. Описание понятий в контекстном пространстве Вектор опыта, представляя все множество опорных понятий в целом, является интегральной характеристикой контекста ПО. Дифферек- циальной характеристикой контекста является вектор коэффициентов значимости признаков для выделения дифференцируемых опорных понятий на фоне контекста. Предложено много достаточно произвольных процедур вычисления коэффициентов значимости признаков по известному набору оценок дифференцируемых понятий. В данном случае оценки признаков имеют лингвистический эквивалент, что позволяет при выборе процедуры использовать наглядную интерпретацию [10]. Пусть к , ... , к коэффициенты значимости признаков р ... , р , вычисленные по лингвистическим оценкам базовых понятий данного контекста. Коэффициент значимости задает важность учета признака в данном контексте. Сужая пространство признаков за счет удаления менее значимых признаков, можно акцентировать наиболее важную часть описания контекста. Вопрос о пороге значимостн, превышение которого является необходимым условием сохранения признаков в описании контекста, является контекстуально зависимым и должен рассматриваться в каждам случае отдельно. Представляется разумным в качестве такого порога использовать "нормальное", наиболее типичное для данного контекста значение коэффициента значимости признаков. Для его вычисления УЭС может построить контекстуально зависимую функцию опыта по коэффициентам значимости (распределение числа признаков по коэффициентам значимости), привести ее путем подбора класс-интервалов к унимодальному виду и использовать максимальный коэффициент значимости. Пусть к.,,,,, , — найденное для ■* NORM данного контекста значение порога [10, 14]. В [10] описаны проблемы, связанные с вычислением порога, и приведены примеры вычисления значимости признаков-симптомов при диагностике сердечно-сосудистых заболеваний.
Универсальное пространство ранжированных по значимости признаков р , коэффициенты значимости которых превосходят kNQRM, будет использоваться для описания контекста и называться контекстным. Множество имен признаков контекстного пространства будет называться множеством базовых опорных признаков контекста. Описание понятий в контекстном пространстве акцентирует наиболее важную часть для данного контекста. Набор лингвистических описаний базовых понятий контекста в контекстном пространстве Uc Формализация контекста На основании анализа обучающих примеров можно сделать вывод, что УЭС способна порождать лингвистические описания понятий на фоне заданного контекста. При изменении контекста ПО описание знаний автоматически меняется, и УЭС подготавливает новую базу знаний. Исходной информацией для УЭС является: £1 — множество имен понятий на этапе обучения; F — множество имен признаков, используемых на этапе обучения; 2 — множество обучающих примеров — векторов в семантическом пространстве признаков; Е — множество базовых понятий на этапе настройки на конкретный контекст. Чем больше множества И, Р и 2, тем больше опыт УЭС. Заметим, что примеры из S могут восприниматься с разными степенями доверия в зависимости от доверия к источнику информации. В формализации контекста ПО выделяются следующие этапы: — корректировка семантического пространства признаков; — построение вектора опыта для формирова ния лингвистических оценок, отображение в универсальное пространство; — ранжирование признаков по значимости для описания контекста; — вычисление контекстуально зависимого по рога значимости признаков и построение мно жества опорных признаков контекста; — построение контекстного пространства для описания наиболее значимой части контекста. Для формального описания контекста С будем использовать кортеж из пяти элементов: С - ( Е, Р, Q, F, Z ), где Е — множество базовых понятий контекста, Р — множество базовых признаков контекста, Q — вектор коэффициентов значимости базовых признаков, F — вектор опыта по базовым признакам, Z — набор лингвистических оценок для описания базовых понятий на фоне контекста, Z = {Le }, k = 1, .... т. ОеЕ. Каждое новое понятие на фоне данного кон-текста может быть описано УЭС путем набора лингвистических оценок в результате отображения с помощью вектора опыта в контекстное пространство. Расстояние в контекстном пространстве Введение контекстного пространства позволяет определить расстояние между понятиями на фоне контекста. При изменении контекста расстояние между понятиями меняется, что соответствует представлениям человека о реальном мире. Например, для обозначения понятия "снег" эскимос использует около десяти терминов, а европеец всего один. Это говорит о том, что расстояние между терминами, обозначающими снег, на фоне эскимосского контекста достаточно велико, в то время как на фоне европейского контекста оно становится равным лулю. Введение универсальной шкалы для измерения признака позволяет определить расстояние между значениями признака на фоне контекста. Сделать это на обычной семантической шкале невозможно: например, абсолютно неясно, каким является расстояние между 37° и 37,5° - большим, очень большим или маленьким. Перевод этих оценок на универсальную шкалу позволяет определить расстояние на фоне заданного контекста. Например, если 37° переводится в оценку "высокая", а 37,5° - в оценку "очень высокая", то расстояние между ними равно р = "очень высокая" — "высокая". Если в том же контексте температура 36,5" переводится в "очень низкую", то расстояние между 37° определяется как р = "высокая" - "очень низкая" и, следовательно, р >р . В другом контексте расстояние между 37° и 37,5° может оказаться намного больше — больше, чем между 36,5° и 37°. Таким образом, для вычисления расстояния между оценками на фоне контекста необходимо отобразить их на универсальную шкалу и вычислить их разность, то есть универсальная шкала является абсолютной для измерения значений признака на фоне контекста.
р - Введение расстояния в контекстное пространство создает основание для конструирования внутриконтекстных схем обработки знаний и принятия решений. Работа с базами знаний и контекстами Изменение постановки задачи или предметной области, адаптация, а также добавление новой информации приводят к необходимости перестройки базы знаний УЭС. Процедуры вербализации, интерпретации, восстановления и перевода, определенные в [4], лежат в основе манипуляций УЭС с базами знаний, относящихся к разным контекстам. Благодаря процедуре вербализации УЭС автоматически формирует ноаые базы знаний. Процедура интерпретации, противоположная процедуре вербализации, позволяет перевести описания базы знаний в семантическое пространство, где они используются не только для порождения новых баз знаний, но и для сопоставления, пересечения, объединения их со знаниями из других источников. Процедура перевода позволяет автоматически переводить описания знаний из одного контекста в другой. Алгебра контекстов включает операции сужения, расширения, погружения, объединения и пересечения контекстов, которые лежат в основе перестройки баз знаний и манипулирования с ними в процессе решения многих задач принятия решений. Логика контекстов создает основания для определения схем метафорического к ассоциативного вывода, схем обобщения и вывода по аналогии. Сужение и расширение контекстов Сужая контекст, можно выделить определенные фрагменты его описания. Значение ^,..„т,..> равное норме значимости в данном кон- NORM тексте, рассматривалось как порог для определения контекстного пространства. Можно еще больше сузить пространство Uc, оставляя в описании контекста те признаки, значимость которых больше к . В пределе множество базовых понятий содержит один - центральный - признак для описания контекста (см. раздел по ассоциативным связям контекстов). Пусть С= <Е, Р, Q, F, Z> - контекст, определенный на множестве базовых признаков Р = {р} и Q= < k , ..., к > — вектор значимости базовых признаков, ставящий в соответствие каждому признаку р его значимость к в кон-тексте С. В дальнейшем будем использовать йотации [Р^ , [Q\ , [F]^ и [Z^ , где хе{Е, Р, Q, F} обозначают операции пересчета с помо- щью процедур интерпретации и вербализации элементов контекста Р, Q, F к Z при изменении других элементов контекста хе{Е, Р, Q, F}; результат этих операций будет называться приведением данных элементов контекста по х. Определим операции сужения контекста, результатами которых являются новые контексты: сужение контекста С по значимости а учета признаков R2(c,c0= , где Р - множество базовых признаков Р СР, значимости которых ni>cc; сужение контекста с по множеству признаков Р(СР Rp(c,Pt)= ; сужение контекста с по числу наиболее значимых признаков N RN[Z]p,>-где Р - множество, содержащее N наиболее значимых базовых признаков: Р СР; сужение контекста с по множеству базовых понятий Е RE(C,E)= . Операции расширения контекста необходимы для учета процессов дообучения, адаптации, введения новых понятий, погружения в больший контекст. В общем виде расширение контекста можно описать с помощью операции погружения в больший контекст. Пусть С=<Е, Pf Q, F, Z> и C'= -два контекста. Если ЕСЕ1, РсР1 и Ff(x) Определим специальные операции расширения контекста С, в результате которых появляются новые контексты: расширение контекста С по множеству базовых понятий Е E(C,E1)= [Р1шЕ1, [Q]EUE,, [Г]ШЕ1, tzw; расширение контекста С по множеству признаков Р Е(С, Р,) = <Е, Р}, [Qlp], [F]p], [Z]pi>. Объединение и пересечение контекстов . Пусть С=<Е, Р, Q, F, Z> и С'=<Е',Р', Q1, F1, Z]> — два контекста. Объединением контекстов С и С1 называется контекст C* = CUC'= р еР . Здесь 6[F] - операция приведения функции F к унимодальному виду, a Z2 пересчитан с помощью процедур вербализации к интерпретации по вектору опыта F2 и Q1 — вектор значимости признаков р e[PUP']EU i. Частный случай - операции объединения отдельно по множествам базовых понятий и признаков. Пересечением контекстов С и С называется контекст C2 = CnC' = <ЕПЕ', [РПР'1 ., Qa, F2, Z2>, где F = [[F^Op^pi, a L и Q пересчитаны с помощью процедур интерпретации и вербализации по новому вектору опыта F2. Частными случаями операции пересечения являются операции пересечения контекстов отдельно по базовым понятиям и признакам. Отображение контекстов Операция отображения контекстов может быть задана с помощью кортежа отображений Ф = <1РЕ. ФР>Фд> ФР>Ф2>" Ф с, 2. с, Здесь каждое отображение действует на свой элемент. Если отображения из заданного кортежа тождественны, при записи они будут опущены. Например, отображение <<р , «р> означает, что при отображении контекста С в С параметры Q, F и Z остаются без изменений, в то время как множество базовых понятий отображается с помощью Е—V Е , а множество признаков - с помощью Р —Е* Р . Отображение tp было введено в процедуре перевода. Оно определяется вектором перевода F12 и задает отображение множества всех лингвистических оценок (в том числе и оценок базовых понятий) из одного контекста в другой: Fu Z, -+ Z2. При переводе оценок должны измениться оценки значимости признаков. Пусть ф — отображение, задающее и изменение коэффициентов значимости признаков. Тогда отображение ф= <фЬ f'2> определяет перевод одного контекста в другой: с ----- 3----- ,са. Отображение ф показывает изменение функции опыта. Такое отображение возникает, например, после введения дополнительного опыта УЭС в виде множества каких-то обучающих примеров или в процессе адаптации УЭС. Изменение функций опыта приведет к изменению множества лингвистических оценок Z и коэффициентов значимости из Q . Пусть ф и Ф - отображения, задающие эти изменения. В
Отображение ip на практике само по себе не возникает, поскольку параметр Q является зависимым. Изменение Q при отображении контекстов вызвано присутствием другого отображения и является вторичным. Отображение ф возникает при изменении множества признаков контекста, например, при агрегировании (появлении синдромов), сужении множества признаков по значимости, расширении множества признаков в процессе дообучения. Изменение множества признаков ф влечет за собой изменение функций опыта лингвистических оценок, коэффициентов значимости. В этом случае отображение контекстов задается в виде:
Отображение ф задает изменение в множестве базовых понятий. Оно может представлять обобщение или, наоборот, уточнение понятий. При этом множества F, Q, F и Z в общем случае изменяются и отображение контекстов задается в виде:
Отображение <р может быть установлено в результате метафоры. Метафорическое отображение контекстов Известная метафора "человек - волк" устанавливает отображение "человеческого" контекста в животный. При этом возможны случаи, когда метафора поступает извне (например при анализе текста) и когда метафору формирует сама УЭС. Например, устанавливая отображение понятий контекста у сталевара при варке стали и понятий мариниста, а также отображение признаков этих контекстов, можно задать отображение контекста сталевара в контекст мариниста так, чтобы элементы Q, F и Z при этом не изменились. Для этого, измеряя с помощью аналоговых устройств параметры в печи (температуру, давление и т.д.), можно отобразить их в параметры картины моря (цвет, интенсивность волнения) на экране телевизора. Тогда полученное отображение контекстов позволит на основе анализа картины моря сделать заключение о состоянии стали. Такой пример был использован на практике. Другим примером генерирования метафор может быть установление отображения понятий при сохранении оценок наиболее значимых признаков. Например, по описанию "человек маленький, юркий, остроносый" УЭС может найти в своей памяти такой контекст, в котором некоторое понятие так же описывается через наиболее значимые признаки. Метафора "человек - мышь" может быть найдена, если в памяти УЭС есть контекст, где мышь имеет то же описание по выделенным значимым признакам. Выбор метафоры осуществляется по двум критериям: - признаки, по которым выделяются оценки, должны быть значимыми в контексте С ; - соответствующее понятие должно даваться через те же лингвистические оценки по этим признакам. Употребление метафоры типа "человек -мышь" позволяет делать некоторые выводы от- носителъно понятия из Е (человек) через оценку соответствующего понятия из Е (мышь). При этом для исходного понятия в контекст С могут переноситься оценки наиболее значимых признаков соответствующего понятия из контекста С . Например, если в дальнейшем тексте возникает фраза "серый человек", то ее вполне можно будет (при отсутствии других признаков) отнести к нашему "человек -мышь". В примере со сталью принятие решения относительно состояния моря в контексте морского пейзажа позволяет принимать аналогичные решения по состоянию стали. В общем виде метафорическое отображение контекстов может быть определено следующим образом:
Ассоциативные преобразования контекстов В известном анекдоте "спирт, пинцет, тампон, спирт, тампон, спирт, огурец, спирт, огурец, ..." приводится пример смены одного контекста (хирургического) на другой (алкоголический). Здесь понятие "спирт", являясь базовым для обоих контекстов, выполняет роль сцепления, которое по центральным понятиям или признакам, вероятно, лежит в основе ассоциативных переходов. Дальнейший переход из нового контекста осуществляется также в результате сцепления контекстов по центральному понятию или значимому в нем признаку. Определим операцию сцепления контекстов С и С по понятию О следующим образом:
Адаптация ИИ Изложенный метод формализации контекста и- автоматического порождения знаний позволяет УЭС по мере накопления опыта адаптироваться к внешнему миру. Всякий новый пример работы УЭС, имеющий варификацию, добавляется в БД УЭС и обрабатывается вместе с предшествующим опытом. Это приводит к изменению вектора опыта, корректированию семантического пространства, вычислению новых коэффициентов значимости признаков и порога значимости, изменению вектора опорных признаков и, наконец, лингвистических оценок в описании понятий в контекстном пространстве. Таким образом, по мере накопления опыта УЭС корректирует свою базу знаний и, следовательно, адаптируется к новым условиям. В качестве базовых понятий контекста могут выступать понятия, характеризующие поведение самой УЭС: используемые ею методы, приемы, тактики, стратегии. Если УЭС наращивает опыт относительно этого "поведенческого" контекста, то он может, настраиваясь на этот контекст, автоматически формировать лингвистические оценки данных понятий, корректировать их в процессе адаптации и тем самым оценивать свое собственное поведение. Такая адаптация свойственна и человеку. Только тогда, когда ЭС получит возможность самостоятельно формировать свои знания, она сможет творчески решать задачи и займет достойное место в практике. Как было показано, этого нельзя достичь без решения проблемы формализации контекста знаний. Использование опыта УЭС для формализации контекста позволило вооружить ее процедурами формирования знаний: вербализации, интерпретации, перевода, восстановления, в результате чего она получила способность самостоятельно генерировать свою БЗ. Рассмотренные операции над контекстами представляют собой средства манипулирования базами знаний. С одной стороны, это позволяет динамично перестраивать свою БЗ при изменении постановки задачи и предметной области, с другой - создает основу для формализации естественных схем принятия решений, свойственных человеку (метафорического, ассоциативного, по аналогии и т.п.). Список литературы 1, Conklin 1. HupertMt: an introduction md survey. - IEEE Compute!1, September 1W7, V.2Q, 19, pp. 17-41. 2, Ezhlcova I.B. Knowledge formation through context formallzatkori. Computer and Artificial Intelligence, Vol. 8, NoA 1989. 3, Kendall M, Stuart A. The advanced theory of statistics. London, I960. 4, Wittgenstein L. Philomphical Investigations. Oxford, 1953. 5, Ежкоьд H.B. Применение нечетких схем вывода в задачах медицинс кий диагностики. М.: АН СССР. Научный совет по комплексной пробле ме "Кибернетика". I9S0. 6, Ежкова Н.В. Универсальная шкала для представлении лингвистичес ких оценок /,■' Тр. междунар. симпоэ. по ИИ. Л., 1980. Т. Ежкова И.В. Формализация контекста на основе опыт]. Искусственный интеллект // Тр. / Тарт. гос. ун-т. 1988. 8. Ежко» И.В„ Поспелов Д.А. Принятие решений при нечетких осно ваниях. 1 Универсальны шила // И* АН СССР. Сер. техн. кнбернет. 1ЭТ7. N 6. 9. Мичн Л., Джонстон Р. Компьютер-творец / Пер. с англ. - М.: Мир, 1987. 10. Поспелов Г.С. Искусственный интеллект - основа новой информа ционной типологии. М.: Наука, 1968. 11. Поспелов Г.С., Поспелов Д.А. Искусственный интеллект - приклад ные системы Ц Знание. Сер. мат* кнбернет. Вып. 9. М., 1985. 12. Поспелов ДА. Фантазия или наука: на пути к искусственному ин теллекту. М.: Наука, 1983. 13. Симоне Дж. ЭВМ пятого поколения: компьютеры 90-х годов. М.: Фи нансы н статистика, 1985. И. Фролов А.А„ Муравьев ИЛ. Нейронные модели ассоциативной памяти. М.: Наука, 1987. 15. Элтн Дж., Кумбс М. Экспертные системы: концепции и примеры / Пер. 11НГЛ. - М.: Финансы и статистика, 19Я7. |



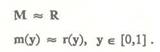


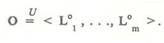





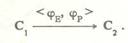

| Постоянный адрес статьи: http://swsys.ru/index.php?id=1321&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 2 за 1991 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Компьютерный тренажер для операторов технологических процессов доменного производства
- Разработка загрузчика программного обеспечения встроенной системы управления
- О программной реализации геоинформационных систем
- Целесообразность применения web-служб в распределенных автоматизированных системах военного назначения
- Эволюционная модель формирования структур виртуальных предприятий
Назад, к списку статей