Система распознавания терминов таксономии в документах на естественном языке
| Якимов В.Н. (yvnr@hotmail.com) - Самарский государственный технический университет (профессор), г. Самара, Россия, доктор технических наук, Мошков И.С. (moshkoff@list.ru) - Самарский государственный технический университет | |
| Ключевые слова: таксономическая структура, анализ текста, естественный язык |
|
| Keywords: taxonomic structure, text processing, natural language |
|
|
|
|
Рост потока информации на естественном языке (ЕЯ) требует подключения систем распознавания документов на нем. Однако универсальные инструменты анализа языка не разработаны. Решаются лишь частные задачи, и возникновение новых требований зачастую приводит к усложнению или разработке новых систем языкового анализа. Поэтому задача построения систем анализа документов на ЕЯ так актуальна. Одним из приложений систем распознавания ЕЯ документов является анализ качества структурирования предметной области человеком. Известно, что в процессе понимания предметной области повышается эффективность структурирования знаний о ней, что увеличивает время извлечения знаний и принятия решений на их основе. Следовательно, анализируя качество структурирования знаний в письменном тексте, можно построить систему автоматической обработки результатов открытого тестирования. Некоторые особенности текста на ЕЯ (неполнота, избыточность, противоречивость) создают трудности при создании инструмента для полноценного анализа текста [1, 2]. Таким образом, возникает потребность в разработке формальных способов анализа, которые, с одной стороны, позволили бы проводить автоматический анализ текста, необходимого для оценки знаний, а с другой – упростили бы анализ за счет введения ряда допустимых ограничений, сохраняющих необходимый уровень его качества. Одним из таких ограничений является использование в качестве анализируемого материала текста, описывающего таксономическую структуру. Это обусловлено тем, что практически в любой области науки и техники требуются структурирование и классификация имеющихся знаний [1, 3, 4]. Следовательно, для оценки знаний человека необходимо иметь систему распознавания терминов таксономии, которая описывается в документе на ЕЯ. Анализ структурных особенностей текста Для того чтобы сформулировать требования к формальному аппарату анализа, поделим высказывание на ЕЯ, описывающее таксономию, на отдельные части и определим функции, которые они выполняют в тексте, а также возможные способы их нахождения. Используем выражение j=áObj, L, K, Tñ, где представлены множества: Obj – сложных составных терминов (ССТ); L – связей между ними; K – критериев деления терминов; T – метаязыковых конструкций, описывающих качественные особенности таксономии. Для определенности в качестве примера используем следующее высказывание: «По химической классификации нефть делится на три основные группы: парафиновые нефти, нафтеновые нефти, ароматические нефти». К множеству Obj относятся термины, заданные словосочетаниями «парафиновые нефти», «нафтеновые нефти»; к множеству L – «делится»; к множеству K – «по химической классификации»; к множеству T – «три основные группы». Для большинства ССТ, встречающихся в таксономических текстах, характерны три составные части [5]. Поэтому зададим структуру термина obj как вектор obj=áo, P, obj¢ñ, где o – корневой элемент; P – множество признаков корневого элемента; obj¢ – внутренний термин, зависимый от корневого элемента. Для наглядности введем пример: «Повреждения рельсов делятся на изгибы, повреждения в шейке, изломы по всему сечению и дефекты подошвы. Изломы бывают поперечными с видимыми пороками и без видимых пороков». Выделим три основные части ССТ. 1. Корневой элемент o (ядро ССТ) на семантическом уровне является классом терминов в эталонной таксономии, в который входит множество зависимых элементов. Под эталонной таксономией понимается экспертно заданное описание всех возможных классификаций предметной области. Элементы данного множества разделяются за счет использования в их описании различного рода признаков. На синтаксическом уровне таким признаком является слово, которому подчиняется остальная часть описания термина. Это также означает, что остальная часть грамматически согласована с корневым элементом. В используемом примере можно выделить два класса терминов: - «повреждения», «изгибы», «изломы» – класс понятий, объединяемых словом «повреждения»; - «рельс», «подошва», «шейка» – класс понятий, объединяемых словом «рельс». 2. Признаковая часть P на семантическом уровне является суммой всех признаков, определяющих занимаемое место среди множества элементов некоторого класса термина. На синтаксическом уровне признаками, как правило, бывают определения (прилагательные, причастные обороты, согласованные второстепенные члены предложения). Кроме того, в признаковую часть могут входить ССТ, связанные с ядром предложно-падежной конструкцией. В используемом примере признаком является слово «поперечные», относящееся к корневому элементу «излом». 3. Субъект obj¢ на семантическом уровне есть значение, описываемое фразой и подчиненное ядру. С одной стороны, он является частью родительского термина, а с другой – самостоятельным значимым термином, имеет такую же структуру, как и весь ССТ, причем корневой элемент субъекта синтаксически согласован с корневым элементом данного термина. При этом каждый внутренний термин может относиться к различным классам предметной области. Схематично структура ССТ показана на рисунке 1. Построение формального аппарата описания ССТ Зададим способы определения морфологических характеристик слов, описывающих ССТ. Существуют два основных способа морфологического анализа: на основе словаря и с помощью морфемного анализа [2]. Для достижения поставленных целей использован подход на основе создания таблицы всех словоформ, так как он проще в реализации, а предметная область описывается конечным набором слов. Для получения представления о структуре текста и входящих в него терминов необходимо оперировать синтаксическими характеристиками. Причем существует взаимосвязь между синтаксической ролью в предложении и местоположением в структуре ССТ. Поэтому введем предикат Flsync, определяющий лингвистическую согласованность текстового выражения слов swi и swj: Flsync:(swi, swj)®{0, 1}. (1) Для типов слов, обычно описывающих ССТ, характерно следующее:
где
В общем случае ядро является существительным, не имеет синтаксических зависимостей от других элементов термина, внутри фразы не зависит от подлежащего и дополнения. Следовательно, критерий
Признаки не имеют зависимых слов, поэтому являются терминальными элементами. Таким образом, критерий
Элемент термина субъект s – это в общем случае дополнение в косвенном падеже, основным признаком данного элемента является отсутствие подчиненного слова. Поэтому критерий
Дополнение, имеющее зависимость от ядра и вместе с тем другое зависимое дополнение, образует новый термин obj¢ и становится его ядром. При этом как ядро o, так и простейший элемент s могут иметь неограниченное множество признаков P. Полученные синтаксические критерии являются общими, их можно делить на составные высказывания и вводить для них систему значимости. Таким образом, уже на этапе синтаксического анализа можно найти во фразе j слова, относящиеся к множеству терминов obj, и задать их структуру. Выделяют несколько уровней значений набора слов – уровень слова, словосочетания, предложения и т.п. Поэтому эталонная система значений должна быть многоуровневой. Зададим систему значений на уровне слова и построим на ней множество необходимых для анализа уровней. Так как каждое слово sw является текстовым выражением определенного значения, зададим систему, хранящую значения sem вводимого текста. Для сопоставления множества значений и множества их текстовых выражений введем функцию получения значения текстового представления: Fsem:Sw® ®Sem. То есть, если полностью задана система значений, должно выполняться условие: "sw $sem, Fsem(sw)=sem. При этом данная функция возвращает одно наиболее вероятное значение. Реализация функции возможна, так как для составных частей терминов не так ярко выражена проблема омонимии. Причем множество Sem может описываться сложной системой значений, которая используется при оценке качества описанной таксономии, так как следует учитывать семантические связи между словами. Для оперирования различными ССТ и его частями объединим множество значений эталона в необходимую структуру. Поскольку структура эталонных знаний базируется на структуре субъективных знаний, изложенных в тексте, обобщим рекурсивную структуру ССТ: obj=áPobj, oobj, obj¢ñ. Если у термина obj есть внутренний термин obj¢ со схожей с родительским термином структурой, то он имеет собственное ядро oobj¢, но в косвенном падеже, так как подчиняется родительскому ядру oobj. У внутреннего термина также может быть свой внутренний термин obj¢¢, если же его нет, то имеется ядро s, для которого нет подчиненных слов. Таким образом, получается следующая система:
Исходя из структуры термина зададим структуру хранения терминов в эталонной базе знаний. База знаний должна содержать термины, образующие таксономическую структуру. Каждый ССТ делится на элементы, являющиеся значениями, для которых задаются возможные текстовые выражения. Подобное деление позволяет задавать отдельное семантическое значение не только для слова, но и для словосочетания и таким образом адекватно реагировать на различные названия одного и того же ССТ. Введем понятие класса терминов W, в который входят все термины с одинаковым ядром:
Так как все термины класса имеют одинаковое ядро, найденное во фразе ядро будет ассоциироваться с данным классом понятий. Следовательно, если ожидается соответствие субъективных знаний эталонным, то в первую очередь будет ожидаться связь ядра фразы с элементами ядра эталонной базы для данного класса. Выделим ряд семантических критериев, позволяющих определить местоположение термина во фразе, а также семантическую роль слова. Термин должен присутствовать в эталонной таксономии как класс понятий W, то есть являться ядром одной из семантик, причем конкретное семантическое значение определяется зависимыми элементами. Таким образом, семантический критерий для термина формулируется как
Если термин obj содержит в качестве субъекта внутренний термин obj¢, то в эталонной базе знаний должны присутствовать описания обоих терминов, причем в описание общего термина obj включена ссылка на описание внутреннего термина obj¢ как его субъекта sobj. При этом оба этих термина могут быть как из одного дерева, так и из независимых деревьев. Таким образом, семантический критерий для субъекта формулируется следующим образом:
Для подтверждения того, что значение sem слова sw является признаком Pobj некоторого термина obj, в эталонной базе знаний нужно найти множество терминов obj, к которым он принадлежит. Среди этого множества предполагается такой термин, появление которого не нарушает последовательность описания таксономии:
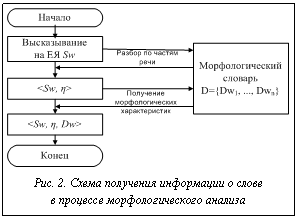
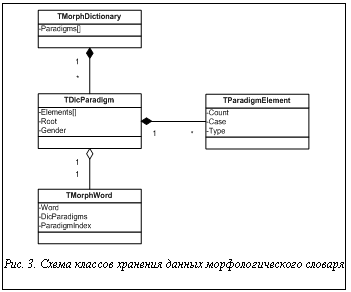
Таким образом, введено множество критериев kr, позволяющих определить семантическую роль слова, входящего в описание ССТ. Применяя критерии на этапах анализа текста, из него можно выделить термины. Построение алгоритма извлечения ССТ из текста В разработанной системе анализа выделены три блока – морфологический, синтаксический и семантический. Каждый из них отвечает за выполнение необходимых операций соответствующего этапа анализа, а также за хранение вспомогательных данных. Опишем основные особенности этапов анализа, которые определяются типом анализируемых данных. 1. Блок морфологического анализа хранит словарные данные обо всех словах анализируемой предметной области. Отсутствие слова в словаре означает отсутствие соответствующего значения в базе знаний. Для снятия неопределенности используется диалог, предлагающий или проверить слово на наличие орфографических ошибок, или ввести его синоним. Языковое описание специфичных слов предметной области ограничено, поэтому подход допустим для анализа качества классификаций данных. 2. 3. Блок семантического анализа хранит максимальное количество возможных классификаций предметной области, а также связи между выделенными смысловыми единицами в классификации с их возможным языковым представлением. Кроме этого, в данном блоке представлено разделение ССТ на составные части, что позволяет определить семантическую роль слова в предложении. В процессе анализа фразы j текстовое выражение слов сопоставляется с их морфологическими парадигмами и синонимическим рядом, после чего фраза j преобразуется во множество кортежей Sd={Sd0, …, Sdn} и Sdi=áSwj, Dek, Semlñ, где Sdi – необходимая морфологическая информация для слова Swj (рис. 2). Далее слова, входящие в состав ССТ, отделяются от слов, определяющих связи между терминами. Так как все элементы термина имеют прямую или косвенную связь с ядром, для определения границ ССТ важно найти позицию ядра в высказывании. Для блока морфологического анализа выделены следующие классы (рис. 3): - класс словообразующих парадигм TDicParadigm, хранящий множество возможных словоформ (TParadigmElement) и общие данные о слове; - класс словоформы TParadigmElement, определяющий выражение слова в тексте (Word) и основные морфологические характеристики (Count, Case, Type); - класс словаря TMorphDictionary, хранящий множество словообразующих парадигм для всех слов, описывающих предметную область; - класс слова TMorphWord со ссылкой на словарную информацию, служащий для сопоставления слов фразы с их морфологическими характеристиками. Для хранения термина в субъективной и эталонной базах знаний введены следующие классы (рис. 4): - класс термина TSemanticObject, хранящий описание ядра термина Kernel, множество признаков Features и возможный внутренний термин Subject; - Выделенные классы позволяют на этапах синтаксического и семантического анализов разложить ССТ на элементы, а также используются для хранения описания ССТ в базе знаний. При разборе текста анализируемому термину подбирается наиболее подходящий термин из базы знаний. Синтаксический анализ проходит в два этапа: на первом этапе делается попытка выделить из предложения термины, а на втором – среди нераспознанных слов осуществляется поиск описания связей между терминами (рис. 5). На этапе разбора терминов в тексте используются экземпляры класса TSemanticObject, то есть предварительная синтаксическая информация для определения семантической роли.
- класс всей базы знаний TSemanticBase; - класс одного дерева родственных терминов TSemanticTree, хранящий ссылку на корневой термин класса TSemanticObject; - класс критериального подмножества TCriterialSemantics, объединяющий родительский термин и дочерние термины по некоторому критерию.
Если в высказывании встречается лишь признак некоторого термина, а ядро, к которому он относится, не найдено, предполагается, что данное ядро уже присутствует в родительском термине этого же класса. Поэтому в процессе анализа сначала идентифицируется термин, заданный синтаксической структурой, который определяет тему (среди оставшихся объектов идентифицируются термины, раскрывающие тему), затем определяется семантическое значение оставшихся слов, предположительно, задающих связь между терминами. Как только выбраны ключевые элементы высказывания, определяется шаблон, удовлетворяющий данной семантической структуре. Далее нераспознанная часть высказывания подгоняется под выбранный шаблон. Как только заканчивается разбор высказывания, полученная структура присоединяется к общей структуре текста посредством темы. Последовательность действий распознавания таксономического высказывания следующая: - поиск и извлечение термина темы; - поиск и извлечение термина ремы; - поиск и извлечение типа связи; - поиск критерия деления; - подбор лингвистического шаблона; - подгонка неразобранных слов под шаблон. Обобщая алгоритм, можно отметить, что на синтаксическом этапе анализа делается попытка определить в высказывании границы всех ССТ и построить связи между словами, входящими в один корневой термин. При этом приоритетным вариантом анализа является случай, когда одно предложение описывает некий ССТ и ряд подчиненных терминов с указанием связи между ССТ родителя и подчиненными ССТ. Если на синтаксическом этапе анализа информации для определения границ и структуры термина недостаточно, используются дополнительные критерии, полученные на основе семантической роли термина в эталонной таксономии. В результате синтаксического анализа получаем набор терминов и слов, связывающих данные термины. Далее на основе изначально имеющихся значений отдельных слов и полученных структур связей для терминов строится субъективная таксономия, аналогичная по принципам построения структуры, но, возможно, имеющая отличия в элементах и связях таксономии. Таким образом, получаем субъективную таксономическую структуру, построенную на основе входного текста. Разработанная система извлечения знаний о классификации предметной области из текста может использоваться при оценке профессиональных знаний человека. Работа системы распознавания базируется на использовании особенностей, характерных для текста таксономического типа. Функционирование системы основано на учете сложной структуры термина, так как оценка качества описания термина требует учета семантической роли каждого слова в сложном термине. Поскольку при описании таксономий основа – это номинация элементов таксономии, важным этапом работы системы является разложение сложного термина на составные части. Кроме того, в работе рассмотрены особенности текстов, описывающих таксономическую структуру, выделены общие составные части элементов таксономии и признаки, по которым их можно найти в предложении. Также в систему заложены алгоритмы разбора, использующие выделенные структуры и критерии анализа. Литература 1. Гаврилова Т.А. Базы знаний интеллектуальных систем. СПб: Питер, 2000. 384 с. 2. Леонтьева Н.Н. Автоматическое понимание текстов: системы, модели, ресурсы. М.: Академия, 2006. 303 с. 3. Знаков В.В. Понимание в познании и общении. Самара: СамГПУ, 2000. 188 с. 4. Солсо Р.Л. Когнитивная психология. М.: Тривола, 1996. 600 с. 5. Якимов В.Н., Мошков И.С. Определение объектов и их характеристик в процессе обработки текстовой информации // Ресурсо- и энергосберегающие технологии и оборудование, экологически безопасные технологии: матер. 9-й Междунар. науч.-технич. конф. (24–26 ноября 2010 г., Минск). Минск: БГТУ, 2010. Ч. 2. С. 334–337. |

 – падеж, род и число соответственно. На основе предиката (1) можно задать предикат определения синтаксического подчинения, который позволит преобразовать упорядоченное множество слов в таксономическую структуру: Fls:( swi, swj)®{0, 1}.
– падеж, род и число соответственно. На основе предиката (1) можно задать предикат определения синтаксического подчинения, который позволит преобразовать упорядоченное множество слов в таксономическую структуру: Fls:( swi, swj)®{0, 1}.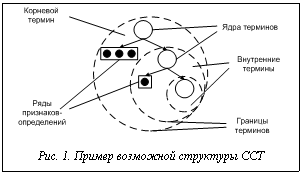 Выделенные предикаты дают возможность делать предположения о семантической роли слова, опираясь на синтаксическую информацию. Однако особенности русского языка требуют нескольких критериев определения семантической роли, в том числе на основе заданных (эталонных) значений слова и словосочетания. Для критериев при необходимости можно определять степень значимости и порог реагирования. Введем множество критериев принадлежности Kr, элементами которого являются предикаты, определяющие принадлежность слова к определенной семантической роли:
Выделенные предикаты дают возможность делать предположения о семантической роли слова, опираясь на синтаксическую информацию. Однако особенности русского языка требуют нескольких критериев определения семантической роли, в том числе на основе заданных (эталонных) значений слова и словосочетания. Для критериев при необходимости можно определять степень значимости и порог реагирования. Введем множество критериев принадлежности Kr, элементами которого являются предикаты, определяющие принадлежность слова к определенной семантической роли: 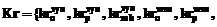
 , где
, где 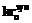 – синтаксический (полученный на основе синтаксической информации) критерий ядра термина;
– синтаксический (полученный на основе синтаксической информации) критерий ядра термина; 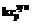 – синтаксический критерий признака;
– синтаксический критерий признака;  – синтаксический критерий субъекта;
– синтаксический критерий субъекта; 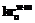 – семантический (полученный на основе значения слова в эталоне) критерий ядра термина;
– семантический (полученный на основе значения слова в эталоне) критерий ядра термина; 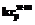 – семантический критерий признака;
– семантический критерий признака; 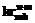 – семантический критерий субъекта.
– семантический критерий субъекта.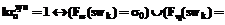
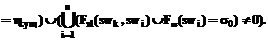
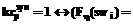
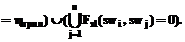
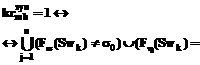
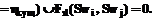
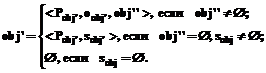
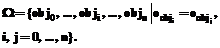
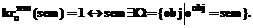
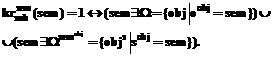
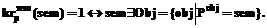
 Блок синтаксического анализа хранит его общие правила, а также специальные синтаксические критерии и шаблоны, которые позволяют выделить в тексте составные части ССТ, а также связи между ними. Данный блок взаимодействует с блоком семантического анализа, на выходе строит синтаксическое дерево с ветками, принадлежащими отдельным ССТ.
Блок синтаксического анализа хранит его общие правила, а также специальные синтаксические критерии и шаблоны, которые позволяют выделить в тексте составные части ССТ, а также связи между ними. Данный блок взаимодействует с блоком семантического анализа, на выходе строит синтаксическое дерево с ветками, принадлежащими отдельным ССТ.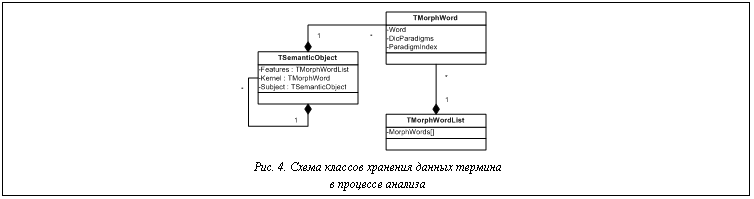
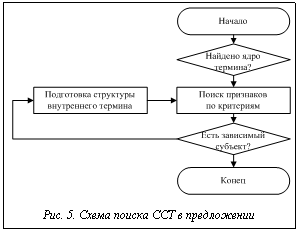 После получения синтаксической структуры начинается этап семантического анализа, на котором строится субъективная база знаний и субъективные знания соотносятся с эталонной базой знаний. Для управления знаниями и их хранения объекты, хранящие термины, организуются в таксономическую структуру эталонной базы знаний (рис. 6). Структура субъективных знаний имеет в основе такую же структуру, однако является фрагментом эталонной базы знаний. Для этого вводятся следующие классы:
После получения синтаксической структуры начинается этап семантического анализа, на котором строится субъективная база знаний и субъективные знания соотносятся с эталонной базой знаний. Для управления знаниями и их хранения объекты, хранящие термины, организуются в таксономическую структуру эталонной базы знаний (рис. 6). Структура субъективных знаний имеет в основе такую же структуру, однако является фрагментом эталонной базы знаний. Для этого вводятся следующие классы: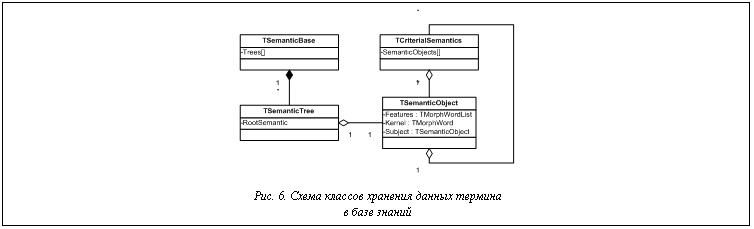
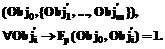
http://swsys.ru/index.php?id=2807&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics: