Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Мультиагентная система поиска информации на промышленном предприятии
Аннотация:Описывается архитектура мультиагентной системы для проведения поиска информации на промышленном предприятии. Перечисляются характерные черты такой системы и особенности ее реализации. Дано описание фор-мального проектирования, результатами которого являются концептуальная модель и дерево интеллектуальных компонентов системы.
Abstract:In the article multiagent architecture of information retrieval system for industrial enterprise are described. Typical streaks of such system and features of implementation are enumerated. Formal designing process is described and conceptual model and intellectual component tree model described as it’s result.
| Авторы: Швецов А.Н. (smithv@mail.ru) - Вологодский государственный технический университет (профессор), Вологда, Россия, доктор технических наук, Летовальцев В.И. (LetovaltsevVictor@gmail.com) - Вологодский государственный технический университет | |
| Ключевые слова: формальное описание, концептуальная модель поиска, мультиагентные системы, информационные поисковые системы |
|
| Keywords: formal description, conceptual retrieval’s model, multi-agent systems, information retrieval system |
|
| Количество просмотров: 12336 |
Версия для печати Выпуск в формате PDF (5.19Мб) Скачать обложку в формате PDF (1.31Мб) |
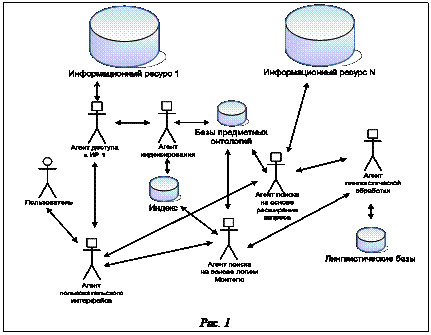
Обеспечение эффективности основной деятельности – обязательное условие при разработке и совершенствовании системы управления предприятием. Более конкурентоспособными являются предприятия, максимально использующие свои ресурсы, в том числе и информацию. Поэтому в современной инфраструктуре предприятия резко возрастает роль информационно-аналитической системы (ИАС). Можно сказать, что основная функция ИАС – обеспечение реализации последовательностей работ, направленных на решение задач управления производством [1]. Важными условиями эффективного управления деятельностью являются возможность использования необходимой информации и обеспечение требований к содержанию и форме представления данных. Под документом в ИАС будем понимать формализованный информационный объект [2]. ИАС участвует в основных бизнес-процессах предприятия: сбор и структуризация исходной информации, хранение данных, формирование отчетов, планирование и анализ. Можно выделить три потока документов – входящие, исходящие и внутренние. В ИАС может входить информация как внутреннего, так и внешнего характера: организационные документы (приказы по предприятию, служебные записки, должностные инструкции и т.д.); производственные (технические регламенты, стандарты, рекомендации, описания техпроцессов); финансовые (бухгалтерские документы, отчеты, результаты экономического анализа); маркетинговые (анализ состояния рынков, уровня конкуренции и т.д.); юридические (законы, указы президента, постановления правительства, распоряжения министерств и ведомств, лицен- зии и т.д.). Перевод документооборота предприятия в электронную форму дает возможность ускорить принятие решений и повысить эффективность управления производством. Информационные технологии позволяют перейти к полностью безбумажному документообороту, при использовании которого одной из важнейших проблем становится обеспечение сотрудников своевременной информацией. Важным механизмом такого обеспечения является информационный поиск. Информационный поиск в ИАС крупных предприятий имеет ряд особенностей. У каждого вида документов свой формат и принадлежность к определенной документной базе. Бухгалтерские документы принадлежат базам бухгалтерских систем (например, 1С или «Галактика»), юридические документы находятся в базах правовых систем (например, «Консультант Плюс» или «ГАРАНТ»), электронная почта – на почтовом сервере предприятия и т.д. Стоит учитывать и возможность разнородности аппаратных ресурсов и вычислительных платформ, на которых функционирует указанное ПО. Существуют различные варианты решения проблемы информационного поиска. Первый вариант – реализация локальных поисковых подсистем в каждом информационном модуле ИАС предприятия. Достоинство такого подхода – простота реализации, недостатки – невозможность поиска по нескольким источникам из единой точки доступа, сложность модификации и обновления системы, высокая стоимость администрирования и настройки. Необходима реализация системы, позволяющей организовать доступ к гетерогенным территориально распределенным источникам информации. Среди современных технологий построения корпоративных информационных систем с подобными характеристиками, по мнению авторов, стоит выделить сервисную и агентную архитектуру. Агентная архитектура имеет ряд преимуществ при решении подобного класса задач [3], поэтому для создания распределенной системы поиска информации в масштабах предприятия имеет смысл использовать именно агентный подход. Неформальная схема мультиагентной системы поиска информации представлена на рисунке 1. Пользователь осуществляет взаимодействие с системой посредством персонального агента пользователя. Запросы пользователя перенаправляются поисковым агентам, реализующим конкретные алгоритмы поиска (на схеме рис. 1 это алгоритм по Интегрированный подход к решению задач создания агентно-ориентированных систем предлагает методология проектирования мультиагентных интеллектуальных систем (МАИС) [5]. Данная методология основывается на теории информационных объектов и охватывает все основные этапы процесса создания распределенной интеллектуальной системы. Она имеет комплексный и завершенный характер, так как рассматривает построение систем такого класса на всех необходимых уровнях описания, начиная от обобщения концептуальной модели предметной области и заканчивая моделью информационного объекта, взаимодействующего с конкретным корпоративным приложением. Предлагаемая методология проектирования МАИС включает следующие этапы: идентификация предметной области (ПрО), извлечение знаний о ПрО, структурирование знаний о ПрО, формализация, реализация, отладка и тестирование. На этапе структурирования знаний о ПрО применяется подход, при котором структуры фреймов соединяются с конструкциями концептуальных графов, образуя концептуальную модель ПрО (КМПрО). Формально КМПрО определяется как KM=(F, m, R, F, Y), где F={ФK} – множество фрейм-концептов (ФК); m={M} – множество модулей концептуальных графов; R={KO} – множество концептуальных отношений; F – отображение F×R→F; Y – отображение F→m, такое, что каждому ФК Fkij может быть поставлено в соответствие некоторое подмножество из множества m, то есть m′={М1, …, Мn}, m′Ím. ФК представляет собой фреймоподобную структуру вида FK=(ИФ, ТФ, ИП, ССП, ССЛ), где ИФ – имя фрейма; ТФ – тип фрейма; ИП – информация о применении (неформальное вербальное описание); ССП – структура сценариев поведения; ССЛ – структура слотов. Динамическое поведение компонентов ПрО описывается структурой сценариев поведения фреймов, позволяющей формировать альтернативные пути поведения каждого фрейма. Структура слотов представляет собой совокупность двух структур: ССЛ=(CK, CA), где СК – структура концептов; СА – структура атрибутов. Структура концептов содержит список ФК, в некотором отношении вложенных или порожденных охватывающим ФК: CK={(ИК1, КО1), (ИК2, КО2), …, (ИКn, КОn)}, где ИКi – имя концепта; КОi – тип концептуального отношения концепта ИКi к данному ФК. Структура атрибутов представляет собой следующее множество: CА={(ИА1, МО1, ЗА1), (ИА2, МО2, ЗА2), …, (ИАm, МОm, ЗАm)}, где ИАi – имя i-го атрибута; МОi – область определения атрибута; ЗАi – значение атрибута. Для установления логической организации ПрО ФК соединяются в структуры концептуальных графов, имеющие два типа вершин: вершины концептов и вершины концептуальных отношений. На начальной стадии концептуализации строится сеть ФК по вложению концептов, принимающая во внимание только структурный аспект ПрО: KM(FK)=(F, R, F). Логические взаимосвязи ФК КМПрО описываются концептуальным графом, в котором дуги связывают концептуальные отношения и ФК, входящие в них. Выделим следующие ФК в ПрО информационного поиска на промышленном предприятии. ФК «Запрос» можно представить в следующем виде: FKзапр=("Запрос", Query, "Запрос_данных", Æ, (CKзапрос, CAнастр)). У него есть один атрибут CAзапр={Текст, String, ЗН}. Здесь и далее будем описывать схемы атрибутов, а не сами конкретные атрибуты. Поэтому в качестве значения используем обозначение ЗН, которое может быть заменено конкретным значением при заполнении соответствующего ФК. Запрос состоит с множеством вложенных настроек в отношении Содержит: CКзапрос={(Настройка1, Содержит), …, (Настройка1, Содержит)}. Запрос может иметь множество вложенных настроек. При этом ФК «Настройка» имеет вид FКнастр=("Настройка", Setting, "Входные_параметры", Æ, (Æ, CAнастр)), CAнастр={(Св1, Binary, ЗН1), …, (Свn, Binary, ЗНn)}, где Св1, …, Свn – множество имен значений свойств настройки; Binary – множество бинарных объектов, типизация которых выполняется алгоритмом. Ввиду многообразия языков представления знаний целесообразно выделить отдельный элемент обработки лингвистической информации. Назовем этот ФК «Лингвист». Важным параметром является множество языков, которые могут обрабатываться данным концептом. Формально концепт «Лингвист» определим так: FКлинг=("Лингвист", Ling, "Обработка_языковых_ данных", СППлинг, (Æ, САлинг)), САлинг={(Яз1, Boolean, ЗН1), …, (Язk, Boolean, ЗНk)}, СППлинг={МорфАнализ, СинАнализ}, где Яз1, …, Язk – множество обозначений языков; Boolean – тип истинного значения; МорфАнализ – сценарий поведения, реализующий морфологический анализ; СинАнализ – сценарий поведения, реализующий синтаксический анализ. В качестве обозначений языков могут выступать их стандарти- зированные буквенные коды. При поддержке со- ответствующего языка логическое поле фрейма становится равным true. Результатами применения поведений МорфАнализ, СинАнализ могут представляться в различной форме. ФК «Текст» имеет следующее формальное представление: FКтекст=("Текст", Text, "Текст_ на_ЕЯ", Æ, (Æ, САтекст)), САтекст={(Название, String, ЗН1), Авт, (URI, String, ЗН2), (Содержание, String, ЗН3)}, Авт={(Автор1, String, ЗН1), …, (Авторn, String, ЗНn)}. В данном случае взят минимальный набор атрибутов текста. Для электронного документа такой набор может быть достаточно обширным. Все тексты находятся в некотором информационном ресурсе, который представляется в данном случае как ФК «Хранилище». Можно сказать, что хранилище находится в отношении Содержит к ФК «Текст»: FКхран=("Хранилище", Storage, "Место_хранения_текстов", СППхран, (СКхран, СА хран)), САхран={(Имя, String, ЗН1), (Tun, String, ЗН)}, СКхран={(Текст1, Содержит), …, (Текстn, Содержит)}, ССПхран={ПолучитьТекст}, где Тип – строковое обозначение хранилища, используемое для определения способа доступа к нему; ПолучитьТекст – операция извлечения текста из хранилища на основе его URI. При организации поиска важное место отводится индексу. ФК «Индекс» может представлять собой произвольную структуру. К настоящему моменту известно множество методов построения индексов для разных целей. Если необходимая служебная информация содержится в индексе, то текст находится с этим индексом в бинарном отношении Индексирован. В данном случае представим ФК «Индекс» следующим образом: FКинд =("Индекс", Index, "Индекс_для_информационного_поиска", Æ, (СКинд, САинд)), САинд={(Имя, String, ЗН1), (Тип, String, ЗН2), (СлИнф1, Binary, ЗН3), …, (СлИнфn, Binary, ЗНn+3)}, СКинд={(Текст1, Индексирован), …, (Текстn, Индексирован)}, где СлИнфi – служебная информация в j-м индексе (в общем случае в бинарном виде), хранимая индексом для текста Текстi, причем $ (Текст, Индексирован)Î Î Индекс используется определенным поисковым алгоритмом. «АлгоритмП» является ФК, инкапсулирующим конкретный способ поиска интересующих текстов. Один алгоритм может использовать несколько индексов и ФК лингвистической обработки. ФК «АлгоритмП» можно представить в следующем виде: FКалгП=("Алгоритм", SearchAlg, "Алгоритм_поиска", СППалгП, (СКалгП, САалгП)), САалгП={(Имя, String, ЗН)}, СКалгП={(Лингвист1, Использовать), …, (Лингвистk, Использовать), (Индекс1, Использовать), …, (Индексm, Использовать)}, ССПалгП={Найти}, где Найти – сценарий поведения, реализуемый конкретным алгоритмом. ФК «Пользователь» представляет пользователя поисковой системы. Пользователь должен иметь имя и идентификатор в системе. Имя используется для отображения в различных вариантах пользовательского интерфейса, идентификатор пользователя – для однозначного определения данного пользователя. Цели такого определения могут быть различными: проверка прав доступа, персонализация настроек, учет и отображение истории запросов и т.д. Для обоих атрибутов можно использовать строковый тип данных. Формально ФК «Пользователь» представим в следующем виде: FКпольз=("Пользователь", User, "Пользователь_системы", Æ, (СКпольз, САпольз)), САпольз={(Ид, String, ЗН)}, СКпольз={(Запрос1, Формировать), …, (Запросn, Формировать), (АлгоритмП1, Выбирать), …, (АлгоритмПk, Выбирать)}. ФК «Пользователь» состоит в отношении Формировать с ФК «Запрос». При формировании запроса пользователь изменяет настройки запроса (ФК «Настройка»), но эта связь не показана, чтобы не перегружать концептуальную модель.
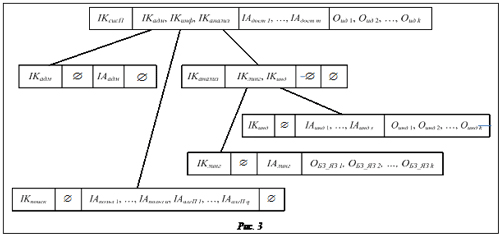
Формализация представляет собой процесс трансляции КМПрО в логическую модель МАИС. В основе логической модели лежит дерево имен концепта IIK, представляющее собой связный неориентированный граф без циклов, вершинами которого являются имена концепта МАИС (IKi, …, IKj, …, IKij…). Дуги графа соединяют имя концепта с другими именами концепта вышестоящего или нижестоящего уровней. С каждым именем концепта связывается его формальная объектная структура: IKi=(IKi1, IKi2, …, IKin; IAi1, IAi2, …, IAim; Oi1, Oi2, …, Oik;), где IKi – интеллектуальный компонент; IAi – интеллектуальный агент; Oi – интеллектуальный объект. Информационный объект – это структура вида O=(NO, {A}, {O}, BM), где NO – имя объекта; {A} – множество атрибутов объекта; {O} – множество объектов, структурно вложенных в данный объект; BM – модель поведения информационного объекта. Атрибут информационного объекта определяется как A=(NA, SA, VA), где NA – имя атрибута; SA – область определения; VA – значение атри- бута. Таким образом, дерево имен концепта является связующим звеном между логической и объектной структурами МАИС. Процесс формализации заключается в выделении интеллектуальных компонентов, построении дерева имен концепта TIK, декомпозиции сети ФК по дереву имен концепта, трансляции дерева ФК в логическую модель МАИС (TFK в T(IK, IA, IO)) и построении БЗ имен концепта. Задача выделения интеллектуальных компонентов состоит в декомпозиции КМПрО на связанные подобласти, которые будут представляться в логической модели интеллектуальными компонентами и их ФОС. Далее сеть ФК связывается с деревьями IIK – выполняется декомпозиция сети ФК по дереву имен концепта. Корневым элементом дерева будет системный компонент, олицетворяющий поисковую систему в целом: IKсисП=(IKадм, IKанлиз, IKпоиск; IAдост1, …, IAдостМ; Oид1, Oид2, …, OидK), Oид =(ИстДанных′, {Свойствоj′}, {Æ}, ПредоставитьРесурс). Этот наиболее абстрактный уровень содержит описание фактически внешних по отношению к системе объектов, которыми являются источники данных Oид. Выделение источников данных необходимо именно на этом абстрактном уровне, так как они являются внешними по отношению к системе, но принимают непосредственное участие в ее функционировании. Источники данных имеют набор свойств Свойствоji (в общем случае бинарных), которые интерпретируются при конкретных реализациях ресурсов. Информационный объект источника данных реализует лишь поведение по предоставлении конкретного ресурса. Информационные ресурсы, как уже отмечалось, могут быть разнородными по своей природе. Соответственно, будут разниться и интерфейсы доступа к ним. Для унификации доступа к произвольным ресурсам вводятся интеллектуальные агенты доступа IAдост, скрывающие специфические методы взаимодействия с ресурсом и предоставляющие общую функциональность для других агентов системы. В некоторых случаях выделение такого агента нецелесообразно, например, при доступе к ресурсам, уже реализующим некоторый общий интерфейс (в качестве веб-сервисов или агентных реализаций). Поэтому количество агентов доступа может отличаться от количества ресурсов. Агенты доступа могут выполнять и задачи протоколирования, профилирования и разграничения доступа. Интеллектуальный компонент администрирования формально представим как IKадм=(Æ; IAадм, …, IAадмК; Æ). Это структурно наиболее простой интеллектуальный компонент, состоящий из агентов-администраторов, позволяющих настраивать различные параметры функционирования других компонентов. Компонент анализа состоит из лингвистической и индексирующей составляющих: IKанализ= =(IKлинг, IKинд; Æ; Æ). Лингвистическая составляющая представляется следующим образом: IKлинг=(Æ; IАлинг; ОБЗ_ЯЗ1, ОБЗ_ЯЗ2, …, ОБЗ_ЯЗN), ОБЗ_ЯЗi = (База_языкаi, {Морфi, Синтаксисi}, Æ, Æ). Лингвистический интеллектуальный компонент содержит информационные объекты для каждого языка. Такие объекты включают всю необходимую информацию о конкретных языках (об их морфологии и синтаксисе).
По отношению к источнику данных индексы Oинд могут быть как внешними, так и внутренними. Если в качестве источника данных выступает БД с внутренними инструментами индексирования, то из соображений скорости поиска такой индекс логично сделать внутренним. Если же источник данных не предоставляет средства семантической индексации, индекс может быть внешним по отношению к ресурсу. Интеллектуальный компонент поиска состоит из двух объектов-агентов: IKпоиск=(Æ; IАпольз1, …, IАпользU, IАалгП1, …, IАалгПQ). Агенты пользователя IAпольз реализуют пользовательский интерфейс для пользователя-человека. Агенты IAалгП осуществляют поиск информации согласно соответствующему алгоритму поиска на основе индекса или без него. Графически дерево имен концепта системы семантического поиска можно представить в виде схемы, изображенной на рисунке 3. Предлагаемый вариант реализации поисковой системы для промышленного предприятия отличается масштабируемостью, хорошей формали- зацией компонентов и небольшой стоимостью разработки. При этом система поиска может функционировать как самостоятельно, так и внутри корпоративных агентных сообществ и использоваться в большинстве существующих поисковых алгоритмов. Литература 1. Костров А.В., Александров Д.В. Уроки информационного менеджмента. Практикум: учеб. пособие. М.: Финансы и статистика, 2005. 304 с. 2. Автоматизированные информационные технологии в экономике / М.И. Семенов [и др.]; [под общ. ред. И.Т. Трубилина]. М.: Финансы и статистика, 2000. 416 с. 3. Летовальцев В.И., Швецов А.Н. Сравнение агентного и сервис-ориентированного подходов к созданию распределенных приложений // Информационные технологии в проектировании и производстве. 2009. № 2. C. 66–71. 4. Швецов А.Н., Летовальцев В.И. Семантическая обработка текста на основе интенсиональной логики для проведения информационного поиска / Интеллектуальные системы: тр. IX Междунар. симпоз.; [под ред. К.А. Пупкова]. М.: РУСАКИ, 2010. С. 146–150. 5. Швецов А.Н. Метаметодология построения мультиагентных интеллектуальных систем // Информационные технологии в проектировании и производстве. 2010. № 1. C. 28–33. |
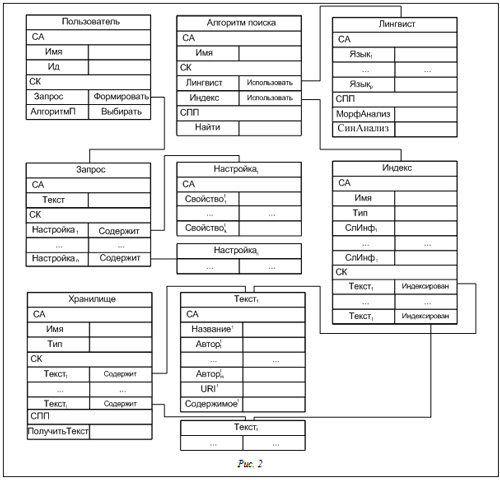
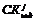 .
.
| Постоянный адрес статьи: http://swsys.ru/index.php?id=3114&like=1&page=article |
Версия для печати Выпуск в формате PDF (5.19Мб) Скачать обложку в формате PDF (1.31Мб) |
| Статья опубликована в выпуске журнала № 2 за 2012 год. [ на стр. 63 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Метод минимизации межузловых взаимодействий в одноранговых проблемно-ориентированных распределенных системах
- VMASTER – среда для разработки и верификации вероятностных мультиагентных систем
- Формальная модель многоагентных систем для федеративного обучения
- Искусственные миры: пространственная организация
- Облачная платформа IACPaaS для разработки оболочек интеллектуальных сервисов: состояние и перспективы развития
Назад, к списку статей