Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Построение адаптивной регулярной сетки трехмерной сцены в реальном режиме времени
Аннотация:Предлагаются новые методы и алгоритмы построения и заполнения в реальном режиме времени структуры ус-корения, основанной на регулярной сетке, для системы трассировки лучей в трехмерных виртуальных сценах. Опи-санные методы и алгоритмы используют архитектуру параллельных вычислений CUDA и подходят как для статиче-ских, так и для динамических сцен.
Abstract:New real-time methods and algorithms of acceleration structure construction and infill, based on regular grid, for the ray tracing system in three-dimensional virtual scenes are proposed. The described methods and algorithms use CUDA parallel computation architecture and are suitable for both static and dynamic scenes.
| Авторы: Мальцев А.В. (avmaltcev@mail.ru) - НИИСИ РАН, г. Москва, г. Москва, Россия, кандидат физико-математических наук | |
| Ключевые слова: параллельные вычисления, регулярная сетка, структура ускорения, трассировка лучей |
|
| Keywords: parallel computing, regular grid, acceleration structure, Kepler orbit |
|
| Количество просмотров: 18067 |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
Приоритетным направлением в области компьютерной графики является улучшение качества создаваемого компьютером изображения и максимально возможное приближение его к существующей действительности. Один из способов получения так называемого фотореалистичного изображения – обратная трассировка лучей, которая заключается в прослеживании траектории распространения лучей света между глазом наблюдателя (камерой) и источниками света в трехмерной виртуальной сцене. Основной проблемой данного метода является его огромная вычислительная сложность для сцен с большим количеством полигонов (или объектов, если сцена состоит из параметрических объектов), связанная с необходимостью рассчитывать точную траекторию каждого из десятков миллионов лучей и точку его пересечения с поверхностью треугольника, ближайшего по направлению этого луча от его начала. Простейший подход основывается на тестировании каждого луча с каждым полигоном на предмет их пересечения, но при количестве полигонов, превышающем несколько десятков и сотен тысяч, и высоком разрешении визуализируемой картинки эта задача становится слишком сложной для реализации в реальном режиме времени даже на самых современных компьютерах. С целью сокращения времени, требуемого для генерации изображения, были разработаны алгоритмы, которые перед выполнением трассировки лучей строят так называемые структуры уско- рения. При этом трассировка одного луча не перебирает все треугольники сцены для проверки пересечения с этим лучом, а с помощью структуры ускорения выбирает из них некоторое подмножество. К наиболее известным типам структур ускорения можно отнести иерархию ограничивающих объемов (BVH), регулярные, иерархические и нерегулярные сетки, а также kd-деревья. Так, например, регулярная сетка – это разбиение всего пространства виртуальной сцены плоскостями, параллельными плоскостям мировой системы координат, на трехмерные ячейки (вокселы) одинакового размера, каждой из которых соответствует список полигонов, пересекающих эту ячейку. Построив сетку виртуальной сцены, для каждого луча можно вычислить последовательность ячеек, через которые он проходит, и тестировать луч на пересечение только с полигонами, принадлежащими этим ячейкам. Основным недостатком алгоритмов построения структур ускорения является сложность их адаптации к динамическим сценам, в которых многие объекты могут менять свой размер, положение и ориентацию от кадра к кадру. Проблема заключается в довольно значительных временных затратах, требующихся для создания такой структуры, что приводит к невозможности перестроения ее в каждом кадре. В данной статье предлагаются новые методы и алгоритмы создания и заполнения структуры ускорения на основе регулярной сетки, использующие параллельные вычисления на графических процессорах компании nVidia с поддержкой технологии CUDA. Представленные методы и алгоритмы дают возможность на порядок ускорить время построения регулярной сетки для статических сцен и перестраивать ее в реальном режиме времени для динамических. Кроме того, для динамических сцен сетка является адаптивной, то есть подстраивается под размеры сцены, которые могут изменяться от кадра к кадру. Этапы формирования регулярной сетки для трехмерной сцены
· Определение ограничивающего параллелепипеда сцены, стороны которого параллельны координатным плоскостям XY, YZ и ZX мировой системы координат WCS (World Coordinate System). В дальнейшем ограничивающий параллелепипед сцены (или треугольника), удовлетворяющий приведенным выше условиям, будем называть просто AABB (Axis-Aligned Bounding Box). · Разбиение AABB сцены плоскостями, параллельными XY, YZ и ZX, на множество кубических ячеек, называемых вокселами. · Составление таблицы, хранящей для каждого воксела номера треугольников, с которыми он пересекается. Так как в данном случае рассматриваются динамические сцены, в которых многие объекты с течением времени могут менять свое положение, ориентацию и размер (например при морфинге), необходимо в каждом кадре осуществлять перестроение сетки. Для обеспечения реального режима времени составление таблицы, хранящей для каждого воксела номера треугольников, с которыми он пересекается, должно быть реализовано с малыми вычислительными затратами.
В данной работе предлагается решение, в основе которого лежит второй из описанных выше подходов, позволяющее обеспечить построение и заполнение регулярной сетки динамической сцены в реальном режиме времени. Алгоритм построения и заполнения регулярной сетки сцены На рисунке 2 представлена общая схема предлагаемого алгоритма построения регулярной сетки трехмерной виртуальной сцены. Поскольку этот процесс весьма трудоемкий, в основе данного алгоритма лежит использование параллельных вычислений с помощью многоядерных процессоров фирмы nVidia с поддержкой технологии CUDA. Так, например, чип gt200b содержит 240 ядер, что позволяет одновременно обрабатывать 240 потоков в режиме SIMD (Single Instruction, Multiple Data). Подробная информация об архитектуре таких процессоров и основных принципах программирования с применением технологии CUDA изложена в [1]. Идею предлагаемого алгоритма можно описать следующим образом. Для начала необходимо загрузить в память видеоадаптера с поддержкой технологии CUDA координаты вершин треугольников, представленные в локальных системах тех объектов, которым они принадлежат, и матрицы перехода из локальных систем в мировую WCS. Далее нужно найти координаты всех загруженных вершин в мировой системе координат WCS и определить AABB каждого треугольника сцены в виде пары минимальной B0 и максимальной B1 вершин бокса. Это делается с помощью параллельной обработки (рис. 2, ядро 1; под термином «ядро» понимается программа для графического процессора, выполняемая на всех его аппаратных ядрах в режиме SIMD), где каждый поток отвечает за свой треугольник. Исходя из рассчитанных AABB треугольников, находим минимальную Bmin и максимальную Bmax точки для AABB всей сцены также с помощью параллельной обработки (рис. 2, ядро 2).
В результате вычислений для каждой группы получим локальный минимум (максимум), после чего все локальные минимумы (максимумы) снова делятся на группы по h элементов и обрабатываются. Процесс повторяется до тех пор, пока не будет получен один общий минимум (максимум) для AABB всей сцены. Если операция нахождения минимума (максимума) двух чисел занимает один такт, то (с учетом сложности чтения чисел из видеопамяти) нахождение минимума из n элементов с использованием описанного алгоритма параллельного вычисления составляет не более Далее на CPU вычисляются параметры сетки, а именно, длина A ребра кубического воксела и количество вокселов, помещающееся по осям X, Y и Z системы WCS в AABB сцены, то есть размерность D=(Dx, Dy, Dz) сетки:
i=iz Dx Dy+ iy Dx + ix, (1) где ix, iy, iz – индексы ячейки по осям координат X, Y, Z соответственно, начиная c нуля от точки Bmin. На рисунке 3 показан пример C- и T-массива, где треугольнику 0 соответствуют вокселы с номерами 3, 4, 5, треугольнику 1 – воксел 0 и т.д. Совокупность массива номеров треугольников и соответствующего ему массива номеров ячеек сетки сцены в дальнейшем будем называть TC-массивом (Triangle/Cell element array), или массивом элементов треугольник/ячейка. Формирование TC-массива осуществляется с помощью параллельной (по треугольникам) обработки с использованием CUDA (рис. 2, ядро 4). Так как в технологии CUDA нет возможности динамического выделения глобальной (общей для всего видеоадаптера) памяти в процессе выполнения ядра, выделять память под TC-массив необходимо заранее. Кроме того, для каждого потока, обрабатывающего свой треугольник, необходимо знать смещение в TC-массиве, с которого этот поток будет начинать запись данных. Поэтому для начала нужно рассчитать число ячеек сетки, занимаемых каждым треугольником, и сумму таких чисел по всем треугольникам. Поскольку на данном шаге необходимо знать лишь максимальное количество ячеек под каждый треугольник, чтобы сделать выделение памяти, с целью ускорения вычислений можно ограничиться грубой оценкой, то есть количеством ячеек, которые пересекают AABB каждого треугольника. Для этого в режиме параллельной обработки (рис. 2, ядро 3) заполняется массив, длина которого равна общему числу n полигонов сцены, а каждый элемент i соответствует треугольнику с тем же номером и содержит то количество вокселов сетки, которое занимает AABB этого треугольника (рис. 4). Далее нужно рассчитать суммарное число элементов в TC-массиве и смещение (выраженное в количестве ячеек), с которого будет начата запись данных каждым потоком ядра 4. Это можно сделать с помощью функции сканирования (параллельной префиксной суммы [2]) cudppScan массива из библиотеки CUDPP (CUDA Data Parallel Primitives Library). На вход cudppScan подается числовой массив длиной n, а на выходе получается массив длиной n+1, в каждом элементе 0 Укажем в качестве входа cudppScan созданный ранее массив (рис. 4), каждый элемент i которого содержит количество вокселов сетки сцены, занимаемых AABB треугольника с номером i. Тогда на выходе получим таблицу смещений в TC-массиве для каждого потока и размер (в ячейках) TC-массива (рис. 5). Напомним, что занесение данных в TC-массив производится в режиме параллельной (относительно треугольников) обработки (рис. 2, ядро 4), где каждый поток, отвечающий за свой полигон, осуществляет запись начиная с некоторого смещения, задаваемого таблицей смещений (рис. 5).
Пусть, например, nz – максимальная по модулю координата нормали n. Тогда в качестве плоскости проецирования будет выбрана плоскость XY. Проведем растеризацию полученного треугольника-проекции, в ходе которой определим для каждого слоя j ячеек по оси Y индексы imin и imax минимальной и максимальной ячеек по X, пересекающихся с треугольником (рис. 6а, искомые ячейки выделены). Далее для каждого индекса i из [imin, imax] каждого слоя j следует определить отрезок из ячеек, расположенных параллельно оси z и пересекающихся с плоскостью треугольника (рис. 6б). Для каждого отрезка получим четыре (это обусловлено сделанным ранее выбором плоскости проецирования) точки его пересечения с плоскостью треугольника, среди которых выберем две: с минимальной zmin и максимальной zmax z-координатой (рис. 6б). По zmin и zmax вычислим минимальный kmin и максимальный kmax индексы ячеек отрезка, которые пересекают треугольник. И, наконец, в рассматриваемом отрезке для всех ячеек с индексами по z от kmin до kmax по формуле (1) определим номера, которые в паре с номером треугольника запишем в TC-массив.
Выполнив ядро 4 (см. рис. 2), получаем заполненный TC-массив, отсортированный по номерам треугольников (рис. 3). Такое представление неудобно для дальнейшего использования. Действительно, зная номер ячейки сетки сцены, необходимо делать полный перебор C-массива, чтобы найти индексы, обращаясь по которым в T-массив, уже можно будет составить список принадлежащих этой ячейке треугольников. Чтобы перейти от представления TC-массива, где пары треугольник/ячейка упорядочены по номерам треугольников, к представлению ячейка/треугольник, то есть упорядочить пары относительно номеров ячеек, можно применить функцию cudppSort параллельной сортировки массивов из библиотеки CUDPP. Функция cudppSort использует алгоритм поразрядной сортировки (radix sort), описанный в [2]. На вход cudppSort подаются массив ключей и массив данных, которые содержат одинаковое коли- чество элементов. При этом считается, что оба массива взаимосвязаны, а именно: i-й элемент первого массива образует с i-м элементом второго массива пару (ключ, информация). Функция производит сортировку ключевого массива и ана- логично изменяет индексы элементов массива данных. На выходе имеем пару массивов, отсортированных по ключам. Если в функцию cudppSort в качестве ключевого массива подать C-массив, а в качестве массива данных – T-массив, в результате получим TC-массив, отсортированный по номерам ячеек, который будем называть СT-массивом (Cell/Triangle element array), или массивом элементов ячейка/треугольник (рис. 7).
Одним из основных преимуществ изложенного алгоритма параллельного построения регулярной сетки на GPU, кроме, конечно, поддержки реального режима времени, является экономия памяти видеоадаптера, поскольку отсутствует предварительное выделение памяти по среднему, заранее рассчитываемому числу ячеек, которые зани- мает один треугольник, и свободные ячейки вообще не записываются в CT-массив. Практические результаты Описанный алгоритм построения регулярной сетки трехмерной виртуальной сцены был реализован в виде программного кода и протестирован на нескольких сценах с различной степенью сложности. Полученные результаты приведены в таблице.
Для тестирования была использована следующая конфигурация компьютера: процессор Pentium IV, 1 Гбайт ОЗУ, видеоадаптер nVidia GeForce GTX280, операционная система Windows XP. Литература 1. NVIDIA CUDA Programming Guide, Version 2.3, 2009. URL: http://developer.download.nvidia.com/compute/cuda/2_3/ toolkit/docs/NVIDIA_CUDA_Programming_Guide_2.3.pdf (дата обращения: 15.06.2010). 2. Дональд Кнут. Искусство программирования. Сортировка и поиск: 2-е изд. М.: «Вильямс», 2007. Т. 3. 3. URL: http://gpgpu.org/developer/cudpp (дата обращения: 15.06.2010). | |||||||||||||||||||||||||||||||
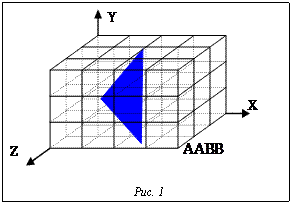 Построение и заполнение регулярной сетки трехмерной виртуальной сцены, состоящей из полигональных объектов (рис. 1), включают несколько основных этапов.
Построение и заполнение регулярной сетки трехмерной виртуальной сцены, состоящей из полигональных объектов (рис. 1), включают несколько основных этапов.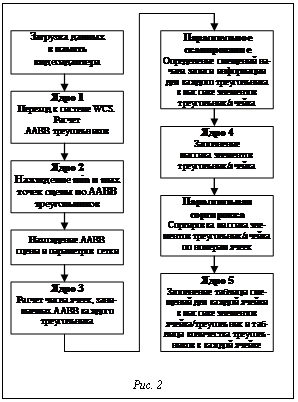 Существуют два основных подхода к составлению такой таблицы. Первый – это пройти по всем вокселам и некоторым образом определить относящиеся к ним треугольники, например, перебором всех треугольников для каждого воксела. В этом случае, принимая за элементарную операцию тест пересечения одного полигона с одним вокселом регулярной сетки, получим M×N×K×t операций, где M, N, K – размерность AABB сцены в вокселах по осям X, Y и Z соответственно; t – количество треугольников в сцене. Второй подход – пройти по всем полигонам, определив, какие вокселы каждый из них пересекает. Тогда, если M≥N≥K, количество элементарных операций будет не больше M×N×t, поскольку максимально возможное число вокселов, занимаемых одним треугольником, равно M×N. Однако в таком случае, чтобы составить таблицу, хранящую для каждого воксела номера треугольников, с которыми он пересекается, необходим свой быстрый и эффективный алгоритм.
Существуют два основных подхода к составлению такой таблицы. Первый – это пройти по всем вокселам и некоторым образом определить относящиеся к ним треугольники, например, перебором всех треугольников для каждого воксела. В этом случае, принимая за элементарную операцию тест пересечения одного полигона с одним вокселом регулярной сетки, получим M×N×K×t операций, где M, N, K – размерность AABB сцены в вокселах по осям X, Y и Z соответственно; t – количество треугольников в сцене. Второй подход – пройти по всем полигонам, определив, какие вокселы каждый из них пересекает. Тогда, если M≥N≥K, количество элементарных операций будет не больше M×N×t, поскольку максимально возможное число вокселов, занимаемых одним треугольником, равно M×N. Однако в таком случае, чтобы составить таблицу, хранящую для каждого воксела номера треугольников, с которыми он пересекается, необходим свой быстрый и эффективный алгоритм. Графический процессор (GPU) фирмы nVidia содержит PM мультипроцессоров, каждый из которых состоит из PU универсальных процессоров. Числа PM и PU зависят от архитектуры чипа GPU. Разобьем совокупности ранее найденных вершин B0,i и B1,i (iÎ[0, n-1]) AABB всех n треугольников сцены на группы по h элементов, где h – максимально возможное число потоков в GPU. Каждая группа будет обрабатываться на одном из PM мультипроцессоров. Для чипа gt200b (GTX280) PM=30, PU=8, h=512.
Графический процессор (GPU) фирмы nVidia содержит PM мультипроцессоров, каждый из которых состоит из PU универсальных процессоров. Числа PM и PU зависят от архитектуры чипа GPU. Разобьем совокупности ранее найденных вершин B0,i и B1,i (iÎ[0, n-1]) AABB всех n треугольников сцены на группы по h элементов, где h – максимально возможное число потоков в GPU. Каждая группа будет обрабатываться на одном из PM мультипроцессоров. Для чипа gt200b (GTX280) PM=30, PU=8, h=512. тактов, где с – константа (не превышающая 20). Подставляя в эту формулу параметры чипа gt200b, получим, что t=0,08n.
тактов, где с – константа (не превышающая 20). Подставляя в эту формулу параметры чипа gt200b, получим, что t=0,08n.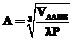 ;
; 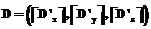 ,
, 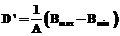 , где VAABB – объем AABB сцены; P – общее количество треугольников в сцене; λ – константа, позволяющая делать сетку более плотной или более разреженной, квадратные скобки обозначают округление сверху до ближайшего целого; Bmax и Bmin – соответственно максимальная и минимальная точки AABB сцены. Формула для вычисления размера сетки А является эвристической.
, где VAABB – объем AABB сцены; P – общее количество треугольников в сцене; λ – константа, позволяющая делать сетку более плотной или более разреженной, квадратные скобки обозначают округление сверху до ближайшего целого; Bmax и Bmin – соответственно максимальная и минимальная точки AABB сцены. Формула для вычисления размера сетки А является эвристической.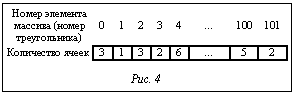 Имея характеристики сетки сцены, необходимо определить, каким вокселам какие треугольники сцены принадлежат. Чтобы решить эту задачу, сначала надо найти для каждого треугольника те ячейки, которые он пересекает, и составить два взаимосвязанных массива, в одном из которых будут храниться номера треугольников (T-массив, Triangle array), а в другом – номера соответствующих им ячеек (C-массив, Cell array). Под номером ячейки будем понимать число, рассчитываемое по формуле
Имея характеристики сетки сцены, необходимо определить, каким вокселам какие треугольники сцены принадлежат. Чтобы решить эту задачу, сначала надо найти для каждого треугольника те ячейки, которые он пересекает, и составить два взаимосвязанных массива, в одном из которых будут храниться номера треугольников (T-массив, Triangle array), а в другом – номера соответствующих им ячеек (C-массив, Cell array). Под номером ячейки будем понимать число, рассчитываемое по формуле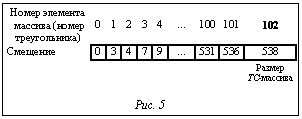 Рассмотрим алгоритм определения номеров ячеек сетки, занимаемых некоторым треугольником с нормалью n к его поверхности. Спроецируем сетку сцены и треугольник на одну из плоскостей XY, ZY или XZ мировой системы координат в зависимости от того, какая из координат нормали – nz, nx или nу (соответственно) – является большей по модулю. Такой выбор плоскости позволяет исключить вероятность того, что проекцией треугольника будет отрезок.
Рассмотрим алгоритм определения номеров ячеек сетки, занимаемых некоторым треугольником с нормалью n к его поверхности. Спроецируем сетку сцены и треугольник на одну из плоскостей XY, ZY или XZ мировой системы координат в зависимости от того, какая из координат нормали – nz, nx или nу (соответственно) – является большей по модулю. Такой выбор плоскости позволяет исключить вероятность того, что проекцией треугольника будет отрезок.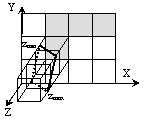

 Кроме CT-массива, необходимо составить таблицу смещений, по которой для любой ячейки с номером i можно определить индекс первого вхождения этой ячейки в CT-массив, и таблицу заполнения ячеек, где будет записано количество треугольников, принадлежащих каждой ячейке (рис. 8). Эта задача решается с помощью параллельного (относительно ячеек) бинарного поиска в C-массиве номеров ячеек (рис. 2, ядро 5). Для ячеек, которые не содержат ни одного треугольника и, следовательно, отсутствуют в CT-массиве, смещение можно задать равным –1, а количество треугольников равным 0.
Кроме CT-массива, необходимо составить таблицу смещений, по которой для любой ячейки с номером i можно определить индекс первого вхождения этой ячейки в CT-массив, и таблицу заполнения ячеек, где будет записано количество треугольников, принадлежащих каждой ячейке (рис. 8). Эта задача решается с помощью параллельного (относительно ячеек) бинарного поиска в C-массиве номеров ячеек (рис. 2, ядро 5). Для ячеек, которые не содержат ни одного треугольника и, следовательно, отсутствуют в CT-массиве, смещение можно задать равным –1, а количество треугольников равным 0. Итак, мы получили набор данных (CT-массив, таблицы смещений и заполнения ячеек), полностью описывающих регулярную сетку трехмерной виртуальной сцены и необходимых для дальнейшей трассировки лучей.
Итак, мы получили набор данных (CT-массив, таблицы смещений и заполнения ячеек), полностью описывающих регулярную сетку трехмерной виртуальной сцены и необходимых для дальнейшей трассировки лучей.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2608&like=1&page=article |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Исследование эффективности библиотеки MaLLBa на примере задач максимальной выполнимости
- Облачный сервис «Параллельный Matlab»
- Неоднозначная семантика и некорректности при работе с потоками на C#
- Язык описания модели предметной области в пакетах прикладных программ
- Моделирование столкновения двух атомов над поверхностью конденсированной фазы
Назад, к списку статей