Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Задача определения группы риска для однородных транспортных узлов
Аннотация:Метод дискриминантного анализа позволяет построить линейную дискриминантную функцию, делящую все од-нородные транспортные узлы на две группы с целью оценки риска их существования или банкротства в зависимости от основных показателей финансово-хозяйственной деятельности. Настоящая работа посвящена решению задачи по-строения модели определения группы риска для однородных транспортных узлов (порт, терминал, грузовая площадка и т.п.).
Abstract:The method of the discriminantal analysis, allows to construct the linear discriminantal function dividing all homogeneous transport units (THOSE) on two groups with the purpose of an estimation of risk of their existence or bankruptcy depending on the basic parameters of financial and economic activity. For homogeneous THAT (port, the terminal, a cargo platform, etc.) the present work is devoted to the decision of a problem of construction of model of definition of group of risk.
| Авторы: Веслав Пасевич (i.arefyev@am.szczecin.pl) - Институт математики Западно-Поморского технологического университета, г. Щецин, Польша, кандидат технических наук | |
| Ключевые слова: дискриминантная функция, модель, риск, вероятность, транспортный узел |
|
| Keywords: discriminant function, mathematical model, risk, probability, transportation hub |
|
| Количество просмотров: 15304 |
Версия для печати Выпуск в формате PDF (5.09Мб) Скачать обложку в формате PDF (1.32Мб) |
Вероятностная интерпретация моделей риска в транспортных системах обусловливает необходимость использования метода дискриминантного анализа и распределений многомерных, статистически зависимых случайных величин [1]. Так, например, выборке Ю. Бригхема соответствует дискриминантная функция Z= –0,3877– –1,0736KTL+0,0579DЗK, где KTL – коэффициент текущей ликвидности, DЗK – доля заемного капитала. В практике транспортных предприятий (ТП) вполне применима модель Э.И. Альтмана, как это показано, например, в [2]: Z=0,012x1+0,014x2+ +0,033x3+0,006x4+0,999x5, где x1 – отношение собственных оборотных средств к сумме активов, x2 – отношение нераспределенной прибыли к сумме активов, x3 – отношение прибыли до вычета процентов и налогов к сумме активов, x4 – отношение рыночной стоимости обыкновенных и привилегированных акций к балансовой оценке заемного капитала, x5 – отношение выручки от реализации к сумме активов. Однако следует заметить, что использование дискриминантной функции Z в случае транспортного узла (ТУ) может дать лишь качественную оценку риска [3]. Например, вероятность банкротства ТУ по модели Альтмана оценивается как очень высокая при Z<1,8, высокая при 1,8<2,7, возможная при 2,7<2,9, очень низкая при Z>2,9. Это обстоятельство объясняется тем, что распределение вероятностей индекса Z в дискриминантном методе не оценивается. Традиционно оценка степени доверия основывается на методе экспертных оценок, ретроспективном анализе и независимом аудиторском контроле. В результате проведенного анализа может быть построена морфологическая матрица доверия ТУ (табл. 1). Таблица 1 Морфологическая матрица доверия
Примечание: KFI – коэффициент фондовооруженности труда с учетом износа основных фондов; BY – удельный вес вложений в производственные активы; HKFI и HBY – нормальные значения этих показателей, выбираемые на основании среднестатистических значений для конкретных типов подрядных организаций. Необходимо найти информационно-статистические методы определения степени доверия и ее корректировки на этой основе. До последнего времени использовалась количественная вероятность, а качественная рассматривалась только в теоретической постановке. Однако в теории принятия решений уже появились специальные процедуры, рассчитанные на анализ качественной информации [4]. В связи с этим понятие качественной вероятности приобрело самостоятельное практическое значение. Для получения количественных оценок субъективной вероятности разработано достаточно большое число методов, но практически все они (методы отношений, собственного значения, равноценной корзины, переменного интервала, фиксированного интервала и др.) основаны на экспертном анализе. Автоматизация процедур управления, особенно значимая в политранспортных процессах, диктует целесообразность использования формализованных методов получения количественных оценок субъективной вероятности на основе теоретико-информационного подхода [2]. Поэтому в качестве первого этапа поставленной задачи предполагаются описание и формирование множества объектов и критериев, по которым производится сравнение. В принципе не может быть надежных способов контроля полноты учета всех возможных факторов, влияющих на итоговую оценку. Однако, если ввести в рассмотрение большое количество факторов и соответствующих им критериев сравнения, определяющих предпочтительность того или иного объекта, то достаточно эффективными статистическими методами можно отделить закономерную составляющую комплексного (обобщенного) показателя. Это может быть показатель, полученный от случайной составляющей, обусловленной неполнотой учета всех возможных факторов и методическими ошибками. Предлагаемый подход основан на аксиомах, позволяющих схематизировать процесс определения предпочтительности выбора того или иного варианта: - аксиома полной упорядоченности, когда руководитель способен упорядочить все возможные варианты с помощью отношений предпочтения (x>y) или безразличия (x~y); - аксиома транзитивности, когда сама аксиома отражает следующие свойства величин: если первая величина сравнима со второй, а вторая с третьей, то первая величина сравнима с третьей. Когда для некоторых критериев предпочтительность объектов определена на качественном уровне с помощью ранговых оценок или баллов, целесообразно использовать принцип максимума неопределенности. Количественная оценка показателя Pi может быть представлена в виде
где i – порядковый номер предпочтения объекта в общей совокупности, определяемый по отношению порядка предпочтения. Справедливость зависимости вытекает из решения следующей экстремальной задачи:
где H2(Pi) – мера неопределенности второго рода. Для определения показателей весомости (с учетом значения оценочных показателей ВY и КFI) представляется целесообразным использовать условие нормировки, из которой следует зависимость вида
где rj – значение оценочного коэффициента на основе статистических значений показателей ВY и КFI, Рассмотрим применение предложенного метода корректировки показателя доверия на основе подхода на любой строке (табл. 1). Пусть для первого столбца BY=K1HBY (K1<1), для второго – BY=K2HBY (K2=1), для третьего – BY=K3HBY (K3>1). Значения Ki (i=1, 2, 3) определены на основе статистического анализа [1]. Оценкам Фишборна (1) соответствуют значения Можно найти зависимость Pi [3]:
Дальнейшая корректировка показателей в таблице 1 может производиться аналогично. Оценка экономической устойчивости логистических систем представляет большую трудность, обусловленную необходимостью одновременного учета нескольких различных признаков и показателей. Если проанализировать подходы к указанной проблеме (метод МДА, дискриминантные функции, модель Э.И. Альтмана), можно сделать вывод качественного характера: вероятность банкротства мала (высока) или при определенных значениях индекса дискриминантной функции определяется зона неведения [5]. С другой стороны, по выборке, характеризующей реализацию распределения двух случайных величин X и Y, можно определить частные (маргинальные) законы распределения F(x) и G(y), а также оценить математические ожидания Параметр g является линейной функцией коэффициента корреляции: g=rxyJ0[F(x), G(y)], где J0[F(x), G(y)] – функционал, определяемый маргинальными распределениями F(x) и G(y):
Согласно сформулированной в [3] зависимости определения случайной величины
получим
Например, если x и y распределены по экспоненциальным законам, функционал J0 равен 4, если по равномерным законам – равен 3 и т.д. После определения значения параметра g вероятность банкротства определится в общем виде
где x1, y1 – параметры финансово-хозяйственной деятельности ТП. Учитывая специфику транспорта, дополнительно рассмотрим и аналогичное решение для распределений Вейбулла [1, 2]:
После очевидных преобразований зависимость (6) примет вид:
где Таким образом, на основе методологии дискриминантного анализа можно построить линейную дискриминантную функцию. Этой функцией можно делить группу однородных ТП, например ТУ, на две группы риска. По результату анализа отнесем их либо к благополучной группе, либо к группе ликвидации (банкротства) в зависимости от основных показателей финансово-хозяйственной деятельности. Указанное соотнесение базируется на статистическом анализе данных состояния ТП и использовании законов распределения вида (5), что позволяет вывести степень риска P на количественном уровне. При современных организации и управлении перевозками по мультимодальному принципу создание новых коридоров, путей и коммуникаций приводит к тому, что в группу риска может попасть любой ТУ как предприятие, имеющее тенденцию к снижению грузооборота или рентабельности по причине изменения (исключения) соответствующего маршрута доставки. Следовательно, используя расчетные данные по возможной переориентации грузовых потоков, на основе предлагаемого подхода можно прогнозировать состояние ТУ, обслуживающих конкретные маршруты, попадающие в группу риска. Для этого достаточно определить группу исходных показателей состояния ТУ по приведенной методике при различных вариантах характерных признаков. Иными словами, если найти вероятность банкротства в общем виде (5) и маргинальные законы общего распределения грузопотоков для каждого ТУ, можно решить задачу выделения ТУ, входящих в группу риска по показателю минимума прибыли за установленный период времени. Рассмотрим пример. Региональные перевозки замыкаются на пяти однородных ТУ, которые обозначены Т1, Т2, Т3, Т4, Т5. При этом возможны четыре варианта организации грузопотоков, об- рабатываемых в этих ТУ. Прогнозируемые (ве- роятностные) объемы груза для каждого ТУ составляют 50, 100, 150, 200 условных единиц соответственно. К таким единицам можно отнести контейнер конкретного типа, тонну сыпучего или жидкого груза, штучно-тарную упаковку, стандартный поддон и т.п. Очевидно, что прогнозируемый прирост (падение) прибыли каждого ТУ зависит от объема заявленного для обработки груза. Исчисление прибыли принимается в тысячах рублей на планируемый период: день, декада, месяц, квартал, год (табл. 2). Необходимо построить план распределения грузов для каждого варианта, когда за критерий оптимальности принимается общее ожидаемое значение прироста прибылей для всех пяти ТУ территориального (регионального) объединения на принятом периоде планирования, и определить их группу риска. Обозначим через xi (i=1, 2, 3, 4, 5) прогнозируемый объем грузов для i-го ТУ, h(xi) – значение прироста прибылей в i-м ТУ на заданном интервале времени, h(xi) – величину прироста прибыли в i-м ТУ. Решение задачи сводится к определению значений искомых переменных xi, которые максимизируют функцию F с учетом условий (7, 8). F(x1, x2, …, xn)=h(x1)+h(x2)+… +h(xn). (7) x1+x2+…+xn=c, (xi³0) для i=1, 2, …, n. (8) Таблица 2 Данные для четырех вариантов плана
Присвоим n-му состоянию системы ресурс в размере xn. Тогда получим результат h(xn) при 0≤xn≤аn=с. Оставшийся ресурс в размере an-1= =an–xn единиц распределим так, чтобы эффект от оставшихся n–1 состояний был максимальным. Найдем максимальное значение этого эффекта от оставшихся n–1 состояний с помощью f(an-1). Тогда полный эффект от n состояний будет
Оптимальным значением xn является такое, которое максимизирует функцию (9). Отсюда находим максимальное значение эффекта для n-го состояния: f(an)= Получаем следующие функциональные уравнения:
Уравнения (11) позволяют найти оптимальное распределение наличных ресурсов с целью получения максимального эффекта. Решение задачи сводится к определению искомых переменных xi, которые максимизируют функцию F при условии (8), где а5 принимает значения 50, 100, 150, 200; ai определяет совокупный объем грузов для i предприятий (i=1, 2, 3, 4, 5). На основании уравнений (10) и (11) и таблицы 1 получаем: 1° для x1: f(a1)=max[h(a1)] = h(a1) , a1= x1; 2° для x2: f(a2)= 3° для x3: f(a3)= 4° для x4: f(a4)= 5° для x5: f(a5)= Определим величины f(a1), f(a2), f(a3), f(a4) и f(a5) при условиях 1°–5°. Алгоритм решения покажем для f(a1) и для f(a2). Величина a1 может принимать значения 0, 50, 100, 150, 200. Если a1=0, то a1=x1=0 и в соответствии с выражением 1° и таблицей 1 получим: при a1=0 a1=x1=0, тогда f(a1=0)= Если a1=50, то a1=x1=50, тогда для реализации 1° f(a1=50)= Аналогично для a1=100, 150 и 200 последовательно оптимизируем: f(a1=100)=70, f(a1=150)=100 и f(a1=200)=140. Согласно изложенному алгоритму определим: a2=0, 50, 100, 150, 200. Если принять a2=0, то a1=x2=0, то есть a2=a1+x2 и далее для реализации 2° при f(a1=0)=0 и из таблицы 1 получим: f(a2=0)= =max[h2(0)+f(0)]=max[0+0]=0. Если a2=50, то a1=50 и x2=0 или a1=0 и x2=50, что покажем в виде таблицы:
Перейдем к реализации 2°: f(a1=50)=25 : f(a2=50)= = =max[0+25, 30+0]=max[25+30]=30. Это значит, что наибольшее значение будет для случая f(a2=50)=30 при a1=0 и x2=50. Если же a2=100, поступая аналогично, найдем:
Тогда f(a2=100)=
=max[0+70, 30+25, 70+0]=70. Это значит, что f(a2=100)=70 достигается при a1=0 и x2=100. Далее выберем a1=100 и x2=0. Если a2=150, то
Находим f(a2=150)=
h2(x2)=150)+f(a1=0)]= =max[0+100, 30+70, 70+25, 90+0]=100. Наибольшее f(a2=150)=100 достигается при a1=150 и x2=0, то же для a1=150 и x2=50. Для дальнейших решений выберем a1=150 и x2=0. Если a2=200, получим:
f(a2=200)=
h2(x2)=150+f(a1=50), h2(x2)=200+f(a1=0)]= =max[0+140, 30+100, 70+70, 90+25, 122+0]=140. Это значит, что наибольшая величина f(a2=200)=140 достигается при a1=200 и x2=0, так же для a1=100 и x2=100. Примем a1=200 и x2=0. Дальнейшие результаты сведем в таблицу 3. Таблица 3 Результаты расчета для x1 и x2
В соответствии с приведенным алгоритмом получим решения для f(a3), f(a4), f(a5) и сведем их в таблицу 4. Таблица 4 Таблица решений для x3, x4, x5
Из таблиц 3 и 4 найдем значения искомых переменных, если примем а5=200. Получаем совокупное решение для всех пяти вариантов: a5=200 ® a4=100 и x5=100, a4=100 ® a3=100 и x4=0, a3=100 ® a2=100 и x3=0, a2=100 ® a1=100 и x2=0, a1=100 ® x1=100. Тогда для а5=200 искомые решения принимают значения x1=100, x2=0, x3=0, x4=0, x5=100. Оптимальную совокупную величину прироста прибыли для заданного периода планирования найдем из таблицы 2: f(a5)=h(x1=100)+h(x5=100)= =70+80=150. Аналогично найдем значения искомых переменных, когда а5=150, 100 или 50. Полученные для а5=200 результаты представлены в таблице 5. Таблица 5 Данные для принятия решения
Из таблицы 5 следует: если общий объем грузов составляет 200 условных единиц, предприятиям Т1 и Т5 необходимо распределить по 100 единиц груза. Тогда максимальная общая величина прироста прибыли за период будет составлять 150 условных единиц. Таким же образом можно вычислить распределение груза и общую величину прироста прибыли за планируемый период для а5=50, 100, 150. Когда наибольшее значение f(ai) получается в двух (или более) случаях (как, например, в приведенном решении f(a2=200)=140 это справедиво как для a1=200 и x2=0, так и для a1=100 и x2=100), тогда допустим вариант, при котором весь груз может быть обработан любым из всех ТУ по решению диспетчера или руководителя объединения. Возможны и другие решения, когда по результатам приведенных расчетов из схемы обработки грузопотоков данного региона (низкая прибыль, малая рентабельность, необходимость дополнительных капитальных вложений, реновация и т.п.) можно исключить несколько ТУ. Они и составят группу риска. Данные, приведенные в примере алгоритма, носят условный характер и служат только для иллюстрации метода. Литература 1. Арефьев И.Б., Мартыщенко Л.А. Теория управления. СПб: Изд-во СЗТУ, 2000. 176 с. 2. Пасевич В. Анализ и прогнозирование транспортных систем. СПб: Система, 2005. 84 с. 3. Арефьев И.Б., Кивалов А.Н., Мартыщенко Л.А. Аналитическая логистика. СПб: Изд-во СЗТУ, 2007. 94 с. 4. Клавдиев А.А., Пасевич В. Адаптивные технологии информационно-вероятностного анализа транспортных систем. СПб: Изд-во СЗТУ, 2009. 305 с. 5. Родников А.Н. Логистика. Терминологический словарь. М.: ИНФРА, 2000. 139 с. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
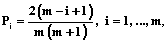 (1)
(1)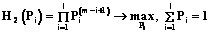 ,
, , (2)
, (2)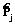 – показатель весомости, найденный на основе принципа максимума меры неопределенности [2].
– показатель весомости, найденный на основе принципа максимума меры неопределенности [2].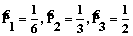 .
.
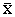 и
и 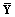 , дисперсии
, дисперсии 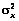 и
и 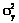 и коэффициент корреляции rxy. Это обстоятельство обусловливает необходимость введения совместной плотности распределения случайных величин h(x, y). В качестве критерия соответствия моделируемых случайных величин следует принять требование тождества математических ожиданий, дисперсий и коэффициента корреляции (тождество случайных векторов в пределах корреляционной теории). В этом случае наиболее адекватной формой совместной плотности случайных величин, построенной по маргинальным распределениям, является плотность распределения h(x, y)=f(x)g(y){1+g[1–2F(x)] [1–2G(y)]}, где g – параметр закона.
и коэффициент корреляции rxy. Это обстоятельство обусловливает необходимость введения совместной плотности распределения случайных величин h(x, y). В качестве критерия соответствия моделируемых случайных величин следует принять требование тождества математических ожиданий, дисперсий и коэффициента корреляции (тождество случайных векторов в пределах корреляционной теории). В этом случае наиболее адекватной формой совместной плотности случайных величин, построенной по маргинальным распределениям, является плотность распределения h(x, y)=f(x)g(y){1+g[1–2F(x)] [1–2G(y)]}, где g – параметр закона.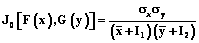 . (3)
. (3)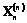 ,
,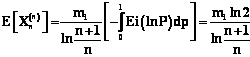 , (4)
, (4)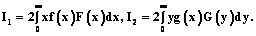
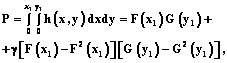 (5)
(5)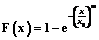 и
и 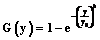 . (6)
. (6)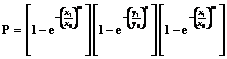
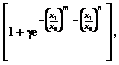
 , vx, vy – коэффициенты вариации случайных величин x и y, определяемые по принятой выборке.
, vx, vy – коэффициенты вариации случайных величин x и y, определяемые по принятой выборке.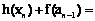
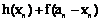 . (9)
. (9)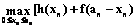 ]. (10)
]. (10)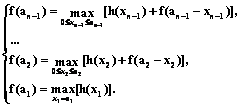 (11)
(11)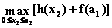 , a2=a1+x2;
, a2=a1+x2;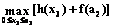 , a3=a2+x3;
, a3=a2+x3;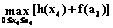 , a4=a3+x4;
, a4=a3+x4;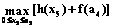 , a5=a4+x5.
, a5=a4+x5.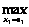 [h1(x1=a1)]=h1(x1)=max[h1(0)]=h1(0)=0.
[h1(x1=a1)]=h1(x1)=max[h1(0)]=h1(0)=0.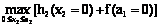 =
=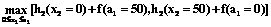 =
=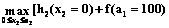 ,
,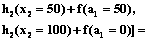
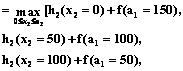
 ,
,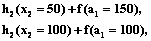
| Постоянный адрес статьи: http://swsys.ru/index.php?id=2735&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.09Мб) Скачать обложку в формате PDF (1.32Мб) |
| Статья опубликована в выпуске журнала № 1 за 2011 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Метод оценки вероятности принятия ошибочных решений при дискриминационном анализе транспортных узлов
- Генератор текста программ в исходном виде для систем реального времени
- Информационное обеспечение процессов развития больших систем административно-организационного управления
- Прогнозирование временного ряда инфекционной заболеваемости
- Моделирование информационных ресурсов при процессной организации системы управления предприятием
Назад, к списку статей