Механизмы управления эволюцией организационно-технологической системы
| Виноградов Г.П. (wgp272ng@mail.ru) - Тверской государственный технический университет (профессор), Тверь, Россия, доктор технических наук, Палюх Б.В. (pboris@tstu.tver.ru) - Тверской государственный технический университет (профессор), г. Тверь, Россия, доктор технических наук | |
| Ключевые слова: эволюция, самоорганизация, целеустремленное состояние, агент, нечеткий вывод, интеллектуальные организации |
|
| Keywords: evolution, self-organization, goal sets, agent, fuzzy conclusion, intelligent organization |
|
|
|
|
Системный подход к управлению интеллектуальными организациями с неоднородными агентами использует два их основных креативных свойства: способность человека к самоорганизации (самосовершенствованию) без участия внешних сил (активная форма адаптации, когда для эффективного поведения системы в будущем она сама изменяет среду) и способность к пассивной форме адаптации (приспособление к изменениям во внешней среде для сохранения эффективности в ней). Организация как центр действий и процессов, ориентированных на цели, объединяет эти два вида потенциала своего развития. Потенциал адаптации реализуется с помощью механизмов функционирования, основанных на централизации. Либеральные механизмы, создавая соответствующий климат, способствуют раскрытию творческих способностей субъекта, реализуют его способность к самоорганизации. При централизованном механизме процедуры планирования должны быть направлены на постепенное обнаружение резервов используемого способа производства путем сочетания их с процедурами исследования объекта управления и активного экспериментирования. Агент, зная цель этих процедур, может занижать свою эффективность в сравнении с имеющимся потенциалом, чтобы увеличить или сохранить свои выгоды в будущем. Это связано со сложным характером соотношения параметров процедур планирования, стимулирования и субъективными оценками агентом текущей и будущих ситуаций целеустремленного состояния. Нарушение этого соотношения приводит к регрессу организации. Либеральные механизмы, использующие свойства агента к самоорганизации, будут эффективными только в случае направленности деятельности агентов на общую цель, достижение которой должно гарантировать им получение ожидаемых состояний. Если развитие зависит от инноваций, изобретений и творчества, эффективность организации в еще большей степени обусловлена поведением агентов. В информационном обществе продукт интеллектуального труда неотделим от работника [1]. Эволюционный менеджмент будет эффективным, если обеспечивает полную реализацию способностей человека. Для эффективного функционирования всех своих членов при достижении определенной цели организация путем обмена овладевает их человеческим капиталом. И в первом, и во втором случаях успех определяется тем, как центр понимает принципы и процедуры формирования у агентов представлений о свойствах ситуации выбора и правил выбора ими решений. В обоих вариантах это связано с анализом обработки информации человеком. Постановка задачи управления эволюцией организационно-технологической системы Пусть организационная система состоит из центра и n агентов, обладающих активностью, автономностью, креативностью. Каждый агент управляет каким-либо технологическим узлом. Возможности k-го агента по выпуску продукции описываются технологическим множеством - областью Xk в пространстве из nk измерений: любой допустимый план xk={xij, j= xkÎXk, k= План всей активной системы будет описываться вектором x={xk, k= Допустимый план x должен удовлетворять не только локальным ограничениям, но и ряду глобальных ограничений вида G(x)≥b, где
Суть глобальных ограничений в том, что за их выполнение отвечает не какой-либо агент, а центр, управляющий всей системой. Формально это выражается в том, что функции G(x) предполагаются зависящими от всего вектора x, а не от одного из векторов xk, Будем считать, что gi(x),
Здесь предполагается, что цель, стоящая перед центром, заключается в максимизации известной ему функции Ф(x), зависящей от всех компонент вектора x. Особенность задачи оптимального планирования (3) заключается в том, что либо центру неизвестна вся область X, либо он не знает все потенциальные возможности агентов. Практическая невозможность для центра получить точное представление о технологических ресурсах агентов предполагает необходимость разработки специальных процедур обмена информацией между центром и агентами. Это позволяет ему сформировать согласованный план без необходимости решения задачи математического программирования в полном объеме (с учетом всех глобальных и локальных ограничений, отражающих интересы агентов).
Описанная модель поведения интеллектуальных агентов предполагает, что агенты, управляющие технологическим агрегатом (процессом), на уровне собственных представлений хорошо знают и чувствуют свои объекты управления и могут с достаточной степенью точности ответить, например, на такие вопросы: Какой план для вас выгоден при заданной системе стимулирования? Укажите по определенной шкале ценность для вас величины стимулирования при данном уровне плана. Если данный план для вас является невыполнимым, то укажите, какой из выполнимых планов наиболее близок к данному плану. Что нужно, по вашему мнению, сделать, чтобы невыполнимый план стал реализуемым? Базовая модель обучающейся организационно-технологической системы Рассмотрим обучающуюся адаптивную организационно-технологическую систему (см. рис.). Функционирование схемы начинается с периода t, t=0, 1, 2, … На вход агента подается управление центра: план ht, определяющий результаты деятельности агента yt, потребляемые ресурсы xt, режимы ведения технологического процесса в виде коэффициентов выпуска at, а также управление его поведением ut. В состав последнего входят затраты на оплату деятельности агента, его обучение и коучинг, стимулирование поиска скрытых резервов и т.п. Кроме того, на вход объекта действует помеха, значение которой в момент времени t известно агенту, но неизвестно центру. Обладая определенной структурой информированности Et, агент может сформировать представление о множествах Y(p(ut), xt, wt) и Z(p(ut), xt, wt). После анализа реализуемости возможных режимов ведения технологического процесса агент выбирает состояние ytÎY(p(ut), xt, wt). Центр наблюдает результат выбора yt и определяет оценку параметра at+1 в периоде t+1: at+1=I(at, yt, xt), a0=a0, (4) где I – процедура оценки технологических возможностей агента; αt – оценки потенциала p(ut) агента в период t, atÎR1, t=0, 1, 2, …, I(αt, yt, xt)ÌC1, I(α, y, x)a, Предположим, что при любых αÎAt процедура (4) удовлетворяет следующим условиям: I(α, y, x)³I(α, y¢, x)Ûm, m¢ÎQ, uÎU, yÎY(p(u), x, m), y¢ÎY(p(u), x, m¢) и m³m¢ [2]. Значит, центр, получив более высокие оценки потенциала агента, может быть уверен, что агент стремится улучшить свое представление об имеющихся резервах технологического процесса и его деятельность направлена на их реализацию в практике управления. Если yÎY(p(u), x, w) и y'ÎY(p(u), x, w'), то I(a, y, x)³I(a, y', x). В силу строгой монотонности Y(p(u), x, w) и условий выпуклости и замкнутости существует единственная форма представлений агента µ=xaÎq о технологических возможностях, при которой yÎY*(p(u), x, w). Это, в свою очередь, гарантирует, что различным потенциалам агента p(u, m) и p(u, m¢), m¹m¢, таким, что yÎY(p(u), x, m) и y'ÎY(p(u), x, m'), центр будет назначать разные оценки I(a, x, y)¹I(a, x, y¢). Зная оценки потенциала агента at+1, центр, используя процедуру планирования p и регулирования Q, определяет ему вознаграждение за достижение плановых показателей: ut+1=Q(at+1), ut+1ÎUt+1 и план ht+1={yt+1, xt+1, at+1) на период t+1: ht+1=p(at+1), ht+1ÎHt+1, p(a)a. Здесь p, QÎC – непрерывные функции, которые могут быть известны и согласованы центром с агентами. Сопоставляя фактическое состояние h*t+1={yt+1, xt+1, at+1) с плановым ht+1={yt+1, xt+1, at+1), центр определяет стимулирующее воздействие на агента по правилу На этом функционирование системы в период t завершается. Допустим, что на r-м шаге интерактивной процедуры центр имеет некоторую информацию о множестве предпочтительных состояний агента Si(r). Предположим, что на r+1-м шаге от агента была получена дополнительная информация и построено новое множество желательных состояний для агента Si(r+1). Последовательно конструируемые центром множества желательных состояний агента должы отвечать следующему условию: Si(r)ÍSi(r+1). (5) В этом случае можно говорить, что множество Si(r+1) непротиворечиво расширяет множество Si(r). Если потребовать, чтобы включение было строгим, то (5) будет условием содержательности дополнительной информации от агента о предпочтительных состояниях. Конечность множества Xk гарантирует сходимость процедуры. Пусть результат деятельности центра dÎA0 определяется результатами деятельности агентов и A0=G(A1, β), где G(·) – функция агрегирования результатов деятельности агентов. Целевая функция центра является функционалом F(s, d) и представляет собой разность между его доходом ld, где l может интерпретироваться как рыночная цена, и затратами на вознаграждение σ(d, p), выплачиваемое агентам: s(d, p)= Тогда F(s(·), d, l, p)=ld– Поведение агента Будем считать, что интересы агента описываются вектором При управлении технологическим узлом такое поведение агент реализует путем выбора значений режимных параметров zi, которые, в свою очередь, определяют значения вектора yi, а значит, и oi. Справедливо условие ziÎZi, где Zi – множество допустимых значений режимных параметров, определяемое технологическим регламентом. Отметим, что агент вправе рассматривать расширенный вариант вектора yi. В него он может включать параметры состояния агрегатов технологического узла, интенсивность своего труда и т.п. Значения вектора режимных параметров zi определяются вектором способов действия ci. В последний входят значения энергетических потоков, расходы сырья, вспомогательных материалов и т.д. Очевидно, что ciÎCi. На технологический узел влияют различного рода возмущающие воздействия wiÎWi, из которых часть siÎSi агент принимает во внимание. Поэтому SiÍWi и SiÇWi¹Æ. Поведение человека как интеллектуального агента, зависящее от его субъективных представлений о ситуации выбора, рассматривалось в работе [3], где было показано, что принимаемое агентом решение о способе действия определяется его оценками компонент ситуации целеустремленного состояния. Оценки, в свою очередь, зависят от структуры информированности Et, которая определяется знаниями, убеждениями, ценностями, нормами, опытом агента. В этой же работе была предложена модель принятия решений агентом, позволяющая учитывать его индивидуальные оценки компонент ситуации целеустремленного состояния. Модифицированный вариант этой модели применительно к задачам управления непрерывным производством имеет следующий вид:
где Eji и EEi – интегральные оценки агента удельной ценности ситуации целеустремленного состояния по результату и эффективности; Целевая функция агента, стремящегося не только увеличить свои доходы в текущем периоде, но и в определенной степени обеспечить их получение в будущем, будет иметь вид Пусть агент может находиться в m состояниях Потенциал самоорганизации и адаптации, реализуемый агентом в действиях, делает справедливым утверждение, что множество Y(p(u), x) является расширяющимся на Q, то есть Y(p(u), x1)Ì ÌY(p(u), x) при uÎU, x, x1ÎQ, m(x)>m(x1), где m(·) – субъективные оценки агента полезности своих представлений. Кроме того, предполагается строгая монотонность Y(p(u), x) на Q при любом uÎU; W(p(u), x)ÇW(p(u), x1)=Æ, m(x)¹m(x1), x, x1ÎQ. Это означает, что способность агента накапливать потенциал за счет самообучения при наличии соответствующего стимулирующего воздействия позволяет дополнить задачу (3) условием
Поскольку механизм функционирования S(I, p, Q, f) с процедурами оценки и прогнозирования потенциала агента I, планирования p, стимулирования f и регулирования Q обладает свойствами выявления потенциала агента путем активной идентификации, будем называть его адаптивным механизмом функционирования. Величину Vt назовем ценой, на которую агент согласен обменять свой человеческий капитал при участии в достижении целей, поставленных центром. В рассмотренном выше случае предполагается, что агент способен к самоорганизации первого типа. Обозначим через ciÎCi способы действия агента, iÎN={1, 2, …} – множество агентов. Пусть Стратегией агента является вектор способа действия ciÎ Ci, который приводит к ожидаемому результату yi в соответствии с его представлениями xi: Удобно ввести вектор v-i={c-i, y-i}, характеризующий полную обстановку игры для i-го агента. Задача (6), решаемая агентом, зависит от параметров p и u, причем целевая функция агента f(·) неизвестна центру. Центр предполагает, что агент, наблюдая обстановку v-i={c-i, y-i}, знает правила реализации своего потенциала в вектор способов действий D: Pk®Ck и вектор параметров результатов Dy: Ck®Yk. Целевая функция i-го агента является функционалом fi(σi, yi, pi) и представляет собой, как показано в (6), удельную ценность ситуации целеустремленного состояния по результату. Второй возможный вариант – это разность между субъективными оценками удельной ценности ситуации целеустремленного состояния по результату и эффективности затрат, то есть fi(si(·), yi, pi)=Ej(si(yi, pi)) –EEi(y(ci, pi)), iÎN. В этом случае агент обменивает свой человеческий капитал pi(xi) на вознаграждение si(yi, pi) при приемлемом для него уровне затрат на получение результата yi [2]. Агент является собственником этого капитала, носителем уникального опыта, знаний и человеческих качеств. Обозначим через X*={x*½x*ÎX*(p), pÎP} множество достижимости или множество предельных технологических возможностей. При выполнении условия (7) способности агента формировать расширяющееся множество способов ведения технологического процесса и стимулирующем воздействии центра u можно определить следующие свойства целевой функции и областей достижимости:
Условие (8) означает, что агент способен сконструировать более эффективные способы действия и видит открывающиеся при их реализации возможности. Алгоритм построения агентом множества предпочтительных состояний Поскольку конкретный вид целевой функции f(·) и состав множеств P и 1. Получение агентом от центра на r-м шаге варианта плана hk(r) и управляющего воздействия uk(r). Формирование агентом множеств Pk и Xk на основе знаний, опыта, интуиции и информации о параметрах своего потенциала pk и обстановке v-k. Просмотр множеств Pk и Xk, формирование точки yo*={yo*½yo*=y(x), xÎXk(p), pÎPk}. Построение для найденной точки оценок значимости результата o(yo*), удельной ценности ситуации целеустремленного состояния по результату Ejk(o(yo*)) и эффективности EEk(o(yo*)). Проверка существования x* и c*, таких, что y(x*(p), c*(p))=yo* и o(yo*)=o*. Если таких способов нет, осуществляется переход к п. 2, иначе проверяются условия
Если условия (9) выполняются, то x* принадлежит к множеству желательных состояний для агента, а y(x*(p)) – вектор результатов, удовлетворяющий представлениям агента о свойствах будущей ситуации целеустремленного состояния. Сообщение информации центру. В противном случае переход к п. 2. 2. Решение задачи поиска потенциально предпочтительного набора действий x*ÎX(p) и c*ÎC(p), позволяющего сформировать вектор 3. Анализ направлений возможного расширения множества P путем изучения свойств обстановки v-k и организация процедур поиска новой информации (знания) для Pk(r)ÍPk(r+1), а значит, конструирование новых правил D и Y, то есть расширение множеств Xk и Ck. 4. Если расширение множества Pk(r) возможно и существует Pk(r+1) такое, что Pk(r)ÍPk(r+1), осуществляется переход к п. 1, иначе фиксируется, что компромиссное решение yo* является неприемлемым при управлении uk(r). 5. На основе условий (9) путем решения обратной задачи определяются лучшие значения o 6. Выполнение процедуры поиска минимально предпочтительной точки в пространстве оценок значимости ситуации целеустремленного состояния по направлению предпочтения y, yo*, определение вектора p0ÎP и x*ÎX(p). 7. Если полученное значение для x*, y*, o* принимается как удовлетворительное решение, процедура останавливается, в противном случае осуществляется переход к п. 8. 8. Для ограничений на o (прямых и косвенных) X определяет приоритетную координату Описанный алгоритм использует три типа механизмов, применение которых порождает интерактивный процесс для построения компромис- сного решения. Механизм анализа: с его помощью агент в момент r обрабатывает сведения, полученные на шаге r–1, для построения множеств Pk и Xk с целью определения xk, yo*, c*, z*. Сопоставляются результаты, полученные на момент r, с результатами на шаге r–1. Формируется представление о значениях вектора oo* и уступок по его компонентам. Строится предварительное представление о желательных значениях показателей Ejk(o(yo*)) и EEk(o(yo*)). Механизм целеполагания: с учетом результатов предшествующего анализа позволяет определять условия, при которых возможно достижение желательных значений xk, yo*, c*, z*, Ejk(o(yo*)) и EEk(o(yo*)). Для этого рассчитывается идеальная точка в пространстве оценок o, связанная с множествами Pk и Xk, – это точка То есть Механизм самоорганизации: для предварительно созданных условий позволяет получать (создавать) знания о правилах D и Y для расширения множеств Pk, Xk и Ck. Он может иметь различные формы: проведение экспериментальных исследований на объекте с целью улучшения своего представления о его функционировании; анализ обстановки v-k; привлечение экспертов для подготовки рекомендаций по улучшению режимов ведения процесса; процедуры опроса персонала; процедуры голосования и т.п. В заключение отметим следующее. Описанная методика использовалась для выявления эффекта от внедрения АСУ технологическими комплексами и систем управления безопасностью в химической промышленности. Ее применение позволило определить потенциальные резервы технологических процессов и согласованные траектории их использования на всех уровнях управления. В результате сократились сроки внедрения автоматизированных систем за счет создания стимулов к совершенствованию технологического процесса и систем управления им у производственного и управленческого персонала. Литература 1. Иноземцев В.А. За пределами экономического общества. М.: Academia-Наука, 1998. 2. Цыганов В.В. Адаптивные механизмы функционирования промышленных объединений. М.: ИПУ РАН, 2000. 3. Виноградов Г.П. Индивидуальное принятие решений: поведение целеустремленного агента: научн. монография. Тверь, ТГТУ, 2011. 4. Виноградов Г.П., Кузнецов В.Н. Моделирование поведения агента с учетом субъективных представлений о ситуации выбора // Искусственный интеллект и принятие решений. 2011. № 3. С. 58–72. |
 k-го агента должен принадлежать области Xk:
k-го агента должен принадлежать области Xk: . (1)
. (1)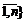 , имеющим размерность
, имеющим размерность  Тогда очевидно, что
Тогда очевидно, что  поскольку подвекторы x1, x2, …, xn принадлежат соответствующим множествам локальных агентов.
поскольку подвекторы x1, x2, …, xn принадлежат соответствующим множествам локальных агентов. . (2)
. (2) описывающих планы отдельных агентов. Общие ограничения отражают задания по выпуску продукции, лимитированность ресурсов, потребляемых комплексом из внешней среды, связи по материальным потокам между технологическими узлами и т.п.
описывающих планы отдельных агентов. Общие ограничения отражают задания по выпуску продукции, лимитированность ресурсов, потребляемых комплексом из внешней среды, связи по материальным потокам между технологическими узлами и т.п. - вогнутые, дифференцируемые функции, а X - выпуклое множество. Тогда задача, решаемая центром, может рассматриваться как задача вогнутого программирования:
- вогнутые, дифференцируемые функции, а X - выпуклое множество. Тогда задача, решаемая центром, может рассматриваться как задача вогнутого программирования: (3)
(3)
 .
. .
. , где σi(yi, pi) – функция стимулирования i-го агента.
, где σi(yi, pi) – функция стимулирования i-го агента.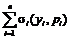 .
.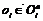 , где
, где  – множество состояний, имеющих различную привлекательность для агента. Значения вектора oi определяются фактическими значениями вектора yi и другими характеристиками технологической ситуации целеустремленного состояния. Предпочтения агента на множестве
– множество состояний, имеющих различную привлекательность для агента. Значения вектора oi определяются фактическими значениями вектора yi и другими характеристиками технологической ситуации целеустремленного состояния. Предпочтения агента на множестве  (6)
(6)
 – оценки, отражающие эмоциональное отношение агента к ситуации выбора.
– оценки, отражающие эмоциональное отношение агента к ситуации выбора. , где r – коэффициент дисконтирования, используемый для приведения будущих доходов к текущему моменту времени t, 0
, где r – коэффициент дисконтирования, используемый для приведения будущих доходов к текущему моменту времени t, 0 образующих его модель ограничений. Предположим, что i-й агент характеризуется параметром piÎWiÍR1, называемым его типом и отражающим потенциал самоорганизации агента. Вектор потенциалов (типов) агентов обозначим через
образующих его модель ограничений. Предположим, что i-й агент характеризуется параметром piÎWiÍR1, называемым его типом и отражающим потенциал самоорганизации агента. Вектор потенциалов (типов) агентов обозначим через  . Тогда yÎY(p)ÍRm. Проявление потенциала агента будет зависеть от управления uÎU со стороны центра, его представлений о свойствах ситуации целеустремленного состояния xÎQ=
. Тогда yÎY(p)ÍRm. Проявление потенциала агента будет зависеть от управления uÎU со стороны центра, его представлений о свойствах ситуации целеустремленного состояния xÎQ= ÌR1, где
ÌR1, где  – представления, известные и разделяемые всеми агентами и центром (общее знание);
– представления, известные и разделяемые всеми агентами и центром (общее знание);  – представления, известные только i-му агенту и в полезности которых он убежден. Будем считать, что множество Y(p) выпукло и замкнуто, то есть Y(p1)ÍY(p2)Í … ÍY(pn)Í … ÍY*(p), где Y*(p) – множество возможных состояний, характеризующих предельные потенциальные возможности агента; p1, p2, …, pn – последовательность потенциальных возможностей агента, возрастающих за счет управления u. Будем предполагать, что множество Y(p(u), x) непрерывно на Q и U соответственно при любых uÎU и xÎQ.
– представления, известные только i-му агенту и в полезности которых он убежден. Будем считать, что множество Y(p) выпукло и замкнуто, то есть Y(p1)ÍY(p2)Í … ÍY(pn)Í … ÍY*(p), где Y*(p) – множество возможных состояний, характеризующих предельные потенциальные возможности агента; p1, p2, …, pn – последовательность потенциальных возможностей агента, возрастающих за счет управления u. Будем предполагать, что множество Y(p(u), x) непрерывно на Q и U соответственно при любых uÎU и xÎQ. (7)
(7) – это вектор способов действия агентов, наблюдаемый всеми агентами, вектор
– это вектор способов действия агентов, наблюдаемый всеми агентами, вектор  – обстановка игры i-го агента по наблюдаемым способам действия.
– обстановка игры i-го агента по наблюдаемым способам действия. , где Ii – доступная агенту информация о правиле получения результата. Тогда
, где Ii – доступная агенту информация о правиле получения результата. Тогда  – вектор результатов деятельности агентов, а вектор
– вектор результатов деятельности агентов, а вектор 
 – обстановка игры i-го агента по результату.
– обстановка игры i-го агента по результату. (8)
(8) полностью неизвестны, решение задачи (3, 7, 8) центром целесообразно выполнять с помощью алгоритмов сводимости, то есть на базе решенных локально-оптимальных задач агентами и полученной от них дополнительной информации. Формирование встречной информации при таком подходе заключается в реализации совокупности последовательных процедур, предназначенных для поиска промежуточных решений, на основании которых агент уточняет свои возможности и формирует окончательное решение. Полный цикл формирования агентом информации о своих возможностях включает следующие шаги.
полностью неизвестны, решение задачи (3, 7, 8) центром целесообразно выполнять с помощью алгоритмов сводимости, то есть на базе решенных локально-оптимальных задач агентами и полученной от них дополнительной информации. Формирование встречной информации при таком подходе заключается в реализации совокупности последовательных процедур, предназначенных для поиска промежуточных решений, на основании которых агент уточняет свои возможности и формирует окончательное решение. Полный цикл формирования агентом информации о своих возможностях включает следующие шаги. . (9)
. (9) предельных оценок значимости ситуации целеустремленного состояния при использовании на данный момент знания о структуре множества P и правилах D и Y. Так как компоненты
предельных оценок значимости ситуации целеустремленного состояния при использовании на данный момент знания о структуре множества P и правилах D и Y. Так как компоненты 
 порознь достижимы, а вместе нет, делается попытка найти компромиссное решение, удовлетворяющее условиям (9), за счет компенсаторных уступок по каждой компоненте, являющейся несколько хуже решения
порознь достижимы, а вместе нет, делается попытка найти компромиссное решение, удовлетворяющее условиям (9), за счет компенсаторных уступок по каждой компоненте, являющейся несколько хуже решения  , по которой делается расширение множеств P и Х так, чтобы
, по которой делается расширение множеств P и Х так, чтобы  , где
, где  – минимально возможное улучшение, которое является значимым для агента. Оно определяется по его высказываниям о гибкости ограничения на основе выполнения процедур поиска дополнительной информации. Определение u(r+1)=u(r)+Du. Переход к п. 1.
– минимально возможное улучшение, которое является значимым для агента. Оно определяется по его высказываниям о гибкости ограничения на основе выполнения процедур поиска дополнительной информации. Определение u(r+1)=u(r)+Du. Переход к п. 1. .
. точки oi¹
точки oi¹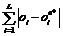 определяются величины pi=oi –
определяются величины pi=oi –http://swsys.ru/index.php?id=3100&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Модель принятия решений целеустремленного поведения агента в слабоструктурированных средах
- Косвенный метод нечеткого вывода для продукционных систем со многими входами
- Алгоритмы формирования управляющих воздействий в распределенных мультиагентных системах
- Архитектура подсистемы нечеткого вывода для оптимизатора баз знаний
- Ресурсно-целевые сети