Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Многомерная конвейеризация циклов
Аннотация:
Abstract:
| Авторы: Вьюкова Н.И. (niva@niisi.msk.ru) - НИИСИ РАН, г. Москва, г. Москва, Россия, Самборский С.В. (sambor@niisi.msk.ru) - НИИСИ РАН, г. Москва, г. Москва, Россия | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 12648 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
Для эффективного использования параллелизма современных суперскалярных и VLIW-процессоров при трансляции циклов широко применяется программная конвейеризация циклов, основанная на совмещении в одной итерации оптимизированного цикла команд, относящихся к разным итерациям исходного цикла. В данной статье рассмотрены ограничения программной конвейеризации одиночных циклов и показано, как они могут быть преодолены в ситуации, когда имеется гнездо вложенных циклов. Перечислим понятия, связанные с программной конвейеризацией циклов: DDG – граф зависимостей между командами цикла с дугами, помеченными парой значений: lat (латентность) и dist (дистанция); контуры – циклы в DDG; зависимости, образующие контуры, называются рекуррентными; периодическое расписание цикла; II – интервал запуска, то есть число тактов, через которое запускается очередная итерация конвейеризованного цикла; ResMII – нижняя оценка II, связанная с конечностью числа доступных на каждом такте ресурсов (функциональных устройств, шин, полей в командном слове и т.п.); RecMII – нижняя оценка II, связанная с наличием рекуррентных зависимостей между командами цикла. Рассмотрим пример (1), иллюстрирующий ситуацию, когда эффективная программная конвейеризация цикла невозможна (здесь и далее оператор завершения цикла ENDDO опущен для краткости): DO J=2, N A(J)=SQRT(A(J-1)) (1) Пусть процессор может запускать операцию извлечения квадратного корня (SQRT) на каждом такте, а ее латентность равна 4. Аргумент SQRT зависит от результата на предыдущей итерации, следовательно, в графе зависимостей имеется контур с суммарной дистанцией 1 и суммарной латентностью 4. В данном случае при отсутствии существенных ограничений по ресурсам (ResMII=1) цикл не может быть эффективно конвейеризован из-за рекуррентных зависимостей (RecMII=4); соответственно, II≥4. Таким образом, если в каком-либо контуре графа зависимостей присутствуют дуги с большой латентностью, может оказаться, что RecМII>ResМII. В этом случае ограничения по зависимостям не позволят эффективно использовать ресурсы процессора. Можно показать, что простая развертка цикла не исправит ситуацию. Тем не менее, когда мы имеем дело с гнездом циклов, эффективность вычислений может быть повышена за счет параллельного выполнения итераций объемлющих циклов. Зависимости в гнезде вложенных циклов Усложним пример (1), добавив внешний цикл. DO I=2, N DO J=2, N (2) A(I,J)=SQRT(A(I,J-1)) В графе зависимостей внутреннего цикла есть контур, содержащий длительную операцию SQRT, и II не может быть меньше латентности этой операции. Однако теперь в примере есть независимые операции. Определим пространство итераций как набор точек, соответствующих итерациям исходного цикла. Размерность пространства равна числу вложенных циклов, а координаты точек определяются индексами циклов, для которых выполняется эта итерация. Если верхние и нижние границы циклов не зависят от индексов объемлющих циклов и шаг цикла всегда равен 1, пространство итераций есть множество целочисленных точек внутри и на границе параллелепипеда с ребрами, параллельными координатным осям. Хотя эти условия необязательны, для простоты рассмотрим только такие пространства итераций. Для команд, принадлежащих гнезду циклов, дистанция зависимости определяется как вектор смещения в пространстве итераций между итерациями, соответствующими этим командам. Порядок на координатах соответствует вложенности циклов, самым младшим является индекс внутреннего цикла. У вектора дистанции могут присутствовать отрицательные координаты, но в предположении, что шаги всех циклов положительны, этот вектор должен быть лексикографически неотрицательным, то есть его старшая ненулевая координата (если таковая имеется) положительная. Этот факт обусловлен тем, что исходное гнездо циклов задает лексикографический порядок обхода пространства итераций, а любая зависимость направлена вперед в этой последовательности. При корректных преобразованиях гнезда циклов дистанции зависимостей должны оставаться лексикографически неотрицательными. В противном случае возникнет зависимость от еще не выполненных вычислений. Суммарная дистанция по контуру в графе зависимостей также становится векторной. При вычислении RecМII для конвейеризации внутреннего цикла существенны только те контуры в графе зависимостей, у которых дистанция нулевая по всем координатам, кроме соответствующей внутреннему циклу. В примере (2) имеем один контур в DDG с дистанцией (0, 1) по I и J соответственно. Переставив заголовки циклов, что корректно для примера (2), получим следующий код: DO J=2,N DO I=2,N (3) A(I,J)=SQRT(A(I,J-1)) Суммарная дистанция единственного контура в DDG стала равной (1, 0), и этот контур больше не учитывается при вычислении RecMII, следовательно, RecMII=0, то есть конвейеризация ограничивается количеством доступных ресурсов. Тем не менее, подобный подход нельзя считать ни эффективным, ни универсальным. Во-первых, проанализируем работу кэш-памяти данных. Для определенности будем считать, что в строчку кэша умещается 4 последовательных элемента массива A, например, A(1,1), A(1,2), A(1,3), A(1,4). Кроме того, считаем, что кэш небольшой: ни строка массива A, ни столбец не могут поместиться в него целиком. Тогда в исходном примере (2) промахи в кэш происходят только при записи A(I,J), причем всего один раз на 4 итерации, в среднем 1/4 промаха. После перестановки циклов промахи происходят уже на каждой итерации, а для одной из 4 итераций внешнего цикла будет происходить по 2 промаха на итерацию внутреннего цикла, то есть в среднем 5/4 промаха, в 5 раз хуже, чем без перестановки. Во-вторых, перестановка циклов не всегда позволяет снять зависимости. Рассмотрим пример (4), в котором индексы I,J используются симметрично. DO I=2, N DO J=2, N (4) A(I,J)=SQRT(A(I,J-1)*A(I-1,J)) В DDG имеем два контура с суммарными дистанциями (0, 1) и (1, 0). Перестановка заголовков превращает их в (1, 0) и (0, 1) соответственно, поэтому она бесполезна. Чтобы использовать параллелизм гнезд циклов, в общем случае применяется метод гиперплоскостей, предложенный в [1]. Суть метода заключается в том, что выбирается такая гиперплоскость, проходящая через начало координат в пространстве итераций, где все векторы дистанций зависимостей находятся относительно нее в одном полупространстве. Пространство итераций можно разбить гиперплоскостями, параллельными выбранной, на слои одинаковой толщины. Толщина слоев выбирается как можно большая, но так, чтобы итерации в пределах одного слоя были независимыми. Вычисления по слоям делаются последовательно, но внутри слоя все итерации могут выполняться параллельно. Перестановка циклов – частный случай метода гиперплоскостей. Для примера (4) метод гиперплоскостей может заключаться в обходе пространства итераций по диагоналям (I+J=const): итерации, лежащие на одной диагонали, можно конвейеризовать без задержек, вызванных зависимостями. Тем не менее, проблема эффективности использования кэш-памяти остается. Если N намного больше числа строчек кэша, то, какой бы порядок выполнения итераций, лежащих на одной диагонали, мы ни выбирали, в среднем произойдет не меньше одного промаха на итерацию. (Наилучший порядок, по-видимому, последовательный, причем чередующийся, чтобы соседние диагонали обрабатывались навстречу друг другу – змейкой.) Проблемы с эффективностью кэша вызваны тем, что, как при перестановке циклов, так и при обходе по слоям в методе гиперплоскостей порядок обхода пространства итераций меняется глобально. Но первоначальный порядок, отраженный в исходной записи гнезда циклов, возможно, был выбран программистом сознательно, с учетом архитектуры компьютера, в частности, устройства кэша. Развертка внешнего цикла В последнее время стали популярны методы, основанные на развертке какого-либо объемлющего цикла в гнезде вложенных циклов. Данная разработка основана на подходе, изложенном в [2]. Рассмотрим его применение на примере (4). Сначала внешний цикл заменяется парой вложенных циклов, где внутренний выполняется небольшое фиксированное число раз: DO K=2,N,4 DO I=K,K+3 DO J=2,N A(I,J)=SQRT(A(I,J-1)*A(I-1,J)) Здесь выбрана кратность развертки, равная четырем, и для простоты будем считать, что N-1 кратно четырем. Далее новый короткий цикл и прежний внутренний цикл меняются местами: DO K=2,N,4 DO J=2,N DO I=K,K+3 A(I,J)=SQRT(A(I,J-1)*A(I-1,J)) Заметим, что одна из зависимостей этого цикла неоднородна: зависимость от вычисления A(I-1,J) имеет разные векторы дистанции для первой итерации цикла по I и для последующих. Однако это обстоятельство не помешает, поскольку на следующем шаге внутренний цикл будет полностью развернут, после чего однородность восстанавливается (рис. 1).
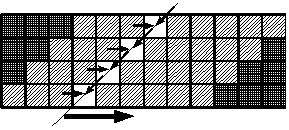
Рис. 1. Развертка внешнего цикла для примера (4). Зависимости В новом графе зависимостей 5 контуров. Один имеет суммарную дистанцию (1, 0) и не требует учета; остальные связаны с зависимостью от вычисления A(I,J-1) и имеют те же суммарные значения латентности и дистанции, как и в первоначальном цикле. Значение RecМII не изменилось, но в новом цикле всех операций стало в 4 раза больше. Если предположить, что значение RecМII превышало ResМII не более чем в 4 раза, в новом цикле оно уже не ограничивает конвейеризацию. Очевидно следующее: если в первоначальном цикле требовалось зачитать 2 строчки кэша на 4 итерации, в развернутом цикле требуется 5 строчек кэша на 4 итерации, равные 16 первоначальным итерациям. Таким образом, получен выигрыш около 37 % . Рис. 2. Дистанции зависимостей в развернутом цикле для примера (5) Сложности с перестановкой циклов Попробуем, действуя аналогичным образом, развернуть внешний цикл в примере (5): DO I=2,N DO J=2,N (5) A(I,J)=SQRT(A(I,J-1)*A(I-1,J+1)) Сначала внешний цикл нужно заменить парой вложенных циклов: DO K = 2, N, 4 DO I = K, K+3 DO J = 2, N A(I,J) = SQRT( A(I,J-1) * A(I-1,J+1)) Далее новый короткий цикл и прежний внутренний следует поменять местами. Однако цикл, который должен быть развернут, нельзя переставить с циклом по J, поскольку столбик из четырех итераций зависит от соседних столбиков (рис. 2). Формально затруднение возникает потому, что дистанция зависимости по A(I-1,J+1) из (0, 1, -1) превращается в (0, -1, 1), а этот вектор лексикографически отрицателен, то есть преобразование некорректно. Метод гиперплоскостей подсказывает естественное решение – обходить по диагоналям полоску в пространстве итераций, соответствующую одной итерации цикла по K. Полоска разбивается на три области (две треугольные и одна в форме параллелограмма, рис. 3), соответствующие трем последовательным циклам. Треугольные области можно обходить в любом корректном порядке, поскольку они маленькие, а параллелограмм – по диагональным слоям. Цикл обхода слоя оказывается внутренним и может быть развернут. Получаем цикл, готовый к конвейеризации. При реализации этого подхода возникают некоторые сложности, а именно: непонятно, из каких соображений следует исходить, выбирая слой (рис. 4). Наименьшее значение II при конвейеризации простого цикла, как известно, не меньше ResMII и RecMII. Но минимальное значение II необязательно равно их максимуму; II может зависеть от структуры зависимостей между операциями, даже если RecMII Чем меньше зависимостей (и чем больше их дистанции), тем больше свободы в расположении команд и, следовательно, больше возможностей оптимального использования ресурсов процессора. Вместе с тем излишнее увеличение дистанции ведет либо к использованию большего числа регистров, либо к удлинению пролога и эпилога цикла – оба варианта нежелательны.
Рис. 3. Правильный обход полоски в пространстве итераций
Рис. 4. Варианты слоев
Рис. 5. Зависимости в развернутом цикле для примера (5) Оказывается, эта задача может быть решена самим методом конвейеризации. Выполним (формально некорректную) операцию перестановки циклов с последующей разверткой, сохраняя при этом старую структуру зависимостей. Векторы дистанций после перехода к новым координатам могут стать лексикографически отрицательными (рис. 5). Запустим процедуру конвейеризации. Скалярные дистанции зависимостей для конвейеризации – младшие координаты векторных дистанций с нулевыми остальными координатами. Тот факт, что некоторые из них отрицательны, заставит конвейеризатор правильно выбрать такие итерации исходного цикла, из которых возможно исполнение команд в итерации конвейеризованного, то есть самому построить оптимальный слой. При этом треугольники, которые возникали при разбиении полоски на три области, – не что иное, как пролог и эпилог конвейеризованного цикла. Разумеется, это соответствие приблизительное, так как конвейеризатор оперирует командами, а не итерациями исходного цикла. Таким образом, алгоритм программной конвейеризации удачно дополняет развертку внешнего цикла в гнезде циклов при условии, что он способен обрабатывать DDG с отрицательными дистанциями. Мы рассмотрели примеры, когда гнездо циклов состоит из двух циклов – внутреннего, который в конечном итоге конвейеризируется, и внешнего, который можно развернуть. При наличии трех или более вложенных циклов возникают дополнительные вопросы. Какой цикл лучше развертывать, если в гнезде более одного объемлющего цикла? Имеет ли смысл развертывать более одного объемлющего цикла? На второй вопрос ответ, по-видимому, утвердительный. Например, в гнезде циклов DO K=2,N DO I=2,N DO J=2,N A(K,I,J)=SQRT(A(K,I-2,J+1)*A(K-2,I,J+1)) имеем зависимости с дистанциями (0, 2, -1) и (2, 0, -1). При развертке любого из циклов по K или по I в четыре раза возникнет описанная выше проблема с перестановкой этого цикла и цикла по J (хотя решение этой проблемы известно, но оно может иметь отрицательные последствия, например, в виде использования большего числа регистров). Если же развернуть оба цикла по K и по I в два раза (то есть в целом в те же четыре раза), зависимости не препятствуют перестановке циклов. Важный момент: если объемлющих циклов несколько, они могут не переставляться между собой. Рассмотрим следующий пример, в котором по тем или иным причинам требуется развернуть цикл по K: DO K=2,N DO I=2,N DO J=2,N A(K,I,J)=SQRT(A(K-1,I+1,J)) Здесь всего одна зависимость с дистанцией (1, -1 ,0). Очевидно, что она не позволяет переставлять местами циклы по K и I. Таким образом, заменив цикл по K на два цикла, мы не сможем сделать новый цикл внутренним, так как он также не переставляется с циклом по I. Если развертываемый цикл нельзя переставить хотя бы с одним из промежуточных циклов, можно поступать так же, как уже предлагалось, – использовать метод, родственный методу гиперплоскостей, внутри соответствующей полоски. При этом снова возникает задача выбора развертываемого слоя. Опять попробуем переложить решение этой задачи на алгоритм конвейеризации, для чего потребуется несколько ее обобщить. Будем считать, что развертываются все объемлющие циклы (для неразвертываемых циклов кратность развертки единичная). Выделяем в пространстве итераций параллелепипед со сторонами, равными кратности развертки соответствующего цикла, – ячейку развертки. Исполнять во внутреннем цикле все итерации исходного цикла, соответствующие одной ячейке, нельзя – этому помешают зависимости, которые не позволяли переставлять циклы. Тем не менее, можно снабдить все итерации одной ячейки векторами сдвига, определяющими, в какой итерации развернутого цикла относительно некоторой текущей должна выполняться данная итерация исходного цикла. Заметим, что слой, то есть множество итераций, которые можно исполнять в теле внутреннего цикла, соответствует ячейке по модулю кратности развертки (если слой «намотать» на ячейку, она будет покрыта вся ровно по одному разу). Далее строим общий DDG для всех команд всех итераций, входящих в одну ячейку. Дистанции между командами будут векторными и зависящими от неопределенных сдвигов между итерациями. Обычные алгоритмы конвейеризации неспособны работать с неопределенными векторными дистанциями. Однако среди методов конвейеризации есть подход, основанный на формулировке ее в виде задачи целочисленного линейного программирования (ЦЛП) [3]. ЦЛП-подход можно обобщить на случай векторных дистанций. Важно, что добавленные неопределенные дистанции оставят все неравенства в ЦЛП-формулировке линейными, так как дистанции в них всегда входят в свободные члены, а не в коэффициенты при переменных. Теперь решение ЦЛП-задачи автоматически даст не только оптимальный конвейеризованный цикл, но и множество итераций исходного цикла, которые должны исполняться вместе, то есть искомый слой, наилучшим образом подходящий для конвейеризации. Разумеется, следует стремиться к тому, чтобы этот слой получился по возможности плотнее для уменьшения прологов и эпилогов циклов. Достичь этого можно как явными ограничениями на сдвиги (возможно, жертвуя оптимальностью), так и заданием правильно подобранной целевой функции. Хотя данный подход представляется очень интересным, он пока недостаточно исследован. Преждевременно утверждать, что получаемые ЦЛП-задачи будут настолько простыми, что их можно было бы эффективно решать. Кроме увеличения числа переменных в ЦЛП-задаче, в нее добавляются большие коэффициенты, соответствующие интервалам запуска (II) объемлющих циклов (они берутся произвольными, но достаточно большими). Последнее обстоятельство плохо сказывается на работе алгоритмов, используемых в ЦЛП. Можно снабдить неопределенными векторными сдвигами не итерации исходного цикла, входящие в одну ячейку развертки, а отдельные команды. Увеличение числа переменных еще усложнит ЦЛП-задачу, но, возможно, это позволит найти более удачный конвейеризованный цикл. В этом варианте данный подход можно назвать многомерной конвейеризацией. Осталось ответить на несколько практических вопросов. Во сколько раз следует развертывать внешний цикл? Понятно, что общая кратность развертки должна быть не меньше RecMII/ResMII, чтобы в развернутом теле цикла RecMII был не больше ResMII. Однако неизвестно, насколько не меньше. Если объемлющих циклов более одного, как именно следует разложить общую кратность развертки в произведение кратностей разверток отдельных циклов? Чтобы ответить на этот вопрос, надо оценить все последствия использования развертки (или разверток) для последующей конвейеризации внутреннего цикла. Следует экспериментально перебрать все разумные варианты, выполняя конвейеризацию и оценивая результат. Возможна адаптивная реализация, когда компилятор сгенерирует несколько вариантов кода для цикла, а во время выполнения случайным образом выбирается вариант и измеряется время его работы. В дальнейшем выбирается оптимальный вариант или варианты. Более традиционный путь – статическая оценка полученного кода в компиляторе. Очевидно, что, чем меньше отношение II к кратности развертки, тем лучше (меньше тактов требуется на итерацию исходного цикла). С другой стороны, необходимо учитывать эффективность работы кэш-памяти. Как оценивать вариант трансляции сразу по обоим критериям, выраженным в разных терминах и единицах? Ранее при анализе преобразований циклов вручную оценивались обращения в память с точки зрения попадания или непопадания в кэш данных. Этот процесс несложно формализовать, и тогда компилятор может разным обращающимся в память командам приписывать различные латентности в зависимости от того, произойдет ли при обращении в память попадание в кэш или вероятен промах [4]. Оптимальный конвейеризованный вариант строится с использованием этих разных латентностей. При вычислении его II уже учтены оба критерия. Разумеется, кроме оценки, получен и лучший код по сравнению с тем, при построении которого латентности всех обращений в память считались одинаковыми. Осталось заметить, что для обращений в память существенны не только латентность промахов в кэш, но и их общее количество. Даже когда за счет удачной конвейеризации удалось все обращения в память, вызывающие промахи, запланировать таким образом, чтобы они по отдельности не задерживали вычисления, механизм работы с памятью может не справиться с этим количеством обращений. Выход видится в учитывании пропускной способности памяти как ресурса. Список литературы 1. Lamport Leslie. The Parallel execution of DO loops, Communications of ACM, 17(2):83–93, 1974. 2. Carr Steve, Ding Chen, Sweany Philip. Improving Software Pipelining with Unroll-and-Jam, Proceedings of the 29th Hawaii International Conference on System Sciences (HICSS'96), Vol. 1: Software Technology and Architecture HICSS'96, 1996. 3. Самборский С.В. Формулировка задачи планирования линейных и циклических участков кода. // Программные продукты и системы. – 2007. – № 3. 4. Ding Chen, Carr Steve, Sweany Phil. Modulo Scheduling with Cache Reuse Information, Proceedings of the Third International Euro-Par Conference on Parallel Processing Euro-Par'97, 1997. |




| Постоянный адрес статьи: http://swsys.ru/index.php?id=1602&page=article |
Версия для печати Выпуск в формате PDF (8.40Мб) |
| Статья опубликована в выпуске журнала № 4 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Механизм контроля качества программного обеспечения оптико-электронных систем контроля
- Автоматизированная информационная система маркетолога
- Система программного обеспечения единого технико-программного комплекса для гибких автоматизированных производств механообработки
- Календарные расчеты на калькуляторе
- Построение тестов для базовых функций встраиваемых операционных систем
Назад, к списку статей