Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Роль стохастического тестирования в функциональной верификации микропроцессоров
Аннотация:С ростом требований к характеристикам современных ИС, в том числе микропроцессоров и систем на кристалле, существенно усложняется их проектирование. Оно превратилось в многоступенчатый процесс, на каждой стадии ко-торого от разработчиков требуется решение все более и более сложных задач. Одной из самых трудоемких из них является функциональная верификация проекта. Задача заключается в установлении соответствия между некоторым уровнем реализации проекта и функциональными требованиями его спецификации. Для проектов ИС современного уровня сложности отсутствует универсальный способ функциональной верификации, однако существует несколько взаимодополняющих подходов к проблеме. Одним из методов, применяемых в НИИСИ РАН при разработке микро-процессоров архитектуры MIPS64, является стохастическое тестирование. В его основе лежит симуляция выполнения тестовых программ на модели микропроцессора. Тесты (тестовые программы) генерируются автоматически по заданному шаблону с параметризованным случайным выбором инструкций тела теста и их аргументов. В данной статье уделяется внимание роли метода стохастического тестирования, области его применения, преимуществам и недостаткам. Функциональная верификация рассматривается как составная часть процесса проектирования ИС. Описываются наиболее известные в мировой практике подходы к верификации и коротко рассматриваются лежащие в их основе идеи. Дается информация о классе методов, основанных на симуляции, и методе стохастического тести-рования. Делаются выводы о преимуществах и недостатках данного метода, иллюстрируемые некоторыми результа-тами его применения в НИИСИ.
Abstract:With the growth of the performance requirements of modern IC, including microprocessors and Systems-on-Chip, their development complicates considerably. It has become a multistage process, and there are many sophisticated tasks to be done on each stage. One of the most labor-consuming tasks is design functional verification. Its goal is to approve a conformity between implementation of a design and it's specification functional requirements. While it does not yet have a general solution, considering modern IC designs complexity, several complementary approaches were developed to address it. One of them is stochastic testing. It was applied for researching of the MIPS64 architecture microprocessors in Science research Institute for system analysis of RAS. The method is based on the test program execution simulation. Test programs are generated automatically from the given template. Instructions, arguments and settings for the test are chosen randomly considering given biases and constraints. This paper is a review, aiming at specifying the role of stochastic testing with its application scope, advantages and disadvantages. In the introduction functional verification is considered in general, as a part of IC design workflow. Then, most well-known verification approaches are reviewed, their underlying ideas analyzed briefly. Particularly, simulation-based methods are considered. Finally, stochastic testing method is described in the given background. Conclusions concerning its advantages and disadvantages are illustrated with some results of its application in SRISA RAS.
| Авторы: Хисамбеев И.Ш. (osipa68@yahoo.com) - НИИСИ РАН, г. Москва | |
| Ключевые слова: метрики тестового покрытия., генерация случайных тестов, стохастическое тестирование, симуляция, rtl-модель, функциональная верификация, микропроцессор |
|
| Keywords: test coverage metrics, random test generation, stochastic testing, simulation, RTL model, functional verification, microprocessor |
|
| Количество просмотров: 12004 |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
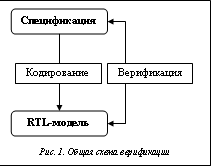
Разработка современных микропроцессоров (МП) и систем на кристалле (СнК) представляет собой сложный многоступенчатый процесс, в котором заняты большие коллективы. Стадии данного процесса – это переходы между уровнями представления проекта в сторону понижения уровня абстракции. Так, в соответствии с техническим заданием уточняется спецификация архитектуры, обычно в виде текстового документа с описанием. Согласно спецификации разрабатывается модель уровня регистровых передач (register-transfer level, RTL). Далее последовательно используется комплекс средств автоматизации проектирования разработки (electronic design automation tools, EDA, САПР) для получения менее абстрактных представлений: таблицы соединений (gate-level netlist) и файла топологии элементов (physical layout), которые принимает завод для изготовления фотошаблонов. Изготовленная в кремнии ИС с этой точки зрения представляет собой окончательный уровень представления проекта. Каждый переход между уровнями представления может быть выполнен с ошибками и требует верификации, то есть установления соответствия этих представлений друг другу. Например, под функциональной верификацией RTL-модели устройства понимается проверка предположения, что она вполне удовлетворяет функциональным требованиям спецификации архитектуры (рис. 1). В хорошо поставленном процессе разработки на функциональную верификацию направляется до 70 % от общих усилий [1]. Это обусловлено следующим. Во-первых, написание RTL-модели – наименее формализованный и автоматизированный шаг разработки, а значит, порождающий максимальное число ошибок. Во-вторых, исправление ошибок на этом шаге наиболее эффективно с точки зрения финансовых и трудовых затрат. Рассмотрим функциональную верификацию RTL-моделей МП и СнК (далее – верификацию). Для общей картины добавим лишь, что в верификации следующих за RTL-моделью уровней представления проекта применяется известный набор технологий, в основном специфичных для того или иного шага разработки (например, equivalence checking, LVS, DRC, scan-based testing). Эта статья посвящена реализации одного из популярных методов верификации RTL-моделей МП – метода стохастического тестирования [2, 3]. Обзор некоторых методов верификации Задачу функциональной верификации можно сформулировать так. Для данной RTL-модели устройства найти валидную комбинацию начального состояния и последовательности входных сигналов, такую, в которой выходные сигналы модели будут противоречить тем или иным требованиям спецификации устройства (найти ошибку), или показать, что такой комбинации нет. Теоретически при достаточно формализованной спецификации задача сведется [4] к известной в теории алгоритмов задаче выполнимости булевых формул (SAT), которая в общем виде согласно теореме Кука–Левина относится к классу NP-полных задач.
Тем не менее существуют и развиваются множество методов, которые позволяют эффективно решать задачу верификации в ее практической постановке: дать разработчику уверенность в отсутствии логических ошибок в работе опытного образца (bug-free first silicon). Опишем коротко наиболее известные из них. Средства статического анализа кода (linting tools) выявляют в синтаксически корректном коде RTL-модели подозрительные фрагменты и конструкции, тем самым быстро находя ошибки, связанные с невнимательностью, плохим стилем и т.п. Очевидно, нельзя считать эти средства достаточными для верификации, но как необходимый инструмент первичной проверки модели они давно себя зарекомендовали.
Метод формальной проверки свойств модели (model checking, property checking, assertion checking) близок к предыдущему и заключается в том, что спецификация проекта (вся или наиболее важные аспекты) переводится на формальный язык утверждений/свойств (assertions/properties). В частности, задаются ограничения (constraints) на наборы значений входных параметров модели. Затем с использованием эвристических решателей для каждого свойства делается попытка подтвердить его для всех наборов входов или опровергнуть. На практике метод находит применение для создания небольших проектов или отдельных блоков сложного проекта, причем таких, спецификация которых легко и надежно переводится на формальный язык. Метод автоматизированного или интерактивного доказательства теорем (automated theorem proving/proof assistants) в принципе схож с методом проверки свойств, но в его реализации используется другой математический аппарат – логика предикатов. Вышеописанные методы в совокупности принято называть формальными методами верификации. Их хватило бы для исчерпывающего решения задачи верификации, так как достаточность включена в постановку задачи метода. Но мировая практика в отрасли подтверждает наличие препятствий, а именно трудности формализации и вычислительной сложности. Рассмотрим класс методов, который без преувеличения можно считать основным и важнейшим для широкого индустриального применения. Это методы, основанные на симуляции (simulation-based verification). Их основная идея следует из названия: работа устройства, которое представлено RTL-моделью, симулируется специальной программой – RTL-симулятором. При этом испытываются тестовые воздействия, или стимулы (разные последовательности наборов значений входных сигналов модели), и анализируются отклики, или реакции (изменения состояния модели и значений ее выходных сигналов) (рис. 2). К данному классу относится и метод стохастического тестирования, реализованный в НИИСИ РАН в системах INTEG [2] и INTEG2 [3]. Наконец, в последние годы развиваются гибридные техники, в которых симуляция комбинируется с формальными методами для использования преимуществ обоих подходов [5]. Различия методов, основанных на симуляции Существуют разнообразные методы, основанные на симуляции, которые при сохранении общей сути значительно отличаются в реализации. Эти различия определяют область применения того или иного метода и возникают при уточнении ряда принципиальных параметров, таких как объект верификации, уровень абстракции модели, устройство тестовых воздействий, выбор тестовых воздействий, набор снимаемых с модели откликов, критерий корректности откликов, критерий полноты верификации. Рассмотрим подробнее эти вопросы и некоторые известные варианты их решения. Выбор объекта верификации. Выбор эффективного метода существенно зависит от того, какое устройство необходимо верифицировать. Это могут быть отдельный блок в составе сложного устройства, функционально выделенный интерфейс, ядро микропроцессора в целом или даже вся система на кристалле. Выбор уровня абстракции модели. В большинстве методов симуляция применяется к RTL-модели, но есть подходы, использующие как менее абстрактные (например gate-level netlist), так и более абстрактные (например модели уровня транзакций [6]) уровни представления устройства. Устройство тестовых воздействий. В зависимости от выбранного объекта верификации состав и детализация стимулов будут различными. Для простых блоков без внутреннего состояния стимулами будут простые комбинации входных сигналов. Для устройств с более сложной работой, например межшинных мостов, стимулы могут быть устроены сложнее, состоять из разнесенных во времени последовательностей сигналов и учитывать внутреннее состояние устройства. При верификации целого микропроцессора пространство внутренних состояний и входных воздействий настолько велико, что практически недостижимо все детализировать в составе одного стимула. Чаще (в том числе в INTEG и INTEG2) применяется другой подход: в качестве тестового воздействия рассматривается последовательность команд архитектуры процессора, то есть тестовая программа. Предполагается, что любую значимую для реальной работы комбинацию входных воздействий и внутренних состояний можно получить при выполнении конечной последовательности команд процессора. Принцип выбора тестовых воздействий. Если мощность множества стимулов и вычислительная стоимость обработки каждого стимула достаточно малы, применяется полный перебор. В других случаях необходимо определить, какие стимулы выбрать и в каком порядке подавать их на модель. В методах, применяющих ручную работу, может предполагаться задание отдельных интересных стимулов вручную. Другие варианты: выделение классов стимулов и перебор классов, а также параметризованный случайный выбор. Выбор значимых параметров и откликов модели. Аналогично устройству стимулов детальность отслеживаемых реакций зависит от сложности объекта верификации. Для небольших моделей может использоваться принцип черного ящика, согласно которому значимыми являются только идущие наружу блока сигналы. Для такого сложного устройства, как процессор в целом, целесообразно отслеживать детали состояния модели и внутренние взаимодействия составляющих ее блоков. Выбор критерия и способа контроля корректности полученных откликов. Наиболее прямым способом является непосредственная проверка корректности реакции на тот или иной стимул. Но очевидно, что из-за трудоемкости этот вариант неприемлем при сколько-нибудь масштабной автоматизированной подаче стимулов. Другой способ – дополнение кода модели особыми утверждениями (assertions) на специальном языке. Сигналом об ошибочной работе модели считается невыполнение в какой-то момент того или иного утверждения. Наконец, распространенный метод – использование второй модели обычно более высокого уровня абстракции. Такая модель называется поведенческой и создается отдельно по архитектурной спецификации проекта на языках общего назначения (C, C++) или языках системного проектирования (SystemC, SystemVerilog). Выбор критерия полноты метода. В случае, когда множество возможных стимулов перебирается заведомо не полностью, а время и ресурсы на функциональную верификацию недостаточны, необходимо ввести другой критерий завершенности процесса. В этой роли выступают метрики верификации [7]. Метрики имеют различную природу. При отсутствии других критериев, а чаще в совокупности с ними, используются метрики, основанные на статистике выявленных ошибок. При снижении частоты появления новых ошибок до определенного значения (пример: отсутствие ошибок при симуляции 4∙1010 тактов работы процессора) верификация завершается. Другая часто используемая метрика, взятая из арсенала верификации ПО, – метрика структурного покрытия кода (code coverage). Суть ее в том, что при отработке на модели того или иного тестового воздействия специальный инструмент собирает информацию о том, какие фрагменты кода модели были задействованы. Фрагментами кода считаются блоки операторов, пути выполнения условных операторов, достижения выражениями определенных значений и другие. Значение метрики – отношение числа задействованных набором тестов фрагментов к общему числу фрагментов. Заметим, что эта метрика задает, скорее, необходимый признак успешной верификации. Достаточным он не является, так как метрика не привязана к функциональным требованиям проекта и не будет ничего знать об упущенной в коде функциональности. В качестве дополнительного критерия полноты выступают метрики функционального покрытия. Идея состоит во внешнем построении пространства тестовых ситуаций, то есть функционально значимых комбинаций входных воздействий и состояний мо- дели. Отличие такого пространства ситуаций от пространства значимых стимулов заключается именно в его явном внешнем задании, хотя в некоторых случаях они могут совпадать. Конкретные способы задания такого пространства различаются по уровню абстракции, на котором описываются тестовые ситуации. В распространенной методологии UVM/OVM функциональное покрытие задается на основе конструкций, дополняющих модель целевого блока [8]. Можно предложить и другой способ: построение пространства тестовых ситуаций в терминах поведенческой модели, то есть на уровне комбинаций поданных на исполнение инструкций. Метод стохастического тестирования Стохастическое тестирование [3] применяется для функциональной верификации микропроцессоров. В основе метода лежит симуляция выполнения тестовых программ на RTL-модели МП. Тесты (тестовые программы) генерируются автоматически по заданному шаблону с параметризованным случайным выбором инструкций тела теста и их аргументов. На вход тестируемой модели тесты подаются в виде образа памяти, содержащего последовательность подлежащих выполнению инструкций, а также блоки необходимых данных. Для контроля корректности выполнения теста используется поведенческая модель процессора, написанная на языке C. Прохождение теста симулируется на обеих моделях, а затем сравниваются полученные отклики в виде лог-файлов выполненных инструкций, записей в регистровые файлы, обращений в кэш-память и ОЗУ. Возникновение расхождений в работе моделей означает наличие ошибки. Найденные уникальные ошибки образуют базу регрессионного тестирования. Для контроля полноты используется сочетание нескольких метрик. Во-первых, ведется статистика нахождения новых ошибок. Во-вторых, при прохождении баз регрессии снимается структурное покрытие кода RTL-модели. В-третьих, разработано несколько инструментов анализа лог-файлов на наличие отдельных тестовых ситуаций. Хотя их использование не дает полноценной метрики, оно является первым шагом в сторону разработки собственной системы задания и анализа функционального тестового покрытия.
Из недостатков и ограничений метода выделим следующие. Значения метрики структурного покрытия показали, что достижение всех состояний некоторых внутренних блоков является трудной задачей, если тестовые воздействия применяются на процессор в целом. Это означает, что детальности задаваемых стимулов не всегда достаточно. Затруднена и обратная связь по выбранным типам метрик. То есть при необходимости достичь того или иного элемента структурного покрытия не всегда получается решить, какой шаблон тестовой программы сможет это сделать. Описанный метод применяется в НИИСИ РАН на протяжении нескольких лет для верификации семейства микропроцессоров архитектуры MIPS64. При этом система тестирования разрабатывается и развивается параллельно с разработкой моделей самих МП. Приведем диаграмму, показывающую количество найденных с помощью описанного метода уникальных ошибок в RTL (рис. 3). Ошибки, возникшие вторично при регрессионном тестировании, а также ошибки, имеющие ту же причину, что ранее найденные, в расчет не брались. В заключение отметим, что метод стохастического тестирования при всех своих преимуществах и широте использования является лишь одним из целого арсенала известных методов функ- циональной верификации. Основная область его применения – масштабное тестирование проекта микропроцессора, отлаженного в первом приближении более простыми тестами. Для более углубленной верификации отдельных блоков и критических мест в функциональности пока более эффективны другие методы, в большей степени опирающиеся на полное тестовое покрытие. Таким образом, описанный метод наиболее успешно работает в связке с дополняющими его. И все-таки планы развития метода предполагают устранение многих его ограничений и слабых мест. Литература 1. Bergeron J. Writing Testbenches using SystemVerilog. Springer, 2006. 2. Стохастическое тестирование в системе INTEG / Грибков И.В., Захаров А.В., Кольцов П.П. [и др.] // Програм- мные продукты и системы. 2007. № 2. С. 22–26. 3. Развитие системы стохастического тестирования микропроцессоров INTEG / Грибков И.В., Захаров А.В., Кольцов П.П. [и др.] // Программные продукты и системы. 2010. № 2. С. 14–23. 4. Drechsler R. Advanced Formal Verification. Kluwer Academic Publishers, 2004. 5. Jayanta Bhadra, Magdy Abadir, Li-C. Wang, Sandip Ray, A Survey of Hybrid Techniques for Functional Verification // IEEE Design and Test of Computers (IEEE D&T). Т. 24. № 2, март–апрель 2007. С. 112–122. 6. Cai L., Gajski D. Transaction Level Modeling: An Overview // сб. докл. Int. Conference on HW/SW Codesign and System Synthesis (CODES-ISSS). 2003. С. 19–24. 7. Piziali A. Functional Verification Coverage Measurement and Analysis. Kluwer Academic Publishers, 2004. 8. URL: http://www.verificationacademy.com/verification-methodology (дата обращения: 17.05.2012). |
 Таким образом, полная верификация сталкивается с двумя практически непреодолимыми препятствиями. Во-первых, исходно необходима полностью формальная или легко поддающаяся формализации спецификация устройства. Это условие крайне редко выполняется в практике разработки МП и СнК. Во-вторых, строгое решение задачи подвержено эффекту комбинаторного взрыва: для верификации современных проектов МП и СнК потребуются столетия на вычисления!
Таким образом, полная верификация сталкивается с двумя практически непреодолимыми препятствиями. Во-первых, исходно необходима полностью формальная или легко поддающаяся формализации спецификация устройства. Это условие крайне редко выполняется в практике разработки МП и СнК. Во-вторых, строгое решение задачи подвержено эффекту комбинаторного взрыва: для верификации современных проектов МП и СнК потребуются столетия на вычисления!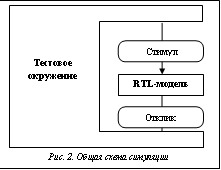 Метод проверки эквивалентности моделей (equivalency checking) рассматривает две формальные модели уровня RTL или gate-level netlist и устанавливает или опровергает одинаковость их поведения. В реализациях метода используются высокопроизводительные эвристические решатели (SAT solvers), так как для описаний таких уровней задача сводится к SAT. Хотя метод чаще применяется на стадии синтеза проекта, он подходит также для проверки функциональной эквивалентности двух RTL-моделей. Например, можно проверить внесенные в код правки, которые не должны влиять на функциональность.
Метод проверки эквивалентности моделей (equivalency checking) рассматривает две формальные модели уровня RTL или gate-level netlist и устанавливает или опровергает одинаковость их поведения. В реализациях метода используются высокопроизводительные эвристические решатели (SAT solvers), так как для описаний таких уровней задача сводится к SAT. Хотя метод чаще применяется на стадии синтеза проекта, он подходит также для проверки функциональной эквивалентности двух RTL-моделей. Например, можно проверить внесенные в код правки, которые не должны влиять на функциональность.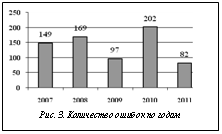 Можно указать следующие преимущества метода стохастического тестирования. Во-первых, задание тестовых воздействий на модель в виде исполняемых программ позволяет приближаться к реальным условиям использования устройства. Во-вторых, выбранный способ съема реакций модели дает достаточную информацию о ее внутренней работе для точной локализации большинства найденных ошибок. В-третьих, гибкость описания шаблонов тестов позволяет методу широко охватывать функциональность тестируемого проекта, а простота их написания позволяет работать с методом одновременно большому количеству специалистов. В-четвертых, массированный автоматизированный запуск обеспечивает регулярное нахождение ошибок в новых проектах и достигает редких ошибочных ситуаций в уже отлаженных.
Можно указать следующие преимущества метода стохастического тестирования. Во-первых, задание тестовых воздействий на модель в виде исполняемых программ позволяет приближаться к реальным условиям использования устройства. Во-вторых, выбранный способ съема реакций модели дает достаточную информацию о ее внутренней работе для точной локализации большинства найденных ошибок. В-третьих, гибкость описания шаблонов тестов позволяет методу широко охватывать функциональность тестируемого проекта, а простота их написания позволяет работать с методом одновременно большому количеству специалистов. В-четвертых, массированный автоматизированный запуск обеспечивает регулярное нахождение ошибок в новых проектах и достигает редких ошибочных ситуаций в уже отлаженных.| Постоянный адрес статьи: http://swsys.ru/index.php?id=3224&page=article |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
| Статья опубликована в выпуске журнала № 3 за 2012 год. [ на стр. 107-112 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Развитие системы стохастического тестирования микропроцессоров INTEG
- Формальные методы верификации RTL-моделей сверхбольших интегральных схем
- Сравнение производительности отечественных и импортных микропроцессоров
- Проблемы создания высокотемпературных вычислительных систем
- Тестирование микропроцессоров и их RTL-моделей приложениями пользователя под ОС Linux
Назад, к списку статей