Использование онтологии при прогнозировании развития предприятия
| Тюков Н.И. (viza-8.11@mail.ru ) - (Уфимский государственный авиационный технический университет, Кумертауский филиал, доктор технических наук, Извозчикова В.В. (viza-8.11@mail.ru) - Оренбургский государственный университет (доцент), Оренбург, Россия, кандидат технических наук, Матвейкин И.В. (imatvejkin@yandex.ru) - Оренбургский государственный аграрный университет, кандидат технических наук | |
| Ключевые слова: домен, аспект, атрибут, объект, эксперт, иерархии, декомпозиция, прогнозирование, онтологии |
|
| Keywords: domain, dimension, attribute, subject, the expert, the hierarchy, decomposition, forecasting, ontology |
|
|
|
|
Современные онтологии играют решающую роль в модели описания знаний экспертов в системах, основанных на управлении знаниями. Обычно онтологии состоят из экземпляров, понятий, атрибутов и отношений, поэтому основной задачей при построении онтологии при прогнозировании развития предприятия является выделение имен объектов, имен их атрибутов и отношений. В основу решения данной задачи положен метод анализа иерархий, который состоит в декомпозиции задач прогнозирования на подзадачи и дальнейшей обработке последовательности суждений экспертов. Декомпозиция производится таким образом, что каждый атрибут объекта нижнего уровня может выступать в качестве критерия для атрибута объекта высшего уровня, при этом имена объектов и имена атрибутов рассматриваются как идентификаторы задач и учитываемых факторов при выработке прогноза. Для декомпозиции постановок задач на постановки подзадач необходима семантическая интерпретация вербальных знаний экспертов в области прогнозирования развития предприятия с целью выделения имен объектов и имен их атрибутов. В настоящее время выделение объектов и их атрибутов из текста естественного языка не может осуществляться автоматически, эта задача возлагается на инженера знаний и экспертов [1]. Под семантической информацией будем понимать выраженные знаками сведения о выделенной стороне (сторонах) объекта (объектов). Решение задачи выделения имен объектов и имен атрибутов из семантической информации, предоставляемой экспертами, может рассматриваться как преобразование первичной семанти- ческой информации (ответов экспертов) во вторичную (имена объектов и имена атрибутов) посредством сжатия первичной семантической информации. Процесс сжатия сводится к тому, что выделенные аспекты модели раскрываются конкретным содержанием первичной семантической информации. Тогда формально такое преобразование может быть представлено отношением первичной семантической информации Sp к вторичной семантической информации Sv, используя знак семантического преобразования Sm. Sp и Sv содержат аспекты (категории), отображающие полноту представления семантической информации. В математической интепретации аспект – это произвольной длины кортеж знаков (букв, слов, символов и др.). Так, кортежем длины n является запись вида b=, где b1, bn – первая и последняя компоненты соответственно. Для аспектов определены свойства: b={bÎb/R(b)}, (1) где R(b) – отношение «быть упорядоченным по местам». При этом "b(bÎb), {Q(b)ÚùQ(b)}, где Q(b) – отношение «быть одинаковым». В информационном плане аспект является элементом слова C "b, bÎb®bÎC. Слово C характеризует объект, его свойства и отношения. В семантическом плане слово состоит из аспектов, и всегда существует их оптимальное число в слове, которое оценивается объемом сведений, необходимых для описания объекта в рамках решаемой задачи прогнозирования. Аспекты в слове выражаются знаками естественного языка. Слово можно представить кортежем С=, где m – длина слова. При этом для слова выполняются следующие соотношения: C={cÎC, c®R(c)}, "c (cÎC), {Q(c)ÚךQ(c)}. (2) Слово можно записать в виде C={P, S}, где P= – кортеж знаков длины l, характеризующий посредством знаков признаковую составляющую слова; S= – кортеж знаков длины m, характеризующий смысловую составляющую слова. Процесс выделения имен объектов и имен их атрибутов состоит из этапов получения первичной семантической информации и сжатия семантической информации. Обе задачи решаются при взаимодействии экспертов в области прогнозирования стратегического развития предприятия и инженера знаний. Рассмотрим специфическую семантическую операцию, связанную с созданием первичной семантической информации об объекте. Методологической основой выполнения семантической операции, связанной с получением ответов экспертов, адекватной объекту познания, является выполнение следующих требований: необходимы наличие конкретного задания и устранение противоречий между многомерным планом содержания и одномерным планом выражения. При декомпозиции постановок задач на постановки подзадач наиболее приемлемыми способами общения инженера знаний и экспертов являются постановка вопросов и уточнение понимания. Наличие конкретного задания интерпретируем как правильную постановку вопроса экспертам и выполнение ими дополнительного задания. Применительно к текстовой форме представления семантической информации план содержания (или семантика) представляет собой внутреннюю, смысловую сторону объекта, а план выражения (или синтаксис) является внешней, формальной стороной предложения. Совпадение плана содержания с планом выражения (адекватность) возможно в суждениях, состоящих из объекта и атрибута, выражающих однозначную мысль, фиксируемую простым нераспространенным предложением. С учетом этого к первичной семантической информации предъявляем следующие требования: P=, Ci={Pl, Sm}, где Pl= , (3) Sm=, (4) P – предложение. То есть ответы экспертов должны состоять из таких слов, признаковая и смысловая части которых являлись бы одноместными кортежами аспектов. Для удовлетворения требованиям (3), (4) вопросы экспертам формулируются по одному из типов: · от чего зависит <имя атрибута> <имя объекта>, · чем определяется <имя атрибута> <имя объекта>, а дополнительное задание заключается в требовании упорядочить факторы (все ci) по степени влияния на значения атрибута объекта, имена которых содержатся в вопросе. Таким образом устанавливаются отношения предпочтения c1>c2>…>ck, (5) а следовательно, выполняется требование (3). Такая постановка вопросов позволяет выбрать из множества объектов предметной области соответствующие заданию, наложить определенные ограничения на множества атрибутов, характеризующих объект, отделить в ограниченном множестве существенные признаки от несущественных. Вторичная семантическая информация отражает посредством знаков результаты аналитико-синтетического и логического преобразований первичной семантической информации и является моделью первичной. Получение вторичной семантической информации неизбежно связано с разрушением структуры первичной семантической информации и построением новой, отличной от первой. При сжатии первичной семантической информации используем модельный способ, для которого характерно строгое формализованное задание, его общими понятиями являются объекты, атрибуты и домены [2]. При построении формальной модели вводится ограничение на количество аспектов в слове вторичной семантической информации, которое должно равняться двум, так как из первичной семантической информации необходимо выделять пары <имя объекта, имя атрибута>. Разделение категорий на объекты и атрибуты не всегда может быть очевидным, поэтому для выделения атрибутов из текстов естественного языка используем их основные свойства: - наличие конечного множества возможных значений атрибута; - возможность упорядочения результатов измерений; - измеряемость значений хотя бы по одному из показателей и др. Введение домена в качестве избыточной семантической информации необходимо для уточнения имен объектов и имен атрибутов в связи с неоднозначностью естественного языка. Домен дает возможность конкретизировать имена объектов и имена атрибутов, которые в ответах экспертов могут только подразумеваться или выражаться общими понятиями, и представляет собой множество знаков. Семантическая интерпретация знака – это слово, состоящее из имени объекта и имени атрибута, которые являются элементами концептуальной схемы предметной области, то есть возможно установление взаимно однозначного соответствия: объект«атрибут«значение, " (dÎDom) $ , (iÎRa). Таким образом, получена система семантических уравнений для данной первичной семантической информации
где Rdom – отношение «иметь значение»; Oxi, ayi – имена неизвестных объектов и их атрибутов. Определить домен предлагается экспертам в предположении, что признаковая часть слова является именем атрибута, а смысловая – именем объекта. Далее решается система семантических уравнений (6) с использованием интерпретации посредством соответствующего слова из (5) и с использованием свойств (1), (2). Из-за неопределенности и неоднозначности естественного языка такая интерпретация может оказаться невозможной. Поэтому с помощью экспертов вводятся дополнительные аспекты, которые при построении первичной семантической информации могли только подразумеваться. Таким образом осуществляется конкретизация первичной семантической информации. Элементы di, имеющие одну и ту же интерпретацию, объединяются во множества и образуют домен для . Сжатие семантической информации осуществляется для каждого фактора, входящего в первичную семантическую информацию. В результате из первичной семантической информации выделяется множество имен объектов и имен их атрибутов. Для выделенных объектов и атрибутов повторяется процедура построения отношения предпочтения (5). Введение понятия домена в формальную модель целесообразно и потому, что значения доменов в дальнейшем будут использоваться при построении полной модели предметной области стратегического управления предприятием. Результатом выполнения методики является таблица, содержащая колонки: эксперт, имя объекта, имя атрибута, домен. В колонке эксперт указывается идентификатор эксперта, предоставившего соответствующую первичную семантическую информацию; в колонке имя объекта – имена выделенных объектов; в колонке имя атрибута – соответствующие имена атрибутов; в колонку домен заносится значение домена соответствующего атрибута объекта. После завершения k-го шага декомпозиции выделенные факторы ранжируются по важности методом парных сравнений [3]. Концептуальная схема предметной области, основанная на выделении имен объектов, имен их атрибутов и отношений, является достаточно обобщенной, поэтому не может быть моделью решения задач прогнозирования развития предприятия. Тем не менее, она описывает факты зависимости значений атрибутов одних объектов от значений атрибутов других, а построенная на ее основе модель дает возможность автоматизировать процесс формирования полной модели предметной области управления стратегическим развитием предприятия. Литература 1. Попов Э.В. Экспертные системы: решение неформализованных задач в диалоге с ЭВМ. М.: Наука, 1987. 2. Поспелов Д.А. Моделирование рассуждений: опыт и анализ мыслительной деятельности. М.: Радио и связь, 1989. 3. Рабочая книга по прогнозированию. М.: Мысль, 1982. |
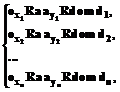 (6)
(6)http://swsys.ru/index.php?id=2518&lang=%E2%8C%A9%3Den&like=1&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Построение структуры предметной области на основе анализа концептуальной схемы
- Прогнозирование временного ряда инфекционной заболеваемости
- Программная среда прогнозирования вероятностной надежности элементов сложных электротехнических систем
- Адекватные междисциплинарные модели в прогнозировании временных рядов статистических данных
- Подход к оценке сложности диаграмм SADT (IDEF0)