Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Компонентный подход: модуль правдоподобного вывода по прецедентам
Аннотация:
Abstract:
| Авторы: Павлов А.И. (asd@icc.ru) - Институт динамики систем и теории управления СО РАН, г. Иркутск (старший научный сотрудник), Иркутск, Россия, кандидат технических наук, Юрин А.Ю. (iskander@irk.ru) - Институт динамики систем и теории управления СО РАН, г. Иркутск (доцент, зав. лабораторией), г. Иркутск, Россия, кандидат технических наук | |
| Ключевые слова: прецедент, компонентный подход, модуль вывода |
|
| Keywords: precedent, , |
|
| Количество просмотров: 16281 |
Версия для печати Выпуск в формате PDF (2.59Мб) |
Компьютерная поддержка исследователя в слабоформализованных предметных областях, связанных с процессами, представляющими опасность для человека (например производство полиэтилена в нефтехимии), является актуальной проблемой [1]. Ее актуальность главным образом обусловлена необходимостью обеспечения безопасности людей и повышением надежности оборудования, задействованных в опасных процессах.
Наиболее перспективным в данной ситуации является создание программного средства, автоматизирующего исследование динамики состояний данных технических (механических) производственных систем. Создаваемое средство автоматизации исследований должно обладать высокой универсальностью (гибкостью), то есть обеспечивать возможность решения широкого круга задач исследования (идентификация, диагностирование и прогнозирование) и настройки на определенную предметную область [2]. Наиболее эффективным способом создания подобных программных систем является компонентная сборка требуемой системы из функциональных компонентов. Технология сборки систем из компонентов – один из подходов объектно-ориентированного программирования, центральным понятием данной технологии является компонент – независимый модуль, который может быть реализован в виде исполняемого файла или динамической библиотеки. Каждый компонент реализует как минимум один интерфейс, определяющий границу взаимодействия одного компонента с другими или с программами. Интерфейс строго специфицирует поведение компонента, благодаря чему компонент может быть использован на основании описания интерфейса, без внимания к подробностям его реализации. В данной работе под компонентом системы автоматизации исследований понимается компонент, который, кроме основной функциональности, обеспечивает реализацию механизма внутренней памяти и предложенного авторами унифицированного интерфейса компонента [3]. Концептуально в архитектуре подобной системы (рис. 1) можно выделить библиотеку компонентов, содержащую компоненты с унифицированными интерфейсами, и управляющий модуль, содержащий механизм интеграции компонентов в единую систему. Использование унифицированного интерфейса позволяет перестраивать архитектуру системы исследования динамически, без внесения в код компонентов информации о межкомпонентных связях.
Среди множества методов, которые могут быть алгоритмизированы и программно реализованы в виде компонентов для системы автоматизации исследований, выделим метод (подход), основанный на изучении существующего в определенной предметной области опыта – это правдоподобный вывод по прецедентам (поиск решения по аналогии, case-based reasoning) [4]. Выбор данного метода обусловлен тем, что зачастую в областях, где требуется поддержка исследователя (например, обеспечение надежности и безопасности сложных технических систем в нефтехимии), к моменту возникновения новой проблемы уже накоплен значительный опыт решения похожих проблем, возникавших ранее на подобном оборудовании. Однако невозможность или сложность аналитической обработки этого опыта по ряду причин (например, отсутствие специалистов необходимой квалификации, экспертов и др.) приводит к невозможности эффективно использовать эти знания и реализовать их потенциал. Представление же этого опыта в виде прецедентов и его автоматизированная обработка при помощи специализированных программных систем позволяют значительно повысить эффективность его повторного использования. Решение проблемы по прецедентам основано на распознавании текущей проблемной ситуации, информация о которой представлена в виде некоего образа (прецедента), и поиске похожих образов, содержащихся в хранилище образов (базе прецедентов), с последующей их адаптацией и повторным использованием для решения задач исследования. Таким образом, можно выделить основные функции, которыми должен обладать компонент, обеспечивающий решение задач с помощью правдоподобного вывода по прецедентам. 1. Представление прецедента (формирование модели прецедента). Структура прецедента (образа) может быть произвольной, но четко выделяются две части: описание проблемы и ее решение. 2. Формирование базы (библиотеки) прецедентов на основании сформированной модели. Предполагается, что база прецедентов формируется с использованием существующего хранилища информации предметной области, например, базы данных отказов оборудования. 3. Поиск решения (правдоподобный вывод) по прецедентам. При поиске руководствуются полезностью того или иного образа (прецедента) для решения новой проблемы. Полезность аппроксимируется мерой похожести описаний образов, вычисляемой как расстояние между образами в многомерном признаковом пространстве. Компонент, реализующий описанную функциональность, содержит следующие основные моду- ли (рис. 2): · модуль моделирования прецедентов – обеспечивает возможность создания, модификации моделей прецедентов, формирования и обновления баз прецедентов на основе существующих моделей; · внутренняя память – обеспечивает хранение моделей прецедентов и самих прецедентов; · прецедентная машина вывода – позволяет осуществлять поиск прецедентов по полученному описанию; · управляющий модуль – обеспечивает взаимодействие между модулями компонента и предоставляет интерфейсы для взаимодействия с внешней по отношению к компоненту средой. Рассмотрим модули подробнее.
Модель прецедента базируется на классической модели прецедента: прецедент = <проблема, решение> [4]. Части модели представляют собой коллекции описаний свойств хранимых классов – классов хранилища данных. В процессе формирования модели прецедента пользователь посредством графического интерфейса, отображающего информацию о структуре хранилища данных, указывает свойства, составляющие описания проблемы и решения. При этом предполагается существование некоего хранилища данных со структурой, элементы которой можно использовать как основу для формирования прецедентов. Если подобное хранилище отсутствует и все знания эксперта содержатся в неявном виде, структуру хранилища предлагается создать и заполнить данными перед формированием модели. В этом случае структура модели будет соответствовать структуре хранилища данных. Внутренняя память, или память компонента. Для хранения сформированных моделей предлагается использовать хранилище данных, при этом создается хранимый класс (структура), который позволяет сохранять информацию, идентифицирующую модель (идентификатор модели), и данные модели, подвергнутые сериализации, в виде потока двоичной или символьной информации. Данная структура при ее простоте позволяет сохранять модели прецедента любой степени сложности. Перед использованием модели происходит десериализация – обратное преобразование хранимых данных. Хранение прецедентов также осуществляется в памяти компонента. Возможна синхронизация (односторонняя, в сторону базы прецедентов) хранилища данных предметной информации и базы прецедентов или формирование последней на основании анализа хранилища данных в соответствии с актуальной моделью прецедента. В процессе работы компонента база прецедентов размещается в оперативной памяти, что, хотя и приводит к определенной потере производительности в процессе загрузки базы прецедентов, однако обеспечивает высокое быстродействие в дальнейшем. Существует возможность сохранения информации о новых прецедентах, полученных в процессе работы компонента. Это обеспечивает возможность обучения как прецедентного компонента в отдельности, так и системы исследования в целом: опыт решения новой проблемы становится доступным для повторного использования в будущем. Машина вывода. На основании сформированной базы прецедентов возможно построение правдоподобного вывода путем анализа описаний прецедентов, представленных в виде наборов признаков с качественными и количественными значениями, формирования локальных и глобальных оценок близости описаний прецедентов и эталона с учетом субъективных предпочтений, задаваемых пользователем (оператором), с последующим выбором наиболее близкого прецедента. Извлечение прецедентов осуществляется в соответствии с глобальной мерой (оценкой) подобия (близости) описаний прецедентов, вычисляемой как расстояние между прецедентами в признаковом пространстве. При вычислении расстояния каждому прецеденту ставятся в соответствие векторы (дескрипторы) описания: бинарные (…01001…) или состоящие из кортежей ({…,Свi,…} типа Свi=<н,з,в, о>, где н – наименование свойства; з – его значение; в – важность или информационный вес свойства; о – ограничение на интервал допустимых значений). Ограничение определяет интервал значений, в рамках которого значение свойства может определять значение меры подобия, при выпадении значения свойства за этот интервал значение меры подобия равно 0. Выбор вида вектора происходит в зависимости от сложности описания прецедента: типов признаков (детерминированных или логических) и наличия иерархии свойств. Бинарные векторы используются в том случае, если необходимо проанализировать отсутствие или присутствие определенных признаков в описании прецедентов, а кортежи – если признаки имеют иерархическую структуру (например, иерархия типа: процесс – параметр процесса с числовым значением) или важны числовые (количественные) значения этих признаков. Вычисление расстояния между прецедентами осуществляется при помощи данных векторов и метрики Миньковского [5]: Данная метрика является обобщением метрик городских кварталов (используется при обработке бинарных векторов, при этом p=1) и евклидова расстояния (используется при обработке множеств кортежей, при этом p=2). Результатом работы машины вывода является список прецедентов с оценками близости. Управляющий модуль обеспечивает взаимодействие между модулем моделирования, машиной вывода и внутренней памятью, публикацию результатов работы машины вывода с возможностью выбора, назначения и модификации (адаптации) решения и сохранение пересмотренного прецедента в базе прецедентов. Основная его функция – обеспечение предоставляемых компонентом интерфейсов, в том числе и унифицированного. Сложность и многообразие задач в различных областях, связанных с опасными для человека и окружающей среды процессами, обусловливает необходимость проектирования и разработки специализированных интеллектуальных прикладных систем на основе изучения существующего опыта. Перспективность данного направления подтверждается примерами успешного решения задач планирования, диагностики, проектирования и подбора персонала в таких областях, как электронная коммерция и синтез программного обеспечения, авиация, атомная энергетика и др. Однако в большинстве случаев для решения подобных задач в конкретной предметной области создается отдельная программная система, что является неэффективным и затратным. Компонентный подход позволяет значительно повысить эффективность процесса разработки программных систем путем создания расширяемого и настраиваемого компонентного программного обеспечения. Система автоматизации исследований, разрабатываемая в соответствии с этим и содержащая описанный прецедентный компонент, позволит эффективно решать задачи планирования, диагностики, проектирования. Компонент, реализующий прецедентный подход, использован при решении задачи идентификации технического состояния уникальных машин и конструкций в интеллектуальной системе поддержки принятия решений при определении причин отказов и аварий в нефтехимической промышленности [6]. Список литературы 1. Берман А.Ф. Деградация механических систем. – Новосибирск: Наука, 1998. 2. Берман А.Ф., Николайчук О.А., Павлов А.И., Юрин А.Ю. Моделирование свойств адаптивности программной системы. // Матер. Всерос. конф.: Инфокоммуникационные и вычислительные технологии и системы. – Улан-Удэ, 2003. 3. Павлов А.И. Подход к автоматизации исследования надежности механических систем. // Матер. V Междунар. науч.-технич. конф.: Информационно-вычислительные технологии и их приложения. – Пенза, 2007. 4. Aamodt A., Plaza E. Case-Based reasoning: Foundational issues, methodological variations, and system approaches. AI Communications, vol. 7, no. 1, 1994. 5. Bergmann R. Experience Management. Lecture notes on artificial intelligence, vol. 2432, 2002. 6. Берман А.Ф., Николайчук О.А., Павлов А.И., Юрин А.Ю. Интеллектуальная система поддержки принятия решений при определении причин отказов и аварий в нефтехимической промышленности. // Автоматизация в промышленности. – 2006. – № 6. |
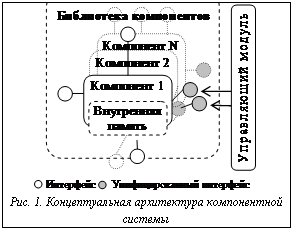 Таким образом, функциональность системы автоматизации исследований напрямую зависит от компонентов, составляющих ее библиотеку.
Таким образом, функциональность системы автоматизации исследований напрямую зависит от компонентов, составляющих ее библиотеку.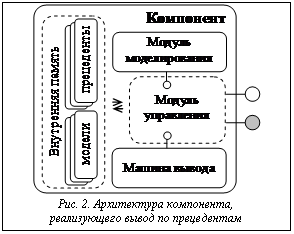 Модуль моделирования. Решение задач исследования на основе прецедентов требует создания моделей прецедента под эти задачи. В случае построения базы прецедентов на основании существующего хранилища данных предметной области наличие подобной модели позволит понизить избыточность этой базы путем отсечения (исключения из модели прецедента) неинформативных (нерелевантных решаемой задаче) признаков (данных).
Модуль моделирования. Решение задач исследования на основе прецедентов требует создания моделей прецедента под эти задачи. В случае построения базы прецедентов на основании существующего хранилища данных предметной области наличие подобной модели позволит понизить избыточность этой базы путем отсечения (исключения из модели прецедента) неинформативных (нерелевантных решаемой задаче) признаков (данных).| Постоянный адрес статьи: http://swsys.ru/index.php?id=1581&like=1&page=article |
Версия для печати Выпуск в формате PDF (2.59Мб) |
| Статья опубликована в выпуске журнала № 3 за 2008 год. | |
| Статья находится в категориях: Разработка программных приложений | |
| Статья относится к отраслям: Вычисления | |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Средства прототипирования прецедентов в проектировании автоматизированных систем
- Модель интерактивной обучающей системы
- Система назначения персонифицированного лечения по аналогии на основе гибридного способа извлечения прецедентов
- Программная реализация модуля анализа данных на основе прецедентов для распределенных интеллектуальных систем
- Препроцессорная обработка множеств прецедентов для построения решающих функций в задачах классификации
Назад, к списку статей