Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Синтез синтаксисов в создании специализированных языков программирования
Аннотация:Рассматривается метод синтеза синтаксиса языков программирования как специализированных средств описания заданной предметной области.
Abstract:Syntax synthesis method of programming languages is considered as specialised tools to descript defined application domain.
| Авторы: Никифоров А.Ю. (netlab@rambler.ru) - Национальный исследовательский ядерный университет «МИФИ», г. Москва, Русаков В.А. (var41@mail.ru) - Национальный исследовательский ядерный университет «МИФИ», г. Москва, кандидат технических наук | |
| Ключевые слова: специализированные искусственные языки, технология разработки, языки программирования, синтаксис |
|
| Keywords: specialized artificial languages, development technology, programming languages, syntax |
|
| Количество просмотров: 11369 |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
Синтаксис является неотъемлемой частью любого языка. Без его знания невозможно правильно построить фразу. Согласно ряду лингвистических теорий, существует универсальная грамматика, присущая каждому человеческому языку. При этом она понимается как знание о языке, встроенное на генетическом уровне [1]. Для искусственных языков, используемых в ходе последующей компьютерной обработки, наличие строгого описания синтаксиса является основой построения программных систем. Практика показала, что отсутствие строгих синтаксических правил у естественных языков приводит к существенным трудностям при попытках их использования для решения конкретных прикладных задач. Формируемым описаниям обычно присущи неполнота, неоднозначность, а также недостаточность формальных оснований для последующего анализа свойств объектов. Данное обстоятельство служило и служит мощным стимулом появления искусственных языков. При этом специализация средств описания позволяет значительно снизить сложность создаваемых языков. При возникновении новых потребностей человека разрабатываются новые рукотворные системы и новые средства поддержки их разработки, включая языки программирования. В силу понятийного отрыва универсальных языков от конкретных предметных областей у специалистов в этих областях мотивация к изучению и последующему применению таких языков чрезвычайно слаба. Естественным средством повышения привлекательности средств описания является разработка новых специализированных языков, максимально простых и приближенных к задаваемым предметным областям. Объединенные усилия специалистов в конкретной предметной области и теории построения языков дают возможность таких выделения и группировки понятий этой области при адекватном семантическом наполнении соответствующих языковых конструкций, что вся совокупность подобных групп понятий полностью содержательно покрывает данную предметную область. Разумеется, наилучшим вариантом описанного объединения усилий является их воплощение в одном лице. В настоящее время широчайшее применение разного рода моделей не такая уж редкость. За меру удаленности, приводящей к включению в разные группы, может быть принята ориентировочная семантическая независимость понятий. Поэтому, выбрав по представителю в каждой из таких групп, можно сформировать семантический базис предметной области. Это означает, что язык с конструкциями, нагруженными семантикой такого базиса, и представляемый совокупностью программ на нем, в состоянии полностью передать семантику заданной предметной области. Такой язык естественно назвать допустимым для этой области, а его синтаксис и соответствующую грамматику – допустимыми синтаксисом и грамматикой. Переход к другому семантическому базису с другими представителями групп означает выбор другого языка для данной предметной области также с допустимым синтаксисом. В итоге при последующем введении дополнительной меры, например, так или иначе понимаемой сложности языка, появляется возможность выбора допустимого языка на ее основе. Интересным и важным вопросом, примыкающим к рассматриваемым эвристическим построениям, является вопрос о действительной алгоритмической полноте создаваемого языка, полноте в рамках задаваемой предметной области. Прежде рассмотрим допустимость в терминах грамматик. На рисунке 1 Ga – множество грамматик произвольно широкой предметной области; Gp – множество грамматик конкретной предметной области; Gb – допустимая грамматика, отобранная для языка ее описания. Граница между Ga и Gb может быть существенно размытой, что на рисунке 1 изображено заштрихованной зоной. Такая размытость обусловлена двумя обстоятельствами. Во-первых, применимостью многих языковых конструкций, формирующих семантические базисы данной предметной области, в целом ряде других языков, ориентированных на другие области. Во-вторых, эвристическим характером формирования групп понятий. С другой стороны, определенная предметная область на деле может быть весьма обширной и близкой в этом смысле предельно широкой области, соответствующей Ga. Учет факторов обеих этих сторон объясняет возможный и нередкий на практике случай алгоритмической полноты языка с грамматикой, синтезированной для конкретной предметной области. Формально задача синтеза состоит в построении процедурного языка, удовлетворяющего заданным требованиям, то есть ограничениям допустимости, и имеющего при этом наименьшую сложность. Другими словами, на множестве допустимых решений требуется отыскать контекстно-свободную грамматику G=(N, T, S, P), на которой достигается минимум коэффициента синтаксической сложности СС= 1. Формирование целевой функции. Эксперт должен выбрать метрики, формирующие целевую функцию, и оценить весовые коэффициенты. 2. Формирование множества допустимых грамматик. Эксперт выделяет базовую компоненту, которая входит во все грамматики, описывающие предметную область. Обозначим ее Gb=(Nb, Tb, S, Pb), где Nb – множество нетерминальных символов; Tb – множество терминальных символов; S – начальный символ; Pb – продукции. Основываясь на понятиях предметной области, эксперт разбивает возможные описания предметной области на n групп (например, группа управления потоком команд, манипуляций с данными определенного типа), в каждой i-й группе создается набор возможных решений из ki компонент. Каждая компонента состоит из множеств Nij – нетерминальных символов, Tij – терминальных символов, Pij – продукций. Допустимая грамматика состоит из базовой компоненты Gb и по одной из компонент из каждой группы, то есть Gдоп=(Nдоп, Tдоп, S, Pдоп), где 3. Нахождение на множестве допустимых решений грамматики, на которой достигается минимум коэффициента синтаксической сложности. В силу ресурсоемкости полного перебора для нахождения решения можно воспользоваться различными эмпирическими методами, например, управляемым на основе метода размытых эвристик просмотром множества допустимых грамматик с подсчетом значений сформированной целевой функции [2].
В связи с этим при разработке лабораторного практикума была поставлена двуединая задача: добиваться формирования у обучаемого взгляда на архитектуру ВОС как на нечто единое целое, все части которого подчинены общим принципам и взаимодействуют согласованно, где нет ничего лишнего, и в то же время показывать конкретные механизмы, их варианты в различных сочетаниях, смысл и практическое значение применения таких механизмов, то есть показывать «кухню» обеспечения взаимосвязи. Из-за ограниченности времени на освоение курса потребовалось разработать простой язык упорядоченного описания взаимодействия систем для использования в лабораторном практикуме по курсу ВОС, что и было сделано на основе представленного метода. Анализ широко известных языков, таких как Estelle, LOTOS, SDL, позволил выделить основные требования к языку. Он должен быть, во-первых, пригодным для формального описания статики и динамики компонентов архитектуры упорядоченного взаимодействия систем, во-вторых, инвариантным относительно существующих архитектур взаимосвязи. Для описания статики компонентов архитектуры упорядоченного взаимодействия систем (см. рис. 2) необходимо описать взаимное расположение объектов, возможные взаимодействия объектов и их параметры, возможные внутренние состояния объектов. Взаимное расположение объектов для большей наглядности описывается в явном виде при задании разделения по уровням иерархии. Возможные взаимодействия также заданы явно в виде списка всех возможных входных событий. Внутренние состояния описываются пользователем с помощью набора переменных. Для представления динамики компонентов архитектуры упорядоченного взаимодействия систем необходимо описать реакцию взаимодействия объектов: изменение внутренних состояний, инициацию взаимодействий. Разработанный язык основан на расширенном конечном детерминированном автомате. Хотя некоторые языки описания, например Estelle, дают возможность недетерминизма переходов, для упрощения решено остановиться на детерминированном автомате. Каждый переход является атомарным действием, происходит либо при взаимодействии объектов с выше- и нижележащими уровнями, либо при взаимодействии внутри уровня. Описываемая архитектура основывается на слабосвязанных модулях – уровнях систем, взаимодействующих через точки доступа (ТД) (см. рис. 2), с описанием примитивов взаимодействия и типов их параметров, а также событий, вызываемых по таймеру [3]. Так как переходы по таймеру с точки зрения автомата не отличаются от переходов по входным примитивам взаимодействия, их описание единообразно. При создании языка использовался вышеописанный метод. В таблице 1 приведены выделенные группы языка. Таблица 1 Выделенные семантические группы языка упорядоченного описания взаимодействия систем
Таблица 2 Оценка синтаксической сложности различных языков
Возможный путь решения этой проблемы следующий. Группа экспертов выделяет атомарные элементы искомой предметной области. Сложность программ на разрабатываемом языке будет обратно пропорциональна сложности его операторов, которую можно оценить традиционными метриками программирования на основе описания этих операторов через атомарные элементы предметной области. Подходящее усреднение сложности отдельных операторов и будет являться коэффициентом семантической простоты языка. В будущем неизбежны появление, развитие и отмирание специализированных языков для специалистов в конкретных предметных областях. Такие языки могут и должны создаваться под их нужды. При создании языка следует использовать метрики, позволяющие выбрать более простой в обучении и использовании вариант языка. Литература 1. Hauser M.D., Chomsky N., Fitch W.T. The Faculty of Language: What Is It, Who Has It, and How Did It Evolve? / Science. AAAS/ 2002. Vol. 298, pp. 1569–1579. 2. Самойленко С.И., Агаян А.А. Методы поиска решений / В кн.: Проблемы случайного поиска. Рига: Зинатне, 1980. Вып. 8. С. 15–62. (Вопросы структурной адаптации). 3. Зайцев С.С. Описание и реализация протоколов сетей ЭВМ. М.: Наука, 1989. 272 с. 4. Power J.F., Malloy B.A. Metric-Based Analysis of Context-Free Grammars / 8th IEEE International Workshop on Program Comprehension. Limerick: IEEE Computer Society, 2000, pp. 171–178. 5. Никифоров А.Ю. Язык описания взаимодействия иерархических систем и его персонализация // Программные продукты и системы. 2009. № 1. С. 36–37. | ||||||||||||||||||||||||||||||||||||||||||||||||
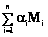 , где ai – весовые коэффициенты выбранной метрики размера/сложности языка Мi. Укрупненные этапы ее решения следующие.
, где ai – весовые коэффициенты выбранной метрики размера/сложности языка Мi. Укрупненные этапы ее решения следующие.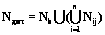 ,
, 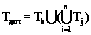 ,
, 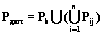 , jÎ{1, …, ki}.
, jÎ{1, …, ki}.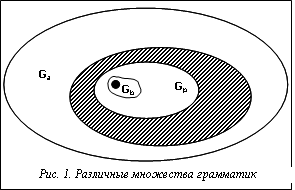 Предложенный метод был реализован в НИЯУ «МИФИ» (г. Москва) при разработке лабораторного практикума по курсу «Взаимосвязь открытых систем» (ВОС). При обучении организации распределенной обработки информации возникает ряд трудностей. За последние десятилетия разработаны и достаточно подробно описаны применяемые при этом модели весьма общего характера. Оборотной стороной обобщающих усилий специалистов является высокий уровень абстрактности подобных описаний. Вместе с тем многие поддерживающие взаимосвязь механизмы при своей адекватной работе настолько незаметны, что кажутся несуществующими, прозрачными для пользователя. Это может способствовать формированию неверного априорного отношения к основам курса ВОС, с одной стороны, как к излишне теоретизированной дисциплине, с другой – как к дисциплине, описывающей нечто избыточное с практической точки зрения.
Предложенный метод был реализован в НИЯУ «МИФИ» (г. Москва) при разработке лабораторного практикума по курсу «Взаимосвязь открытых систем» (ВОС). При обучении организации распределенной обработки информации возникает ряд трудностей. За последние десятилетия разработаны и достаточно подробно описаны применяемые при этом модели весьма общего характера. Оборотной стороной обобщающих усилий специалистов является высокий уровень абстрактности подобных описаний. Вместе с тем многие поддерживающие взаимосвязь механизмы при своей адекватной работе настолько незаметны, что кажутся несуществующими, прозрачными для пользователя. Это может способствовать формированию неверного априорного отношения к основам курса ВОС, с одной стороны, как к излишне теоретизированной дисциплине, с другой – как к дисциплине, описывающей нечто избыточное с практической точки зрения.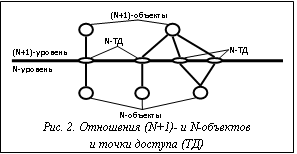 При использовании метрик оценки синтаксической сложности полученного языка [4] в сравнении с такими языками описания, как E-LOTOS и SDL-92, а также с популярными языками программирования ISO C, ISO C++ и Java приведены в таблице 2. Простота разрабатываемого языка в соответствии с этими оценками очевидна [5]. Многолетняя практика использования разработанного языка подтвердила справедливость этих оценок – по сравнению с аналогичным практикумом, использующим для описания универсальные языки программирования, скорость освоения и выполнения заданий повысилась более чем в два раза (см. рис. 3).
При использовании метрик оценки синтаксической сложности полученного языка [4] в сравнении с такими языками описания, как E-LOTOS и SDL-92, а также с популярными языками программирования ISO C, ISO C++ и Java приведены в таблице 2. Простота разрабатываемого языка в соответствии с этими оценками очевидна [5]. Многолетняя практика использования разработанного языка подтвердила справедливость этих оценок – по сравнению с аналогичным практикумом, использующим для описания универсальные языки программирования, скорость освоения и выполнения заданий повысилась более чем в два раза (см. рис. 3).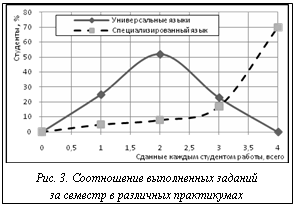 Если вернуться к начальному этапу построения языка – определению семантической нагрузки операторов семантического базиса – то такое определение выделяется как отдельная сложная задача. С одной стороны, с уменьшением нагрузки операторов до атомарных действий усложняются понимание и написание программы вплоть до тьюринговской трясины эзотерических языков, которые, несмотря на их полноту, сложно использовать в практических целях. С другой стороны, введение большого количества операторов на все случаи жизни усложняет обучение, при этом многие из них не будут использоваться большинством программистов. В итоге требуется введение некоторой меры оценки семантической сложности операторов языка.
Если вернуться к начальному этапу построения языка – определению семантической нагрузки операторов семантического базиса – то такое определение выделяется как отдельная сложная задача. С одной стороны, с уменьшением нагрузки операторов до атомарных действий усложняются понимание и написание программы вплоть до тьюринговской трясины эзотерических языков, которые, несмотря на их полноту, сложно использовать в практических целях. С другой стороны, введение большого количества операторов на все случаи жизни усложняет обучение, при этом многие из них не будут использоваться большинством программистов. В итоге требуется введение некоторой меры оценки семантической сложности операторов языка.| Постоянный адрес статьи: http://swsys.ru/index.php?id=2920&page=article |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2011 год. [ на стр. 85 – 88 ] |
Назад, к списку статей