Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Программа для построения геномных профилей весовых матриц
Аннотация:Целью данной работы явилась разработка программы для анализа геномных профилей весовых матриц. Геном-ным профилем автор называет гистограмму, построенную для графика плотности распределения сайтов связывания с транскрипционными факторами, найденными с помощью этой матрицы. Разработанная программа позволяет строить геномные профили для различных матриц и порогов поиска. Была экспериментально обнаружена независимость профиля матрицы от заданных порогов.
Abstract:Aim of this work was to develop software package for analysis of genomic profiles of positional weight matrices. By genomic profile author means a histogram, that is build for density of binding sites distribution found with this matrix. Software allows to build genomic profiles for different matrices and search cutoffs. It was found experimentally that matrix profile is independent on given cutoffs.
| Авторы: Черемушкин Е.С. (evgeny.cheryomushkin@gmail.com) - Институт систем информатики им. А.П. Ершова СО РАН; компания «Новые вычислительные системы в биологии» (научный сотрудник), Новосибирск, Россия, кандидат физико-математических наук | |
| Ключевые слова: программная система, днк, геном, сайты связывания с транскрипционными факторами, весовые матрицы |
|
| Keywords: software system, DNA, genome, transcription factor binding site, positional weight matrix |
|
| Количество просмотров: 15641 |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
Регуляция транскрипции (считывания РНК) является одним из наиболее широко исследуемых биоинформатикой биомолекулярных процессов [1]. При считывании РНК важную роль играют специфические белки, называемые транскрипционными факторами (ТФ) [2]. Они образуют комплексы на участках ДНК, называемых промоторами (участками ДНК, расположенными до старта транскрипции). Если в клетке присутствует необходимый для данного промотора набор ТФ, то с некоторой вероятностью он образует белковый комплекс на этом промоторе, что позволяет РНК-полимеразе закрепиться на старте транскрипции этого гена и начать считывание РНК. Таким образом, за счет различного состава ТФ происходит дифференциация клеток: в разных клетках присутствуют всевозможные наборы ТФ, которые запускают транскрипцию различных генов, производящих различные белковые продукты. Эти белки, в свою очередь, тоже могут быть ТФ, запускающими, к примеру, следующую стадию развития клетки. Небольшие фрагменты ДНК длиной в среднем 10–20 нуклеотидов, к которым прикрепляются ТФ, называются сайтами связывания с ТФ, или просто сайтами [3, 4]. Сайты одного и того же ТФ имеют схожие последовательности. Это объясняется тем, что ТФ обладают специфической формой, позволяющей им закрепляться на последовательностях определенного типа. Но, несмотря на кажущуюся простоту, определить, является ли заданная последовательность сайтом, сложно. Это обусловлено тем, что на связывание, кроме ха- рактера последовательности, влияют и иные факторы, в частности, другие сайты в окрестнос- ти и т.д. Разработан целый ряд алгоритмов и программ для распознавания сайтов на заданной последовательности ДНК [5]. Одним из лидеров в распознавании сайтов являются продукты компании Biobase, такие как библиотека весовых матриц Transfac и алгоритм поиска сайтов match [6]. Этой компанией была собрана БД известных сайтов, открытых биологическими методами. Затем по сайтам построены специальные модели, называемые весовыми матрицами. Весовые матрицы являются самым распространенным средством для выявления потенциальных сайтов связывания с ТФ на ДНК. В данной работе для каждой весовой матри- цы построены гистограммы распределения плотности сайтов на геноме человека, названные геномными профилями. Исследовались шесть весовых матриц библиотеки TRANSFAC компании Biobase: V$MYOD_01, V$E47_01, V$VMYB_01, V$CMYB_01, V$AP4_01, V$MEF2_01. Была экспериментально подтверждена независимость геномных профилей от порогов, задаваемых для поиска сайтов. Разработана программная система, позволяющая строить, выводить и сохранять геномные профили для заданных весовых матриц (см. http://nprog.ru/en/genomesignal.zip). Алгоритм построения геномных профилей состоит в следующем. Каждая хромосома разбивается на участки длины L (L=100 000). На каждом участке для каждой матрицы вычисляется количество предсказанных с заданным порогом сайтов. Далее для каждых хромосомы, матрицы и порога строится профиль. Затем вычисляется средний профиль для всех хромосом. Для порогов меньше 0,8 профиль практически одинаков для любого порога, поэтому можем считать, что для каждой матрицы имеем единственный профиль. Опишем шаги подробнее.
Предсказание сайтов. Весовая матрица – это матрица размером 4´N. Пример весовой матрицы V$MYOD_01 показан в таблице. В каждом столбце записана частота встречаемости в данной позиции нуклеотидов A, C, G или T соответственно. Номер строки соответствует позиции нуклеотида внутри сайта. Например, в позиции 5 частота A составляет 5, а частоты C, G и T равны 0.
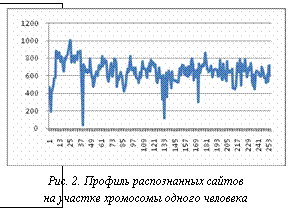
В каждой строке весовой матрицы записаны частоты встречаемости нуклеотидов A, C, G, T в соответствующей позиции в сайтах, используемых для построения данной матрицы. Зачастую многие матрицы имеют участок, называемый ядром, в котором нуклеотиды наиболее консервативны во всех сайтах исходной выборки (в данном примере – участок с позиции 04 по позицию 09). Распознавание сайтов производится в режиме скользящего окна. Для каждой позиции i последовательности S вычисляется вес матрицы w. С этой целью рассматривается фрагмент S[i, …, i+N], для которого вычисляется сумма соответствующих элементов матрицы M, как показано на рисунке 1. Вес матрицы вычисляется путем последовательного суммирования весов, соответствующих нуклеотидам последовательности, а затем нормируется в интервале [0, 1]. Далее искомый вес нормируется на интервал [0, 1] следующим образом: w=(wc–wmin)/(wmax– –wmin), где wmin и wmax – минимальный и максимальный вес последовательности. После вычисления веса последовательности он сравнивается с некоторым наперед заданным порогом c. Если w³c, то сайт в данном месте на последовательности считается распознанным, в противном случае нераспознанным. Построение профиля распознанных сайтов. Зафиксируем порог c и матрицу М. Разобьем каждую хромосому chr на участки фиксированной длины L=100 000. В каждом из таких участков произведем поиск сайтов по описанной выше процедуре. Для каждого участка chri получим количество Vi,c,M найденных на нем сайтов. Таким образом, получим профиль распознанных сайтов на каждой хромосоме (рис. 2), где по оси X отложен номер участка i, а по оси Y – количество предсказанных на данном участке сайтов, распознанных с порогом 0,3 для матрицы V$MYOD_01.
Таким образом, из графиков видно, что каждая матрица имеет свой уникальный геномный профиль. Некоторые матрицы имеют схожий геномный профиль, а у иных он отличается. Описание программной системы. Программа Genomesignal, предназначенная для построения геномных профилей матриц, написана на языке С++ с использованием MFC. Она представляет собой диалоговое окно, в котором отображаются распределение сайтов на участке хромосомы, построенный по геному или хромосоме профиль, а также функциональность, позволяющая строить и сохранять геномные профили (рис. 4). Кроме того, имеются кнопки Draw profile и Refresh, предназначенные для рисования построенных профилей по хромосоме и итогового профиля. Для них необходимо выбрать матрицу и порог; кнопка Build Total Prf предназначена для построения общего профиля по всем хромосомам; Build Chr Distr – это поиск сайтов на хромосоме.
Следующим шагом является построение одного тестового профиля по одной из хромосом. Для этого необходимо выбрать файл с выходными данными первого шага, например chr1.fa.out, выбрать матрицу и порог, а затем нажать кнопку Draw Profile. Изменяя матрицы и пороги, можно нажимать Refresh, чтобы сравнивать различные профили матриц. Но эти профили построены пока только по одной хромосоме. Чтобы построить общие профили для всех хромосом, необходимо нажать кнопку . С ее помощью также отслеживается прогресс операции и оценивается общее и затраченное время. Результирующий профиль можно отобразить по кнопке Refresh либо считать из файла profiles.out. Таким образом, разработанная автором программа позволяет строить распределения сайтов на хромосоме, сохранять и загружать, а также строить геномный профиль матрицы по всем загруженным хромосомам.
Литература 1. Rister J., Desplan C. Deciphering the genome's regulatory code: the many languages of DNA // Bioessays. 2010, May, №. 32, pp. 381–384. 2. Won K.J. [et.al.]. An integrated approach to identifying cis-regulatory modules in the human genome // PLoS One. 2009, № 4 (5). 3. Bauer D.C., Bailey T.L. Studying the functional conservation of cis-regulatory modules and their transcriptional output // BMC Bioinformatics. 2008, Apr. № 29 (9), p. 220. 4. Blanchette M. [et.al.]. Genome-wide computational prediction of transcriptional regulatory modules reveals new insights into human gene expression // Genome Res. 2006, May, № 16 (5), pp. 656–668. 5. Van Loo P., Marynen P. Computational methods for the detection of cis-regulatory modules // Brief Bioinform. 2009, Sep., № 10 (5), pp. 509–524. 6. Matys V. [et.al.]. TRANSFAC: transcriptional regulation, from patterns to profiles // Nucleic Acids Res. 2003. № 31, pp. 374–378. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
![Подпись: A C G T S[i,…,i+N]01 1 2 2 0 A02 2 1 2 0 G03 3 0 1 1 A04 0 5 0 0 C05 5 0 0 0 A06 0 0 4 1 G07 0 1 4 0 G08 0 0 0 5 T09 0 0 5 0 G10 0 1 2 2 G11 0 2 0 3 T12 1 0 3 1 TРис. 1. Вычисление веса матрицы М на подпоследовательности S[i,…,i+N]](uploaded/image/2010-4/image906.gif)
 Построение профиля матрицы. Профиль матрицы есть не что иное, как гистограмма профиля распознанных сайтов, нормированная и с отсеченными по 5 % хвостами распределения. В графике Vc,M(i), построенном на предыдущем шаге, отсортируем значения Vc,M(i) по возрастанию и отбросим 5 % значений сверху и снизу. Перед этим отбросим все нулевые значения, так как они образуются на непредсказанных участках ДНК, заполненных поли-N-сигналом. Этим способом отсекаем выбросы распределения Vc,M(i). Полученное распределение V¢c,M преобразуем следующим образом: найдем V¢max и V¢min – максимум и минимум V¢c,M. Разобьем интервал [V¢min, V¢max] на T=20 равных фрагментов d1, …, dT. Далее посчитаем количество V¢c,M(i), попавших в каждый из dt. Повторим процедуру для каждой хромосомы. Получим искомый геномный профиль Pc,M(t). Экспериментальным путем установлено, что для порогов с£0,8 корреляция между профилями больше 99 %. Таким образом, можно считать, что профиль не зависит от порога с: PM(t). Полученные профили для 6 матриц отображены на рисунке 3, где по оси X отложено относительное количество найденных сайтов, нормированное на интервал [0, 20], а по оси Y частота встречаемости такого количества сайтов в геноме.
Построение профиля матрицы. Профиль матрицы есть не что иное, как гистограмма профиля распознанных сайтов, нормированная и с отсеченными по 5 % хвостами распределения. В графике Vc,M(i), построенном на предыдущем шаге, отсортируем значения Vc,M(i) по возрастанию и отбросим 5 % значений сверху и снизу. Перед этим отбросим все нулевые значения, так как они образуются на непредсказанных участках ДНК, заполненных поли-N-сигналом. Этим способом отсекаем выбросы распределения Vc,M(i). Полученное распределение V¢c,M преобразуем следующим образом: найдем V¢max и V¢min – максимум и минимум V¢c,M. Разобьем интервал [V¢min, V¢max] на T=20 равных фрагментов d1, …, dT. Далее посчитаем количество V¢c,M(i), попавших в каждый из dt. Повторим процедуру для каждой хромосомы. Получим искомый геномный профиль Pc,M(t). Экспериментальным путем установлено, что для порогов с£0,8 корреляция между профилями больше 99 %. Таким образом, можно считать, что профиль не зависит от порога с: PM(t). Полученные профили для 6 матриц отображены на рисунке 3, где по оси X отложено относительное количество найденных сайтов, нормированное на интервал [0, 20], а по оси Y частота встречаемости такого количества сайтов в геноме.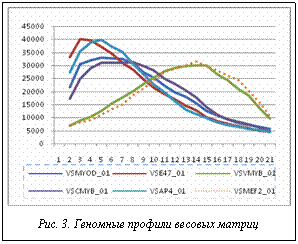 Входными данными программы являются файл с библиотекой матриц Transfac matrix.dat, а также последовательность генома человека, взятая с http://hgdownload.cse.ucsc.edu/goldenPath/hg19/ chromosomes/. Для использования программы необходимо положить файлы с последовательностью ДНК в тот же каталог, что и библиотеку матриц. Для того чтобы построить распределение сайтов по всем хромосомам, необходимо нажать кнопку . Это длительная про- цедура, поэтому в левом нижнем углу отмеча- ется прогресс операции и отображается затраченное и оцененное время на всю операцию. Если скорость расчета слишком низкая, можно сократить количество матриц в исходной библиотеке матриц.
Входными данными программы являются файл с библиотекой матриц Transfac matrix.dat, а также последовательность генома человека, взятая с http://hgdownload.cse.ucsc.edu/goldenPath/hg19/ chromosomes/. Для использования программы необходимо положить файлы с последовательностью ДНК в тот же каталог, что и библиотеку матриц. Для того чтобы построить распределение сайтов по всем хромосомам, необходимо нажать кнопку . Это длительная про- цедура, поэтому в левом нижнем углу отмеча- ется прогресс операции и отображается затраченное и оцененное время на всю операцию. Если скорость расчета слишком низкая, можно сократить количество матриц в исходной библиотеке матриц. Геномные профили матриц, разработанные автором, являются характеристикой скученности или густоты сайтов на длинных участках ДНК. Они характеризуют распределение этой густоты сайтов: то есть сколько фрагментов генома имеют одну густоту сайтов, сколько другую, сколько третью и т.д. Экспериментальным путем выведено, что построенный профиль не зависит от порога, с которым производится поиск сайтов. Это является большим преимуществом, поскольку в таком случае профиль характеризует только вид матрицы. Из графиков на рисунке 3 видно, что матрицы V$VMYB_01 и V$MEF2_01 имеют схожий тип профиля с пиком в районе 14. При этом длина матрицы V$VMYB_01 составляет 10 нуклеотидов, а V$MEF2_01 – 16. Например, длина V$MYOD_01 равна 12, из чего следует вывод, что профили не зависят от длины матрицы. Что же влияет на похожесть профилей, пока остается невыясненным и является предметом дальнейших исследований.
Геномные профили матриц, разработанные автором, являются характеристикой скученности или густоты сайтов на длинных участках ДНК. Они характеризуют распределение этой густоты сайтов: то есть сколько фрагментов генома имеют одну густоту сайтов, сколько другую, сколько третью и т.д. Экспериментальным путем выведено, что построенный профиль не зависит от порога, с которым производится поиск сайтов. Это является большим преимуществом, поскольку в таком случае профиль характеризует только вид матрицы. Из графиков на рисунке 3 видно, что матрицы V$VMYB_01 и V$MEF2_01 имеют схожий тип профиля с пиком в районе 14. При этом длина матрицы V$VMYB_01 составляет 10 нуклеотидов, а V$MEF2_01 – 16. Например, длина V$MYOD_01 равна 12, из чего следует вывод, что профили не зависят от длины матрицы. Что же влияет на похожесть профилей, пока остается невыясненным и является предметом дальнейших исследований.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2626&page=article |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Библиотека для поиска сайтов связывания с транскрипционными факторами
- Comatch – поиск партнерских сайтов связывания с транскрипционными факторами
- Система поддержки многоатрибутивного принятия решений при управлении сложными системами
- Интеллектуальный подход к задаче информирования и краткосрочного прогнозирования временного ряда в онлайн-режиме
- Применение продукционной модели представления знаний для оценки соответствия уровня подготовки кандидата требованиям должности IT-отдела
Назад, к списку статей