Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Оптимальность структурирования программных ресурсов при конвейерной распределенной обработке
Аннотация:Получены формулы и оценки минимального общего времени выполнения однородных распределенных конкурирующих процессов. Проведен сравнительный анализ режимов взаимодействия процессов, процессоров и блоков программного ресурса. Сформулированы и доказаны критерии эффективности и оптимальности структурирования программных ресурсов.
Abstract:Formulas and estimations of minimum general time of performance of the homogeneous distributed com- peting processes are received. The comparative analysis of modes of interaction of processes, processors and blocks of a program resource is carried out. Are formulated criterion of efficiency and an optimality of structurization of program resources.
| Авторы: Павлов П.А. (pavlov.p@polessu.by) - Полесский государственный университет, Беларусь, г. Пинск (доцент), Пинск, Беларусь, кандидат физико-математических наук | |
| Ключевые слова: оптимальность, эффективность, характеристический набор, ограниченный (неограниченный) параллелизм, структурирование, асинхронный и синхронный режимы, однородная система, программный ресурс, распределенный процесс |
|
| Keywords: optimality, effectively, characteristic set, the limited (unlimited) parallelism, the structurization, asynchronous mode, homogeneous system, the program resource, the distributed process |
|
| Количество просмотров: 10455 |
Версия для печати Выпуск в формате PDF (5.84Мб) Скачать обложку в формате PDF (1.43Мб) |
В различных областях человеческой деятельности постоянно приходится сталкиваться с большими задачами, эффективное решение которых связано с распараллеливанием процессов вычислений. Решение подобных задач объединяет в единое целое сведения из таких областей, как архитектура компьютеров и вычислительных систем, системное программирование и языки программирования, различные методы обработки информации и т.д. [1]. С появлением и активным использованием масштабируемых систем многие проблемы параллельных вычислений приходится переосмыслить, по-новому взглянуть на принципы организации вычислений, на создание эффективного аппаратного, алгоритмического и программного обеспечения многопроцессорных систем (МС), на обеспечение однозначности результата выполнения программ, на эффективное планирование и распределение параллельных процессов [2]. В связи с этим особую актуальность приобретают задачи построения и исследования математических моделей параллельных распределенных процессов, основанных на принципах распараллеливания и конвейеризации. Математическая модель распределенной обработки конкурирующих процессов. Для построения математических моделей распределенных вычислительных систем конструктивными элементами являются понятия процесса и программного ресурса. Как и в [3], процесс рассмотрим как последовательность блоков (команд, процедур) Q1, Q2, …, Qs, для выполнения которых используется множество процессоров (процессорных узлов, обрабатывающих устройств). При этом процесс называется распределенным, если все блоки или часть их обрабатываются разными процессорами. Для ускорения выполнения процессы могут обрабатываться параллельно, взаимодействуя путем обмена информацией. Такие процессы называются кооперативными, или взаимодействующими. Понятие ресурса используется для обозначения любых объектов вычислительной системы, которые могут использоваться процессами для своего выполнения. Реентерабельные (многократно используемые) ресурсы характеризуются возможностью одновременного использования несколькими процессами. Для параллельных систем характерной является ситуация, когда одну и ту же последовательность блоков или ее часть процессорам необходимо выполнять многократно. Такую последовательность будем называть программным ресурсом (ПР), а множество соответствующих процессов – конкурирующими. Математическая модель распределенной обработки конкурирующих процессов включает в себя p процессоров МС, n конкурирующих процессов, s блоков Q1, Q2, …, Qs структурированного на блоки программного процесса, матрицу Tp=[tij] времен выполнения j-х блоков i-ми конкурирующими процессами [3–5]. Указанные параметры изменяются в пределах p³2, n³2, s³2, 1£i£n, 1£j£s. Будем предполагать, что все n процессов используют одну копию структурированного на блоки ПР, а на множестве блоков установлен линейный порядок их выполнения. Введем в рассмотрение параметр t>0, характеризующий время (системные расходы), затрачиваемое МС на организацию параллельного выполнения блоков программного ресурса множеством распределенных конкурирующих процессов. В дальнейшем будем говорить, что вышеперечисленные объекты математической модели образуют систему распределенных конкурирующих процессов. Определение 1. Система n распределенных конкурирующих процессов называется неоднородной, если время выполнения блоков программного ресурса Q1, Q2, …, Qs зависит от объема обрабатываемых данных и/или их структуры, то есть разное для разных процессов. Определение 2. Система n распределенных конкурирующих процессов называется однородной, если время выполнения j-го блока каждым i-м процессом равно, то есть tij=tj, Будем считать, что взаимодействие процессов, процессоров и блоков подчинено следующим условиям [3–5]: 1) ни один из блоков программного ресурса не может обрабатываться одновременно более чем одним процессором; 2) ни один из процессоров не может обрабатывать одновременно более одного блока; 3) обработка каждого блока осуществляется без прерываний; 4) распределение блоков программного ресурса по процессорам для каждого из процессов осуществляется циклически по правилу: блок с номером j=kp+i, Кроме того, введем дополнительные условия, которые определяют режимы взаимодействия процессов, процессоров и блоков: 5) отсутствуют простои процессоров при условии готовности блоков, а также невыполнение блоков при наличии процессоров; 6) для каждого из n процессов момент завершения выполнения j-го блока на i-м процессоре совпадает с моментом начала выполнения следующего (j+1)-го блока на (i+1)-м процессоре, 7) для каждого из блоков момент завершения его выполнения l-м процессом совпадает с моментом начала его выполнения (l+1)-м процессом на том же процессоре, Условия 1–5 определяют асинхронный режим взаимодействия процессоров, процессов и блоков, который предполагает отсутствие простоев процессоров при условии готовности блоков, а также невыполнение блоков при наличии процессоров. Если к условиям 1–4 добавить условие 6, то получим первый синхронный режим, обеспечивающий непрерывное выполнение блоков программного ресурса внутри каждого из процессов. Второй синхронный режим, определяемый условиями 1–4, 7, обеспечивает непрерывное выполнение каждого блока всеми процессами. Время реализации однородных систем распределенных конкурирующих процессов. В работах [3, 4] исследованы базовые асинхронный и синхронные режимы, возникающие при организации распределенных процессов в условиях конкуренции за общий программный ресурс. В рамках этих режимов получены математические соотношения для вычисления значений минимального общего времени выполнения неоднородных распределенных конкурирующих процессов в случаях неограниченного (s£p) и ограниченного (s>p) параллелизма по числу процессоров МС. Рассмотрим однородную систему распределенных конкурирующих процессов. Пусть Рассмотрим случай, когда s=kp, k>1. Введем следующие обозначения: Общее время выполнения n конкурирующих распределенных однородных процессов в случае s=kp, k>1, определяется как сумма длин составляющих диаграмм Ганта с учетом максимально допустимого совмещения по оси времени, то есть
Здесь
В случае s=kp+r, k³1, 1£r
где Если взаимодействие процессов, процессоров и блоков осуществляется во втором синхронном режиме, при котором для каждого блока структурированного программного ресурса момент завершения его выполнения для i-го процесса совпадает с началом его выполнения для (i+1)-го процесса на том же процессоре,
Значения Tl, · ·
· ·
Анализ режимов организации распределенных конкурирующих процессов. Определенный теоретический и практический интерес представляет задача сравнительного анализа соотношений для определения минимального общего времени выполнения множества распределенных конкурирующих процессов. Проведем такой анализ для класса однородных систем с учетом дополнительных системных расходов t>0. Рассмотрим однородную систему распределенных конкурирующих процессов с временем выполнения блоков структурированного на блоки программного процесса Пусть
Тогда для введенного подмножества характеристических наборов справедлива теорема 1. Теорема 1. Пусть Доказательство. Пусть
где Пусть взаимодействие процессов, процессоров и блоков осуществляется во втором синхронном режиме с непрерывным переходом по процессам. В этом режиме для любого характеристического набора из множества b при 2£s£p выполняется равенство
Покажем, что для любого характеристического набора Учитывая, что Теорема 2. Для любой однородной распределенной системы с параметрами p, n, s и накладными расходами t>0, допустимый характеристический набор которой
Доказательство. Условие теоремы 2 равносильно неравенству При s=2 множество всех допустимых характеристических наборов однородных систем конкурирующих процессов При s=3 справедливость неравенства (2) для Пусть неравенство (2) выполняется при s=i, то есть Действительно, при s=i+1 имеем
Рассмотрим два случая. 1) Максимальное значение Здесь второе слагаемое равно нулю, так как 2) Значение Здесь При Эффективность систем однородных конкурирующих процессов в условиях неограниченного параллелизма. Введем следующее определение, которое выделяет в классе однородных систем конкурирующих процессов специальный подкласс так называемых равномерных систем. Определение 3. Однородную распределенную систему конкурирующих процессов назовем равномерной, если выполняется цепочка равенств В теореме 1 доказано, что для однородных систем конкурирующих процессов минимальное общее время с учетом накладных расходов t>0 для всех трех базовых режимов, указанных ранее, в случае s£p вычисляется по формуле
где В случае равномерной однородной системы конкурирующих процессов минимальное общее время их выполнения определяется равенством
где tt=Ts/s+t, Ts=st. Определение 4. Однородную систему распределенных конкурирующих процессов будем называть эффективной при фиксированных p, n³2, если выполняется соотношение При наличии двух эффективных однородных систем конкурирующих процессов будем считать, что первая более эффективна, чем вторая, если величина Dt(s) первой системы не меньше соответствующей величины второй. Для введенного подмножества однородных систем справедливо следующее утверждение. Теорема 3. Для любой эффективной однородной системы конкурирующих процессов при s£p и t>0 существует более эффективная равномерная однородная распределенная система. Доказательство. Рассмотрим любую эффективную однородную распределенную конвейерную систему. Согласно определению 4 условие ее эффективности с учетом (3) записывается в виде следующего неравенства:
где Для любой равномерной однородной распределенной системы с учетом (4) имеем, что
где Чтобы убедиться в справедливости теоремы 3, достаточно доказать выполнение неравенства Докажем справедливость последнего неравенства. Рассмотрим равномерную однородную распределенную систему, в которой
что и доказывает теорему. Следующее утверждение устанавливает достаточное условие эффективности однородной системы в случае неограниченного параллелизма. Теорема 4. Однородная система конкурирующих процессов с параметрами p, n, s, t, удовлетворяющая соотношениям 3£s£p, s=n¹3, ns³2(n+s-1) и Доказательство. Согласно (5) условие эффективности равносильно неравенству
Следовательно, для доказательства теоремы 4 достаточно убедиться в справедливости неравенства (7). Непосредственная проверка показывает, что следствием соотношений
так как в силу выбора t выполняется неравенство Из ns³2(n+s-1) следует справедливость неравенства
Проверка показывает, что неравенство (7) является следствием неравенств (8) и (9). Таким образом, теорема 4 доказана. Сформулируем и докажем критерий существования эффективной однородной системы распределенных конкурирующих процессов при достаточном числе процессоров в зависимости от величины накладных расходов t. Теорема 5. Для существования эффективного структурирования программного ресурса при заданных параметрах 3£s£p, Ts, t>0 необходимо и достаточно, чтобы выполнялись следующие условия:
где Доказательство. Согласно (6) условие эффективности любой однородной распределенной системы конкурирующих процессов равносильно неравенству
Введем в рассмотрение функцию Нетрудно проверить, что она достигает своего максимума в точке Достаточность следует из (11), поскольку j(x) достигает наибольшего значения при Замечание. При p=s=2 структурирование программного ресурса будет эффективным, если выполняется оптимальность одинаково распределенных систем конкурирующих процессов. Определение 5. Эффективная одинаково распределенная система называется оптимальной, если величина De достигает наибольшего значения. Ранее показано, что оптимальную однородную распределенную систему достаточно искать среди эффективных однородных распределенных систем. Более того, в силу теоремы 3 оптимальную однородную распределенную систему следует искать среди равномерных однородных распределенных систем. Тогда с учетом (6) имеем
Введем функцию действительного аргумента x вида
Решение задачи об оптимальности равномерного структурирования программного ресурса на s блоков для достаточного числа процессоров для всех трех базовых режимов следует из теоремы 6. Теорема 6. Для того чтобы эффективное структурирование программного ресурса на s блоков при s£p было оптимальным при заданных s³2, Ts, t>0, необходимо и достаточно, чтобы оно было равномерным и число блоков s0 равнялось одному из чисел
в котором функция Доказательство. Необходимость. Рассмотрим введенную функцию
Согласно определению 5 однородная распределенная система будет оптимальной в той точке x, где функция Следовательно, функция Целочисленными точками, в которых достигается наибольшее значение функции Если же окажется, что ни одна из точек ция В силу отрицательности второй производной исследуемая функция выпукла. Следовательно, точка максимума всегда существует, а значит, существует и эффективная однородная распределенная система конкурирующих процессов в случае, когда s®¥. Достаточность следует из свойств выпуклости функции Обобщая, отметим, что полученные критерии эффективности и оптимальности структурирования программных ресурсов могут использоваться при проектировании системного и прикладного программного обеспечения МС и вычислительных комплексов. Полученные формулы также служат основой для решения задач оптимизации числа процессоров при заданных объемах вычислений и (или) директивных сроках реализации процессов, исследования всевозможных смешанных режимов организации выполнения параллельных процессов при распределенной обработке, в том числе с учетом ограниченного числа копий структурированного программного ресурса и прочего. Литература 1. Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. СПб: БХВ–Петербург, 2002. 608 с. 2. Топорков В.В. Модели распределенных вычислений. М.: Физматлит, 2004. 320 с. 3. Иванников В.П., Коваленко Н.С., Метельский В.М. О минимальном времени реализации распределенных конкурирующих процессов в синхронных режимах // Программирование. 2000. № 5. С. 44–52. 4. Kapitonova Yu.V., Kovalenko N.S., Pavlov P.А. Optimality of systems of identically distributed competing processes // Cybernetics and Systems Analysis. New York: Springer, 2006, pp. 793–799. 5. Павлов П.А. Анализ режимов организации одинаково распределенных конкурирующих процессов // Вест. БГУ. Сер. 1: Физматинформ. 2006. № 1. С. 116–120. |
 ,
,  .
. , k³0, распределяется на процессор с номером i.
, k³0, распределяется на процессор с номером i. ,
,  ;
; .
. – длительности выполнения каждого блока Qj,
– длительности выполнения каждого блока Qj,  и первом синхронном режиме
и первом синхронном режиме  будем иметь
будем иметь  .
. – время выполнения j-го блока l-й группы всеми n процессами,
– время выполнения j-го блока l-й группы всеми n процессами,  ,
,  ;
;  – общее время выполнения l-й группы блоков всеми n процессами на p процессорах,
– общее время выполнения l-й группы блоков всеми n процессами на p процессорах,  – время завершения выполнения [(l-1)p+j]-го блока программного ресурса всеми n процессами на j-м процессоре,
– время завершения выполнения [(l-1)p+j]-го блока программного ресурса всеми n процессами на j-м процессоре,  .
. – отрезок возможного совмещения по оси времени, представляющий собой разность между моментом начала выполнения j-го блока первым процессом для (l+1)-й группы блоков и моментом завершения выполнения j-го блока последним процессом для l-й группы блоков;
– отрезок возможного совмещения по оси времени, представляющий собой разность между моментом начала выполнения j-го блока первым процессом для (l+1)-й группы блоков и моментом завершения выполнения j-го блока последним процессом для l-й группы блоков;  – разность между началом выполнения первого блока i-м процессом для (l+1)-й группы блоков и моментом завершения выполнения p-го блока i-м процессом для l-й группы блоков, которые вычисляются по формулам
– разность между началом выполнения первого блока i-м процессом для (l+1)-й группы блоков и моментом завершения выполнения p-го блока i-м процессом для l-й группы блоков, которые вычисляются по формулам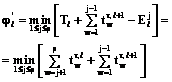 ,
, ,
, .
.
 – время выполнения (k+1)-й группы r блоков всеми n процессами;
– время выполнения (k+1)-й группы r блоков всеми n процессами;  – разность между моментом начала выполнения j-го блока первым процессом для (k+1)-й группы блоков и моментом завершения выполнения j-го блока последним процессом для k-й группы блоков;
– разность между моментом начала выполнения j-го блока первым процессом для (k+1)-й группы блоков и моментом завершения выполнения j-го блока последним процессом для k-й группы блоков;  – разность между началом выполнения первого блока i-м процессом для (k+1)-й группы блоков и моментом завершения выполнения p-го блока i-м процессом для k-й группы блоков.
– разность между началом выполнения первого блока i-м процессом для (k+1)-й группы блоков и моментом завершения выполнения p-го блока i-м процессом для k-й группы блоков. то минимальное общее время
то минимальное общее время  выполнения n однородных процессов на p процессорах определяется по формулам
выполнения n однородных процессов на p процессорах определяется по формулам при s£p,
при s£p,
 ,
,  ,
,  ,
,  ,
,  вычисляются по формулам
вычисляются по формулам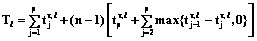 – общее время выполнения l-х p блоков программного ресурса всеми n процессами на p процессорах,
– общее время выполнения l-х p блоков программного ресурса всеми n процессами на p процессорах,  ,
, ,
,  ,
, 
 – время выполнения (k+1)-х r блоков для всех n процессов;
– время выполнения (k+1)-х r блоков для всех n процессов; – величина максимального совмещения по оси времени k-й и (k+1)-й диаграмм:
– величина максимального совмещения по оси времени k-й и (k+1)-й диаграмм:
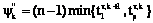 .
. . Обозначим через
. Обозначим через 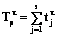 суммарное время выполнения программного ресурса каждым из процессов с учетом накладных (системных) расходов и назовем набор параметров
суммарное время выполнения программного ресурса каждым из процессов с учетом накладных (системных) расходов и назовем набор параметров 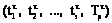 данной системы характеристическим.
данной системы характеристическим. есть множество всех допустимых характеристических наборов систем однородных конкурирующих процессов. Выделим из множества b подмножество характеристических наборов вида
есть множество всех допустимых характеристических наборов систем однородных конкурирующих процессов. Выделим из множества b подмножество характеристических наборов вида
 – характеристический набор любой однородной системы с параметрами p, n, s³2 и накладными расходами t>0. Тогда в случае неограниченного параллелизма минимальное общее время
– характеристический набор любой однородной системы с параметрами p, n, s³2 и накладными расходами t>0. Тогда в случае неограниченного параллелизма минимальное общее время  ,
,  и
и  выполнения множества однородных распределенных конкурирующих процессов в асинхронном и базовых синхронных режимах совпадают.
выполнения множества однородных распределенных конкурирующих процессов в асинхронном и базовых синхронных режимах совпадают. . Тогда для асинхронного и первого синхронного режима с непрерывным переходом по блокам для любого характеристического допустимого набора однородной системы, в том числе и для любого характеристического набора
. Тогда для асинхронного и первого синхронного режима с непрерывным переходом по блокам для любого характеристического допустимого набора однородной системы, в том числе и для любого характеристического набора 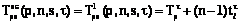 ,
, ,
,  .
. , тем самым будет доказана теорема.
, тем самым будет доказана теорема.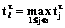 , для всех номеров j£l имеет место равенство
, для всех номеров j£l имеет место равенство  , а для j>l имеет место
, а для j>l имеет место  . Следовательно,
. Следовательно, 
 , что и требовалось доказать.
, что и требовалось доказать. , при 2£s£p выполняются соотношения
, при 2£s£p выполняются соотношения . (2)
. (2)
 . Доказательство последнего проведем индукцией по числу блоков s, s³2.
. Доказательство последнего проведем индукцией по числу блоков s, s³2. будет принадлежать классу
будет принадлежать классу  .
. . Покажем, что оно справедливо при s=i+1.
. Покажем, что оно справедливо при s=i+1.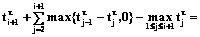

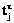 , 1£j£i+1, равно
, 1£j£i+1, равно  , тогда
, тогда 
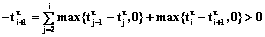 .
. , а первое слагаемое больше нуля, в противном случае
, а первое слагаемое больше нуля, в противном случае  находится в промежутке 1£j£i. В этом случае имеем:
находится в промежутке 1£j£i. В этом случае имеем: 

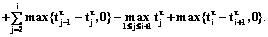
 по индукционному предположению и в силу того, что
по индукционному предположению и в силу того, что  . Покажем, что
. Покажем, что 
 . Действительно, для
. Действительно, для  равенство нулю очевидно.
равенство нулю очевидно.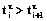 получаем
получаем  , а при
, а при 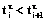 имеем
имеем 
 , что и требовалось доказать.
, что и требовалось доказать. .
. , (3)
, (3) .
. , (4)
, (4)
 , где nTs – время выполнения n процессов в последовательном режиме;
, где nTs – время выполнения n процессов в последовательном режиме;  .
. , (5)
, (5)
 .
. , (6)
, (6) .
. ³ ³Dt для введенных эффективных систем. Подставив в левую и правую части последнего неравенства из (5) и (6) вместо
³ ³Dt для введенных эффективных систем. Подставив в левую и правую части последнего неравенства из (5) и (6) вместо  и Dt(s£p) соответствующие величины и проведя несложные преобразования, приходим к равносильному неравенству
и Dt(s£p) соответствующие величины и проведя несложные преобразования, приходим к равносильному неравенству  .
. . Пусть для определенности
. Пусть для определенности  , тогда справедлива цепочка соотношений
, тогда справедлива цепочка соотношений ,
, , является эффективной.
, является эффективной. . (7)
. (7) является цепочка неравенств
является цепочка неравенств , (8)
, (8) .
. . (9)
. (9) (10)
(10) , [x] – наибольшее целое, не превосходящее x.
, [x] – наибольшее целое, не превосходящее x. (11)
(11) .
. при x>0. Выбрав в качестве эффективного структурирование на s блоков, при котором
при x>0. Выбрав в качестве эффективного структурирование на s блоков, при котором  , если
, если  – целое, или
– целое, или  , если
, если  , если
, если  .
. .
.
 ,
, достигает наибольшего значения. Здесь [x] означает наибольшее целое, не превосходящее x.
достигает наибольшего значения. Здесь [x] означает наибольшее целое, не превосходящее x. . Действительно,
. Действительно, 

 так как n³2, x>0.
так как n³2, x>0. , то есть
, то есть 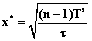 .
.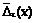 , будут s0=[x*] или s0=[x*]+1. Следовательно, в качестве S0 можно выбрать одно из чисел
, будут s0=[x*] или s0=[x*]+1. Следовательно, в качестве S0 можно выбрать одно из чисел  , в которых функция
, в которых функция | Постоянный адрес статьи: http://swsys.ru/index.php?id=2564&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.84Мб) Скачать обложку в формате PDF (1.43Мб) |
| Статья опубликована в выпуске журнала № 3 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Синхронный режим распределенных вычислений при непрерывном выполнении блоков ограниченного числа копий программного ресурса
- Распределенные вычисления при ограниченном числе копий программного ресурса
- Оценка эффективности систем логического вывода модифицируемых заключений
- Методы восстановления рабочего состояния приложения
- Об эффективности наследования таблиц в СУБД PostgreSQL
Назад, к списку статей