Абдуктивный вывод versus дедукция
| Вагин В.Н. (vagin@appmat.ru) - Московский энергетический институт (технический университет), г. Москва, Россия, доктор технических наук, Хотимчук К.Ю. (khotimchukky@mail.ru) - Московский энергетический институт (технический университет) | |
| Ключевые слова: минимальное абдуктивное объяснение, первичная импликата, импликата, принятие решений, интеллектуальные системы, дедукция, абдукция |
|
| Keywords: minimal abductive explanation, primary implicate, implicate, decision making, intelligent systems, deduction, abduction |
|
|
|
|
В настоящее время разработка формальных моделей разных форм рассуждения играет ключевую роль в создании интеллектуальных систем различного назначения. Известно, что индуктивный вывод – это вывод от частного к общему, в то время как абдуктивный заключается в выводе причины из наблюдаемого события и является выводом от частного к частному. Вывод по абдукции успешно применяется для решения задач диагностики [1], понимания естественного языка [2], распознавания, накопления знаний, составления расписаний и, несомненно, является очень важной составляющей интеллектуальных систем. В данной работе рассматриваются понятия первичной импликаты и минимального абдуктивного объяснения, после чего изложен принцип нахождения множества минимальных абдуктивных объяснений с помощью первичных импликат, приводятся алгоритм SOL-резолюции (skipping ordered linear – линейная упорядоченная резолюция с перемещением) для нахождения первичных импликат и алгоритм ImpAA для нахождения минимальных абдуктивных объяснений. Кроме того, предожен эвристический метод для сокращения поискового пространства в алгоритме SOL-резолюции, названный авторами методом выбора начального порядка литер в исходных дизъюнктах. Первичные импликаты Для организации абдуктивного вывода используется метод импликат, где под импликатой понимается следствие из формулы. Используются модификации этого понятия: -импликата и -первичная импликата [3]. Определение 1. Пусть L – конечное подмножество литер; S – некоторая формула; Ф – конъюнкция формул логики предикатов первого порядка (ЛП1П); Lit(d) – множество литер дизъюнкта d. Дизъюнкт p является -импликатой S, если ФÙS½=p, Ф½¹p и Lit(p)ÍL. Дизъюнкт p является -первичной импликатой S, если p – -импликата S; и для всех -импликат π' формулы S выполняется {p'╞p}Þ{p╞p'}. Множество всех -первичных импликат формулы S будем обозначать как PILФ(S). Пример 1. Пусть S=(a®b), Ф=(b®c)Ù Ù(cÙØb®d), L={Øa, b, d}. Тогда ØaÚb, ØaÚbÚd являются -импликатами формулы S. Пример 2. Пусть S=(a®b), Ф=(b®c)Ù Ù (cÙØb®d), L={Øa, b, d}. Тогда ØaÚb является -первичной импликатой формулы S; ØaÚbÚd не является -первичной импликатой формулы S. Решение задачи абдукции с помощью первичных импликат Определение 2. Пусть Ф – конъюнкция формул ЛП1П; H – конечное множество фактов, называемых предположениями (гипотезами); упорядоченная пара T=<Ф, Н> – теория, построенная на предположениях [3]. Определение 3 (абдуктивного вывода). Пусть T=<Ф, Н> – теория, построенная на предположениях. Абдуктивный вывод заключается в выводе объяснения для наблюдаемого события δ как подмножества γÍH, такое, что Ф & γ╞δ [3]. Заметим, что на γ в определении 2 накладывается синтаксическое ограничение – γ представляет собой конъюнкцию фактов. Определение 4. Пусть Т=<Ф, Н> – теория, основанная на предположениях; δ – формула ЛП1П. Конъюнктивно интерпретируемое подмножество γÍH назовем абдуктивным объяснением δ относительно Т, если Ф&γ╞ δ и если Ф&γ выполнимо. Пример 3. Пусть Т=<Ф, Н>, где Ф="x (Студент(x)®Юн(x)), δ=Юн(Петров). Пусть H={Студент(x1), Рабочий(x2)}. Тогда Студент(Петров), Студент(Петров) & Рабочий(Иванов) являются абдуктивными объяснениями δ относительно T. Заметим, что абдуктивное объяснение не должно быть противоречивым. В примере 1 Студент(Петров) & ØЮн(Петров) не является абдуктивным объяснением δ относительно T в силу противоречивости. Определение 5. Пусть Т=<Ф, Н> – теория, основанная на предположениях; d – формула ЛП1П. Конъюнктивно интерпретируемое подмножество γÍH назовем минимальным абдуктивным объяснением δ относительно Т, если γ – абдуктивное объяснение для δ относительно Т; для любого абдуктивного объяснения γ' для δ относительно Т выполняется (γÍγ')®( γ'Íγ) [3]. Пример 4. Пусть Т=<Ф, Н>, где Ф = "x (Студент(x)®Юн(x)), δ=Юн(Петров). Пусть H={Студент(x1), Рабочий(x2)}. Тогда Студент(Петров) является минимальным абдуктивным объяснением δ относительно T. Студент(Петров) & Рабочий (Иванов) не является минимальным абдуктивным объяснением δ относительно T. Существуют различные методы решения задачи абдукции. В данном случае рассматривается метод решения с помощью первичных импликат. В основе этого метода лежит принцип абдукции через дедукцию [4]: Ф, γ╞ δ; применяя теорему о дедукции и аксиому контрпозиции, получаем Ф, Øδ╞Ø γ. Доказана справедливость следующего утверждения [3]. Утверждение. Пусть T=<Ф, H> – теория, основанная на предположениях, и пусть δ – формула; γ – минимальное абдуктивное объяснение для δ относительно T тогда и только тогда, когда Øγ является <Ф, ØH>-первичной импликатой формулы Øδ. Замечание: ØH означает <Øh1, Øh2, …, ØhN>. Пример 5. Пусть Т=<ØaÚb, {a, Øa, b, Øb}> – теория, основанная на предположениях. Пусть наблюдается факт δ=b. Сведем задачу нахождения минимальных абдуктивных объяснений для δ=b относительно Т к задаче нахождения множества <ØH, Ф>-первичных импликат формулы Øδ: Øδ=Øb; Ф=ØaÚb; ØН={Øa, a, Øb, b}. Формулы Øa, Øb являются <ØH, Ф>-первичными импликатами формулы Øδ. Для каждой из этих двух формул получаем соответствующее минимальное абдуктивное объяснение путем взятия отрицания a и b. Алгоритм ImpAA Для нахождения множества -первичных импликат формулы S применяется алгоритм SOL-резолюции, основанный на работах Ковальски и Кунера [5]. Неформально суть его такова: пусть формула Ф допускает дизъюнктивное представление S, тогда последовательно осуществляется резолюция формулы S с дизъюнктами из S до того момента, пока не окажется, что полученный к данному моменту дизъюнкт D уже нельзя прорезольвировать ни с одним из дизъюнктов S. Для того чтобы не допустить вывод дизъюнктов, не являющихся первичными импликатами, в алгоритме используется механизм обрамления литеры, по которой имело место резольвирование [6]. SOL-резолюция оперирует расширенными и структурными дизъюнктами. Определение 6. Пусть LPS – множество литер ЛП1П. Расширенным дизъюнктом называется упорядоченный дизъюнкт, литеры которого берутся из множества LPSÈ{[r], rÎLPS}, где {[r], rÎLPS} – это множество так называемых обрамленных литер. Обрамление литеры является способом запомнить, что по данной литере резольвирование уже было. Таким образом, если дизъюнкт содержит обрамленную литеру [r], то это означает, что один из его родительских дизъюнктов содержит r. С логической точки зрения расширенный дизъюнкт не зависит от его обрамленных литер, то есть представляет собой дизъюнкт, составленный только из необрамленных литер данного. Целью обрамления являются организация последовательного поиска и обеспечение вывода только первичных импликат: резольвирование дизъюнкта с дизъюнктами из Ф, содержащими литеру, по которой производилось резольвирование выше, бесполезно. Определение 7. Структурным дизъюнктом называется упорядоченная пара , где d – дизъюнкт, e – расширенный дизъюнкт. Структурный дизъюнкт в SOL-резолюции логически означает некоторый дизъюнкт, уже являющийся первичной импликатой формулы S, то есть означает дизъюнкт, составленный из литер дизъюнкта d и необрамленных литер расширенного дизъюнкта e. Разделение на d и e необходимо для четкого определения части, которую надо резольвировать (e), и части, от резольвирования которой уже нельзя получить новые импликаты (d), – тем самым реализуется последовательный перебор. Опишем кратко сам алгоритм. Первоначально из исходного дизъюнкта составляется структурный дизъюнкт, левая компонента которого является пустым множеством, а правая состоит из множества литер исходного дизъюнкта. Построенный структурный дизъюнкт подается на вход алгоритма SOL-резолюции, на выходе которого получается множество первичных импликат. Опишем действие алгоритма SOL-резолюции для произвольного узла дерева вывода. Со структурным дизъюнктом, связанным с этим узлом, можно выполнить два действия: переместить первую литеру из второй компоненты в первую (Skip) и прорезольвировать по первой литере со всеми подходящими дизъюнктами из базы правил, объединенной с начальным дизъюнктом (Resolve). Процедура Skip перемещает первую литеру из второй компоненты в первую, после чего вызывается процедура Reduce, которая редуцирует вторую компоненту. Процедура Resolve перебирает все дизъюнкты из базы правил, объединенной с исходным дизъюнктом, если находит подходящий для резольвирования дизъюнкт, то осуществляются резолюция и редуцирование Reduce. Процедура Reduce удаляет из структурного дизъюнкта повторные литеры, а также все обрамленные литеры второй компоненты структурного дизъюнкта, которым не предшествует ни одна необрамленная литера. Алгоритм ImpAA Исходные данные: clauses – исходное множество дизъюнктов, observed – наблюдаемый конъюнкт. Выходные данные: result – множество абдуктивных объяснений для observed (результирующее множество конъюнктов). Начало. Шаг 1. Создаем дизъюнкт clause= Шаг 2. Обращаемся к процедуре SOLSolve с параметрами clause, clauses, Lit(clause) Шаг 3. Для каждого дизъюнкта implicate из implicates создаем конъюнкт explanation= Конец. Алгоритм SOLSolve Исходные данные: clause – дизъюнкт, для которого требуется найти множество -первичных импликат; ruleBase – имеющаяся база правил; lit – множество литер, которые могут присутствовать в выводимых дизъюнктах. Выходные данные: result – множество -первичных импликат. Начало. Шаг 1. Образование начального центрального структурного дизъюнкта topClause=<<Æ>, >. В качестве базы правил нужно взять имеющуюся базу правил, объединенную с clause. Шаг 2. Поиск всех первичных импликат с помощью выполнения шага 4. Шаг 3. Выбор из полученного на предыдущем шаге множества неповторяющихся дизъюнктов и запись их в result. Конец. Шаг 4. Поиск множества первичных импликат для поступающего на вход узла (структурного дизъюнкта). Возвращается множество дизъюнктов, которые являются первичными импликатами дизъюнкта, образованного из необрамленных литер родительского структурного дизъюнкта topClause, и где резольвировать можно только по литерам из второй компоненты topClause. Для узла, в котором произошел вызов данного шага, выполнить шаг 5, получив множество дизъюнктов s1, и шаг 6, получив множество дизъюнктов s2. Возвратить s1Ès2. Шаг 5. Рассмотрение 1 – первой литеры из второй компоненты topClause. Если lÎlit, необходимо осуществить перенос (правило Skip) литеры из второй компоненты topClause в первую, иначе Конец. Осуществить редукцию (шаг 7). Если вторая компонента topClause пуста, возвратить дизъюнкт, полученный из литер левой компоненты topClause. Иначе продолжить рекурсивный поиск для topClause – выполнить шаг 4. Шаг 6. Резолюция (правило Resolve) первой литеры из второй компоненты со всевозможными дизъюнктами из базы правил. Пусть входной структурный дизъюнкт на данном этапе имеет вид <, >, а подходящее правило rule=l’1, …, l’t, Øl, l’t+1, l’p, тогда резольвента примет вид <, < sl’1, …, sl’t, sl’t+1, sl’p, [sl], sl1, …, sln>>. При выборе подходящего правила нужно соблюдать условие lit(rule)Çframed({l, l1, …, ln})=Æ. Осуществить редукцию (шаг 7) всех полученных резольвент и с ними перейти к шагу 4. Шаг 7. Редукция поступающего на вход структурного дизъюнкта (правило Reduce). Если в l1, …, ln литера l встречается дважды, то удаляется ее самое левое вхождение. Получаем l11, l12, …, l1n1. Если какая-либо литера из a1, a2, …, ak совпадает с некоторыми литерами из l11, l12, … l1n1, то удаляем из последнего множества эти литеры. Получаем l21, l22, … l2n2. Удалить все обрамленные литеры из , которым не предшествует обрамленная литера. Конец. Пример работы алгоритма SOL-резолюции Пример 6. Пусть Ф представима как {(1) ØaÚd, (2) ØdÚe, (3) ØaÚf, (4) ØfÚe, (5) ØeÚg}; S=aÚbÚc; L – множество всех встречающихся в данном примере литер. Тогда дерево вывода множества -первичных импликат формулы S имеет следующий вид (здесь номер шага в квадратных скобках означает, что на этом шаге выведена первичная импликата): 1. <<Æ>, >, 2. <, > (правило Skip для п. 1), 3. <<Æ>, > (правило Resolve для п. 1 с (1)), 4. <<Æ>, > (правило Resolve для п. 1 с (3)), 5. <, > (правило Skip для п. 2), 6. Æ (правило Resolve для п. 2 невыполнимо), 7. < > (правило Skip для п. 3), 8. <<Æ>, > (правило Resolve для п. 3 с (2)), 9. < > (правило Skip для п. 4), 10. <<Æ>, > (правило Resolve для п. 4 с (4)), [11]. <, <Æ>> = a Ú b Ú c (правило Skip для п. 5), 12. Æ (правило Resolve для п. 5 невыполнимо), 13. <, > (правило Skip для п. 7), 14. Æ (правило Resolve для п. 7 невыполнимо), 15. <, > (правило Skip для п. 8), 16. <<Æ>, > (правило Resolve для п. 8 с (5)), 17. <, > (правило Skip для п. 9), 18. Æ (правило Resolve для п. 9 невыполнимо), 19. <, > (правило Skip для п. 10), 20. <<Æ>, > (правило Resolve для п. 10 с (5)), 21. <, <Æ>> = b Ú c Ú d (правило Skip для п. 13), 22. Æ (правило Resolve для п. 13 невыполнимо), 23. <, > (правило Skip для п. 15), 24. Æ (правило Resolve для п. 15 невыполнимо), 25. <, > (правило Skip для п. 16), 26. Æ (правило Resolve для п. 16 невыполнимо), [27]. <, <Æ>> = b Ú c Ú f (правило Skip для п. 17), 28. Æ (правило Resolve для п. 17 невыполнимо), 29. <, > (правило Skip для п. 19), 30. Æ (правило Resolve для п. 19 невыполнимо), 31. <, > (правило Skip для п. 20), 32. Æ (правило Resolve для п. 20 невыполнимо), [33.] <, <Æ>> = b Ú c Ú e (правило Skip для п. 23), 34. Æ (правило Resolve для п. 23 невыполнимо), 35. <, > (правило Skip для п. 25), 36. Æ (правило Resolve для п. 25 невыполнимо), [37]. <, <Æ>> = b Ú c Ú e (правило Skip для п. 29), 38. Æ (правило Resolve для п. 29 невыполнимо), 39. <, > (правило Skip для п. 31), 40. Æ (правило Resolve для п. 31 невыполнимо), [41]. <, <Æ>> = b Ú c Ú g (правило Skip для п. 35), 42. Æ (правило Resolve для п. 35 невыполнимо), [43]. <, <Æ>> = b Ú c Ú g (правило Skip для п. 39), 44. Æ (правило Resolve для п. 39 невыполнимо). Ответ: aÚbÚc, bÚcÚd, bÚcÚf, bÚcÚe, bÚcÚg, решение получено за 44 шага. Эвристический метод выбора начального порядка литер в исходных дизъюнктах в алгоритме SOL-резолюции Заметим, что уменьшение количества выведенных повторных дизъюнктов в алгоритме SOL-резолюции возможно за счет варьирования порядка литер в исходных дизъюнктах. На этом наблюдении основывается эвристический метод выбора начального порядка литер в исходных дизъюнктах. Метод заключается в упорядочении литер в дизъюнкте по возрастанию функции Rank, действующей из декартова произведения множества литер и множества множеств дизъюнктов во множество целых чисел. Пусть RuleBase – множество дизъюнктов. Тогда ранг литеры r в RuleBase определяется следующим образом. Находятся дизъюнкты d1, … dn, содержащие Ør. Тогда
Пример 7. Рассмотрим множество из 3 дизъюнктов {(1) aÚbÚс, (2) ØaÚb, (3) ØbÚс}. Вычислим значения функции Rank для литер a, Øa, b, Øb, c. Rank(a, (1, 2, 3))=1+Rank(b, (1, 3))=1+1+Rank(c, (1))=2, Rank(b, (1, 2, 3))=1+Rank(c, (1, 2))=1, Rank(Øa, (1, 2, 3))=1+Rank(b, (2, 3))+Rank(c, (2, 3))=1+1=2, Rank(Øb, (1, 2, 3))=1+Rank(a, (2, 3))+Rank(c, (2, 3))+ +Rank(Øa, (1, 3))=1+1+Rank(b, (3))+0+1+ +Rank(b, (3))+Rank(c, (3))=3+2=5, Rank(c, (1, 2, 3))=0. Таким образом, на первых местах во второй компоненте расширенного дизъюнкта оказываются литеры, которые, по оценке авторов, приведут к порождению наименьшего числа дизъюнктов. Ранг 0 имеет та литера, по которой резольвирование вообще не происходит. Пример 8. Изменяем порядок следования литер согласно эвристическому методу выбора начального порядка литер в исходных дизъюнктах; Ф представима как {(1) ØaÚd, (2) eÚØd, (3) ØaÚf, (4) eÚØf, (5) gÚØe}, а S=bÚcÚa. В этом случае решение получается уже за 20 шагов. 1. <<Æ>, >, 2. <, > (правило Skip для п. 1), 3. Æ (правило Resolve для п. 1 невыполнимо), 4. <, > (правило Skip для п. 2), 5. Æ (правило Resolve для п. 2 невыполнимо), [6]. <, <Æ>> = a Ú b Ú c (правило Skip для п. 4), 7. <, > (правило Resolve для п. 4 с (1)), 8. <, > (правило Resolve для п. 4 с (3)), [9]. <, <Æ>> = b Ú c Ú d (правило Skip для п. 7), 10. <, > (правило Resolve для п. 7 с (2)), [11]. < <Æ>> = b Ú c Ú f (правило Skip для п. 8), 12. <, > (правило Resolve для п. 8 с (4)), [13]. <, <Æ>> = b Ú c Ú e (правило Skip для п. 10), 14. <, > (правило Resolve для п. 10 с (5)), [15]. <, <Æ>> = b Ú c Ú e (правило Skip для п. 12), 16. <, > (правило Resolve для п. 12 с (5)), [17]. <, <Æ>> = b Ú c Ú g (правило Skip для п. 14), 18. Æ (правило Resolve для п. 14 невыполнимо), [19]. <, <Æ>> = b Ú c Ú g (правило Skip для п. 16), 20. Æ (правило Resolve для п. 16 невыполнимо). Ответ: aÚbÚc, bÚcÚd, bÚcÚf, bÚcÚe, bÚcÚg. В заключение отметим, что абдуктивный вывод широко применяется в интеллектуальных системах различного назначения. В работе рассмотрен алгоритм ImpAA решения задачи абдукции с помощью -первичных импликат. Собственно нахождение -первичных импликат осуществляется по алгоритму SOL-резолюции. Недостатками этого алгоритма являются, во-первых, полный перебор, а во-вторых, в общем случае он находит повторные дизъюнкты. Авторы предложили эвристический метод выбора начального порядка литер в исходных дизъюнктах для сокращения поискового пространства. Литература 1. Cox P.T. and Pietrzykowski T. General diagnosis by abductive inference // Proc. IEEE Sympos. Logic Programming. San Francisco. 1987, pp. 183–189. 2. Hobbs J., Stickel M.E., Appelt D. [et al.]. Interpretation as abduction // Artificial Intelligence. 1993. № 63 (1–2), pp. 69–142. 3. Marquis P. Consequence finding algorithms // Handbook for Defeasible Reasoning and Uncertain Management Systems [eds. D.M. Gabbay and P. Smets]. 2000. Vol. 5, pp. 41–145. 4. Kakas A.C., Kowalski R.A., Toni F. The role of abduction in logic programming // Handbook of Logic in Artificial Intelligence and Logic Programming [Ed. Gabbay D.M., Hogger C.J. and Robinson J.A.]. Oxford. Oxford University Press. 1998, pp. 235–324. 5. Kowalski R., Kuhner D. Linear resolution with selection function // Artificial Intelligence. 1971. Vol. 2, pp. 227–260. |
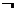 observed.
observed.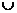 Lit(clauses), где Lit(clause) / Lit(clauses) – множество литер, встречающихся в дизъюнкте/дизъюнктах. Результат выполнения процедуры – множество implicates.
Lit(clauses), где Lit(clause) / Lit(clauses) – множество литер, встречающихся в дизъюнкте/дизъюнктах. Результат выполнения процедуры – множество implicates.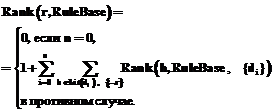
http://swsys.ru/index.php?id=2612&lang=%E2%8C%A9%3Den&like=1&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Программная система дедуктивного логического вывода
- Прецедентный подход для оценки влияния молний на системы уличного освещения с использованием онтологий
- Становление и развитие научной школы искусственного интеллекта в Московском энергетическом институте
- Методы удовлетворения временных ограничений в интеллектуальных системах поддержки принятия решений реального времени
- Получение случайных последовательностей на основе анализа Вальда