Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Распределенные вычисления при ограниченном числе копий программного ресурса
Аннотация:Решаются задачи нахождения времени выполнения распределенных конкурирующих процессов при ограничен-ном числе копий программного ресурса в условиях неограниченного и ограниченного параллелизма.
Abstract:Problems of a finding of time of performance of the distributed competing processes are solved at the limited number of copies of a program resource in the conditions of the unlimited and limited parallelism.
| Авторы: Коваленко Н.С. (kovalenkons@rambler.ru) - Белорусский государственный экономический университет, г. Минск (профессор), Минск, Беларусь, доктор физико-математических наук, Павлов П.А. (pavlov.p@polessu.by) - Полесский государственный университет, Беларусь, г. Пинск (доцент), Пинск, Беларусь, кандидат физико-математических наук | |
| Ключевые слова: одинаково распределенная система, однородная система, неограниченный параллелизм, ограниченный параллелизм, синхронный режим, асинхронный режим, программный ресурс, распределенный конкурирующий процесс |
|
| Keywords: homogeneous system, homogeneous system, unlimited parallelism, limited parallelism, synchronous mode, asynchronous mode, the program resource, distributed competing process |
|
| Количество просмотров: 10065 |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
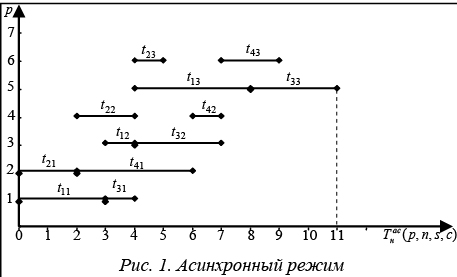
Во многих приложениях, связанных с проек- тированием многопроцессорных систем (МС), вычислительных комплексов, системного и прикладного ПО [1–2], оптимальной организации параллельных вычислительных процессов, значительный интерес представляют задачи, в которых множество конкурирующих процессов могут использовать не одну, а несколько копий структурированного программного ресурса (ПР). Случай, когда в общей памяти МС имеется одна копия ПР, с различных точек зрения описан в работах [3–5]. При этом были решены задачи нахождения минимального общего времени выполнения распределенных конкурирующих процессов, использующих структурированный на блоки ПР в различных режимах взаимодействия процессов, процессоров и блоков, получены критерии эффективности и оптимальности структурирования ПР, проведен сравнительный анализ режимов взаимодействия процессов, процессоров и блоков, решен ряд оптимизационных задач по расчету числа процессов, минимального числа процессоров и др. Изучение этих и других задач, относящихся к оптимальной организации параллельных вычислений, приобретает особую актуальность, когда в общей памяти МС одновременно могут размещаться две или более копий (c) ПР. Такое обобщение носит принципиальный характер ввиду того, что отражает основные черты мультиконвейерной обработки, а также позволяет сравнить эффективность конвейерной и параллельной обработки. В данной работе строится и исследуется математическая модель организации конкурирующих процессов, использующих ограниченное число копий ПР. При этом с помощью метода структурирования ПР на блоки с их последующей конвейеризацией по процессам и процессорам исследуются оптимальные временные характеристики такой организации. Математическая модель распределенных вычислений при ограниченном числе копий ПР Конструктивными элементами для построения математических моделей систем распределенных вычислений являются понятия процесса и ПР. Процесс будем рассматривать как последовательность блоков (команд, процедур) Q1, Q2, …, Qs, для выполнения которых используется множество процессоров (процессорных узлов, обрабатывающих устройств, интеллектуальных клиентов). При этом процесс называется распределенным, если все блоки или часть из них обрабатываются разными процессорами [2]. Для ускорения процессы могут обрабатываться параллельно, взаимодействуя путем обмена информацией. Такие процессы называются кооперативными, или взаимодействующими. Ресурсом являются любые объекты, которые используются для выполнения процесса. Реентерабельные (многократно используемые) – это ресурсы, одновременно используемые несколькими вычислительными процессами. Для параллельных систем характерна ситуация, когда одну и ту же последовательность блоков или ее часть необходимо выполнять многократно. Такую последовательность будем называть программным ресурсом, а множество соответствующих процессов – конкурирующими. Математическая модель распределенной обработки конкурирующих взаимодействующих процессов при ограниченном числе копий ПР включает в себя: p процессоров МС (p³2), которые имеют доступ к общей памяти; n распределенных конкурирующих процессов (n³2); s блоков структурированного на блоки ПР (s³2); матрицу T=[tij], Также предположим, что число процессов n кратно числу копий c структурированного ПР, то есть n=mc, m³2, и что взаимодействие процессов, процессоров и блоков ПР подчинено следующим условиям: - ни один из процессоров одновременно не может обрабатывать более одного блока; - процессы выполняются в параллельно-конвейерном режиме группами, то есть осуществляется одновременное (параллельное) выполнение c копий каждого блока в сочетании с конвейеризацией групп из c блоков по процессорам и процессам; - обработка каждого блока ПР происходит без прерываний; - распределение блоков ПР по процессорам для каждого из процессов i=lc+q, Введем следующие режимы взаимодействия процессов, процессоров и блоков с учетом наличия c копий ПР: - асинхронный режим, при котором начало выполнения очередной группы из c копий блока Qj, - первый синхронный режим, обеспечивающий линейный порядок выполнения блоков ПР внутри каждого из процессов без задержек, то есть для каждого процесса i=lc+q, - второй синхронный режим, при котором c копий каждого блока непрерывно переходят по группам из с процессов, то есть момент окончания обработки c копий текущего блока совпадает с моментом начала их обработки на следующей группе из c процессоров. На рисунках 1–3 представлены диаграммы Ганта, иллюстрирующие выполнение n=4 распределенных конкурирующих процессов, использующих c=2 копии структурированного ПР в МС с p=7 процессорами в рассмотренных выше режимах и с заданной матрицей времени выполнения блоков ПР с учетом дополнительных системных расходов
Определение 1. Система n распределенных конкурирующих процессов называется неоднородной, если время выполнения каждого из блоков ПР Q1, Q2, …, Qs зависит от объемов обрабатываемых данных и/или их структуры, то есть разное для разных процессов. Определение 2. Систему распределенных конкурирующих процессов будем называть однородной, если время выполнения Qj-го блока каждым из i-х процессов одинаково, то есть tij=tj, Определение 3. Систему конкурирующих процессов будем называть одинаково распределенной, если время tij выполнения каждого из блоков Qj, Время выполнения неоднородных распределенных процессов в асинхронном режиме при достаточном числе процессоров Обозначим минимальное общее время выполнения n неоднородных распределенных конкурирующих процессов при ограниченном числе c копий ПР в МС с p процессорами в асинхронном режиме с учетом параметра e через
Пусть имеется система n=mc, m³2, 2£c£p, неоднородных распределенных конкурирующих процессов, причем число блоков s структурированного ПР не превосходит числа групп процессоров по с процессоров в каждой, то есть Пусть
где Пример 1. Рассмотрим интерпретацию формулы (1) на числовом примере. Пусть p=7, n=6, s=3, c=2, а время выполнения блоков процессами задано матрицей Тогда m=3, следовательно, функционал (1) примет вид
1) При q=1 имеем:
Если u1=1,
=max[12, 11, 10, 11, 10, 10]=12. 2) При q=2 имеем:
Если u1=1,
=max[8, 8, 10, 10, 12, 12]=12. Следовательно, минимальное общее время выполнения n=6 неоднородных распределенных взаимодействующих конкурирующих процессов, использующих c=2 копии структурированного на s=3 блока ПР, в МС с p=7 процессорами в асинхронном режиме составит
По заданным s, c, Теорема 1. Минимальное общее время выполнения n=mc, m³2, неоднородных распределенных конкурирующих процессов, использующих 2£c£p копий структурированного на Пример 2. Используя данные примера 1, найти минимальное общее время По заданным n=6, s=3 и матрице Te строим 2-слойный (c=2) вершинно-взвешенный граф Асинхронный режим выполнения распределенных конкурирующих процессов в условиях ограниченного параллелизма Рассмотрим случай ограниченного параллелизма, то есть когда число блоков структурированного ПР больше числа групп по c процессоров в каждой, то есть Как и в случае с одной копией ПР в общей памяти МС множество из s блоков разобьем на (k+1) групп по
Полученная структура результирующей совмещенной диаграммы Ганта определяется матрицей T* (2), которая состоит из подматриц
где
По матрице T* построим c-слойный вершинно-взвешенный граф Теорема 2. Минимальное общее время Пример 3. По значениям параметров диаграммы Ганта, изображенной на рис. 6, найти минимальное общее время Так как
Построим по матрице T* 2-слойный вершинно-взвешенный граф
Согласно определению 2, систему распределенных конкурирующих процессов будем считать однородной, если время выполнения каждого блока Qj, На рисунке 9 представлена диаграмма Ганта, иллюстрирующая выполнение однородных распределенных конкурирующих процессов при ограниченном числе копий ПР в МС с параметрами p=7, n=4, s=3, c=2, Оценим общее время выполнения n однородных распределенных конкурирующих процессов в асинхронном режиме, использующих c копий структурированного ПР. Пусть – длительности выполнения каждого из блоков Qj, Покажем, что в этих условиях вычисление общего времени Из формулы вычисления общего времени выполнения n однородных конкурирующих процессов, использующих одну копию структурированного ПР с учетом того, что n=mc, m³2, 2£c£p, получаем
Для доказательства формулы (3) воспользуемся функционалом (1) задачи Беллмана–Джонсона, который для систем однородных конкурирующих процессов примет вид
где
Если Определение 4. Однородное структурирование ПР на s блоков с временем выполнения , Следствие. В случае равномерного структурирования для вычисления минимального общего времени выполнения распределенных конкурирующих процессов при ограниченном числе копий программного продукта имеют место формулы
Рассмотрим систему одинаково распределенных конкурирующих процессов. Время выполнения всех ее блоков с учетом накладных расходов e каждым из i-х процессов совпадает и равно На рисунке 10 представлена диаграмма Ганта, иллюстрирующая выполнение одинаково распределенных конкурирующих процессов в МС с параметрами p=7, n=4, s=3, c=2, Обозначим через Теорема 3. Минимальное общее время вы- полнения n, n³2, одинаково распределенных конкурирующих процессов, использующих структурированный на s, s³2, блоков ПР в МС с p, p³2, процессорами в асинхронном режиме при ограниченном числе копий ПР составляет величину
Для доказательства рассмотрим сначала случай, когда
где Рассмотрим далее случай, когда
Здесь В случае, когда общего времени выполнения одинаково распределенных конкурирующих процессов при ограниченном числе копий ПР. В заключение отметим, что рассмотренное обобщение математической модели с одним структурированным ПР (конвейером) на случай ограниченного числа ПР позволяет установить взаимосвязи мультиконвейерной обработки с аналогичной обработкой при одном программном конвейере, получить аналитические оценки общего времени выполнения конкурирующих процессов при ограниченном параллелизме и провести математическое исследование эффективности и оптимальности мультиконвейерной организации конкурирующих процессов, вскрыть потенциальные возможности роста ускорения вычислений, выполнить сравнительный анализ различных режимов такой обработки. Литература 1. Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. СПб: БХВ–Петербург, 2002. 2. Топорков В.В. Модели распределенных вычислений. М.: Физматлит, 2004. 3. Иванников В.П., Коваленко Н.С., Метельский В.М. О минимальном времени реализации распределенных конкурирующих процессов в синхронных режимах // Программирование. 2000. № 5. С. 44–52. 4. Павлов П.А. Оптимальность структурирования программных ресурсов при конвейерной распределенной обработке // Программные продукты и системы. 2010. № 3. С. 76–82. 5. Kapitonova Yu.V., Kovalenko N.S., Pavlov P.А. Optimality of systems of identically distributed competing processes // Cybernetics and Systems Analysis. NY: Springer. 2006, pp. 793–799. |
 ,
, 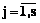 , времен выполнения блоков ПР распределенными взаимодействующими конкурирующими процессами; c копий (2£c£p) структурированного на блоки ПР, которые могут одновременно находиться в оперативной памяти, доступной для всех p процессоров, причем
, времен выполнения блоков ПР распределенными взаимодействующими конкурирующими процессами; c копий (2£c£p) структурированного на блоки ПР, которые могут одновременно находиться в оперативной памяти, доступной для всех p процессоров, причем  ; параметр e (e>0), характеризующий время дополнительных системных расходов, связанных с организацией конвейерного режима использования блоков структурированного ПР множеством взаимодействующих конкурирующих процессов при распределенной обработке.
; параметр e (e>0), характеризующий время дополнительных системных расходов, связанных с организацией конвейерного режима использования блоков структурированного ПР множеством взаимодействующих конкурирующих процессов при распределенной обработке. , l³0,
, l³0, 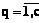 , осуществляется циклически по правилу: блок с номером
, осуществляется циклически по правилу: блок с номером  ,
, 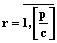 , распределяется на процессор с номером q+c(r–1).
, распределяется на процессор с номером q+c(r–1). , определяется наличием c процессоров и готовностью этой группы блоков к выполнению (программный блок считается готовым к выполнению, если он не выполняется ни на одном из процессоров);
, определяется наличием c процессоров и готовностью этой группы блоков к выполнению (программный блок считается готовым к выполнению, если он не выполняется ни на одном из процессоров); ,
,  .
.
 . Для его вычисления рассмотрим случаи неограниченного
. Для его вычисления рассмотрим случаи неограниченного  и ограниченного
и ограниченного  параллелизма.
параллелизма.
 . В этом случае без ограничения общности можно считать, что каждый Qj-й,
. В этом случае без ограничения общности можно считать, что каждый Qj-й,  , l³0,
, l³0,  , закреплен за (q+c(r–1))-м процессором,
, закреплен за (q+c(r–1))-м процессором,  процессоров, а остальные
процессоров, а остальные 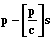 процессоров не будут задействованы.
процессоров не будут задействованы.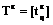 – n´s-матрица времени выполнения блоков ПР каждым из i-х процессов с учетом параметра e>0, где
– n´s-матрица времени выполнения блоков ПР каждым из i-х процессов с учетом параметра e>0, где 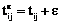 ,
, 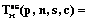

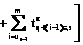 , (1)
, (1) ,
,  ,
,  ,
, 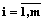 ,
,  .
.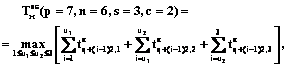
 .
.
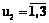 , если u1=2, u2=2,3, если u1=3, u2=3, тогда
, если u1=2, u2=2,3, если u1=3, u2=3, тогда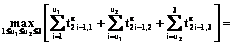






 . При этом будут использованы 6 процессоров.
. При этом будут использованы 6 процессоров.

 ,
,  . Каждый q-й,
. Каждый q-й,  ,
,  – входные вершины,
– входные вершины,  – выходные,
– выходные,  ,
,  ,
,  ,
, 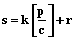 , k³1,
, k³1,  .
. блоков в каждой, за исключением (k+1)-й группы, которая будет содержать r блоков. Тогда матрицу
блоков в каждой, за исключением (k+1)-й группы, которая будет содержать r блоков. Тогда матрицу  ,
,  , времени выполнения блоков разбиваем на (k+1) подматрицу
, времени выполнения блоков разбиваем на (k+1) подматрицу  ,
, 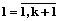 , размерностью
, размерностью  каждая, за исключением последней
каждая, за исключением последней  , которая будет содержать при s, не кратном
, которая будет содержать при s, не кратном  столбцов будут нулевыми. По каждой из подматриц
столбцов будут нулевыми. По каждой из подматриц  процессорах всеми n процессами, использующими ограниченное число c копий структурированного ПР. При r¹0 (k+1)-я диаграмма будет отражать выполнение последних r блоков на cr процессорах. На рисунке 6 представлена диаграмма Ганта для МС с параметрами p=7, n=4, s=3, c=2:
процессорах всеми n процессами, использующими ограниченное число c копий структурированного ПР. При r¹0 (k+1)-я диаграмма будет отражать выполнение последних r блоков на cr процессорах. На рисунке 6 представлена диаграмма Ганта для МС с параметрами p=7, n=4, s=3, c=2: .
.

 . В матрице T* учтены как все горизонтальные, так и все вертикальные связи между блоками, а также связи между блоками из разных диаграмм Ганта. Отметим также, что результирующая матрица T* имеет размерность
. В матрице T* учтены как все горизонтальные, так и все вертикальные связи между блоками, а также связи между блоками из разных диаграмм Ганта. Отметим также, что результирующая матрица T* имеет размерность  , является блочной, симметричной, верхней диагональной относительно второй диагонали, типа Ганкелевой порядка k+1
, является блочной, симметричной, верхней диагональной относительно второй диагонали, типа Ганкелевой порядка k+1 , (2)
, (2) ,
,  ,
, .
.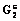 , аналогичный графу
, аналогичный графу  графа
графа  ,
,  – выходными,
– выходными,  , в асинхронном режиме в случае неограниченного параллелизма
, в асинхронном режиме в случае неограниченного параллелизма 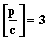 , то
, то 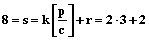 , следовательно, k=2, r=2. Матрицу Te разбиваем на подматрицы
, следовательно, k=2, r=2. Матрицу Te разбиваем на подматрицы  , размерностью 4´3 каждая. Матрица T* будет иметь размерность
, размерностью 4´3 каждая. Матрица T* будет иметь размерность  и следующий вид:
и следующий вид:

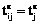 ,
,  .
. ,
,  .
. в случае неограниченного параллелизма сводится к нахождению общего времени выполнения однородных распределенных процессов при одной копии структурированного ПР. При n=mc, m³2, 2£c£p, выполнение c копий структурированного ПР в асинхронном режиме равносильно выполнению c групп по m процессов, конкурирующих за использование одной копии ПР на
в случае неограниченного параллелизма сводится к нахождению общего времени выполнения однородных распределенных процессов при одной копии структурированного ПР. При n=mc, m³2, 2£c£p, выполнение c копий структурированного ПР в асинхронном режиме равносильно выполнению c групп по m процессов, конкурирующих за использование одной копии ПР на  (3)
(3)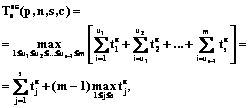


 , k>1, матрица времени выполнения блоков ПР строится аналогично матрице T*. Отличие в том, что в каждой из подматриц
, k>1, матрица времени выполнения блоков ПР строится аналогично матрице T*. Отличие в том, что в каждой из подматриц 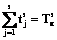 , будем называть равномерным, если
, будем называть равномерным, если 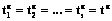 .
.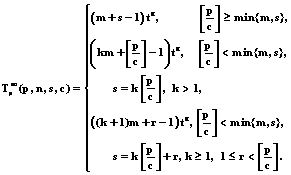
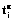 , то есть справедлива цепочка равенств
, то есть справедлива цепочка равенств  для всех
для всех  в случае неограниченного
в случае неограниченного  суммарное время выполнения каждого из блоков Qj,
суммарное время выполнения каждого из блоков Qj,  – максимальное время выполнения блока из этой группы,
– максимальное время выполнения блока из этой группы,  , равную
, равную
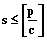 или
или  . Воспользуемся функционалом (1) задачи Беллмана–Джонсона, который для систем одинаково распределенных конкурирующих процессов примет вид
. Воспользуемся функционалом (1) задачи Беллмана–Джонсона, который для систем одинаково распределенных конкурирующих процессов примет вид 
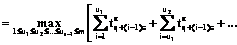

 ,
,  . Вычисление общего времени
. Вычисление общего времени 

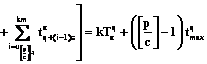 .
. ,
, 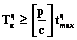 , вычисление общего времени с помощью функционала задачи Беллмана–Джонсона приводит к третьей формуле для вычисления
, вычисление общего времени с помощью функционала задачи Беллмана–Джонсона приводит к третьей формуле для вычисления| Постоянный адрес статьи: http://swsys.ru/index.php?id=2938&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2011 год. [ на стр. 155 – 163 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: