Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Кластеры распределенной системы тренажерно-моделирующего комплекса в задаче агрегации фракталов
Аннотация:Рассматривается концепция построения и работы современных распределенных информационных систем тренажерно-моделирующих комплексов, при этом особое внимание уделено перспективным методам представления структур системы в приложении к задаче оптимизации размещения данных на основе эволюционного моделирования и фрактальных кластерных агрегатов.
Abstract:The author gives concept of construction and work distributed information systems of simulators, thus the special attention is given to perspective methods of structures representation in the appendix to a problem of data accommodation optimization basis on evolutionary modeling and fractal cluster units.
| Авторы: Янюшкин В.В. (vadim21185@rambler.ru) - Донской филиал Центра тренажеростроения, г. Новочеркасск, г. Новочеркасск, Россия, кандидат технических наук | |
| Ключевые слова: сервис данных, распределенное информационное пространство, модели представления данных, агрегация, самоподобие, фрактал, кластер |
|
| Keywords: data service, distributed information space, data presentation models, aggregation, self-similarity, fractal, cluster |
|
| Количество просмотров: 15443 |
Версия для печати Выпуск в формате PDF (4.03Мб) Скачать обложку в формате PDF (1.25Мб) |
Многие задачи подготовки специалистов успешно решаются с помощью компьютерных тренажерных систем. Создание таких сложных программно-аппаратных комплексов требует поддержания необходимой функциональности распределенных по узлам вычислительной сети моделей и взаимосвязанных данных. Для решения этих задач создается распределенная информационная система, которая обеспечивает своевременное поступление исходных данных и команд моделям, передачу результатов моделирования средствам имитации, а также размещение данных модельного мира в информационной системе.
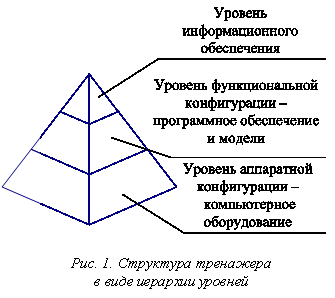
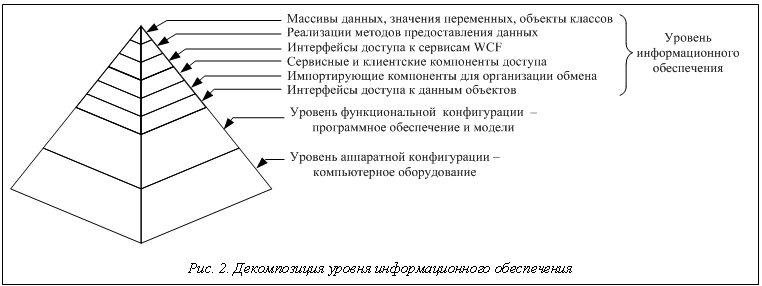
Формализация и постановка задачи. Описание структуры тренажера можно представить в виде иерархии нескольких уровней (рис. 1): - уровень аппаратной конфигурации, который представлен компьютерами и другим оборудованием тренажера, а также набором характеристик, таких как объем оперативной памяти, скорость передачи данных, частота процессора, объем видеопамяти и т.д.; - уровень функциональной конфигурации, характеризующий распределение программного обеспечения и моделей тренажера по узлам вычислительной сети, то есть по элементам аппаратной конфигурации; при этом каждая модель имеет определенный состав данных, необходимых для ее функционирования и правильной работы приложений; - уровень информационной модели, на котором представлен состав данных, необходимых для функционирования системы в целом и отдельных приложений и моделей в частности. Предложенная иерархическая организация архитектуры может являться практическим примером и попыткой декомпозиции сложной системы, на основе которой удобно рассматривать функциональные составляющие системы и их взаимодействие. Наибольшее внимание в данной работе уделяется верхнему уровню организации системы. Например, дальнейшая декомпозиция данного уровня при использовании подхода Service-Oriented Architecture (SOA) и современной технологии Windows Communication Foundation (WCF) может быть такой, как представлено на рисунке 2, из которого видно, что именно массивы данных, конкретные объекты и значения их атрибутов являются основой формирования распределенного общетренажерного ресурса, находясь на вершине уровней. Для упрощения понимания процедур организации данная задача разбивается на ряд отдельных подзадач, или этапов формирования информационной среды [1, 2].
· Множество компьютеров вычислительной сети, вошедших в состав проведения тренировки: PC={PC1,…,PCi,…PCn}. · Множество элементов функционального программного обеспечения: M={M1,…,Mj,…Mp}. · Матрица соответствия аппаратной и функциональной конфигурации тренировки, которая конструируется на основе фактической привязки определенных программных компонент к узлам тренажера: · Множество элементов качественной классификации типов данных, при этом для каждого типа объекта выделяется признак статического или динамического обновления, то есть факт изменения значений параметров моделями в процессе работы. Если значения будут меняться, для такого объекта вводится дополнительный параметр частоты обновления: D={D1,…,Dj,…Dm}. · Матрица потребностей моделей, которая строится на основе входных и выходных параметров всех существующих моделей системы: · Объемы выделенной оперативной и (или) дисковой памяти для хранения объектов модельного мира на узле системы: V={V1,…, Vi,…, Vn}. Для математической постановки дополнительно вводятся следующие переменные: tnet – среднее время получения единицы информации с использованием удаленных фрагментов модельного мира; tmem – среднее время получения единицы информации с использованием локальных фрагментов модельного мира. При этом количественный состав информационной наполняющей моделей для каждого типа заранее неизвестен. Для некоторых типов и структур данных характеристики, например, объем требуемой для хранения памяти и интенсивность использования, могут значительно отличаться. Поэтому каждый тип более детализированно может характеризоваться такими параметрами, как количество объектов определенного типа и их размер:
где Требуется найти оптимальный вариант начального распределения элементов уровня информационного обеспечения для минимизации целевой функции для системы:
при размещении объектов данных, выполненном в соответствии с введенной матрицей размещения: Целевая функция представляет собой величину суммарных затрат на построение информационной системы и включает суммарные значения времени обращения и обновления данных, а также суммарные объемы всей размещенной в системе информации. Такая форма записи является глобальным критерием эффективности системы, при этом возможно выделение набора отдельных функций F={F1,…,Fi,…,Fn} для каждого элемента аппаратной конфигурации. Оптимизация группы выбранных критериев целесообразна для принятия решений о локальной оптимизации размещения данных модельного мира на каждом узле:
Минимумы целевых функций находятся при выполнении следующих введенных ограничений: 1) выполнение условия соблюдения максимального отведенного объема для хранения данных на каждом узле:
2) размещение каждого объекта данных хотя бы на одном узле конфигурации:
3) предельное время выполнения временных операций на каждом узле тренажера при заданном ограничении T={T1,…,Ti,…Tn}:
Алгоритмы и модели представления данных. Используемые математические модели имеют ряд недостатков, основные из которых: описываются отдельные характеристики, а не их комплекс; отдельные математические модели не дают представления о работе системы в целом; модели позволяют описать только статическое состояние систем без учета их динамических характеристик; в качестве элементов размещения используются БД или информационные массивы, структуры которых, как правило, не оптимизируются. Для устранения указанных недостатков предлагаются методы построения математических моделей проектирования и оптимизации структур распределенных информационных систем на основе следующих подходов: · применение эвристических алгоритмов современной теории принятия решений для проектирования рациональных логических структур распределенных БД (РБД), в основе которых лежит решение задачи размещения информации в вычислительной сети; · применение интеллектуальных стратегий и алгоритмов принятия решений, которые позволяют обеспечить значительное снижение сетевого трафика за счет использования кэширования данных в распределенных системах и, как следствие, уменьшить время одной транзакции и увеличить количество одновременно выполняемых параллельных транзакций; · проектирование с помощью графовых моделей, позволяющих строить взаимосвязи фрагментов распределенного информационного объекта и потребителей, а также сетей Петри; · разработка и использование моделей на базе распределенной фреймовой иерархии архитектур построения распределенных интеллектуальных систем, в которых знания, сосредоточенные в различных узлах компьютерной сети, могут использоваться совместно для решения определенной задачи в процессе коллективного распределенного или локального вывода. Среди существующих схожих задач оптимизации сложного информационного пространства наиболее широко представлена задача синтеза оптимальной структуры РБД. Решаемые проблемы отличаются большой размерностью, сложностью и трудоемкостью, что определяется распределенностью мест хранения и обработки данных, необходимостью учета большого количества характеристик используемой информации и процедур ее обработки; многообразием критериев эффективности; ограничениями, вносимыми СУБД, операционными системами и техническими средствами. Разработка логических структур РБД базируется на использовании эвристических методов проектирования рациональных и формализованных методов проектирования оптимальных логических структур РБД. Большинство разработанных моделей синтеза логических структур РБД основывается на исследовании задач размещения БД или информационных массивов и программ по узлам вычислительной системы заданной конфигурации. На математическом уровне это сводится к решению задачи о назначениях, распределении файлов по уровням памяти вычислительной системы, оптимальном распределении программных модулей между процессорами и вероятностными моделями теории принятия решений. Задача оптимизации состоит в нахождении схемы распределения данных, при которой суммарное среднее время выполнения запросов и распространения обновлений, порожденных функционированием системы, минимально. Одним из перспективных подходов является применение эволюционных подходов при решении задач размещения данных и распределения ресурсов. Таким образом, на сегодняшний день основное внимание уделяется теоретическим основам проектирования структур РБД, репликации отдельных фрагментов и обеспечению функционирования системы с точки зрения принятых математической моделью ограничений. При этом широко не изучены и не известны технологии оптимизации размещения данных в распределенных системах, ориентированных на специфику работы сложных тренажерно-моделирующих комплексов, а используемые технологии имеют ряд существенных недостатков по отношению к современным тенденциям разработки обучающих комплексов и прикладного программного обеспечения. Для решения задач распределения данных в информационной системе предлагается использовать генетический алгоритм [3]. Каждый вариант размещения элементов данных в алгоритме представляется битовой последовательностью, над которой будут проводиться генетические операции. Пусть алгоритм строится как набор поколений E={g1,g2,…,gt} эволюционирующих экземпляров хромосом. При этом каждое поколение представляет собой набор хромосом и соответствующих каждой хромосоме оценок – фенотипов Другим новым подходом при рассмотрении информационного пространства является применение фракталов и кластеров, а также моделей построения кластеров и агрегации фракталов в задаче оптимизации распределенной информационной системы тренажерно-моделирующих комплексов. В информационном пространстве возникают, формируются, растут и размножаются кластеры – группы взаимосвязанных документов. Системы, основанные на кластерном анализе, самостоятельно выявляют новые признаки объектов и распределяют объекты по новым группам. Фрактальные свойства характерны для кластеров информационных Web-сайтов, на которых публикуются документы, соответствующие определенным тематикам [4, 5]. Например, в сфере информационно-социального контента следующим этапом развития популярных пользовательских сервисов (odnoklassniki, vkontakte, wiki, livejournal, blogs) является древовидная структура: макросообщество, которое состоит из сообществ поменьше, а те, в свою очередь, собирают в себе совсем узкие мини-сообщества. Специализация возможна внутри уже существующих макросообществ. Последний современный уровень фрактализации проекта – летучие сообщества, которые пойдут в рост с развитием мобильного Интерне- та [6]. Приложение подобных подходов не только к информационным сетевым ресурсам, но и к корпоративным распределенным системам является актуальной и новой задачей, еще не получившей широкого распространения и рассмотрения. Проектирование архитектурных структур распределенных приложений и данных может быть формализовано в кластерные модели, которые в дальнейшем рассматриваются как объекты некоторого множества для проведения соответствующих логике модификаций. В решении оптимизационной задачи на основе агрегации фракталов лежат следующие принци- пы [7]: · построение кластеров – массивов определенным образом связанных между собой исследуемых объектов; · факторизация кластеров, то есть уменьшение размерности задачи путем представления кластеров в виде новых объединенных кластеров; · DLA (Diffusion Limited Aggregation), то есть агрегация, протекающая в условиях случайного, направленного и комбинированного присоединения элементов к кластерам; · использование отдельных и объединенных моделей эволюций Ч. Дарвина, Ж. Ламарка, де Фриза, К. Поппера и синтетической теории эволюции.
При создании кластера строятся связи моделей через типы данных, образуя логические цепочки соответствующей функциональности, при этом графически получаются определенные связанные геометрические фигуры, на основе которых визуально заметны типы различных связей между моделями тренажера и данными. Естественно, вследствие этого возникают и само понятие распределенных данных, и существующее функциональное разделение между ними и моделями – конечными потребителями информации. В рассмотренной модели представления вся распределенная информационная система может строиться как один большой суперкластер для тренажерного комплекса или как набор кластеров по функциональным моделям или отдельным независимым частям. Исключение тех или иных функциональных возможностей приводит к уменьшению числа элементов кластера и его размеров. При этом не теряется логическая составляющая информационной системы, но функционально разделенные рабочие места и элементы реального тренажера образуют именно такой набор различных кластеров. Существуют повторяющиеся аналогичные фрагменты, свидетельствующие о наличии самоподобных фрактальных зависимостей между моделями и экземплярами данных, которые выражены визуально не изменяющимися частями кластера при увеличении масштаба системы. Для примера рассматривается упрощенный фрагмент кластера комплексного информационного пространства, объединенного набором моделей и типов данных. На рисунке 5 представлен первый кластер, в состав которого входят 6 моделей и 12 типов данных. Элементы кластера соответствуют описанию рисунка 4, при этом затонированная часть показывает не вошедшие в кластер фрагменты информационной системы. Дальнейшее изменение кластера может сопровождаться уменьшением или увеличением числа моделей, при этом очевидно, что число типов данных, задействованное в связях кластера, будет зависеть от количества и характера используемых моделей. Для иллюстрации этого рассматривается кластер, в котором исключены модели 3–4 и, соответственно, типы данных 4, 12.
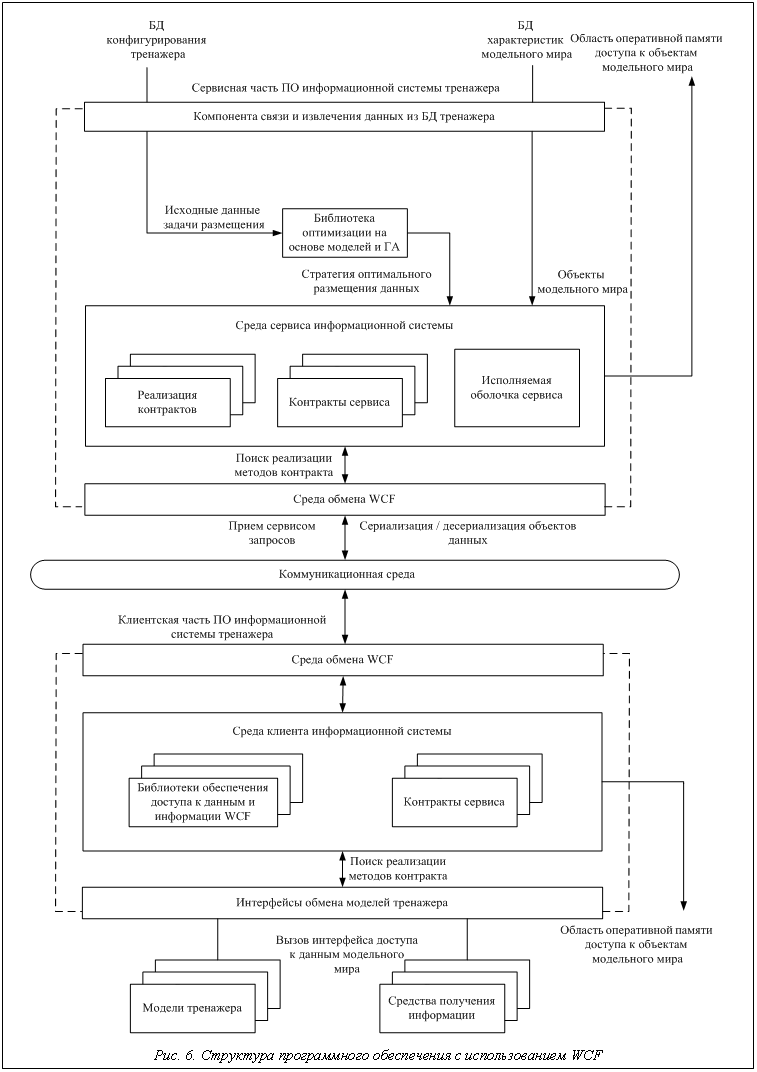
Математически данный подход в терминах задачи оптимизации распределенной информационной системы можно представить как набор элементов множества кластеров, соответствующих всем возможным режимам работы системы и отдельных моделей: clusters={cluster1, cluster2,…, clustert}. Каждый кластер представлен тройкой элементов – подмножество множества компьютеров вычислительной сети, вошедших в состав проведения тренировки PC, множество элементов функционального программного обеспечения M, классификации типов данных D: clusteri={PС, M, D}, в развернутом виде: clusteri={(PCi1, PCi2, …, PCinp), (Mi1, Mi2, …, Minm), (Di1, Di2, …, Dind)}, где np, nm, nd – мощности множеств PС, M, D соответственно. Наличие множества PC в структурах кластеров свидетельствует о распределенном на множество компьютеров характере взаимодействия и размещения данных. Таким образом, представление кластера ведется исходя из двух возможных вариантов: · · многомерное по уровням, где каждый уровень характеризует размещение и формирование кластера на отдельном узле системы, при этом существуют связи между уровнями, соответствующие наличию дублирующихся элементов данных. Оптимизация ведется на основе построения множества подобных кластеров и работы с ними как с хромосомами для подачи на вход генетического алгоритма. Критериями могут быть различные виды типов связей и размерности кластеров, при этом производится разделение (разбиение по критерию) всего кластера на участки с минимальным повторением элементов экземпляров данных, другими словами, выделение в соответствии с функциональным размещением моделей такого результирующего кластера, который удовлетворял бы всем ограничениям, предъявляемым структурами данных. Выделим этапы построения модели оптимизации распределенной информационной системы на основе построения кластеров и агрегации фракталов: · выделение начального набора сущностей из типов данных и моделей тренажера; · построение и образование первичных типов связей между элементами; · создание на этой основе множества кластеров; · факторизация по заданным критериям (по типу данных, связей, по способу определения скорости роста и эффективности кластера); · агрегация элементов в процессе моделирования работы системы, что даст возможность не только присоединять новые типы данных и работать с ними, но и в целом обеспечивать процесс функционирования тренажера; · применение модели эволюции на основе генетического подхода и модификаций генетических алгоритмов, дающих различные наборы кластеров для оценки их эффективности. Архитектурная и программная составляющие части информационной системы. Виртуализация компьютерных ресурсов, вычислительных мощностей и памяти – одно из наиболее перспективных направлений развития информационных технологий. Для высокопроизводительных Появление современных технологий SOA, динамических композитных приложений и Web 2.0 изменило сферу стратегических бизнес-задач при построении и развертывании корпоративных приложений, при этом следующим этапом развития распределенных вычислений и хранения данных является технология cloud computing, вобравшая в себя существенную часть подходов SOA, SaaS (software-as-service), моделей виртуализации, удаленные хранилища данных и принципы предоставления программного обеспечения в аренду (Application Service Providers, ASP). Архитектура вычислительного облака представлена массивом серверов и интерактивным интерфейсом, позволяющим пользователю выбирать службу из каталога с помощью запросов, передаваемых в управление системы, далее находятся правильные ресурсы и вызываются вспомогательные инструменты, которые извлекают информацию из облака. Приложение подобных подходов на основе идеологии использования удаленного облака данных и центра обработки данных, содержащего все необходимые инструменты построения эффективных обучающих систем, способного эффективно строить информационные каналы, предоставлять удобные интерфейсы для сборки и использования массивов данных, а также хранящего все функционирующие и требовательные к ресурсам и отрабатываемые на защищенных серверах модели, является актуальной для рассмотрения задачей. Основной задачей проектирования данной системы является разработка схем взаимодействия аппаратно-программной составляющей облака данных, в которой можно выделить следующие подзадачи: выбор аппаратных средств серверов хранения, БД, моделирования, резервирования, поддержки функционирования, дополнительных устройств обеспечения надежности и управляемости; размещение в соответствии с функциями моделей, БД, разработка распределенного программного обеспечения и проектирование внешних интерфейсов на основе SOA, а также разработка функций поддержки единого информационного пространства, репликации и тиражирования данных. Таким образом, на следующем уровне разработка системы ведется с использованием технологии WCF, продолжающей развитие концепции SOA, и предполагает создание развитых исполняемых интерфейсов, при работе с которыми клиенты системы в стандартной сетевой терминологии не являются тонкими или толстыми, а представляют собой унифицированные рабочие места, имеющие в своем распоряжении список доступных сервисов (рис. 6). Отображенные на рисунке сервисные и клиентские части распределенной системы имеют удобную программную реализацию и расширяемость на любом уровне организации, а также обеспечивают с помощью специализированного программного обеспечения интеллектуальную стратегию размещения данных. Обобщенно архитектура тренажерно-моделирующего комплекса при использовании перечисленных концепций предоставления ресурсов центров данных может быть представлена в виде некоторого сложного интеллектуального распределенного информационного портала, предоставляющего клиентам высокоскоростные надежные и защищенные каналы информации самого различного назначения. На основе представленных в статье положений выполнена работа по следующим аспектам: · анализ литературных источников позволил сделать вывод о том, что отсутствие отечественных стандартов и готовых решений для построения систем реального времени высокой готовности [8] ставит задачи разработки и построения моделей и алгоритмов проектирования таких структур на основе современных положений теории принятия решений; · предложена и описана упрощенная структура тренажера на уровне основных положений и требований с введением понятия облака данных и иерархической структуры системы, на основе представления уровней которой строятся вся идеология работы распределенной информационной системы и кольца интерфейсов доступа вокруг информационных объектов; · получена формализованная постановка задачи оптимизации размещения данных и взаимодействия информационных объектов в распределенной информационной системе; · с помощью анализа имеющихся методов решения задач данного класса кратко рассмотрены современные методики решения на основе генетического поиска и формирования фрактальных кластерных агрегатов, представляющих собой объединенные сущности моделей и данных. Автором предложены перспективный подход и способ представления и манипулирования размещением данных и их потоками в сложных корпоративных информационных пространствах с применением фракталов и эволюционного моделирования. Литература 1. Янюшкин В.В. Оптимизация размещения данных модельного мира в распределенной информационной системе тренажерно-моделирующего комплекса // Изв. вузов. Северо-Кавказский регион. 2008. № 4. C. 25–28 (Технические науки). 2. Янюшкин В.В. Постановка задач и общие алгоритмы оптимизации размещения данных модельного мира в тренажерно-моделирующих комплексах // Теория, методы проектирования, программно-техническая платформа корпоративных информационных систем: матер. VI науч.-практ. конф. (г. Новочеркасск, 26 мая 2008 г.). ЮРГТУ (НПИ). 2008. С. 71–80. 3. Янюшкин В.В. Подход к применению генетических алгоритмов и конструированию структур данных в задаче оптимизации размещения данных // Там же. С. 81–85. 4. Ландэ Д.В. Фракталы и кластеры в информационном пространстве // Корпоративные системы. 2005. № 6. С. 35–39. 5. Ландэ Д.В. Фрактальные свойства тематических информационных потоков из Интернета // Регистрация, сбор и обработка данных. 2006. Т 8. № 2. С. 93–99. 6. Янюшкин В.В., Янюшкин В.В. Фракталы как основа инновационных технологий в современных средствах моделирования и прикладных приложениях информационных систем. Новочеркасск: Новочерк. гос. мелиор. акад., 2008. 114 c. 7. Емельянов В.В., Курейчик В.М., Курейчик В.В. Теория и практика эволюционного моделирования. М.: Физматлит, 2003. 432 с. 8. Янюшкин В.В. Специализированные стандарты распределенного моделирования и задачи размещения информационных объектов // Теория, методы проектирования, программно-техническая платформа корпоративных информационных систем: матер. VI науч.-практ. конф. (г. Новочеркасск, 26 мая 2008 г.). ЮРГТУ (НПИ), 2008. С. 52–59. |

 ,
,  .
.
 .
. ,
, – объем объекта данных j типа Dj;
– объем объекта данных j типа Dj; 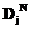 – количество объектов данных типа Dj.
– количество объектов данных типа Dj.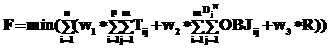
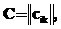
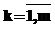 , где Tij – матрица значений времени, рассчитанных исходя из принятых величин tnet и tmem , а также объемов данных; w1, w2, w3 – весовые коэффициенты, показывающие важность и вклад каждого компонента в общий критерий; R – дополнительные временные затраты на обновление и модификацию удаленных реплицированных фрагментов информационной системы при изменении поведения динамичных объектов моделей:
, где Tij – матрица значений времени, рассчитанных исходя из принятых величин tnet и tmem , а также объемов данных; w1, w2, w3 – весовые коэффициенты, показывающие важность и вклад каждого компонента в общий критерий; R – дополнительные временные затраты на обновление и модификацию удаленных реплицированных фрагментов информационной системы при изменении поведения динамичных объектов моделей:  .
.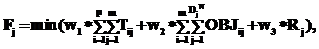

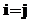 ,
, 


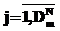 ;
;

 . Каждая хромосома представляет собой вариант матрицы размещения данных
. Каждая хромосома представляет собой вариант матрицы размещения данных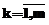 . Каждая оценка (фенотип) – это численное выражение критерия эффективности текущего размещения F={F1,…,Fi,…,Fn}. На рисунке 3 изображены логическая структура хромосомы и деление отдельных участков на гены в соответствии с иерархическим представлением информационной системы.
. Каждая оценка (фенотип) – это численное выражение критерия эффективности текущего размещения F={F1,…,Fi,…,Fn}. На рисунке 3 изображены логическая структура хромосомы и деление отдельных участков на гены в соответствии с иерархическим представлением информационной системы.
 Исключение тех или иных функциональных возможностей, а именно уменьшение множества моделей, приводит к уменьшению числа элементов кластера и его размеров. Причем не теряется логическая составляющая информационной системы, но функционально разделенные рабочие места и элементы реального тренажера образуют именно такой набор всевозможных кластеров в различных режимах работы. При этом в каждом построенном таким образом кластере будут существовать повторяющиеся аналогичные фрагменты, свидетельствующие о наличии самоподобных фрактальных зависимостей между соответствующими режимами работы системы и связями элементов, которые выражены визуально не изменяющимися частями кластера при увеличении масштаба системы. При введении некоторых моделей (или удалении существующих) могут возникнуть отдельные несвязанные структуры кластеров аналогично классическим определениям физики фрактальных кластеров, характеризуя процесс сборки типа кластер–кластер или кластер–частица.
Исключение тех или иных функциональных возможностей, а именно уменьшение множества моделей, приводит к уменьшению числа элементов кластера и его размеров. Причем не теряется логическая составляющая информационной системы, но функционально разделенные рабочие места и элементы реального тренажера образуют именно такой набор всевозможных кластеров в различных режимах работы. При этом в каждом построенном таким образом кластере будут существовать повторяющиеся аналогичные фрагменты, свидетельствующие о наличии самоподобных фрактальных зависимостей между соответствующими режимами работы системы и связями элементов, которые выражены визуально не изменяющимися частями кластера при увеличении масштаба системы. При введении некоторых моделей (или удалении существующих) могут возникнуть отдельные несвязанные структуры кластеров аналогично классическим определениям физики фрактальных кластеров, характеризуя процесс сборки типа кластер–кластер или кластер–частица.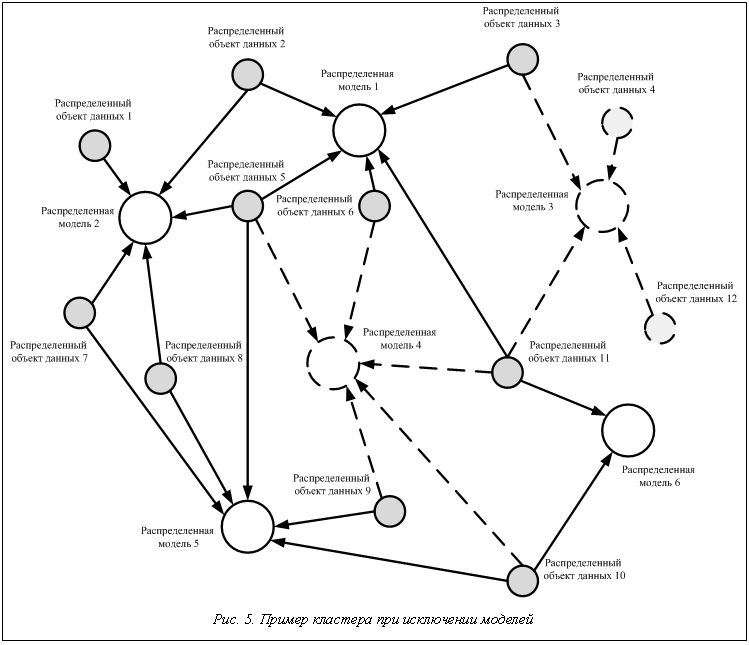
| Постоянный адрес статьи: http://swsys.ru/index.php?id=2426&like=1&page=article |
Версия для печати Выпуск в формате PDF (4.03Мб) Скачать обложку в формате PDF (1.25Мб) |
| Статья опубликована в выпуске журнала № 1 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Нелинейная фрактальная модель валютного кризиса
- Определение перспективных характеристик самолетов с помощью кластерного анализа
- Трехтактная кластеризация динамичных интернет-ресурсов с применением DOM-моделей
- Комплекс проблемно-ориентированных программ анализа микрофотоизображений текстуры нанокомпозитов «FRA_VA_T»
- Методология построения автоматизированной системы консолидированной отчетности
Назад, к списку статей