Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Программное обеспечение для разработки моделей нечетких систем автоматического управления
Аннотация:
Abstract:
| Авторы: Тачков А.А. (tachkov@bmstu.ru ) - НУЦ «Робототехника» МГТУ им. Н.Э. Баумана (начальник отдела «Автоматизированные транспортные системы»), Москва, Россия, кандидат технических наук, Калиниченко С.В. () - | |
| Ключевые слова: алгоритм трансляции, продукционные правила, типовые функции принадлежностей, логико-лингвистические модели |
|
| Keywords: , condition-action rules, , |
|
| Количество просмотров: 14878 |
Версия для печати Выпуск в формате PDF (3.60Мб) |
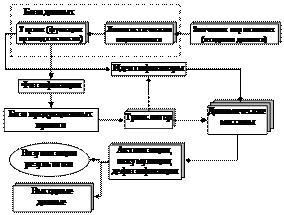
При проектировании систем автоматического управления велика роль динамических исследований – оценки точности выполнения операций, управляемости и устойчивости при отклонениях параметров элементов системы от номинальных значений. Для их проведения в классе интеллектуальных систем управления разрабатываются логико-лингвистические модели на основе теории нечетких множеств. При этом приходится сталкиваться с проблемой выбора среды разработки и отладки таких моделей. Специфика ряда задач зачастую не позволяет использовать существующие решения типа Matlab, LabView, Fuzzy System Component и другие, особенно в случаях, когда требуется кардинальная перестройка модели без перекомпиляции проекта. Результаты, полученные с их помощью, не всегда могут быть использованы в других пользовательских приложениях. Поэтому удобное для практики решение заключается в разработке автономного модуля в виде DLL-библиотеки, подключаемой к объектно-ориентированным средам программирования. Предлагаемый программный модуль выполняет следующие функции: · оперативно формирует входные и выходные лингвистические переменные, термы (функции принадлежности); · оперативно формирует, пополняет и редактирует базы нечетких знаний в интерактивном режиме; · задает правила на языке, близком к естественному («ЕСЛИ … ТО….»); · позволяет оперативно отлаживать базы знаний и осуществлять их настройки; · проверяет правила при помощи синтаксического анализатора; · осуществляет визуализацию результата выполнения правил из сформированной базы; · сохраняет созданную модель в файл, а также считывает ее из файла; · пошагово выполняет продукционные правила. Модуль поддерживает тип моделей MIMO (multi-input multi-output), логические операции И, ИЛИ, связанные с лингвистическими переменными, реализует классический метод максимина (max-min) при преобразовании функций принадлежности термов выходных лингвистических переменных, а также осуществляет импорт входных значений из внешней программы и экспорт результатов в нее. На рисунке 1 представлена структурная схема модуля, отражающая взаимодействие его отдельных блоков: базы данных, базы продукционных правил, транслятора, блока логического вывода.
Рис. 1. Структурная схема модуля База данных имеет древовидную структуру и хранит указатели на соответствующие объекты: TVariable (лингвистическая переменная) и TFuzzySet (нечеткое множество). Все лингвистические переменные разделены на входные и выходные, поэтому дерево содержит два родительских узла – «Входы» и «Выходы». Ветви, содержащие указатели на TFuzzySet, в свою очередь, являются дочерними по отношению к соответствующим узлам лингвистических переменных. Нечеткие множества в модуле задаются типовыми функциями принадлежностей (Z-, S-, П-, Л-типа) по двум–четырем точкам.
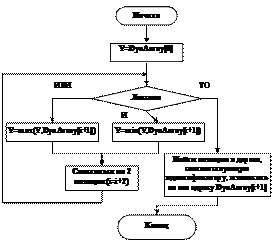
Рис. 2. Блок-схема активизации одного правила Формирование базы продукционных правил осуществляется построчным синтаксическим вводом в специальное окно редактирования. Такой ввод более приближен к естественному языку. Отдельно взятая строка представляет собой продукционное правило, антецедентами которого выступают соответствующие термы входных лингвистических переменных, а консеквентом – терм выходной переменной. В качестве логических операторов, связывающих несколько антецедентов в правиле, используются операции И, ИЛИ, операция НЕ зарезервирована. По мнению авторов, использование операции НЕ усложняет обработку правил, и в этом случае проще использовать термы новой лингвистической переменной, противоположной исходной по смыслу. С позиции человеческой логики, например, выражение «неопасно слева» эквивалентно «безопасно слева», и тогда математическая интерпретация входной переменной может быть представлена в виде X=1–X*, где X* – множество точек, описывающее исходную лингвистическую переменную. Одно из правил синтаксиса заключается в единственности консеквента во введенной строке. Данное правило введено для упрощения алгоритма трансляции при активизации базы продукционных правил, так как, например, для второго консеквента проще организовать ввод еще одного правила с тем же набором антецедентов. База правил может иметь следующий вид: ЕСЛИ ЦельСлева ТО ВлевоМедленно ЕСЛИ ЦельСправа ТО Вправо ЕСЛИ ЦельПрямо И ОпасностьПрямо ТО ВлевоБыстро В начале трансляции лексемы каждой строки считываются в список и передаются в транслятор, осуществляющий проверку на их допустимость и порядка следования. Если ошибок не обнаружено, происходит дальнейшая трансляция в динамический массив целого типа данных, длина которого определяется количеством лексем в строке. Антецеденты передаются в массив в виде номеров ветвей в дереве, являющихся идентификаторами, а операторы И, ИЛИ, ТО в виде отрицательных констант. По окончании трансляции всех правил функция анализа процесса трансляции возвращает значение логической истины. В случае возникновения ошибок формируется лист, в который заносится информация об ошибке. Трансляция всегда проводится до конца с регистрацией всех возникших ошибок, что минимизирует время, затрачиваемое на отладку правил. Конечным ее результатом является формирование n-динамических векторов, где n – количество продукционных правил. Логический вывод осуществляется путем агрегирования (свертка массива, вычисление значения степени истинности правила) и аккумуляции всех правил (формирование результирующей функции для каждой переменной в отдельности). Динамический массив для правила, приведенного выше, может быть представлен следующим образом:
Такая структура массива позволяет легко формализовать процесс определения степени истинности каждого правила в соответствии с блок-схемой (рис. 2). Полученные значения степеней истинности каждого правила позволяют провести min-активизацию, при этом результирующая функция для каждой выходной переменной принимает минимальное значение из соответствующей степени истинности правила и исходной функции принадлежности указанной выходной переменной. В результате аккумуляции находится общая функция принадлежности для выходной переменной по всем термам. Нахождение четкого значения итогового расплывчатого множества осуществляется по методу центра тяжести. В режиме отладки для визуализации результатов выполнения алгоритмов, а также оценки их работы создаются диаграммы по числу выходных переменных. Каждая из диаграмм отображает результат аккумуляции и дефаззификации. Графический интерфейс модуля представлен двумя формами: главной и вспомогательной диалоговой, применяемой при добавлении новых переменных и термов. Визуальные компоненты главной формы распределены по трем закладкам: «Функции принадлежности», «Правила» и «Отладка» таким образом, чтобы обеспечить пользователю последовательность разработки и удобство в эксплуатации. Первая содержит дерево базы данных, хранящее указатели на объекты TVariable и TFuzzySet, поля редактирования характеристик функций принадлежности, а также диаграмму, отображающую ансамбль термов для одной лингвистической переменной. Вторая – окна для ввода правил и отображения возникших ошибок во время трансляции, а также кнопку ее запуска. В последней закладке располагаются динамически создаваемые диаграммы по количеству выходных переменных, панель управления процессом отладки и список правил отлаживаемой базы. Каждая закладка соответствует своему этапу проектирования модели, обеспечивая определенную логику разработки. Перемещаясь между ними, пользователь может оперативно просматривать и менять настройки лингвистических переменных, термов, увеличивать или уменьшать число правил. Изменяя значения входных величин при помощи панели управления процессом отладки, можно исследовать веса каждого из правил в пошаговом режиме, а также определять четкие значения выходных переменных. Все операции отладки визуализированы. Испытания DLL-библиотеки проводились на базе программного обеспечения, работающего совместно со средой имитационного моделирования ПК МВТУ 3.5, при исследовании работы нечетких регуляторов. Результаты компьютерного моделирования подтвердили эффективность алгоритмов, заложенных в модуль, и правильность его функционирования, а также высокую скорость выполнения операций. Литература 1. Ложников П.С., Михайлов Е.М. Обеспечение безопасности сетевой инфраструктуры на основе операционной системы Microsoft. – М.: Изд-во Бином, 2008. 2. Леонов Д.Г., Лукацкий А.В., Медведовский И.Д., Семьянов Б.В. Атака из Internet. – М.: Солон-Р, 2002. 3. Ларичев В.Д., Бембетов А.П. Налоговые преступления. – М.: Экзамен, 2001. |
| Постоянный адрес статьи: http://swsys.ru/index.php?id=2024&page=article |
Версия для печати Выпуск в формате PDF (3.60Мб) |
| Статья опубликована в выпуске журнала № 1 за 2009 год. [ на стр. 60 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Система автоматизированной разработки учебно-методических комплексов на основе многомерных логических регуляторов
- Информационная поддержка принятия решений при возникновении аварийной ситуации на объектах газопровода на основе продукционных правил
- Интеллектуально-экспертный метод определения оптимального маршрута транспортировки продукции
Назад, к списку статей