Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Модуль для полуавтоматического извлечения и обработки данных в области нанокомпозитов
Аннотация:В данной работе предпринята попытка создания базы данных по свойствам нанокомпозитов. Проведена класси-фикация нанокомпозитов по матрице и наполнителю. Создан модуль единого поиска статей в научных журналах, а также модуль полуавтоматического извлечения фактов, который значительно ускорил процесс наполнения базы ин-формацией, автоматизировав его.
Abstract:Recently sharp jump of publications in area nanocomposites is observed. But all information is not structured, there is no general database on properties of these materials. In the given work attempt of creation to such base has been undertaken. Authors classifications nanocomposites on a matrix and fillers is spent. The module of uniform search of articles in scientific journals and as the module of semi-automatic extraction of the facts which has considerably accelerated process of filling of base by the information, having automated it is created.
| Авторы: Митрофанов И.В. (kolts@muctr.ru) - Российский химико-технологический университет им. Д.И. Менделеева, г. Москва, Краснов А.А. (kolts@muctr.ru) - Российский химико-технологический университет им. Д.И. Менделеева, г. Москва, Порысева Е.А. (kolts@muctr.ru) - Российский химико-технологический университет им. Д.И. Менделеева, г. Москва, Кольцова Э.М. (kolts@muctr.ru) - Российский химико-технологический университет им. Д.И. Менделеева (профессор), Москва, Россия, доктор технических наук | |
| Ключевые слова: обработка информации, метод опорных векторов, нанокомпозиты |
|
| Keywords: information processing, support vector machines, nanocomposite |
|
| Количество просмотров: 14605 |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
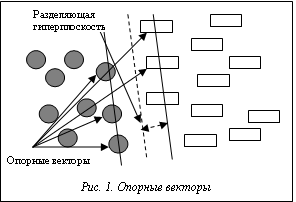
Нанотехнологическая отрасль сегодня в числе наиболее динамично развивающихся. Оцениваемый объем мирового рынка наноматериалов и технологий их получения в 2009 году составил 10,1 млрд долл. США. Одним из основных продуктов этой отрасли являются нанокомпозиты, позволяющие значительно (в отдельных случаях на несколько порядков) улучшать свойства обычных композитов благодаря применению наночастиц. Согласно прогнозам, мировой рынок нанокомпозитов до 2015 года ежегодно будет расти в среднем на 25 % в натуральном выражении и почти на столько же в стоимостном (снижение темпов произойдет ближе к 2014–2015 годам, причем почти на 10 % ежегодно) [1]. Активное развитие нанотехнологий и, как следствие, информационный бум в этой области привели к появлению в 1990–2010 гг. около 300 тысяч публикаций, посвященных нанокомпозитам, более чем в 120 странах мира. Поэтому создание информационной системы, в которой были бы отражены основные свойства нанокомпозитов, их классификация, методики исследования, способы получения и применения, на данном этапе развития технологий является важной задачей. Ее успешное решение позволит исследователям и производителям выбирать оптимальные критерии при получении или применении композиционных наноматериалов, ускорить разработку, учитывая опыт своих коллег. Цель данной работы – упростить поиск и обработку информации. Для этого был создан единый модуль, с помощью которого можно находить статьи для уже имеющейся БД по нанокомпозитам, а также реализовать возможность полуавтоматического извлечения информации. При разработке модуля руководствовались следующими критериями: высокая скорость разработки, дружелюбный интерфейс, легкая поддержка и доработка программы в будущем. Основой разработанной системы NanoClassificator стала реализация БД свойств по нанокомпозитам в виде «вопрос–ответ». То есть имеется набор вопросов (количество которых постоянно растет, что позволяет более полно отражать основные свойства и характеристики нанокомпозитов), разделенных по группам (например, физико-химические свойства, механические свойства, оптические свойства, методы получения и др.), и найденные в статьях ответы на них. Для удобства хранения обработанной ин- формации необходимо было ее структурировать: для этого разработана несложная и достаточно общая классификация по наполнителям и мат- рицам, делящая их в общем случае на металлические и неметаллические с последующей детализацией. Кроме создания структуры системы, необходимо было решить и вопрос ее заполнения: очевидно, что, имея такое количество статей, следует автоматизировать процесс сбора и обработки информации. Задачи автоматической классификации текстов и извлечения фактов являются сегодня одними из наиболее актуальных в таких областях, как Text mining и Data mining. Поэтому авторами были разработаны модуль единого поиска информации по существующим сетевым ресурсам, а также модуль полуавтоматического извлечения необходимой информации из отечественных и зарубежных статей, посвященных нанотехнологии и наноиндустрии. При разработке модуля автоматической классификации использован метод опорных векто- ров [2], применяемый при решении задач распознавания образов, управления, прогнозирования и др. Кроме того, метод показывает высокие результаты на тестах и относится к категории методов «Обучение с учителем» (как и нейронные сети), то есть для его работы нужна начальная выборка информации для обучения. Геометрически суть этого метода сводится к поиску оптимальной разделяющей гиперплоскости и нахождению максимального зазора между этой гиперплоскостью и опорными векторами, как это показано на рисунке 1. Гиперплоскость является разделяющей прямой, опорные векторы лежат на двух параллельных ей прямых. Алгебраически это задача квадратичного программирования. Метод опорных векторов позволяет: - получить функцию классификации с минимальной верхней оценкой ожидаемого риска; - использовать линейный классификатор для работы с нелинейно разделяемыми данными, сочетая простоту с эффективностью. Правильный выбор программных средств реализации модуля является залогом успеха. Выбор был сделан в пользу связки Java + MySQL. Основные причины такого решения: высокая скорость разработки, низкая вероятность допущения критических ошибок, сравнимая с С++ по скорости работы приложений. При разработке модуля использовалась бесплатная IDE Netbeans v6.8. Использованные библиотеки: - для разработки интерфейса – фреймворк Spring, лицензия Apache License, v2.0 (совместима с GPLv3); - для реализации SQL-запросов к БД – Mysql Connector, лицензия GPL License v3; - для работы с html-кодом страниц – библиотека Jsoup, лицензия MIT License. Все библиотеки распространяются под открытыми для распространения и разработки лицензиями. Прежде чем классифицировать текст, необходимо подготовить статью, преобразовав ее в специальную модель. Первым этапом такого преобразования является нормализация. Вначале следует убрать все стоп-слова – предлоги, союзы и другие часто встречаемые слова. Затем необходимо извлечь корни из слов по алгоритму Портера, таким образом выделяется суть статьи. Далее нужно избавиться от шума: убрать все числа, привести статью к единому регистру, убрать знаки препинания.
Извлечение из статьи фактов и необходимой для базы информации происходит на основе анализа структуры html-документа. Обработка кода html-страниц с результатами поиска и со статьями производилась с помощью библиотеки Jsoup. Все обработанные html-страницы находятся в папке для хранения временных файлов модуля. Таким образом, в случае повторения поисковых запросов в течение одного сеанса работы с модулем будут обработаны страницы, находящиеся в папке для временных файлов. Так же применялся алгоритм, основанный на регулярных выражениях и поиске ключевых слов, которые были привязаны к вопросам в разработанной БД. Модуль автоматически ищет в выбранной статье необходимые авторам для заполнения созданной БД ответы на вопросы. Полученные после применения такого подхода результаты пользователю необходимо или подтвердить, или опровергнуть, или изменить, только после этого информация заносится в созданную БД. Модуль разработан таким образом, что вся обработанная информация (значимые слова, корни слов, коэффициенты TF*IDF), а также ответы на вопросы и классификация хранятся в БД для промежуточной информации (рис. 2). Это сделано для того, чтобы обеспечить более детальный анализ статей в дальнейшем (без необходимости обработки статей каждый раз, когда происходит модернизация модуля), а также для реализации качественной поисковой системы. На рисунке 2 показана инфологическая модель используемой структуры БД. Эти таблицы созданы в дополнение к уже имеющимся в БД по нанокомпозитам. Таблица words_all содержит все значимые в статьях слова; в words_stem находятся только корни слов; feature – это таблица свойств метода опорных векторов для каждой статьи, а таблицы category_matrix, category_nap, composite, matrix, nap, classification отвечают за классификацию статей по матрицам и наполнителям. Кроме того, в модуль внедрен единый поиск статей, который использует поисковые механизмы научных журналов, представленных, например, в коллекции электронных журналов на платформе Sciencedirect, обрабатывает результаты (анализируя html-структуру полученной страницы) и выводит на экран пользователя только необходимую для дальнейшей работы информацию. Пользователю больше не нужно посещать сайты научных журналов, чтобы найти статьи. Достаточно воспользоваться поиском, который предлагает модуль. Кроме того, в модуле создан менеджер загрузок, предназначенный для загрузки и сохранения pdf-файлов статей на жесткий диск пользователя. Для работы программы необходимо скопировать папку NanoClassificator на жесткий диск пользователя. Программа запускается приложением Classificator.jar. Это клиентское приложение, обеспечивающее связь с сервером БД, а также реализующее поиск по сайтам научных журналов. Входных данных при запуске программы нет. Все выходные данные (название статьи, авторы, дата публикации, ссылка на страницу статьи, а также извлеченная информация по свойствам нанокомпозита) проанализированной статьи записываются в БД на сервере. Для оценки качества работы используемой программы метода SVM был проведен специальный тест с применением программы SVM-light.
Было проведено обучение программы с помощью статей Reuters и коллекции имеющихся документов на основе 1 000 позитивных и 1 000 отрицательных примеров и произведена проверка на 600 тестах. В результате работы программы точность классификации составила 97,67 %. Условия, необходимые для работы программы: - персональный компьютер с процессором Intel Pentium III (и выше) или аналогичный; - ОЗУ не менее 512 Мб; - доступ в Интернет; - свободное место на жестком диске не менее 1 Гб для хранения временных файлов и статей в формате pdf; - ПО Java, которое бесплатно доступно для установки (http://www.java.com/ru/); - операционная система, поддерживающая технологию Java. Для работы программы необходим хороший канал доступа в Интернет, так как поиск происходит по сайтам научных журналов в online-режиме. Программа работает стабильно, во время тестирования никаких сбоев не наблюдалось. Средства самовосстановления не предусмотрены. Благодаря разработанным модулям процесс обработки и поиска статей стал значительно проще. Раньше на обработку статьи в ручном режиме требовалось от 4 часов и более: необходимо было перевести статью, найти необходимую информацию и после этого перенести найденные факты в БД. За год таким образом было обработано около 300 статей. Сейчас для обработки одной статьи требуется от 5 до 20 минут в зависимости от ее сложности. За две недели практического применения разработанных модулей было обработано 150 статей. Таким образом, благодаря разработанным модулям полуавтоматического извлечения фактов и классификации процесс заполнения БД по нанокомпозитам ускорен в несколько раз. Главным образом разработан модуль автоматического анализа текста и извлечения необходимой информации из него, что значительно облегчило такой длительный и трудоемкий процесс, как наполнение созданной БД информацией. Информационный и научно-прикладной характер разработанной системы позволяет использовать ее в научно-исследовательских работах (для получения данных о структуре, строении, физико-механических и химических показателях веществ), в учебно-образовательном процессе, а также в производственной деятельности для извлечения информации о качественном и количественном улучшении свойств композитных материалов, при введении в их матрицу различных армирующих наполнителей. Литература 1. Исследовательская компания «Abercade». Маркетинговый отчет «Мировой рынок полимерных нанокомпозитов в 2003–2009 годах». 2010. 134 с. http://www.abercade.ru/research/ reports/3829.html. 2. Burges C.J.C. A tutorial on support vector machines for pattern recognition // Data Mining and Knowledge Discovery. Vol. 2. 1998. 988 p. |
 Следующий этап преобразования – применение так называемой модели TF*IDF к нормализованной статье. TF – отношение количества раз, которое слово t встретилось в документе d, к длине документа. Нормализация длиной документа нужна, чтобы уравнять в правах короткие и длинные (в которых абсолютная встречаемость слов может быть гораздо больше) документы. IDF – логарифм отношения общего числа документов к числу документов, содержащих слово t. Таким образом, для слов, которые встречаются в большом числе документов, IDF будет близок к нулю (если слово встречается во всех документах, IDF равен нулю), что помогает выделить наиболее важные слова. Коэффициент TF*IDF равен произведению TF и IDF; TF играет роль повышающего множителя, IDF – понижающего. Соответственно, вместо простой частоты встречаемости элементами векторов-документов будут значения TF*IDF. Во многих задачах (но не во всех) это позволяет заметно улучшить качество. Полученная в итоге модель представляет собой вектор номеров слов и значений коэффициента TF*IDF.
Следующий этап преобразования – применение так называемой модели TF*IDF к нормализованной статье. TF – отношение количества раз, которое слово t встретилось в документе d, к длине документа. Нормализация длиной документа нужна, чтобы уравнять в правах короткие и длинные (в которых абсолютная встречаемость слов может быть гораздо больше) документы. IDF – логарифм отношения общего числа документов к числу документов, содержащих слово t. Таким образом, для слов, которые встречаются в большом числе документов, IDF будет близок к нулю (если слово встречается во всех документах, IDF равен нулю), что помогает выделить наиболее важные слова. Коэффициент TF*IDF равен произведению TF и IDF; TF играет роль повышающего множителя, IDF – понижающего. Соответственно, вместо простой частоты встречаемости элементами векторов-документов будут значения TF*IDF. Во многих задачах (но не во всех) это позволяет заметно улучшить качество. Полученная в итоге модель представляет собой вектор номеров слов и значений коэффициента TF*IDF.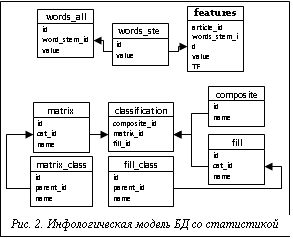 Документы, которые необходимо было классифицировать, представлены в виде характеристических векторов (в результате обработки статей по модели TF*IDF). Каждая характеристика соответствовала основе слова (9947 характеристик).
Документы, которые необходимо было классифицировать, представлены в виде характеристических векторов (в результате обработки статей по модели TF*IDF). Каждая характеристика соответствовала основе слова (9947 характеристик).| Постоянный адрес статьи: http://swsys.ru/index.php?id=2919&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2011 год. [ на стр. 82 – 85 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Программная система для исследования характеристик сетей обработки информации
- Алгоритмы автоматизированной системы управления испытанием оборудования на надежность
- Комбинированный метод автоматического определения тональности текста
- Программное обеспечение и алгоритмы обработки информации при калибровке термометров сопротивления
- Параллельная система автоматической текстовой классификации
Назад, к списку статей