Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Оценка состояния программного проекта с детерминированной структурой технологического цикла
Аннотация:Рассмотрены вопросы оценки состояния разработки программных систем, развиваемых в рамках итерационного жизненного цикла. Описывается подход к определению подмножества компонент системы, достаточного для оценки состояния системы по результатам регрессионного анализа. Предлагается метод прогноза сложности дальнейших работ на основе анализа документации процесса разработки и результатов предыдущих итераций.
Abstract:Status accounting and evaluation of software systems developed under iterative life cycle is very important in project and configuration management processes. This paper describes an approach for definition of system components set, sufficient for evaluation of system status based on regression analysis. Prognosis method based on analysis of life cycle processes and configuration items from current and previous project iterations is proposed.
| Авторы: Давыдов А.А. (nnalutin@gmail.com) - Национальный исследовательский ядерный университет «МИФИ», г. Москва, Налютин Н.Ю. (nnalutin@gmail.com) - Национальный исследовательский ядерный университет «МИФИ», г. Москва, кандидат технических наук, Синицын С.В. (nnalutin@gmail.com) - Национальный исследовательский ядерный университет «МИФИ», г. Москва, кандидат технических наук, Батаев А.В. (nnalutin@gmail.com) - Национальный исследовательский ядерный университет «МИФИ», г. Москва, кандидат технических наук | |
| Ключевые слова: жизненный цикл, управление конфигурациями, регрессионный анализ, оценка состояния, управление проектами |
|
| Keywords: life cycle, configuration management, regression analysis, status evaluation, project management |
|
| Количество просмотров: 12049 |
Версия для печати Выпуск в формате PDF (4.97Мб) Скачать обложку в формате PDF (1.38Мб) |
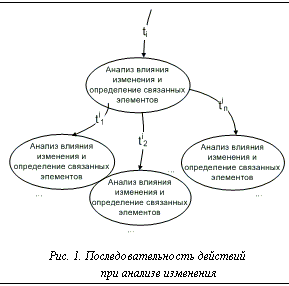
Современные программные комплексы обычно развиваются в рамках итерационного жизненного цикла. Регулярные изменения внешних условий и потребностей пользователя приводят к изменениям требований к системам, а реализация новых требований вызывает необходимость регулярно анализировать внесенные изменения, проверяя согласованность различных частей проекта после внесения обновлений. Для решения подобных задач используется регрессионный анализ [1]. При этом для оценки текущего состояния проекта исследуются как новые (измененные) компоненты, так и старые, потенциально подверженные влиянию внесенных изменений. При промышленной разработке программного обеспечения большая часть порождаемых документов (артефактов) проекта контролируется процессом управления конфигурациями [2]. Будем называть эти документы конфигурационными элементами. Таким образом, для регрессионного анализа доступны такие конфигурационные элементы, как требования, исходные тексты, тесты и их результаты и пр., а также все версии документов, созданные на различных итерациях проекта. При этом процесс управления конфигурациями поддерживает трассируемость (целостность связей) между всеми конфигурационными элементами. При разработке высококритичного программного обеспечения особенно актуальна проблема достаточности множества артефактов, отобранных по результатам регрессионного анализа. Требования к отказоустойчивости подобных систем регламентированы отраслевыми стандартами (например ГОСТ З 51904-2002). Повторное тестирование всей системы после внесения изменений потребует весьма значительных ресурсов, но ошибка в случае выбора слишком малой части объектов может обойтись гораздо дороже. Поэтому необходимо разработать методы регрессионного анализа, заведомо дающие достаточное множество объектов, потенциально подверженных изменениям и требующих доработки. В таких условиях процесс регрессионного анализа можно представить как рекуррентную последовательность следующих шагов. · Определение измененных артефактов и добавление их в множество Ti объектов, требующих анализа. · Определение артефактов, непосредственно связанных с уже отобранными для анализа, и добавление их в множество объектов Ti+1 для последующего анализа. Также может потребоваться внести изменения в такие артефакты для обеспечения непротиворечивости поведения системы. · Повторение шага 2. Таким образом, в ходе регрессионного анализа мы получаем волну, распространяющуюся по связям между конфигурационными элементами. Определение критерия останова для распространения волны – сложная задача, и окончательное решение принимается человеком. Для облегчения его принятия может использоваться предлагаемый метод оценки состояния конфигурации. Пусть Tn+1 – некоторое множество артефактов проекта, полученное по итогам очередной итерации из Tn – множества артефактов, полученных в предыдущей итерации. Здесь под артефактом без снижения общности понимаем элемент конфигурационного управления, который может быть однозначно идентифицирован. Пусть также DT – множество изменений от Tn к Tn+1. Требуется определить DTres – реальное подмножество элементов конфигурации, требующих доработки вследствие внесения изменений DT. Анализу подвергается каждый артефакт tiÎDT. Определяются связанные артефакты tijÎ(TnÈTn+1). Каждый отобранный элемент tij дополнительно анализируется с целью выявления противоречий с ранее отобранными элементами. В случае возникновения противоречия элемент tij добавляется во множество объектов, которые необходимо обновить. Для каждого выявленного элемента проводят аналогичный анализ уже связанных с ним элементов. Если изменение не влияет на результат работы связанного артефакта, дальнейший анализ для него не проводится. Общий вид дерева анализа артефактов проекта представлен на рисунке 1.
Для формализации высказанного предположения требуется ввести некоторые обозначения. Пусть артефакты проекта образуют некоторую сеть G в общем случае как с направленными, так и с ненаправленными связями. Направленные связи отражают случай, когда влияние может распространяться только в одном направлении, например, выходной параметр требования ti является входным для требования tj. Ненаправленные связи характеризуют разного рода ссылки между артефактами, допускающими распространение влияния в любом направлении. То есть
где T – множество артефактов проекта, введенное выше; S – дуги, отображающие направленные связи; M – ребра, отображающие ссылки между элементами. Пусть Ga и Gb – сети вида (1), то есть
Пусть x – некоторый результат анализа, то есть тройка из модели данных проекта G, актуальной на момент анализа, набора анализируемых изменений DT, а также выявленной области влияния этих изменений Gres (подсеть G):
Тогда обозначим соответствующие проекции x как G(x), DT(x) и Gres(x), а множество всех доступных результатов анализа на предыдущих итерациях как X={x}. Можно считать, что результаты анализа достоверны. Для прогноза распространения влияния изменений DT интерес представляют следующие два подмножества X:
Здесь Xinc – множество предыдущих результатов анализа, таких, что, если изменения были на предыдущих итерациях, то они есть и на текущей итерации; Xexc – множество текущих результатов анализа, таких, что, если изменения есть на текущей итерации, то они были и на предыдущих итерациях. Для каждого элемента tÎT модели G актуальных данных проекта введем параметры α(t) – количество попаданий под влияние меньших изменений и β(t) – количество непопаданий под влияние больших изменений.
где На основе этих параметров можно ввести частоты включения и невключения в область влияния, что позволит получить величины, не зависящие от мощности множества X, и в дальнейшем оперировать ими: − частота включения в область влияния:
− частота невключения в область влияния:
С помощью этих частот можно сформулировать вышеописанное предположение следующим образом: степень влияния изменений DT на произвольный элемент t множества T в модели G уменьшается при уменьшении ninc(t) или увеличении nexc(t). Для любого проекта с учетом конкретной интерпретации элементов модели G и накопленной в проекте статистики можно определить пороговые значения ninc и nexc и с их помощью оценить снизу и сверху DTres – область влияния анализируемого изменения. Для получения более точной оценки DTres предлагается, кроме анализа трассировки между элементами конфигурации, проводить анализ технологических операций проекта, которые необходимо проделать вследствие внесенных изменений. В узком смысле жизненный цикл проекта может быть представлен в виде сети технологических операций над проектными артефактами, связанных друг с другом. То есть при таком подходе к оценке влияния DT получится волна изменений, распространение которой необходимо ограничить для получения достаточной оценки размера DTres. Значительное число связей между технологическими операциями дублируется трассировкой, однако в общем случае это необязательно, а значит, применение двух методов позволяет получить более точную оценку.
Будем считать без снижения общности, что любая технологическая операция или ее часть может быть представлена как неделимый акт создания нового значения c на основе некоторого CinÍC. Назовем такое действие проектной активностью aÎA, где A – множество проектных активностей. Проектные активности задают отображение A:PC®PC, то есть a=, CinÌC и CoutÌC. После применения проектной активности множество C переопределяется как C=C0ÈCout, где C0 – множество значений до совершения активности. Вообще говоря, проектная активность A не является чистой функцией, однако если рассматривать только уже совершенные активности, то данным побочным эффектом можно пренебречь. Для любого значения c однозначно определена породившая его активность a. Из практических соображений удобно ввести типизацию активностей. В любом проекте существуют различные типы активностей, таких как разработка требований, кодирование, тестирование и т.п. То есть в любом проекте существует набор классов активностей A1…AnÍA. Таким образом, целесообразно рассматривать набор классов элементов конфигурационного управления T1…TmÍT. Будем считать, что проектная активность всегда задает новое значение для элемента конфигурации, даже если не был изменен его текст. Значит, каждому классу элемента соответствует набор классов значений C1, …, Ck, в том числе отображающих состояние элемента. Значения могут выступать в качестве входных параметров активности (тогда создаются новые значения соответствующих элементов) или ока- зывать управляющее воздействие на активность, или выступать средством совершения активности (рис. 2). Таким образом, следует говорить о множестве ролей, которые может выполнять значение в активности, как об отображении R:C®A, то есть роль задает значения, которые могут быть переданы активности.
Допустимая структура последовательностей технологических операций (технологических цепочек) проекта, то есть модель жизненного цикла, определяется дополнительными ограничениями на связи между конкретными классами активностей, значений, ролей. Немаловажную роль играют ограничения на кардинальность некоторых сочетаний связываемых классов. Для наиболее тонкого моделирования конкретного проекта можно строить развитую структуру классов на множествах A, C, T, R. Таким образом, задается объектная модель жизненного цикла. Состояние проекта определяется классами значений элементов конфигурационного управления. Анализ состояния проекта сводится к определению возможных технологических цепочек, результатом которых будут требуемые значения элементов конфигурации. На основе истории про- ектных активностей можно оценить ожидаемые пути развития проекта и выбрать наиболее приемлемую из возможных цепочек активностей, приводящих проект в заданное состояние после реализации изменений DT. По прогнозу активностей можно предположить создаваемые значения элементов конфигурации и соответственно определить DTres – множество элементов, подверженных изменениям. Если объекты активностей содержат информацию об обязательных ресурсах, затребованных для осуществления конкретных активностей, то можно прогнозировать трудоемкость работ по приведению проекта к требуемому состоянию. Реализация предложенного в статье подхода позволит снизить трудозатраты и увеличить точность при построении оценки состояния проекта с фиксированным технологическим циклом, а также обеспечит дополнительную информационную поддержку принятия решений при управлении изменениями. Литература 1. Блэк Р. Ключевые процессы тестирования. Планирование, подготовка, проведение, совершенствование; пер. с англ. М.: Лори, 2006. 544 с. 2. Alexis L. Software Configuration Management Handbook, Second Edition. Artech House Publishers, 2004. 412 p. |
 Пусть при проведении анализа уже имеется некоторое количество достоверных результатов, полученных при анализе на предыдущих итерациях. Если предположить, что с внесением изменений структура проекта и технология существенно не изменились, то, используя старые результаты, можно попробовать спрогнозировать глубину распространения вышеописанного процесса анализа влияний. Из практики известно, что область, вовлекаемая в повторную верификацию по текущим изменениям, обычно не меньше области, выявленной в процессе внесения меньших изменений, и не больше области, затронутой внесением больших изменений.
Пусть при проведении анализа уже имеется некоторое количество достоверных результатов, полученных при анализе на предыдущих итерациях. Если предположить, что с внесением изменений структура проекта и технология существенно не изменились, то, используя старые результаты, можно попробовать спрогнозировать глубину распространения вышеописанного процесса анализа влияний. Из практики известно, что область, вовлекаемая в повторную верификацию по текущим изменениям, обычно не меньше области, выявленной в процессе внесения меньших изменений, и не больше области, затронутой внесением больших изменений. (1)
(1) и
и 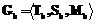 , тогда обозначим
, тогда обозначим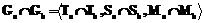 . (2)
. (2) . (3)
. (3) , (4)
, (4) . (5)
. (5)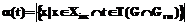 , (6)
, (6) , (7)
, (7) .
. , (8)
, (8) . (9)
. (9)
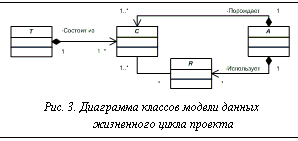 Используя введенные обозначения, все действия в проекте можно представить в виде сети объектов введенных классов (рис. 3). Каждый объект из A связан с одним или несколькими объектами из C; данная связь определяет создание значения в результате активности. Каждый объект из класса R связан как минимум с одним значением из C и одной активностью из A. Это означает, что значение выполняло некоторую роль в активности. Каждое значение из C связано ровно с одним элементом из T, каждый элемент связан с некоторым набором значений из C. Кроме этого, каждому значению соответствует некоторый набор атрибутов, в том числе и текст документа. Заданная таким образом модель данных может непосредственно использоваться для реализации хранения элементов конфигураций в объектной СУБД.
Используя введенные обозначения, все действия в проекте можно представить в виде сети объектов введенных классов (рис. 3). Каждый объект из A связан с одним или несколькими объектами из C; данная связь определяет создание значения в результате активности. Каждый объект из класса R связан как минимум с одним значением из C и одной активностью из A. Это означает, что значение выполняло некоторую роль в активности. Каждое значение из C связано ровно с одним элементом из T, каждый элемент связан с некоторым набором значений из C. Кроме этого, каждому значению соответствует некоторый набор атрибутов, в том числе и текст документа. Заданная таким образом модель данных может непосредственно использоваться для реализации хранения элементов конфигураций в объектной СУБД.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2514&like=1&page=article |
Версия для печати Выпуск в формате PDF (4.97Мб) Скачать обложку в формате PDF (1.38Мб) |
| Статья опубликована в выпуске журнала № 2 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Система управления жизненным циклом оборудования
- Метод поддержки принятия решений по управлению временными аспектами проектов на промышленных предприятиях
- Автоматизация прогнозного расчета стоимости эксплуатации надводных кораблей
- Архитектура и информационно-технологические инструменты комплекса программ интегрированной логистической поддержки промышленных трубопроводных систем
- Динамическая схема GraphQL в реализации интегрированной информационной системы
Назад, к списку статей