Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Технология создания адаптируемых систем обработки информации
Аннотация:Описывается технология создания адаптируемых систем обработки информации, охватывающая весь жизненный цикл создания системы и позволяющая закладывать в архитектуру разрабатываемых систем свойство независимости от реализаций конкретных алгоритмов обработки информации. В качестве примера практической реализации рассматривается задача машинного перевода текстов для мобильных устройств.
Abstract:This article describes the technology for creating of adaptive information processing systems. The problem of machine translation of texts for mobile devices is given for an example. The described technology includes the entire lifecycle of the system and allows the architecture to be independent of the implementation of specific algorithms for processing information.
| Автор: Чередниченко А.В. (A.Cherednichenko@mail.ru) - Московский государственный университет леса | |
| Ключевые слова: алгоритмы, масштабируемость, паттерн/шаблон, адаптируемая система, технология, обработка информации |
|
| Keywords: algorithms, scalable, pattern, adaptive system, technology, information processing |
|
| Количество просмотров: 12266 |
Версия для печати Выпуск в формате PDF (5.84Мб) Скачать обложку в формате PDF (1.43Мб) |
В данной статье предлагается технология создания ядра прикладной вычислительной системы, легко адаптируемого к различным внешним компонентам, обслуживающим потребности вычислительной системы. Разработка систем с подобным адаптируемым ядром подразумевает применение паттернов проектирования для наделения архитектуры создаваемой системы требуемыми свойствами. Однако применение паттернов не гарантирует создание системы с расширяемой функциональностью и способной эффективно выполнять поставленные перед ней задачи в случае изменения требований к функциональности. В качестве примера рассмотрим вычислительную систему для осуществления машинного перевода. Предположим, что основной средой применения данной системы будут платформы, используемые в сотовых телефонах. Для анализа исходного текста необходимо использовать морфологический и синтаксический анализаторы, а также другие необходимые лингвистические ресурсы, реализованные к настоящему моменту и имеющиеся в продаже (или свободно использующиеся). Причем эти компоненты разработаны различными фирмами, подчиняются всевозможным требованиям и стандартам, могут использовать разные структуры данных. Тривиальное решение предполагает написание системы, к которой будут подключены конкретные выбранные компоненты. Но если потребуется изменить реализацию одного из анализаторов, придется изменять систему и структуры данных, используемых для взаимодействия с внешними анализаторами. Также одним из основных требований при постановке задачи является возможность при продаже телефона (или математического обеспечения для определенной платформы) установить с нуля или откорректировать в соответствии с требованиями покупателя (действующего в конкретном регионе) свойства вычислительной системы. Такими свойствами могут быть множество языков и направления для перевода, уровень качества перевода, тематика переводимых текстов и т.п. Для этого необходимо обеспечить использование определенного набора компонент. В ядре прикладной вычислительной системы должна быть предусмотрена такая функциональность (без необходимости изменения самого ядра разработчиками системы).
Аналогом данной технологии можно считать сервис-ориентированную архитектуру [2], при работе с которой используется базовое понятие «сервис». Реализация бизнес-логики в сервис-ориентированном приложении состоит в последовательном использовании уже имеющихся реализованных сервисов. В случае использования предлагаемой технологии ядро разрабатываемой системы будет использовать внешние компоненты с максимально абстрактным для выбранной предметной области интерфейсом (см. рисунок). Описываемая технология основана на следующих принципах: - изучение имеющихся реализаций внешних компонентов, которые необходимо будет подключать к системе; - выделение максимально абстрактного интерфейса, учитывающего все параметры компонентов, которые необходимо будет выполнять в роли внешних по отношению к ядру системы; - предоставление на уровне ядра системы возможности выбора конкретной реализации алгоритма – программного компонента. Рассмотрим подробнее каждый из шагов создания. Имея выбор при проектировании системы из нескольких решений одной и той же задачи, архитектор системы может использовать конкретную реализацию, что наложит определенные ограничения на всю архитектуру. В случае проектирования расширяемой системы увеличивается стоимость разработки архитектуры и проведения предпроектного обследования, однако в процессе сопровождения системы появляется возможность легко расширять набор подключенных компонентов без изменения архитектуры системы. Как правило, ограничения, заложенные на этапе создания архитектуры, практически не устранимы в процессе опытной, а тем более, промышленной эксплуатации системы. В соответствии с предлагаемой технологией нужно выделить все компоненты, которые могут существовать в уже реализованном виде; для каждого такого компонента описать абстрактный интерфейс, учитывающий все возможные комбинации параметров компонентов (например, морфологический анализатор для использования в лингвистических процессорах). В точке входа в компонент следует использовать именно этот абстрактный интерфейс. В качестве аналогии приведем паттерны проектирования Abstract Factory, Facade, Proxy [3]. Для рассматриваемого примера можно выделить следующие абстрактные интерфейсы: получение исходного текста, определение тематики текста, осуществление перевода, выдача перевода пользователю. Каждый из интерфейсов должен быть максимально абстрактным. Так, например, получение исходного текста может содержать лишь один выходной параметр – это сам текст. Конкретная реализация алгоритма ввода текста будет зависеть от технических возможностей приборов, использующих создаваемую систему. Компоненты, связанные с переводом на начальном этапе создания системы, могут иметь реализацию, поддерживающую лишь общую лексику, без каких-либо специфических словарей и компонентов анализа/синтеза естественно-языковых текстов. Выделение абстрактного интерфейса подразумевает изучение изначального алгоритма, а также как минимум одной его реализации для подключения и запуска системы в эксплуатацию. Важной деталью является возможность сериализации (при необходимости) параметров для вызова компонента. При проектировании необходимо предусмотреть объектно-ориентированные па- раметры с возможностью сериализации (в зависимости от поставленной задачи). Данный шаг яв- ляется более техническим и в случае создания переводчика может лишь означать выбор технологической платформы для реализации системы. В качестве примера можно привести решение использовать динамически подключаемые библиотеки (dynamic-link library – dll) с известным интерфейсом (степень объектности этого интерфейса зависит от конкретных реализаций компонентов). А именно: wraper для большого количества известных реализаций морфологического анализатора русского языка может получать на входе слово, а на выходе предоставлять структуру с максимально возможным количеством грамматических категорий (для передачи граммем [4]). Приняв достаточно важное решение о выделении всего функционала, связанного с выполнением функции собственно перевода, в отдельный компонент, оставим ядру системы лишь решение задачи ввода и вывода текстов. В случае с машинным переводом это может быть целесообразно, так как появляется возможность применения кардинально различных реализаций для этапа анализа и синтеза текстов. С другой стороны, в абстрактном интерфейсе можно предусмотреть передачу критериев для возможности принятия решения о выборе реализации. В примере с машинным переводом набором критериев могут являться такие параметры, как точность перевода, его скорость, выполнение перевода для заполнения лингвистической БД. Самым важным шагом является предоставление на уровне ядра возможности выбора (пользователем или в автоматическом режиме) реализации конкретного алгоритма. Выделение каких-либо критериев для автоматического выбора той или иной реализации должно происходить либо на этапе создания архитектуры системы, либо позже, путем передачи каких-то данных для автоматического выбора во внешний компонент, который, в свою очередь, вызовет наиболее подходящую реализацию. В отличие от приведенных примеров паттернов проектирования данная технология не только подразумевает обеспечение уровня независимости, но и рассматривает использование подключенных компонентов. В приведенном примере создания прибора-переводчика выбор конкретного алгоритма-исполнителя осуществляется путем передачи критериев абстрактному интерфейсу. Семантика использования этих критериев диктуется ядром системы. Вопрос выбора компонентов можно решить иначе. В переводчике, к примеру, использование конкретной лингвистической БД может быть указано пользователем. В этой БД могут храниться как определенные специализированные словари, так и правила анализа и синтеза предложений из этой предметной области [1]. Скажем, выделив тему «передвижение по дорогам на автомобиле», модули анализа и синтеза будут оперировать простыми односложными предложениями. При этом, если не требовать от переводчика полного соответствия переводов, можно получить представление о направлении движения либо о каких-то маршрутах объезда и о дорожных пробках. В противном случае для получения максимально точного перевода можно разбить лингвистическую базу на отдельные разделы, касающиеся проезда по различным типам дорог или в различных погодных условиях и т.п. Кроме того, введя критерии автоматизированного выбора лингвистической БД, можно предоставлять пользователям наиболее актуальный режим работы приложения. К примеру, анализируя скорость передвижения при постоянной низкой скорости, автоматически выбрать вариант более качественного перевода, который позволит пользователю точнее отреагировать на дорожную обстановку и объехать возникшую пробку. В случае использования абстрактного интерфейса для ввода данных можно предложить вводить данные с изображениями дорожных знаков исходной страны, чтобы получить перевод значения этих знаков на свой родной язык. Как видно из приведенного примера, реализация на основе изменяемых требований к качеству и свойствам алгоритмов решения задачи (или ее части) требует отдельного подхода. Практика показывает, что изменение требований к реализации алгоритмов на уровне ядра приводит к необходи- мости подключения к ядру (либо к его полной замене) дополнительных компонентов, наиболее подходящих в данный момент. Наделение же ядра системы свойством расширяемости, а также следование определенным правилам при создании системы позволяют создать программный продукт, способный управлять поступающей информацией, принимая на ее основе максимально эффективные решения по управлению состоянием системы. Литература 1. Волкова И.А. Введение в компьютерную лингвистику. Практические аспекты создания лингвистических процессоров. М.: Изд-во ф-та ВМиК МГУ, 2006. 2. Norbert Bieberstein, Sanjay Bose, Marc Fiammante, Keith Jones, Rawn Shah. Service-Oriented Architecture (SOA) Compass: Business Value, Planning, and Enterprise Roadmap // IBM Press, 2006. 3. Гамма Э., Хелм Р., Джонсон Р., Влиссидес Дж. Приемы объектно-ориентированного проектирования. Паттерны. СПб: «Питер», 2007. 4. Сокирко А.В. Морфологические модули на сайте www.aot.ru // Диалог'2004: тр. Междунар. конф. М.: Наука, 2004. |
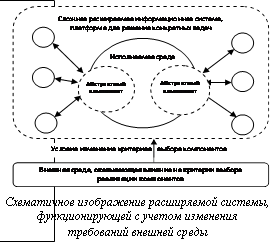 Автором предлагается новая технология создания легко расширяемого прикладного ПО с заранее определенным свойством функционального масштабирования (дополнения функциональности без изменения архитектуры системы). В результате использования данной технологии разрабатываемое ПО будет обладать свойством расширяемости функциональности, которое позволяет под воздействием внешних (и, возможно, внутренних) условий добавлять функциональность системе без драматических изменений архитектуры ее ядра. Для наделения системы этим свойством ее ядро должно эффективно решать задачу управления новыми реализациями компонентов новой требуемой функциональности. В качестве примера-иллюстрации предлагаемого подхода рассмотрим создание прибора, позволяющего осуществлять автоматический перевод (возможно, автоматизированный) текста на естественном языке. Для эффективного решения поставленной задачи необходимо реализовать несколько основных компонентов: модуль ввода текста (возможно, с какого-либо сканера изображений, либо с помощью ручного ввода, либо с помощью системы распознавания голоса); модуль перевода входного текста на естественном языке; лингвистическую БД (словари, какие-либо настройки модуля перевода для различных языков и т.п. [1]); модуль вывода текста пользователю (вывод на экран, на печать, генерация аудиопотока и т.п.). При создании данного прибора необходимо учитывать возможность добавления новых языков для перевода, использования специализированных лингвистических ресурсов и модулей перевода.
Автором предлагается новая технология создания легко расширяемого прикладного ПО с заранее определенным свойством функционального масштабирования (дополнения функциональности без изменения архитектуры системы). В результате использования данной технологии разрабатываемое ПО будет обладать свойством расширяемости функциональности, которое позволяет под воздействием внешних (и, возможно, внутренних) условий добавлять функциональность системе без драматических изменений архитектуры ее ядра. Для наделения системы этим свойством ее ядро должно эффективно решать задачу управления новыми реализациями компонентов новой требуемой функциональности. В качестве примера-иллюстрации предлагаемого подхода рассмотрим создание прибора, позволяющего осуществлять автоматический перевод (возможно, автоматизированный) текста на естественном языке. Для эффективного решения поставленной задачи необходимо реализовать несколько основных компонентов: модуль ввода текста (возможно, с какого-либо сканера изображений, либо с помощью ручного ввода, либо с помощью системы распознавания голоса); модуль перевода входного текста на естественном языке; лингвистическую БД (словари, какие-либо настройки модуля перевода для различных языков и т.п. [1]); модуль вывода текста пользователю (вывод на экран, на печать, генерация аудиопотока и т.п.). При создании данного прибора необходимо учитывать возможность добавления новых языков для перевода, использования специализированных лингвистических ресурсов и модулей перевода.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2565&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.84Мб) Скачать обложку в формате PDF (1.43Мб) |
| Статья опубликована в выпуске журнала № 3 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Развитие алгоритма спонтанного структурирования цифровых изображений природных комплексов
- Алгоритмы и программное обеспечение распознавания низкоконтрастных изображений при оценке качества стали
- Программная система для исследования характеристик сетей обработки информации
- Алгоритмы автоматизированной системы управления испытанием оборудования на надежность
- Технология взаимодействия сервисов облачной платформы IACPaaS с внешним программным обеспечением
Назад, к списку статей