Растущие индукторные пространства и анализ параллельных алгоритмов
| Коганов А.В. (koganow@niisi.msk.ru) - НИИСИ РАН, г. Москва, кандидат физико-математических наук | |
| Ключевые слова: тесты, вычисления, эффективность, параллельность, алгоритмы |
|
| Keywords: testes, calculation, effectively, parallelism, algorithms |
|
|
|
|
Рассматриваемая математическая задача возникла при разработке тестов инженерной психологии, направленных на выявление людей, способных одновременно выполнять несколько операций распознавания при обработке визуальной текстовой информации. С точки зрения математики проблема сводится к поиску логических функций двух типов. Одни функции должны допускать значительное ускорение решения при одновременном использовании нескольких процессоров, выполняющих распознавание символов исходной информации и операции некоторого логического базиса. Другие требуют для этого очень большого увеличения ресурсов при низкой средней эффективности на один процессор. Требуется также, чтобы каждая задача допускала вариацию в широких пределах объема исходной информации. Тесты были построены, проведен эксперимент, показавший эффективность методики [1–3]. Рассмотрим математический аппарат анализа логических функций для выявления задач указанных типов. Каждый алгоритм вычисления функции – это процесс на индукторном пространстве [4–5]. Использование в алгоритме операций условных переходов делает удобным введение понятия растущего индукторного пространства, где на каждом такте вычислений добавляются необходимые элементы индукции. Понятие характеристики задачи Под задачей будем понимать алгоритм, определяющий функцию от конечного (но переменного и неограниченного) числа переменных (входов). Все входы и значения примеров (ответы) принимают конечное число значений в некотором фиксированном (базовом) алфавите. Каждый набор значений переменных определяет один пример задачи. Для вычисления ответов примеров задачи используется заданный набор элементарных операций, образующих логический базис в базовом алфавите, необязательно минимальный (операционный базис). Реализацией примера задачи будем называть итеративную структуру элементарных операций, построенную как направленный граф без циклов. Вершины графа распадаются на уровни (уровни вложенности). Вершинам графа начального уровня сопоставлены элементы исходных данных. Вершинам последующих уровней сопоставлены операции из операционного базиса. Стрелки показывают, как передаются данные в аргументы этих операций – от элементов исходных данных или от результатов операций предыдущих уровней. В связи с тем, что порядок аргументов операции в общем случае существенен для результата, операция должна различать и упорядочивать стрелки, входящие в вершину, с которой она ассоциирована. Операции последнего уровня выдают ответ. Далее рассматривается операционный базис, состоящий из всех логических функций от некоторого фиксированного числа k переменных со значениями в базовом алфавите (значение k будет емкостью элементарных операций). Глубиной реализации назовем максимальный уровень вложенности операций в ней. Начальный уровень исходных данных считается нулевым. Запараллеленностью реализации назовем максимальное число операций одного уровня вложенности. Оптимальная по глубине реализация примера – это реализация наименьшей (оптимальной) глубины при заданном классе элементарных операций и заданной запараллеленности. Функциональная зависимость оптимальной глубины от запараллеленности – характеристика данного примера из задачи. T(k, P) – характеристика задачи, время решения примера задачи с запараллеленностью P на операциях емкости k. Когда параметр k фиксируется, его можно не указывать. Эффективность запараллеленности определяется абсолютной и относительной удельной эффективностью на один дополнительный процессор:
Замечание: в некоторых задачах граф оптимальной реализации можно выбирать в зависимости только от числа входов, но не от значений входных данных; в других задачах такой граф будет различным для разных наборов значений входов. Задача с эффективной запараллеленностью Высокой эффективностью запараллеленности обладает задача поиска наименьшего (или наибольшего) числа в строке или в таблице чисел: F(x1, …, xn)=min{x1, …, xn}. (3) Если обозначить S(xk, …, x1) операцию емкости k сравнения k однозначных чисел из цифрового алфавита, например {0; 1; 2; 3; 4; 5; 6}, S(xk,…, x1)=min{xk,…, x1} или S(xk, …, x1)=max{xk, …, x1}, то последовательная реализация имеет вид F(x1, …, xn)=S(xn, …, xn-k+2, S(xn-k+1, …, xn-2k+3, S(…S(xk, …, x1)…))). (4) Запараллеленность P может быть реализована в виде (4) с разбивкой всего набора чисел на P равных частей (возможно, последняя будет меньше), с последующим поиском минимума из P чисел (предварительных результатов) с запараллеленностью P: F(x1, …, xn)=F(F(x1, …, xkP), …, F(xk(P-1)+1, …, xn)). (5) Последний этап можно реализовать древовидной итерацией операций S с ветвлением до P. Легко доказать, что это оптимальная реализация по глубине и по числу операций одновременно:
Для характерных в эксперименте значений n=10, k=2 эффективность параллельности будет следующая: P=2; D=4,00; d=40 %, (9) P=3; D=2,48; d=25 %, (10) P=4; D=1,94; d=19 %, (11) где P – число процессоров; D – удельная эффективность на один дополнительный процессор; d – относительная удельная эффективность. Из характеристик (9–11) видно, что эффективность высока, особенно при введении второго и третьего процессоров. Растущие индукторные пространства Для задач, в которых реализация зависит от исходных данных, удобно ввести понятие растущего индукторного пространства. Смысл этого понятия в том, что новые точки и элементы индукции вводятся по мере обработки входной информации. Этот эффект хорошо известен в программировании при использовании операций условного перехода. В зависимости от полученных промежуточных результатов к вычислениям подключаются те или иные программные блоки. Если построить развертку реализации алгоритма по тактам с указанием переходов от одной операции к другой и источников операндов для очередной операции, то получится индукторное пространство, в котором вычисление представлено процессом типа индукторного автомата. Но разным исходным данным будут соответствовать в общем случае разные пространства и автоматы в зависимости от реализации условных переходов в программе. Дадим формальное определение этого явления. Обозначения. A – алфавит, в котором определены значения операндов и результатов всех операций; k – емкость операций, то есть максимально возможное число операндов; H(A, k) – класс всех операций в заданном алфавите и с заданной емкостью (базовые операции); n – число входов примера задачи (число аргументов вычисляемой функции, число точек нулевого уровня в реализации); P – запараллеленность (максимально допустимое число операций на одном уровне реализации); V(A, n, k, P) – класс операций порождения реализации при ограничениях, заданных указанными параметрами (определение 1); U(A, n, k, P) – класс алгоритмов роста. Определение 1. Операция порождения реализации u(s; x1, …,xk)ÎV(A, n, k, P) имеет операнды xiÎA, i=1, …, k, sÎ{0; 1; …} и выдает значения вида á(i1, s1), …, (ik,sk); wñ, где wÎH(A, k) и для всех j=1,…, k выполнены следующие ограничения: 0£sj Определение 2. Алгоритм роста из U(A, n, k, P) – это рекурсивная функция построения уровней индукторного пространства реализации решения по набору входов примера задачи. Алгоритм удовлетворяет следующим требованиям. 1. Уровень L0 состоит из n точек 2. Уровень L1 состоит из P точек 3. Пусть построены уровни L0, …, Ls-1. Все слои, кроме нулевого, содержат P точек. Каждой точке Алгоритм роста из U(A, n, k, P) формирует индукторное пространство реализации запараллеленности P, используя только операции порождения емкости k. Для каждой исследуемой задачи надо выбрать из класса U(A, n, k, P) подкласс решающих ее алгоритмов. На этом подклассе надо оценить характеристику задачи. Потенциальное и универсальное пространства реализаций Определение 3. Потенциальным пространством реализаций (ППР) ранга [n, k, P] называется индукторное пространство, в котором граница состоит из n точек и в котором для любой возможной реализации с соответствующими параметрами есть изоморфное подпространство. Определение 4. Универсальным пространством реализаций (УПР) ранга [n, k, P] называется пространство, в котором граница состоит из n точек и для любой возможной реализации с соответствующими параметрами можно реализовать эквивалентный процесс (в смысле возможности взаимного пересчета состояний точек при некоторой биекции точек реализации и УПР [5, 6]). Теорема 1. Универсальное пространство определено однозначно своим рангом с точностью до полных индукторов точек. Оно является объединением счетного числа не пересекающихся попарно подмножеств (назовем их уровнями) T=L0ÈL1È…, где #L0=n; #Li=P для i³1. Элементы индукции (полные индукторы) имеют вид [t, {t}ÈL0È…ÈLs-1]I для tÎLs, s³1. Доказательство. Поскольку требуется изоморфизм процессов на реализации и на универсальном пространстве, каждому уровню графа реализации должно соответствовать равное по числу элементов подмножество из УПР, и эти подмножества должны быть не пересекающимися попарно. Так как индуктор точки пространства реализации может содержать любые k элементов из предыдущих уровней, в УПР полный индуктор точки должен содержать объединение всех предыдущих уровней. Процесс реализации формируется по схеме построения растущего пространства, но вместо порождения новой точки и элемента индукции используется очередная точка следующего уровня. В точках тех уровней, которых нет в реализации, процесс на УПР задается как тривиальный (с одним состоянием). Конец доказательства. Замечание: имеется бесконечно много неизоморфных УПР одного ранга, которые различаются наборами неполных индукторов каждой точки. Теорема 2. Имеется единственное минимальное потенциальное пространство реализаций. Оно является объединением попарно не пересекающихся подмножеств (уровней) T=L0ÈL1È…, где #L0=n. Каждому подмножеству {t1; …tk}ÌL0È…È ÈLs-1, содержащему k точек из L0È … ÈLs-1, взаимно однозначно соответствует одна точка tÎLs уровня Ls с индуктором {t; t1; …tk}. Это порождающая система индукторов. Доказательство. Поскольку требуется наличие в ППР подпространства, изоморфного любой реализации с указанными параметрами, и в различных реализациях возможны любые индукторы вида {t; t1; …tk}, где {t1; …tk}ÌL0È…ÈLs-1, tÎLs, то в любом ППР должны быть указанные в формулировке теоремы уровни (доказывается индукцией по номеру уровня). Тот факт, что такое пространство является ППР, доказывается прямым инъективным вложением в него любой реализации последовательно по слоям с учетом индукторов точек реализации. Конец доказательства. Замечание: имеется бесконечно много неизоморфных ППР, которые получаются произвольным расширением минимального ППР без изменения системы индукторов на минимальном ППР. Утверждение 1. В минимальном ППР число ns точек слоя Ls удовлетворяет рекуррентному гипергеометрическому соотношению
Доказательство. На слое Ls необходимо иметь одну точку для каждого набора из k точек из объединения предыдущих слоев и для каждого из P процессоров слоя. Конец доказательства. В соответствующем растущем пространстве слой содержит только P точек. Задача с неэффективной запараллеленностью Описание задачи слежения. Данные примера в задаче слежения оформлены как прямоугольная таблица M´N, где M – вертикаль, N – горизонталь (см. рис. 1). В каждой клетке таблицы стоит знак из алфавита +0–. В крайнем левом столбце одна из клеток дополнительно помечена символом (*). Рядом с крайним правым столбцом правее стоят метки из алфавита A B C D, образующие N+1-й столбец. Эти метки повторяются циклически в строках 1,…,M. Задание: проследить от меченой левой клетки траекторию до правого столбца меток и выдать тот символ, который стоит в финишной правой клетке. Траектория строится так: из клетки со знаком (+) надо перейти в правый соседний столбец на строку выше; из клетки со знаком (-) переход вправо на строку ниже; знак (0) означает переход вправо в ту же строку. В примере запрещено указывать выход за верхнюю или нижнюю границы таблицы. Формально переход из клетки с координатами (i, j) (строка, столбец) описывается так:
Символ в правых скобках показывает, что записано в клетке. Для неграничных клеток aÎ{+; 0; –}. В граничном случае
Расчет характеристики задачи слежения. Использование запараллеленности в задаче слежения возможно только путем предварительного расчета нескольких отрезков траектории в середине или в конце таблицы. Когда основная траектория, идущая от начальной левой клетки с меткой (*), попадет в начало такого отрезка, ее можно сразу перенести в конец этого отрезка. В этой схеме эффект явно вероятностный: попадет ли основная траектория в заранее заготовленный отрезок. Однако расчет характеристики задачи проводится по худшему случаю. Тогда требуется, чтобы дополнительные процессоры гарантированно рассчитывали продолжение траектории из всех точек, в которые может попасть начальный участок траектории, рассчитываемый основным процессором. Такую совокупность начальных точек для гипотетического продолжения траектории назовем потенциальной границей (п-граница) траектории. После переноса основного процессора в заранее вычисленную последнюю точку продолжения траектории можно повторить для нее, как для корня процесс параллельного расчета из точек новой границы.
Определение 5. Относительным рангом п-границы для данной начальной точки назовем наименьшее по траекториям число уровней от начальной точки до точки п-границы. Утверждение 2. Наименьшая по числу точек п-граница данного относительного ранга s – это уровень s на Т-табло с корнем в начальной точке. (Доказывается индукцией по рангу.) Следствие. При заданной запараллеленности в оптимальном по характеристике алгоритме решения задачи слежения дополнительные процессоры отслеживают траектории из точек некоторого уровня s. Доказательство. Допустим, процессоры на начальном такте распределены по некоторой п-границе уровня s. Тогда имеется траектория при неких исходных данных, для которой встреча с границей происходит на такте s. В этом случае все дополнительные процессоры надо перестраивать на новую п-границу новой начальной точки. Таким образом, в расчете на самый плохой случай число тактов решения задачи будет не лучше, чем при распределении процессоров по уровню s. По утверждению 2 для этого заведомо хватит процессоров. Конец доказательства. Замечание: при достаточно большом числе процессоров, если позволяет длина траектории N, можно вести расчет траекторий сразу с нескольких п-границ (обозначим их число r). При этом по числу тактов решения задачи оптимально делать одинаковые расстояния x=Ds между границами. Тогда по истечении s тактов можно перенести начальную точку сразу на rx уровней, затратив только r дополнительных тактов (см. рис. 2). На основе этих фактов можно рассчитать характеристику T(P) задачи слежения. T(1)=N. (15)
#v(s)=2s+1 (16) P=1+#v(x)+#v(2x)+…+#v(rx), P(r, x)=r+1+xr(r+1). (17) Условная характеристика задачи:
Характеристика задачи:
Можно определить приведенную характеристику: t(p)=T(P)/N, (20)
Аналитическое решение задачи (19–21) (поиск для (19) экстремума) приводит для r(P) к уравнению четвертой степени. Но возможно численное решение с учетом ограничений на вероятные значения запараллеленности (17). Для больших N проведены расчеты эффективности для начальных значений запараллеленности. При малых N эффективность ниже. Во всех случаях показана низкая эффективность. При числе процессоров меньше шести эффекта вообще нет. При P=6 эффект составил t(P)=75 % по времени и d(P)=5 % по процессорам. При P=18 время t(P)=56 % и не меняется при увеличении числа процессоров до 22. Удельная эффективность падает с d(18)=2,5 % до d(22)=2 %. Задача слежения на прямоугольной таблице и в полосе. Построение п-границ (слоев) на полосе ширины M или в таблице M´N требует учета выхода траекторий на границу. При малых продольных смещениях L от начальной точки на средней линии полосы (таблицы) выхода за границу нет. Это соответствует условию 1+2L£M. При алгоритме решения с r п-границами и расстоянием x между ними это условие соответствует по (16) значению L=xr. Тогда
P(r, x)=r+1+xr(r+1). (23) После выхода возможных траекторий на границу полосы каждая п-граница имеет длину M. Приведенные характеристики сохраняют вид (20) и (21). При r>m(x) P(r, x)=m(x)+1+xm(x)(m(x)+1)+(r–m(x))M, (24)
При больших x значение m(x)=0 и t* убывает, поэтому
где По этим формулам рассчитаны характеристика задачи и эффективность запараллеленности для двух значений ширины полосы M=4 и M=8 при N>>1, которые удобны для теста. Удельная эффективность дополнительных процессоров для M=4 варьируется от d(P)=12,5 % при P=5, r=1, t(P)=50 %, до d(P)=2,8 % при P=33, r=8, t(P)=11 %. Для M=8 для r=1, P=9 эффект t(P)=50 %, d(P)= 6,25 %, а для r=8, P=65 эффект t(P)=11 %, d(P)=1,39 %. При этом эффект возникает только при достаточно больших (указанных) начальных запараллеленностях, и эффективные значения P нарастают с шагом M. Таким образом, параллельный счет задачи слежения неэффективен. Литература 1. Коганов А.В., Пятецкий-Шапиро И.И., Фейгенберг И.М. Зависимость скорости решения от сложности и способа кодирования исходных данных // Вопросы экспериментального исследования скорости реагирования. Тарту, 1971. 2. Коганов А.В. Коллективы автоматов в детерминированных и случайных средах и приложение к психологическим тестам: дис. … канд. физ.-мат. наук. М., 1972. 3. Коганов А.В. Исследование возможности параллельного выполнения логических операций человеком. Параллельные вычисления и задачи управления // РАСО–2001: тр. междунар. конф. (2–4 октября 2001 г., Москва). М.: ИПУ РАН, 2001. 4. Коганов А.В. Индукторные пространства и процессы // ДАН. 1992. Т. 324. № 5. С. 953–958. 5. Koganov A.V. Processes and Automorphisms on Inductor Spaces // Russian Journal Mathematic Physics. Vol. 4, № 3, 1996, pp. 315–339. |
 ; (1)
; (1)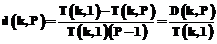 . (2)
. (2) . Характеристика задачи (3) (с точностью до целочисленного округления):
. Характеристика задачи (3) (с точностью до целочисленного округления): ; (6)
; (6) ; (7)
; (7)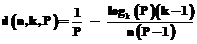 . (8)
. (8) без индукторов (это граница индукторного пространства реализации). Если входы примера имеют значения a1, …, an, то точке
без индукторов (это граница индукторного пространства реализации). Если входы примера имеют значения a1, …, an, то точке  сопоставим состоя- ние ai.
сопоставим состоя- ние ai. . Каждой точке
. Каждой точке  сопоставлен индуктор, содержащий, кроме этой точки, ровно k точек
сопоставлен индуктор, содержащий, кроме этой точки, ровно k точек  уровня L0. Каждой точке
уровня L0. Каждой точке  из V(A, n, k, P) и нумерация точек индуктора. Состоянием процесса вычисления в этой точке будет
из V(A, n, k, P) и нумерация точек индуктора. Состоянием процесса вычисления в этой точке будет  . Каждой точке
. Каждой точке  из V(A, n, k, P) и нумерация точек индуктора. Построение следующего слоя ведется по значениям
из V(A, n, k, P) и нумерация точек индуктора. Построение следующего слоя ведется по значениям 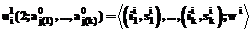 .
. , iÎ{1; …; P}, j=1, …, s-1, сопоставлены операция порождения
, iÎ{1; …; P}, j=1, …, s-1, сопоставлены операция порождения  из V(A, n, k, P) и нумерация точек индуктора. Состоянием процесса вычисления в этой точке будет
из V(A, n, k, P) и нумерация точек индуктора. Состоянием процесса вычисления в этой точке будет  , где аргументы соответствуют значениям процесса в точках индуктора, отличных от центра индукции. Каждой точке
, где аргументы соответствуют значениям процесса в точках индуктора, отличных от центра индукции. Каждой точке  сопоставлены операция
сопоставлены операция  из V(A, n, k, P) и нумерация точек индуктора. Построение следующего слоя ведется по значениям кортежа
из V(A, n, k, P) и нумерация точек индуктора. Построение следующего слоя ведется по значениям кортежа 
 . Такому значению сопоставляется точка
. Такому значению сопоставляется точка  слоя Ls с индуктором
слоя Ls с индуктором  и указанным порядком точек индуктора. Этой точке также сопоставляется операция
и указанным порядком точек индуктора. Этой точке также сопоставляется операция  с тем же порядком аргументов. Конец определения.
с тем же порядком аргументов. Конец определения. . (12)
. (12)
 (13)
(13) (14)
(14)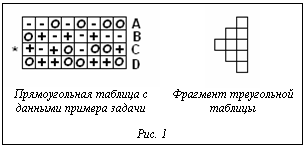 Для расчета характеристики этой задачи вначале рассмотрим случай расчета траектории на треугольной таблице (Т-табло) с числом уровней N от корня (нулевой уровень). В задаче на Т-табло отсутствует краевой эффект выхода на нижнюю или верхнюю границу таблицы.
Для расчета характеристики этой задачи вначале рассмотрим случай расчета траектории на треугольной таблице (Т-табло) с числом уровней N от корня (нулевой уровень). В задаче на Т-табло отсутствует краевой эффект выхода на нижнюю или верхнюю границу таблицы.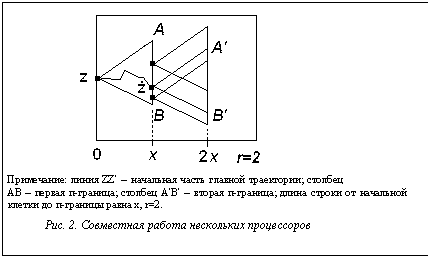 Объем исходных данных n=1+2N(N+1) для Т-табло, а для прямоугольной таблицы n=(N+1)M. Емкости операции k=1 (операция обрабатывает одну клетку или выход одного процессора). Число одновременно обрабатываемых п-границ обозначим r. Расстояния по уровням s между границами обозначим x=Ds. На Т-табло число точек уровня s от любой начальной точки:
Объем исходных данных n=1+2N(N+1) для Т-табло, а для прямоугольной таблицы n=(N+1)M. Емкости операции k=1 (операция обрабатывает одну клетку или выход одного процессора). Число одновременно обрабатываемых п-границ обозначим r. Расстояния по уровням s между границами обозначим x=Ds. На Т-табло число точек уровня s от любой начальной точки: . (18)
. (18) . (19)
. (19) . (21)
. (21) , (22)
, (22) . (25)
. (25) , (26)
, (26) , x®¥.
, x®¥.http://swsys.ru/index.php?id=2506&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Оценка эффективности систем логического вывода модифицируемых заключений
- Технология создания адаптируемых систем обработки информации
- Методы восстановления рабочего состояния приложения
- Об эффективности наследования таблиц в СУБД PostgreSQL
- Алгоритмы и программное обеспечение распознавания низкоконтрастных изображений при оценке качества стали