Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Параллелизация гидродинамических расчетов на блочно-структурированных сетках
Аннотация:Рассматриваются некоторые особенности эффективного применения технологии MPI при решении ресурсоемких задач вычислительной гидродинамики на кластерных системах с использованием блочно-структурированных расчетных сеток. Даны рекомендации по организации межпроцессорного обмена данными для повышения эффективности распараллеливания.
Abstract:We discuss some features of effective usage of the MPI technology to solve resource-demanding CFD problems on cluster systems using block-structured computational grids. Recommendations are given for arrangement of the inter-process data exchange to increase the parallelization efficiency.
| Авторы: Смирнов Е.М. (aero@phmf.spbstu.ru) - Санкт-Петербургский государственный политехнический университет, Зайцев Д.К. (aero@phmf.spbstu.ru) - Санкт-Петербургский государственный политехнический университет, Якубов С.А. (aero@phmf.spbstu.ru) - Санкт-Петербургский государственный политехнический университет | |
| Ключевые слова: блочно-структурированные сетки, численное моделирование, гидродинамика, параллельные вычисления |
|
| Keywords: block-structured grids, numerical simulation, hydrodynamics, parallel computing |
|
| Количество просмотров: 16153 |
Версия для печати Выпуск в формате PDF (4.21Мб) |
Расчеты сложных турбулентных потоков в условиях реальной геометрии моделируемого объекта прочно вошли в практику в самых разных областях науки и техники – от энергетики и строительства до медицины и экологии. Стационарные расчеты на сетках до полумиллиона ячеек на современном персональном компьютере занимают несколько часов и часто рассматриваются как рядовые. В более сложных случаях, например при использовании вихреразрешающих подходов к моделированию турбулентности, возникает необходимость решения нестационарной задачи на большом интервале времени для получения статистически установившегося результата, что увеличивает объем вычислений в сотни раз. При этом единичный компьютер зачастую не может обеспечить требуемый объем оперативной памяти для работы с многомиллионными расчетными сетками, использование которых диктуется необходимостью адекватного разрешения сложной вихревой структуры потока. Эффективным средством решения столь ресурсоемких задач гидродинамики является применение параллельных вычислений на распределенных системах кластерного типа, которые сравнительно дешевы и легко масштабируются как по числу процессоров, так и по объему оперативной памяти. Однако эффективность параллелизации существенно зависит от того, как в программе организован межпроцессорный обмен данными, который обычно является самой медленной частью алгоритма и может свести на нет эффект от увеличения числа используемых процессоров. В настоящей работе представлен весьма удачный, по мнению авторов, опыт распараллеливания академического программного комплекса (ПК) SINF (Supersonic to INcompressible Flows). ПК SINF развивается на кафедре гидроаэродинамики Санкт-Петербургского государственного политехнического университета с 1993 года [1] и обеспечивает решение трехмерных уравнений Навье-Стокса в областях произвольной геометрии с использованием блочно-структурированных сеток (более полное описание ПК SINF можно найти в работах [2, 3]).
Распараллеливание ПК SINF осуществлено на основе библиотеки MPI (Message Passing Interface) с ориентацией на распределенные системы кластерного типа. Декомпозиция расчетной области проводится по блокам сетки, распределение блоков между процессами выполняется вручную. Во всех процессах работает один и тот же программный код, который производит вычисления в принадлежащих данному процессу блоках. При этом один из процессов назначается главным и, помимо вычислений в своих блоках, производит сбор и рассылку необходимых данных по всем блокам (невязки, интегральные величины и др.). Тем не менее, большая часть межпроцессорного обмена данными приходится на процедуры стыковки блоков, и, соответственно, организация этого процесса непосредственно сказывается на эффективности параллелизации. Как уже указывалось, в ПК SINF для стыковки блоков используется вспомогательный виртуальный блок. В однопроцессорной версии кода вычисления в виртуальном блоке и соответствующая пересылка данных производятся поочередно, поле за полем, с использованием общей памяти (рис. 1). Сохранение подобной концепции в параллельной версии привело бы к необходимости многократного MPI-копирования данных для каждой стыковки, что является крайне неэффективным – гораздо быстрее пересылать все данные единым пакетом.
На рисунке 3 показаны типичные зависимости эффективности от числа использованных процессоров. Кривая 1 получена для модельной задачи о течении в прямоугольной каверне; расчетная сетка была разбита на 24 одинаковых блока, что обеспечило почти равномерную загрузку процессоров и, соответственно, высокую эффективность параллелизации. При расчете нестационарного обтекания цилиндра (кривая 2) не было уделено должного внимания равномерности загрузки, что сказалось на эффективности параллелизации. Та же задача, решенная на другой сетке с разбивкой на близкие по размерам блоки (кривая 4), демонстрирует эффективность, близкую к максимальной. Несколько выпадает из общего ряда кривая 3 (расчет течения, индуцируемого колебаниями упругой пластины). В данном случае расчет на двух процессорах показал эффективность, близкую к единице, поскольку оба процессора находились на одном узле кластера и обмен данными между ними проходил через общую память. Другой особенностью данной задачи являлось использование алгоритма SIMPLEC (в остальных случаях применялся метод искусственной сжимаемости), который требует дополнительных итераций (и стыковок) при решении уравнения Пуассона для поправки давления. Увеличение доли стыковок в общем объеме вычислений привело к более быстрому снижению эффективности параллелизации при увеличении числа процессоров. Тем не менее, при использовании 10–15 процессоров эффективность все еще остается на приемлемом уровне. Подводя итог, можно сказать, что, благодаря оптимизации межпроцессорного обмена данными, ПК SINF может эффективно использовать более 20 процессоров. Заметное влияние на эффективность параллелизации оказывает не только равномерность загрузки процессоров (которая отчасти зависит от способа разбиения сетки на блоки), но и выбор численной схемы. Размер сетки практически не сказывается на эффективности. Литература 1. Smirnov E.M. Numerical simulation of turbulent flow and energy loss in passages with strong curvature and rotation using a three-dimensional Navier-Stokes solver / Vrije Universitet Brussel, Dept. Fluid Mechanics, Report on «Research in Brussels'92» Action. Brussels, March 1993, 122 p. 2. Смирнов Е.М., Зайцев Д.К. Метод конечных объемов в приложении к задачам гидрогазодинамики и теплообмена в областях сложной геометрии // Научно-технические ведомости СПбГТУ, 2004, № 2 (36). С. 70–81. 3. Зайцев Д.К., Щур Н.А. Применение деформируемых сеток для численного моделирования течений в областях с подвижными границами // Там же, 2006, № 5/1 (47). С. 15–22. |

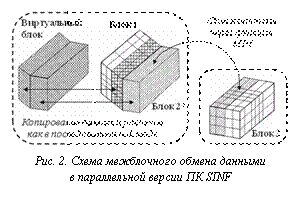 Чтобы упростить копирование и обеспечить эффективную передачу данных между процессами, не затрагивая при этом уже реализованные алгоритмы работы с виртуальным блоком, в ПК SINF использован следующий прием (см. рис. 2). В том процессе, где происходит обработка одного из стыкуемых блоков (блок 1), создается дополнительный блок 2*, являющийся копией приграничных слоев ячеек реального блока 2. Копирование необходимых для стыковки данных из блока 2 в блок 2* осуществляется единым пакетом при помощи функций MPI. Далее выполняется обычная обработка стыковки блоков 1 и 2*, после чего проводится обратное MPI-копирование данных в блок 2.
Чтобы упростить копирование и обеспечить эффективную передачу данных между процессами, не затрагивая при этом уже реализованные алгоритмы работы с виртуальным блоком, в ПК SINF использован следующий прием (см. рис. 2). В том процессе, где происходит обработка одного из стыкуемых блоков (блок 1), создается дополнительный блок 2*, являющийся копией приграничных слоев ячеек реального блока 2. Копирование необходимых для стыковки данных из блока 2 в блок 2* осуществляется единым пакетом при помощи функций MPI. Далее выполняется обычная обработка стыковки блоков 1 и 2*, после чего проводится обратное MPI-копирование данных в блок 2.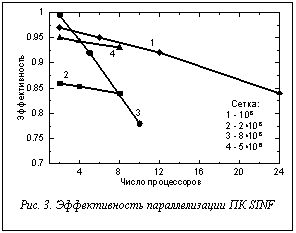 Эффективность параллелизации. К настоящему времени накоплен большой опыт применения ПК SINF при проведении ресурсоемких расчетов (с размерностью сетки до 20 миллионов ячеек) на нескольких кластерах с использованием до 24 процессоров.
Эффективность параллелизации. К настоящему времени накоплен большой опыт применения ПК SINF при проведении ресурсоемких расчетов (с размерностью сетки до 20 миллионов ячеек) на нескольких кластерах с использованием до 24 процессоров.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2349&like=1&page=article |
Версия для печати Выпуск в формате PDF (4.21Мб) |
| Статья опубликована в выпуске журнала № 3 за 2009 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Разработка графической оболочки для параллельных расчетов на базе платформы OpenFOAM
- Облачный сервис «Параллельный Matlab»
- Исследование эффективности библиотеки MaLLBa на примере задач максимальной выполнимости
- Реализация алгоритма оптимизации параметров молекулярно-динамического потенциала REAXFF
- Неоднозначная семантика и некорректности при работе с потоками на C#
Назад, к списку статей