Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Прогнозирование обнаружения дефектов в программном обеспечении
Аннотация:Предложена модель прогнозирования обнаружения дефектов в ПО, позволяющая с достаточной точностью устанавливать подмножество компонентов системы, которое будет содержать наибольшее число дефектов при выпуске очередной версии. Приведены результаты сравнения показателей точности предложенной модели с двумя существующими моделями, из которых можно сделать вывод о ее практической ценности.
Abstract:We propose a software defect prediction model. It allows to predict defect-prone files for the next release of the system. We consider experimental results of using two defect prediction models and our model to show its practical importance.
| Авторы: Кирносенко С.И. (kirnosenko@mail.ru) - Волгоградский государственный технический университет, Лукьянов В.С. (kirnosenko@mail.ru) - Волгоградский государственный технический университет, доктор технических наук | |
| Ключевые слова: исходный код, системы контроля версий, метрики, качество, прогнозирование дефектов, дефекты |
|
| Keywords: source code, version control systems, metrics, quality, defect prediction, defects |
|
| Количество просмотров: 11841 |
Версия для печати Выпуск в формате PDF (5.05Мб) Скачать обложку в формате PDF (1.39Мб) |
Прогнозирование дефектов в ПО призвано помочь разработчикам, менеджерам и специалистам по тестированию обнаруживать и исправлять их. Существует множество моделей, которые позволяют получать прогностическую информацию о дефектах в том или ином виде. Обычно такие модели дают возможность с некоторой точностью ответить на два наиболее важных вопроса: сколько в ПО осталось необнаруженных дефектов и как они распределены между отдельными компонентами системы. Ответ на первый вопрос важен для принятия решения о завершении стадии тестирования. Ответ на второй позволяет выбрать стратегию распределения ресурсов тестирования таким образом, чтобы более тщательному тестированию подвергались компоненты, для которых наиболее высока вероятность наличия дефектов. Среди методов прогнозирования дефектов наибольшее распространение получили так называемые модели роста надежности. Они были предложены еще в 70-х годах прошлого века, поэтому накоплен большой опыт их использования как в академической, так и в промышленной сферах. Эти модели основаны на использовании функции надежности – монотонно возрастающей функции, для которой по оси абсцисс откладывается время, а по оси ординат – количество ошибок, обнаруженных к соответствующему моменту. Обычно для получения этой функции выбирается известное распределение, например экспоненциальное, и на основе предыдущего опыта и текущей информации об обнаруженных дефектах оцениваются его параметры. Используя такое распределение, можно оценить число необнаруженных дефектов. Модели роста надежности достаточно просты, но имеют серьезные недостатки. Во-первых, они основаны на предположениях, большинство из которых в реальной жизни не выполняется. Кроме того, в силу своих особенностей такие модели хорошо работают для проектов, разрабатываемых с использованием традиционных методологий, таких как «водопад», когда последовательно выполняются этапы проектирования, кодирования, тестирования и внедрения, причем возможность возврата с более поздних стадий к более ранним не подразумевается. Большинство же современных проектов разрабатывается от версии к версии, процесс разработки каждой из которых проходит относительно короткие стадии проектирования, кодирования, тестирования и внедрения. Для таких проектов использование моделей роста надежности затруднительно либо вовсе невозможно. За последние двадцать лет широкое распространение получили регрессионные модели прогнозирования дефектов. Они основаны на использовании функции регрессии, параметры которой оцениваются по множеству метрик исходного кода, измеренных в разное время. Обычно набор метрик измеряется для каждой новой версии системы. По результатам тестирования становится известно число обнаруженных дефектов. Если данных достаточно, то для очередной новой версии можно еще до начала тестирования по одним лишь метрикам оценить с приемлемой точностью количество присутствующих в ней дефектов. Но обычно результатом работы таких моделей является выборка некоторого подмножества компонентов системы, которые в соответствии с прогнозом содержат наибольшее число необнаруженных дефектов. Множество исследований ссылается на факт соблюдения принципа Парето, когда примерно 20 % компонентов системы будут со- держать примерно 80 % необнаруженных дефектов [1]. В отличие от моделей роста надежности регрессионные модели хорошо применимы к проектам с итерационным характером развития. К недостаткам таких моделей можно отнести то, что они требуют наличия множества метрик, измеренных для каждой версии системы, а число версий должно быть достаточным для оценки параметров функции регрессии. Еще одна проблема связана со снижением точности в тех случаях, когда отношение числа компонент, не содержащих дефекты, к числу дефектных компонент становится слишком большим. Недостатки существующих моделей и ограничения в их применении создают предпосылки для разработки новых моделей прогнозирования дефектов. Изложим суть предложенной вероятностной модели, которая названа так потому, что рассматривает процесс написания исходного кода как множество независимых испытаний. Пусть написание отдельной строки исходного кода является независимым испытанием с известной вероятностью успеха p и вероятностью неудачи q=1–p. Успехом считается написание строки кода, не содержащей дефектов, а неудачей – написание строки кода с дефектом. Тогда вероятность того, что N строк кода содержат дефекты, можно вычислить как вероятность нахождения в этом объеме исходного кода хотя бы одной дефектной строки: P(E1)=1–(1–q)N, где E1 – событие, состоящее в наличии дефектов в исходном коде объемом N строк, причиной которых является естественная плотность ошибок как следствие неизбежных ошибок кодирования. Дефекты обычно не проявляются сразу. На их обнаружение уходит время, в течение которого ПО используется по назначению. Ряд публикаций указывает на то, что каждому дефекту можно поставить в соответствие некий период времени эксплуатации, который должен пройти до его обнаружения [2]. Те дефекты, для которых этот период меньше, будут обнаружены и исправлены раньше. Как подтверждение этого факта можно рассматривать и модели роста надежности. На основе используемой ими функции надежности можно получить распределение вероятности обнаружения всех дефектов. Возьмем экспоненциальную модель роста надежности. Она задается следующим уравнением: µ(t) Предметом споров является наличие связи между уже исправленными дефектами и дефектами, которые проявят себя в будущем. Одни считают, что если в коде обнаружены дефекты, то этот код сложен или часто модифицируется, а значит, в ближайшем будущем в нем вновь обнаружатся дефекты. Другие исходят из следующего: если в коде обнаружены и исправлены дефекты, то надежность этого кода увеличивается, а вероятность обнаружить в нем еще дефекты уменьшается. Существует ряд научных публикаций в пользу обеих гипотез. Для предложенной модели придерживаемся второй гипотезы, то есть примем, что с увеличением числа исправлений в коде вероятность обнаружить в нем новые дефекты уменьшается. Наличие ранее внесенных в исходный код исправлений означает, что из добавленных N строк кода было удалено NE дефектных строк. Тогда наличие большего числа дефектов означает, что в исходном коде содержится некоторое число дефектных строк кода ND, большее чем NE. Естественно, ND не может быть больше N. А учитывая, что исходный код может быть удален в результате не только исправления дефектов, но и рефакторинга, число ND не может быть больше числа N–NR, где NR – число строк кода, удаленных в результате рефакторинга из исходного кода с начальным объемом N строк. Следовательно, вероятность наличия дефектов в исходном коде, для которого ранее уже вносились исправления, может быть подсчитана как вероятность того, что число ND окажется больше числа NE и не больше числа N–NR. Данную вероятность можно вычислить, воспользовавшись интегральной теоремой Лапласа, при условии, что события E1 и E2 наступи- ли: В итоге вероятность наличия дефектов в исходном коде объемом N строк и возраста T, для которого ранее было удалено NE строк в результате исправления дефектов и NR строк в результате рефакторинга, находится по следующей формуле: P(E)=P(E1)P(E2)P(E3), где E – событие, заключающееся в одновременном наступлении событий E1, E2 и E3. Это событие наступает, если в коде есть дефекты, прошло достаточно времени для того, чтобы эти дефекты были обнаружены, и они не были исправлены ранее. Для применения предложенной модели необходимо знать вероятность внесения дефектов при написании отдельной строки исходного кода q и интенсивность отказов λ. Вероятность внесения дефектов можно оценить, зная общее число написанных строк исходного кода и число строк, оказавшихся дефектными. Тогда отношение второго к первому есть статистическая оценка искомой вероятности. Интенсивность отказов при применении моделей роста надежности оценивается исходя из имеющихся данных об отказах: времени между последовательными отказами, информации о количестве установленных копий системы и вычислительной мощности применяемого оборудования. Для ПО, свободно распространяемого и массово используемого на тысячах компьютеров по всему миру, подобный подход неприменим. Однако, если бы можно было экспериментально получить распределение вероятности обнаружения дефектов, на его основе возможна была бы оценка интенсивности отказов. Пусть к некоторому моменту времени в системе обнаружено некоторое число дефектов. Для каждого отдельного дефекта определим время жизни, то есть период, прошедший с момента внесения ошибочного кода до момента его исправления. Для поиска ошибочного кода воспользуемся методом поиска исправляющих ревизий в системе контроля версий [3]. Далее можно построить график, откладывая по оси абсцисс время, а по оси ординат количество дефектов, время жизни которых оказалось не больше соответствующего времени. Таким образом получаем распределение вероятности обнаружения дефектов, являющееся аналогом функции надежности модели роста надежности и позволяющее оценить неизвестную интенсивность отказов, воспользовавшись, например, методом наименьших квадратов. Для проверки точности прогнозирования предложенной модели и ее сравнения с другими моделями был проведен эксперимент, в ходе которого использовались три модели прогнозирования обнаружения дефектов. Первая модель, обозначаемая M1, является регрессионной. Модель использует логистическую регрессию, для оценки параметров которой выполняются измерения единственной метрики, а именно числа строк исходного кода, для каждого компонента каждой версии системы. Вторая модель, обозначаемая M2, тоже является регрессионной и использует логистическую регрессию, но для оценки параметров регрессии применяет набор метрик, в который входят число строк кода, число строк кода, добавленных в новой версии, число строк кода, удаленных в новой версии, число модификаций исходного кода с момента выпуска предыдущей версии, плотность ошибок. Третья модель, обозначаемая M3, является реализацией предложенной вероятностной модели. Выбор моделей для сравнения обусловлен следующими факторами. Модели роста надежности не рассматриваются. Как отмечено выше, их применение к одним и тем же данным вместе с регрессионными моделями проблематично ввиду того, что регрессионные модели работают с данными по отдельным версиям, тогда как модели роста надежности для работы с такими данными не предназначены. Обе регрессионные модели используют логистическую регрессию, но разные множества метрик, что оправдано, так как существующие исследования отмечают отсутствие значительного влияния выбора конкретной регрессии на результирующую точность, а рост множества метрик способствует повышению точности лишь при относительно небольшой размерности такого множества [4]. В качестве данных для расчета были использованы репозитории исходного кода двух проектов – gnome-terminal (терминальная консоль окружения GNOME) и dia (программа построения UML и других видов диаграмм). Это проекты с открытым исходным кодом, и используемые репозитории могут быть получены через сеть Интернет (http://svn.gnome.org/). Методика эксперимента заключалась в следующем. Весь период имеющейся в репозитории истории проекта разбивался на две равные части. Из первой части выбирались отдельные версии, чтобы рассматривались только те, по которым накоплено достаточно истории. Далее версии объединялись в множества, каждое из них состояло из пяти последовательных версий. Для регрессионных моделей для каждой из четырех первых версий в множестве выполнялось измерение метрик и на их основе оценивались параметры регрессии. Для пятой версии в множестве выполнялось прогнозирование наличия дефектов в отдельных компонентах, после чего рассчитывалась точность. Предложенная вероятностная модель не оперирует метриками для отдельных версий, она использовала всю информацию по первым четырем версиям множества для оценки параметров. Аналогично моделям M1 и M2 модель M3 использовала последнюю в рабочем множестве версию для прогнозирования дефектов и анализа точности. Результаты эксперимента приведены в таблице.
Для сравнения точности прогнозирования использовались метрики Precision (P) и Recall (R), основанные на понятии ошибок первого и второго рода [5]. Метрику Precision можно трактовать как долю выборки, составленную дефектными модулями, а метрику Recall – как долю дефектных модулей, попавших в выборку. В идеале обе эти метрики должны быть равны единице. На деле прогноз, для которого обе эти метрики оказываются не меньше 0,7, считается очень хорошим. Метрика Neg/Pos представляет отношение количества недефектных компонентов системы к дефектным. Из результатов видно, что предложенная модель прогнозирует дефектные компоненты системы с большей точностью, чем это делают две рассмотренные регрессионные модели. Кроме того, следует отметить, что при растущих значениях метрики Neg/Pos наблюдается падение точности регрессионных моделей, в то время как предложенная вероятностная модель демонстрирует относительно стабильные показатели точности и даже некоторый их рост для большей метрики Neg/Pos. Рассмотренная вероятностная модель прогнозирования дефектов на двух исследованных множествах данных демонстрирует хорошие показатели точности. Кроме того, точность модели не падает при увеличении значений метрики Neg/Pos, что наблюдается практически для всех регрессионных моделей. Следует отметить, что предложенная модель не требует измерения метрик для конкретных версий системы, как и на- личия этих версий в истории. Однако модель использует данные о плотности ошибок и распределении времени жизни ошибок, что делает возможным ее применение только в тех случаях, когда накоплено достаточно истории об изменениях исходного кода. Впрочем, это свойственно практически всем моделям прогнозирования дефектов и не может считаться недостатком. В дальнейшем авторам предстоит изучить результаты применения модели к другим множествам данных, дабы убедиться в том, что полученные результаты неслучайны. Кроме того, планируется совершенствование модели, которое позволит улучшить показатели точности. Для этого имеется целый ряд потенциальных направлений работы, прежде всего связанных с выборкой множеств исходного кода, которые используются для оценки параметров модели. Все операции по извлечению необходимых данных из систем контроля версий и по подсчету метрик выполнены с помощью специально разработанного в рамках данного исследования ПО MSR Tools (http://msr.sourceforge.net). Литература 1. Fault detection and prediction in an open-source software project / M. English [et. al.] // PROMISE ’09: Proceedings of the 5th International Conference on Predictor Models in Software Engineering. NY, USA: ACM, 2009, pp. 1–11. 2. Bell R.M., Ostrand T.J., Weyuker E.J. Looking for bugs in all the right places // Proceedings of the 2006 international symposium on Software testing and analysis. ISSTA’06. NY, USA: ACM, 2006, pp. 61–72. 3. Кирносенко С.И., Лукьянов В.С. Идентификация исправляющих ревизий в системах контроля версий // Изв. ВолгГТУ: сер. Актуальные проблемы управления, вычислительной техники и информатики в технических системах. ВолгГТУ. Волгоград, 2010. Вып. 9. № 11. C. 146–149. 4. Benchmarking classification models for software defect prediction: A proposed framework and novel findings / S. Lessmann [et. al.] // IEEE Trans. Softw. Eng. 2008. July. Vol. 34, pp. 485–496. 5. Problems with Precision: A Response to «Comments on 'Data Mining Static Code Attributes to Learn Defect Predictors'» / T. Menzies [et. al.] // IEEE Transactions on Software Engineering. 2007. Vol. 33, pp. 637–640. |
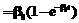 , где µ(t) – математическое ожидание числа дефектов, обнаруженных к моменту t; β0 – начальная оценка общего числа дефектов в системе; β1 – интенсивность отказов. Если обе части уравнения разделить на β0, получим распределение вероятности обнаружения всех дефектов:
, где µ(t) – математическое ожидание числа дефектов, обнаруженных к моменту t; β0 – начальная оценка общего числа дефектов в системе; β1 – интенсивность отказов. Если обе части уравнения разделить на β0, получим распределение вероятности обнаружения всех дефектов: 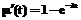 , где µ'(t) – математическое ожидание отношения числа дефектов, обнаруженных к моменту t, к общему числу дефектов; λ – интенсивность отказов. Будем считать возрастом строки исходного кода период времени, прошедший с момента добавления строки до текущего момента. Тогда для N строк кода, возраст которых равен T, вероятность обнаружения имеющихся в этом коде дефектов (при условии, что событие E1 наступило) равна: P(E2)=µ¢(T), где E2 – событие, состоящее в обнаружении имеющихся дефектов в исходном коде объемом N строк и возраста T, причина которого в достаточно долгом периоде эксплуатации кода и как следствие – в достаточно высокой вероятности проявления дефектов за это время.
, где µ'(t) – математическое ожидание отношения числа дефектов, обнаруженных к моменту t, к общему числу дефектов; λ – интенсивность отказов. Будем считать возрастом строки исходного кода период времени, прошедший с момента добавления строки до текущего момента. Тогда для N строк кода, возраст которых равен T, вероятность обнаружения имеющихся в этом коде дефектов (при условии, что событие E1 наступило) равна: P(E2)=µ¢(T), где E2 – событие, состоящее в обнаружении имеющихся дефектов в исходном коде объемом N строк и возраста T, причина которого в достаточно долгом периоде эксплуатации кода и как следствие – в достаточно высокой вероятности проявления дефектов за это время.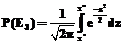 , где
, где 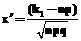 ,
, 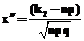 , k1=NE+1, k2=N–NR, n=N, E3 – событие, состоящее в том, что обнаруженные в исходном коде дефекты не были исправлены ранее.
, k1=NE+1, k2=N–NR, n=N, E3 – событие, состоящее в том, что обнаруженные в исходном коде дефекты не были исправлены ранее.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2815&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.05Мб) Скачать обложку в формате PDF (1.39Мб) |
| Статья опубликована в выпуске журнала № 3 за 2011 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Генератор текста программ в исходном виде для систем реального времени
- Оценка состояния безопасности интернет-сайтов как плохо формализуемых объектов на основе методов нечеткой логики
- Оценка качества тренажерных средств
- Автоматизированная система оценки качества электронных курсов
- Программное обеспечение для диагностики дефектов в прокатных валках
Назад, к списку статей