Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Основные операции над N-ориентированными гиперграфами в реляционной базе данных
Аннотация:Введено понятие N-ориентированного гиперграфа. Описаны операции добавления и удаления вершин и ребер в N-ориентированных гиперграфах, представленных в реляционной базе данных.
Abstract:The concept of N-oriented hypergraph. We describe the operations of adding and removing vertices and edges in N-oriented hypergraphs represented in a relational database.
| Авторы: Мокрозуб В.Г. (mokrozubv@yandex.ru) - Тамбовский государственный технический университет, кандидат технических наук | |
| Ключевые слова: операции добавления и удаления, реляционная база данных, гиперграф |
|
| Keywords: adding and deletion, relational database, hypergraph |
|
| Количество просмотров: 13995 |
Версия для печати Выпуск в формате PDF (5.09Мб) Скачать обложку в формате PDF (1.32Мб) |
Гиперграфы применяются в автоматизированных системах для процедур анализа и синтеза технических объектов. В работе [1] подробно описаны методы декомпозиции гиперграфовых структур, в [2] – операции над ультра- и гиперграфами, представленными в аналитическом виде. Данные публикации описывают операции над гиперграфами, не привязываясь к программным продуктам, в среде которых предполагается реализация автоматизированной системы. Между тем выбранная программная среда оказывает большое влияние на последовательность действий при выполнении операций над гиперграфами. Целью настоящей работы является представление N-ориентированных гиперграфов и операций добавления и удаления вершин и ребер в реляционной БД. Эти операции описываются как с помощью теории множеств, так и непосредственно операторами языка структурированных запросов, в качестве которого выбран Transact-SQL. Определение ориентированного гиперграфа Обозначим ориентированный гиперграф Ggo(X, U), где X={xi}, Пример ориентированного гиперграфа представлен на рисунке 1. Запись 41 на рисунке означает, что номер вершины x5 в ребре u4 один. Для пояснения рисунка в таблице приведены наборы вершин, инцидентных ребрам.
Определение N-ориентированного гиперграфа
Для простоты координаты (свойства) вершин обозначим номерами от 1 до N. Значение свойства n,
Примем, что значения полей первичного ключа ID_U, ID_X, ID_G определяются автоматически (например, свойство IDENTITY в Transact-SQL или счетчик в MS-Access). Будем также считать, что наименования вершины в таблице X и ребра в таблице U уникальны; FK_G_X, FK_G_U – внешние индексы, которые связывают таблицы G и X, G и U. Поля NPP_1, NPP_2, … NPP_N таблицы G представляют собой координаты (или свойства) вершины ID_X в ребре ID_U. Число координат определяется прикладной задачей. Максимальное число координат N определяется ограничениями выбранной СУБД. Так, например, для СУБД MS-SQL Server 2005 максимальное число столбцов в таблице – 1024, этого достаточно для решения практических задач по проектированию технологического оборудования и управления предприятиями химического и машиностроительного профилей. Операции над N-ориентированными гиперграфами Добавление новой вершины выполняется в два этапа: 1) добавление вершины во множество вершин, X={xi}, 2) добавление вершины во множество инцидентных ей ребер, U1ÍU, где U1 – множество ребер, которым инцидентна добавляемая вершина. При добавлении вершины в существующие ребра возможны следующие ситуации: - координаты вершин, входящих в ребро, изменяются; например, координата «порядковый номер вершины» изменяется у всех существующих вершин (увеличивается на единицу) при добавлении новой вершины с порядковым номером один; - координаты существующих вершин не изменяются. Введем следующие обозначения: xt – добавляемая вершина; U1={um1(X1m1)}, " m1ÎM1, Для представления операции добавления новой вершины в среде Transact-SQL введем таблицу свойств добавляемой вершины S1=(ID_S1, ID_U, NPP_1, NPP_2, …, NPP_N}, где ID_S1 – поле первичного ключа; ID_U – поле первичного ключа ребер, инцидентных добавляемой вершине; NPP_1, NPP_2, …, NPP_N – значения свойств добавляемой вершины в ребре ID_U. Наименование добавляемой вершины обозначим переменной @Наименование_вершины; значение поля первичного ключа – @ID_Х. С учетом введенных обозначений последовательность действий и реализация этих действий в среде Transact-SQL при добавлении новой вершины в ребро следующие. 1) Если xtÏX, то добавление xt в X: if not exists (select * from X where Наименование_вершины=@Наименование_вершины) begin insert X values(@Наименование_вершины) select @ID_X=@@Identity end 2) Добавление вершины xt в каждое ребро множества ребер U1={um1(X1m1)} со своим набором свойств S1t={s[n, t, m1]}, Insert G (ID_X, ID_U, NPP_1, NPP_2,…, NPP_N) (select @ID_X, ID_U, NPP_1, NPP_2,…, NPP_N from S1) 3) Корректировка свойств Sk вершин множества ребер U1={um1(Y1m1)} в зависимости от свойств вершины xt. Этот пункт полностью определяется характером решаемой задачи. Для примера обозначим функцию, позволяющую получить новое значение свойства NPP вершины ID_X в ребре ID_U как dbo.F_NPP(NPP, ID_X, ID_U). Тогда корректировку свойств вершин можно записать следующим образом. Sk={s[n, k, m]=f_npp(n, k, m)},
Update G set NPP_1=dbo.F_NPP('NPP_1', G. ID_X, S1.ID_U), NPP_2=dbo.F_NPP('NPP_2', G. ID_X, S1.ID_U), … , NPP_N=dbo.F_NPP('NPP_N', G.ID_X, S1.ID_U) from S1 where G.ID_U=S1.ID_U and G.ID_X< >@ID_X При добавлении нового ребра возможны два основных случая: - новое ребро содержит только существующие вершины; - новое ребро содержит новые вершины. Введем обозначения: ut – добавляемое ребро; S1t={sk, Sk}, Для представления операции добавления в Transact-SQL введем таблицу вершин добавляемого ребра X1=(ID_X1, ID_X, Наименование_вершины). В таблице X1 поле ID_X имеет значение NULL, если вершина новая (не содержится в таблице Х). Введем таблицу свойств добавляемого ребра U1=(ID_U1, ID_X, NPP_1, NPP_2, …, NPP_N), где ID_U1 – поле первичного ключа; ID_X – поле первичного ключа вершины, инцидентной добавляемому ребру; NPP_1, NPP_2, …, NPP_N – значения свойств вершин в добавляемом ребре. Обозначим наименование нового ребра как @Наименование_ребра. С учетом введенных обозначений последовательность действий и реализация этих действий в среде Transact-SQL при добавлении нового ребра следующие. 1) Добавление во множество X новых вершин, если они есть в добавляемом ребре, результат – множество X2. Если Kn¹Æ, то X2=XÈ{xk}, "kÎKn. Insert X (Наименование_вершины) (select Наименование_вершины from X1 where not exists(select * from X where X.Наименование_вершины=X1.Наименование_вер- шины)) 2) Формирование множества вершин и свойств вершин добавляемого ребра X1t={xk, Sk}, xkÎX2. Insert U1 (ID_X) (select X.ID_X from X,X1 where X.Наименование_вершины=X1.Наименова- ние_вершины) Exec INPUT_U1_NPP, где INPUT_U1_NPP – процедура, позволяющая ввести значения свойств вершин добавляемого ребра. 3) Добавление ребра ut, результат – множество U2=UÈut. Insert U values(@Наименование_ребра) set @ID_U=@@Identity Insert G (ID_X,ID_U, NPP_1, NPP_2,…, NPP_N) (select ID_X, @ID_U, NPP_1, NPP_2,.., NPP_N from U1) Удаление вершины. В [1] предлагается называть слабым удалением удаление вершины из ребра с сохранением ребер, сильным удалением – удаление вершин вместе с инцидентными ребрами. Рассмотрим следующие типовые операции удаления вершины: - из определенного ребра с сохранением ребра – простое удаление вершины; - из ребра вместе с ребром (равнозначно удалению ребра, инцидентного вершине) – составное удаление; - из всех ребер с сохранением ребер – слабое удаление; - из всех ребер вместе с ребрами (равнозначно удалению ребер, инцидентных вершине) – сильное удаление. При этом возможны как удаление вершины из множества X, так и сохранение ее в этом множестве. Удаление вершины из множества X возможно только при слабом и сильном удалении вершины, в противном случае будет нарушена целостность базы. Кроме того, удаление вершины из ребра, как и в случае с добавлением вершины в ребро, может привести к изменению координат (свойств) других вершин в этом ребре. Введем обозначения: xt, Как и в случае с добавлением вершины, корректировка свойств Sz вершин ребра uz(X1z) в зависимости от свойств вершины xt полностью определяется характером решаемой задачи. Обозначим функцию, позволяющую получить новое значение свойства NPP вершины ID_X в ребре ID_U, как dbo.F_NPP(NPP, ID_X, ID_U); @Наименование_вершины – наименование удаляемой вершины; @Наименование_ребра – наименование ребра, из которого удаляется вершина. Простое удаление вершины – удаление вершины из определенного ребра с сохранением ребра: U2={uj(X1j)Èuz(X1z\xt)}, "jÎKj, delete from G where ID_X=(select ID_X from X where Наименование_вершины=@Наименование_вершины) and ID_U= =(select ID_U from U where Наименование_ребра=@Наименование_ребра) Корректировку свойств вершин можно записать следующим образом: Sk={s[n, k, z]=f_npp(n, k, z)}, Update G set NPP_1=dbo.F_NPP( 'NPP_1', ID_X , S1.ID_U), NPP_2=dbo.F_NPP( 'NPP_2', ID_X , S1.ID_U), … , NPP_N=dbo.F_NPP( 'NPP_N', ID_X, S1.ID_U) from G where G.ID_U= (select top 1 ID_U from U where Наименование_ребра=@Наименование_ребра) Составное удаление вершины – удаление вершины из ребра вместе с ребром можно записать как U2={uj(X1j)}, "kÎKj, delete from G where ID_U=(select ID_U from U where Наименование_ребра=@Наименование_ребра) Так как ребро удаляется, корректировку свойств его вершин проводить не надо. Слабое удаление вершины – удаление вершины из всех ребер с сохранением ребер можно записать как U2={uj(X1j)Èur(X1r\xt)}, " jÎKj, " rÎ ÎKr, В нотации Transact-SQL слабое удаление вершины запишется как delete from G where ID_X=(select ID_X from X where Наименование_вершины=@Наименование_вершины) Удаление вершины из множества X, то есть Ggon(X\xt, U2), можно записать в виде delete from X where Наименование_вершины = @Наименование_вершины Если при этом внешний ключ FR_G_X описать как alter table G add constraint FK_G_X foreign key (ID_X) references X(ID_X) on delete cascade, то удаление вершины из всех ребер будет сделано при удалении вершины из множества X. Корректировку свойств вершин можно записать следующим образом: Sk={s[n, k, m]=f_npp(n, k, m)}, select @ID_X=ID_X from X where Наименование_вершины=@Наименование_вершины Update G set NPP_1=dbo.F_NPP( 'NPP_1', ID_X , ID_U), NPP_2=dbo.F_NPP( 'NPP_2', ID_X , ID_U), … , NPP_N=dbo.F_NPP( 'NPP_N', ID_X, ID_U) from G where G.ID_U in (select ID_U from G where ID_X=@ID_X) Сильное удаление вершины – удаление вершины из всех ребер вместе с ребрами: U2= ={uj(X1j)}, "jÎKj, "rÎKr, select @ID_X=ID_X from X where Наименование_вершины=@Наименование_вершины delete from G where ID_U in (select ID_U from G where ID_X=@ID_X) Так как ребра удаляются, корректировку свойств их вершин проводить не надо. Удаление ребра. По аналогии с удалением вершины будем различать следующие операции удаления ребер: - простое – удаление ребра из множества Ggon; - составное – удаление ребра из множества Ggon и удаление всех вершин удаляемого ребра из других ребер; - жесткое – удаление ребра из множества Ggon и удаление всех ребер, в которые входят вершины удаляемого ребра. При этом возможны как сохранение, так и удаление ребра и соответствующих вершин из множеств U и X. Введем обозначения: ut – удаляемое ребро, Простое удаление ребра – удаление ребра из множества Ggon: G2gon(X2, U\ut); U2=U\ut – при удалении ut из множества U или U2=U – при сохранении; X2=X – при сохранении вершин удаляемого ребра в множестве X или X2=X\X1t – при удалении вершин ребра ut из множества X. При удалении вершин удаляемого ребра из множества X для обеспечения целостности БД также необходимо удалить эти вершины из всех ребер, в которые они входят, то есть U2={uj(X1j\X3j)}, где X3j=X1jÇX1t, X3j¹Æ, Sk={s[n, k, j]=f_npp(n, k, j)},
Пусть X3=(ID_Х3, ID_X, NPP_1, …, NPP_N) – таблица, содержащая ID_X вершин и свойства вершин удаляемого ребра; @ID_U – ID_U удаляемого ребра. select @ID_U=ID_U from U where Наименование_ребра=@Наименование_ребра /* Запоминание множества вершин удаляемого ребра */ select ID_X, NPP_1, …, NPP_N into X3 from G where ID_U=@ID_U /* Удаление ребра */ delete from G whеre ID_U=@ID_U При удалении вершин удаляемого ребра из множества X для обеспечения целостности БД необходимо удалить эти вершины из всех ребер гиперграфа и, соответственно, произвести корректировку свойств оставшихся в этих ребрах вершин. Причем сначала надо выполнить корректировку вершин, а потом их удаление. В этом случае простое удаление трансформируется в составное. /* Корректировка свойств вершин */ update G set NPP_1=dbo.F_NPP( 'NPP_1', ID_X , ID_U) , NPP_2=dbo.F_NPP( 'NPP_1', ID_X , ID_U) , … , NPP_N=dbo.F_NPP( 'NPP_N', ID_X, ID_U) from G, X3 where ID_U= (select ID_U from G where ID_X in (Select ID_X from X3)) and ID_U< >@ID_U delete from X where ID_X in (select ID_X from X3) Если внешний ключ FR_G_X описать как alter table G add constraint FK_G_X foreign key (ID_X) references X(ID_X) on delete cascade, то удаление вершин из всех ребер будет сделано при удалении вершины из множества X, в противном случае можно воспользоваться оператором delete from G where ID_U< >@ID_U and ID_X in (select ID_X from X3) Составное удаление ребра – удаление ребра и удаление всех вершин удаляемого ребра из других ребер. Составное удаление ребра – это простое удаление с удалением вершин ребра из множества X, которое описано выше. Жесткое удаление ребра – удаление ребра и удаление всех ребер, в которые входят вершины удаляемого ребра, сводится к получению гиперграфа G2gon(X2, U\U3), где X2=X при сохранении вершин удаляемого ребра в множестве X или X2=X\X1t при удалении вершин ребра ut из множества X; U3 – множество ребер, в которые входят вершины удаляемого ребра, U3={uj(X1j)}, X1jÇ ÇX1t¹Æ, Пусть X3=(ID_X3, ID_X) – таблица, содержащая ID_X вершин удаляемого ребра; @ID_U – ID_U удаляемого ребра, тогда жесткое удаление ребра можно записать как select @ID_U=ID_U from U where Наименование_ребра=@Наименование_ребра select distinct ID_X into X3 from G where ID_U=@ID_U delete from G where ID_U in (select ID_U from G where ID_X in (select ID_X from X3)) На основании изложенного можно сделать следующее заключение. В работе введено понятие N-ориентированного гиперграфа и описаны основные операции над такими гиперграфами, представленными в реляционной БД. Эти операции имеют как теоретико-множественное описание, так и описание на языке Transact-SQL. N-ориентированные гиперграфы и операции над ними использовались для описания структуры технических объектов и создания программных шаблонов, предназначенных для разработки систем автоматизированного управления [4] и проектирования технологического оборудования [5]. Литература 1. Батищев Д.И., Старостин Н.В., Филимонов А.В. Многоуровневая декомпозиция гиперграфовых структур // Приложение к журналу «Информационные технологии». 2008. № 5. 34 с. 2. Овчинников В.А. Операции над ультра- и гиперграфами для реализации процедур анализа и синтеза структур сложных систем // Наука и образование. 2009. № 10. URL: http://technomag.edu.ru/doc/132769.html (дата обращения: 11.02.2010). 3. Мокрозуб В.Г. [и др.]. Применение гиперграфов и реляционной базы данных для описания структуры радиотехнических систем // Успехи современной радиоэлектроники. 2009. № 11. С. 37–41. 4. Мокрозуб В.Г., Егоров С.Я., Немтинов В.А. Процедурные и информационно-логические модели планирования выпуска продукции и ремонтов технологического оборудования многоассортиментных производств // Информационные технологии в проектировании и производстве. 2009. № 2. С. 72–76. 5. Мокрозуб В.Г., Мариковская М.П., Красильников В.Е. Интеллектуальная автоматизированная система проектирования химического оборудования // Системы управления и информационные технологии. 2007. № 4.2(30). С. 264–267. |
 – множество вершин гиперграфа, xi – i-я вершина; U={um(X1m)},
– множество вершин гиперграфа, xi – i-я вершина; U={um(X1m)}, 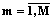 – множество ребер гиперграфа, um(X1m) – m-е ребро гиперграфа, X1m – множество вершин, инцидентных m-му ребру X1mÍX,
– множество ребер гиперграфа, um(X1m) – m-е ребро гиперграфа, X1m – множество вершин, инцидентных m-му ребру X1mÍX, 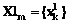 , " kÎKm,
, " kÎKm,  , l – номер вершины в ребре ориентированного гиперграфа,
, l – номер вершины в ребре ориентированного гиперграфа,  , Lm – число вершин в ребре m. При этом будем считать, что наборы вершин {x1, x2, x3} и {x2, x1, x3} разные.
, Lm – число вершин в ребре m. При этом будем считать, что наборы вершин {x1, x2, x3} и {x2, x1, x3} разные. По аналогии с ориентированным гиперграфом обозначим N-ориентированный гиперграф Ggon(X, U), где X={xi},
По аналогии с ориентированным гиперграфом обозначим N-ориентированный гиперграф Ggon(X, U), где X={xi},  , " kÎKm,
, " kÎKm,  – номер вершины в ребре ориентированного гиперграфа представляет собой вектор,
– номер вершины в ребре ориентированного гиперграфа представляет собой вектор,  , мощность которого N. В общем случае номер вершины в ребре необязательно должен иметь значение «номер по порядку» и может отражать определенное свойство вершины, которое принимает конкретное значение при включении вершины в ребро. При этом предполагается, что все вершины в ребрах имеют одинаковый набор свойств.
, мощность которого N. В общем случае номер вершины в ребре необязательно должен иметь значение «номер по порядку» и может отражать определенное свойство вершины, которое принимает конкретное значение при включении вершины в ребро. При этом предполагается, что все вершины в ребрах имеют одинаковый набор свойств. , вершины xi, xiÎX, в ребре um, umÎU, обозначим s[n, i, m]. С учетом сказанного множество вершин, инцидентных m-му ребру X1mÍX, с множеством значений свойств каждой вершины в ребре обозначим X1m={xk, Sk}, где "kÎKm,
, вершины xi, xiÎX, в ребре um, umÎU, обозначим s[n, i, m]. С учетом сказанного множество вершин, инцидентных m-му ребру X1mÍX, с множеством значений свойств каждой вершины в ребре обозначим X1m={xk, Sk}, где "kÎKm,  .
.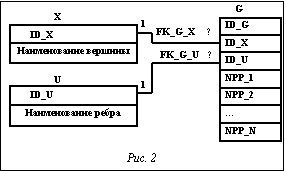 По аналогии со схемой данных ориентированного гиперграфа [3] представим схему данных N-ориентированного гиперграфа (рис. 2).
По аналогии со схемой данных ориентированного гиперграфа [3] представим схему данных N-ориентированного гиперграфа (рис. 2). – множество ребер гиперграфа, которым инцидентна вершина xt; X1m1={xk, Sk} – множество вершин и свойств вершин ребер, инцидентных добавляемой вершине; Sk={s[n, k, m1]},
– множество ребер гиперграфа, которым инцидентна вершина xt; X1m1={xk, Sk} – множество вершин и свойств вершин ребер, инцидентных добавляемой вершине; Sk={s[n, k, m1]}, 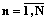 , " kÎKm1,
, " kÎKm1,  . Вершина xt добавляется в каждое ребро со своим набором координат (свойств), которые обозначим как S1t={s[n, t, m1]},
. Вершина xt добавляется в каждое ребро со своим набором координат (свойств), которые обозначим как S1t={s[n, t, m1]}, 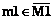 ,
, 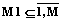 ,
, , то есть в результате получаем U={um(X2m)}, X2m=Xm2È(Xm1Çxt), " m2ÎM\M1, " m1ÎM1, где m1, m2 – индексы ребер, инцидентных и не инцидентных вершине xt.
, то есть в результате получаем U={um(X2m)}, X2m=Xm2È(Xm1Çxt), " m2ÎM\M1, " m1ÎM1, где m1, m2 – индексы ребер, инцидентных и не инцидентных вершине xt. , "mÎM1, M1ÍM, где f_npp(n, k, m) – функция, позволяющая найти новое значение свойства n вершины k в ребре m.
, "mÎM1, M1ÍM, где f_npp(n, k, m) – функция, позволяющая найти новое значение свойства n вершины k в ребре m. – множество вершин ребра с их свойствами; Sk={s[n, k, t]},
– множество вершин ребра с их свойствами; Sk={s[n, k, t]},  .
.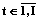 – удаляемая вершина; uz,
– удаляемая вершина; uz,  – ребро, из которого удаляется вершина; X1j, X1z – множество вершин, инцидентных j-му и z-му ребрам; U2 – множество ребер после удаления; Ggon(X\xt, U2) – получаемый гиперграф при удалении вершины из множества X; Ggon(X, U2) – получаемый гиперграф без удаления вершины из множества X; U2 – множество ребер гиперграфа, получаемое после удаления вершины xt.
– ребро, из которого удаляется вершина; X1j, X1z – множество вершин, инцидентных j-му и z-му ребрам; U2 – множество ребер после удаления; Ggon(X\xt, U2) – получаемый гиперграф при удалении вершины из множества X; Ggon(X, U2) – получаемый гиперграф без удаления вершины из множества X; U2 – множество ребер гиперграфа, получаемое после удаления вершины xt. .
. , в нотации Transact-SQL как
, в нотации Transact-SQL как ,
,  , где Kr=M\Kj, где Kj – множество индексов ребер, не инцидентных вершине xt; Kr – множество индексов ребер, инцидентных вершине xt.
, где Kr=M\Kj, где Kj – множество индексов ребер, не инцидентных вершине xt; Kr – множество индексов ребер, инцидентных вершине xt.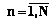 , "kÎKm1,
, "kÎKm1,  , "mÎKr, KrÍM
, "mÎKr, KrÍM ,
,  ; X1t – множество вершин ребра ut; U2, X2, G2gon(X2, U2) – множество ребер, вершин и граф, соответственно, получаемых после удаления ребра ut.
; X1t – множество вершин ребра ut; U2, X2, G2gon(X2, U2) – множество ребер, вершин и граф, соответственно, получаемых после удаления ребра ut. . В этом случае следует провести корректировку свойств оставшихся вершин. Обозначим через Kt множество индексов вершин удаляемого ребра. Тогда корректировку свойств оставшихся вершин можно записать следующим образом:
. В этом случае следует провести корректировку свойств оставшихся вершин. Обозначим через Kt множество индексов вершин удаляемого ребра. Тогда корректировку свойств оставшихся вершин можно записать следующим образом: ,
, 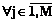 , X3j¹Æ, X3j=X1jÇX1t.
, X3j¹Æ, X3j=X1jÇX1t.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2715&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.09Мб) Скачать обложку в формате PDF (1.32Мб) |
| Статья опубликована в выпуске журнала № 1 за 2011 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик: