Адаптивная компиляция на основе данных профилирования
| Вьюкова Н.И. (niva@niisi.msk.ru) - НИИСИ РАН, г. Москва, г. Москва, Россия, Галатенко В.А. (galat@niisi.msk.ru) - НИИСИ РАН, г. Москва (зав. сектором автоматизации программирования), г. Москва, Россия, кандидат физико-математических наук, Малиновский А.С. () - , Шмырев Н.В. (shmyrev@niisi.msk.ru) - Научно-исследовательский институт системных исследований РАН (НИИСИ РАН), г. Москва, кандидат физико-математических наук | |
| Ключевое слово: |
|
| Ключевое слово: |
|
|
|
|
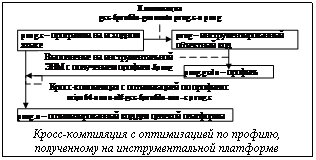
Современные компиляторы реализуют широкий спектр оптимизаций, обеспечивающих генерацию высокоэффективного кода для различных процессорных архитектур. Однако целесообразность выполнения той или иной оптимизации для данного фрагмента кода может зависеть не только от статических свойств программы, но и от динамических характеристик ее выполнения. Например, вынесение инвариантных вычислений из тела цикла, как правило, дает ускорение выполнения, однако если типичное число выполнений некоторого цикла равно нулю, то данная оптимизация лишь увеличит время выполнения программы. Существуют методы оценки динамических характеристик программы на основе статического анализа ее исходного кода, но достоверность результатов такого анализа невысока. Для решения этой проблемы в компиляторах применяются средства для получения профиля программы, который затем используется при оптимизации кода. Средства профилирования программ изначально разрабатывались как инструменты, позволяющие разработчику изучать профиль выполнения программы, чтобы вручную оптимизировать наиболее часто выполняемые (критические) фрагменты кода. Например, в критических участках кода программист мог вручную выполнить развертку (или конвейеризацию) циклов, подстановку коротких функций вместо их вызовов и др. Современные компиляторы способны автоматически выполнять подобные оптимизации с учетом данных профилирования, оставляя разработчику содержательную работу по совершенствованию алгоритмических решений. Более того, компиляторы выполняют с учетом профиля множество оптимизаций, недоступных программисту на уровне исходного кода, таких как глобальное планирование команд, распределение регистров и др. По результатам различных работ (см., например: J. Hubicka. Profile driven optimizations in gcc. In GCC Developers Summit Procedings. 2005.), повышение эффективности кода в результате применения оптимизаций по профилю может составлять 10-20 и более процентов. Виды профилей и их использование при оптимизации кода Существуют виды профилей, полезные для тех или иных оптимизаций. Профиль потока управления может быть представлен с различной степенью детализации: профиль функций содержит информацию о частоте выполнения отдельных функций, профиль базовых блоков – об ожидаемом числе выполнений каждого блока, профиль переходов – о вероятностях переходов (дуг графа управления), профиль путей – о частоте выполнения отдельных конечных путей в графе управления. Наиболее информативным является профиль путей, однако его сбор требует более высоких накладных расходов и его представление сложнее, чем для других видов профилей. По профилю переходов можно вычислить относительные частоты базовых блоков, но нельзя в общем случае получить профиль путей, поскольку вероятность перехода представлена в нем вне зависимости от предыстории выполнения. Тем не менее, именно профиль переходов чаще используется в компиляторах в качестве разумного компромисса между ценой и качеством. Профиль переходов более информативен, чем профиль блоков, притом что связанные с его сбором накладные расходы ненамного выше, чем для профиля блоков. Другой вид профиля – профиль значений – содержит информацию о значениях, принимаемых некоторыми программными выражениями, представляет собой гистограмму значений. Сбор профиля может быть реализован аппаратными и программными средствами. Преимущества аппаратной реализации – низкие накладные расходы и возможность получать профили приложений прозрачным для разработчика образом. Однако точность получаемого профиля может быть ниже, и могут быть доступны не все виды профилей. Преимущества программной реализации профилирования – гибкость и доступность требуемых видов профиля независимо от аппаратных возможностей процессора. Процедура для применения оптимизаций по профилю, собираемому программным способом, включает 3 шага: 1) инструментирование программы (компиляция программы выполняется с ключами, задающими сбор профиля); 2) сбор профиля (инструментированная программа выполняется с некоторыми типичными наборами входных данных, при этом накапливается и сохраняется ее профиль); 3) компиляция с использованием профиля, выполняющаяся с ключами, задающими использование профиля при оптимизациях. Помимо специальных оптимизаций, ориентированных на применение профиля, компилятор может использовать профиль для повышения эффективности многих традиционных оптимизаций. Профили переходов и частоты выполнения базовых блоков могут применяться для следующих целей: принятие решений о целесообразности применения таких оптимизаций, как inline-подстановка функций, развертка или пилинг цикла; выявление циклов, не оформленных в виде соответствующих языковых конструкций; трансформации циклов; распределение регистров; повышение локальности кода для эффективного использования кеша команд (переупорядочение функций и участков кода в соответствии с типичными последовательностями их выполнения); размещение функций (и даже отдельных фрагментов функций) в разных секциях в зависимости от частоты их выполнения (.text, .text.hot, .text.unlikely_executed). Профиль значений может использоваться такими оптимизациями, как: специализация операций; частичное применение функций; предвыборка данных; реорганизация циклов; повышение локальности данных для эффективного использования кеша (реорганизация структур, матриц); реализация операторов-переключателей (если значения выражения, по которому происходит переключение, распределены равномерно, то наиболее эффективной реализацией оператора является таблица переходов). Если же некоторые значения встречаются значительно чаще других, то предпочтительный способ реализации – последовательность условных переходов, упорядоченных по частоте соответствующих значений. Важный частный случай профиля значений – профиль зависимостей по памяти. При планировании потока команд (особенно при глобальном планировании и при конвейеризации циклов) зависимости по памяти препятствуют переносу команд загрузки выше предшествующих им команд записи. Поскольку команды загрузки часто оказываются на критическом пути, подобные зависимости ограничивают возможности генерации эффективного кода. Статический анализ программ часто не позволяет определить, что зависимость по памяти в данном случае фактически отсутствует, поэтому компилятор вынужден считаться с возможностью совпадения адресов в командах записи и чтения. Если профиль зависимостей показывает, что совпадение адресов для некоторой пары команд записи-чтения случается редко (или никогда), то компилятор может переместить чтение выше записи, добавив код для проверки адресов и выполнения компенсационных действий в случае совпадения адресов (который будет выполняться лишь в редких случаях). Наиболее эффективен данный подход при наличии аппаратной поддержки необходимых проверок в виде буфера конфликтов памяти (memory conflict buffer, MCB), однако возможна и программная реализация. Оптимизации по профилю в компиляторе gcc В gcc программный сбор профиля и оптимизации по профилю поддерживаются, начиная с версии 4.0. Используются профиль вероятностей переходов и профиль значений. В gcc реализована инструментовка выполняемой программы для сбора таких статистических характеристик, как: · счетчик числа выполнений базового блока; · счетчик числа выполнений перехода; · детектор степеней двойки – позволяет определить, что некоторое выражение принимает значения, равные степеням 2; · детектор единственного значения – позволяет определить, что некоторое выражение почти всегда принимает одно и то же значение; · детектор постоянной разницы – позволяет определить, что интервал между значениями, последовательно принимаемыми некоторым выражением, практически всегда постоянен; · детектор постоянного адреса вызова – позволяет определить, что адрес косвенного вызова функции с большой вероятностью принимает одно и то же значение; · счетчик среднего значения – вычисляет среднее значение выражения; · Во внутреннем представлении программы профиль потока управления хранится в виде полей структур, описывающих узлы и дуги графа потока управления (CFG – Control Flow Graph). Для базовых блоков поддерживаются поля счетчика и относительной частоты выполнения; для переходов – поля счетчика и вероятности перехода. При этом для базовых блоков поддерживаются предикаты maybe_ hot_p (часто выполняемый), probably_ cold_p (редко выполняемый) и probably_never_ executed (с большой вероятностью не будет выполнен ни разу). Проходы оптимизации в gcc были изменены таким образом, чтобы данные профилирования при всех преобразованиях CFG поддерживались в актуальном состоянии. Эти предикаты опрашиваются различными оптимизациями, которым важна информация об относительной частоте выполнения базовых блоков, поскольку они обеспечивают повышение эффективности кода за счет увеличения его размера. В gcc в настоящее время профиль потока управления используется при принятии решений о развертке и пилинге циклов, об inline-подстановках функций, при распределении регистров, для определении приоритетов выделения физических регистров виртуальным. Профиль значений хранится в виде аннотаций к элементам внутреннего представления программы. На основе профиля значений компилятором выполняются следующие оптимизации. · Специализация операций деления и взятия по модулю: если можно определить, что операнды имеют некоторые специальные значения, то можно реализовать эти дорогостоящие операции более эффективно. · Спекулятивная предвыборка данных: если можно определить, что интервалы между значениями адресных выражений, по которым производится обращение к памяти, постоянны, то в код добавляются инструкции предвыборки данных. · Специализация косвенных вызовов функций: если адрес вызова постоянен, то можно выполнить inline-подстановку вызываемой функции. · Специализация стандартных функций: если операнды таких функций, как memcpy, strcpy выровнены по границе слова, то для этих функций можно сформировать более эффективный код. Для всех оптимизаций по профилю значений компилятор формирует альтернативные ветви выполнения: добавляется проверка условия, при котором данная оптимизация применима, и код генерируется как для частного, так и для общего случаев. Для генерации инструментированного кода с целью получения профиля необходимо скомпилировать программу с ключом -fprofile-generate. Оптимизация кода по профилю осуществляется при задании ключа; важна информация об относительной частоте выполнения базовых блоков (если задан ключ -fprofile-use, а файлы с профилем отсутствуют, то компилятор будет использовать статические оценки частоты переходов). При этом возможно получение профиля на одной платформе и его использование при кросс-компиляции той же программы для другой платформы (важно, чтобы версии применяемых компиляторов совпадали). Эксперименты с компилятором gcc версии 3.4.5 и экспериментальный вариант gcc 4.2 для процессоров i686 под управлением ОС Linux (инструментальная платформа) и кросс-компилятором gcc, выполняющемся на инструментальной платформе и генерирующем код для процессора mips под управлением ОС реального времени отображены на рисунке. В таблице приведены результаты для тестов FLOPS и LINPACK, полученных путем кросс-компиляции с оптимизацией по профилю, вычисленному на целевой платформе i686/Linux в сравнении. Таблица
Рассмотрим два примера оптимизаций по профилю, поддерживаемых в gcc. Подстановка косвенных вызовов. Если указатель, по которому производится косвенный вызов функции, с большой вероятностью принимает некоторое постоянное значение f, и соответствующая функция доступна компилятору для inline-подстановки, то для такого косвенного вызова будет сформирована условная ветвь с подстановкой часто вызываемой функции: static int a1 (void) { return 10; } static int a2 (void) { return 0; } typedef int (*tp) (void); static tp aa [] = {a2, a1, a1, a1, a1}; void setp (int (**pp) (void), int i) { if (!i) *pp = aa [i]; else *pp = aa [(i & 2) + 1]; } int main (void) { int (*p) (void); int i; for (i = 0; i < 10; i ++) { setp (&p, i); p (); }
return 0; } Для вызова p() в функции main будет сформирован код вида: if (p == a1)
else p (); Специализация операций. Дорогостоящие операции (целочисленное деление или взятие остатка при некоторых значениях операндов) могут быть реализованы более эффективно. Для таких операций компилятор (при наличии ключа -fprofile-generate) обеспечивает сбор профиля. Если операнды с большой вероятностью принимают «хорошие» значения, то компилятор (при наличии ключа -fprofile-use) сгенерирует ветви для быстрого вычисления результата: int a[1000]; int b = 256; int c = 257; main () { int i; int n; for (i = 0; i < 1000; i++) { if (i % 17) n = c; else n = b; a[i] /= n; } return 0; } В операторе a[i]/=n делитель будет преимущественно принимать значение 257, поэтому компилятор сгененирует ветвь для быстрого вычисления результата (путем умножения делимого на некоторую большую константу). Результаты выполнения этого примера на процессоре i686: с оптимизацией по профилю: 0.29user 0.00system 0:00.30elapsed 97%CPU без оптимизации по профилю: 0.39user 0.00system 0:00.40elapsed 98%CPU Другие подходы к адаптивной компиляции Хотя оптимизация по профилю может давать значительный прирост производительности и способствовать сокращению размера кода, с ее применением связан ряд проблем. Необходимость двукратной компиляции, а также разработки и сопровождения достаточно представительных тестовых задач для сбора профиля усложняет процесс разработки и сопровождения программ. Не всегда возможно предугадать, с какими входными данными приложение будет работать в производственных условиях. Кроме того, как показывает практика, в некоторых случаях оптимизация по профилю может приводить к деградации производительности каких-то частей программы, то есть разработчику необходимо анализировать результаты оптимизации по профилю и, возможно, применять ее избирательно. Для решения этих проблем применяется метод динамической адаптивной реоптимизации программ. Рассмотрим, например, инфраструктуру динамической реоптимизации (см.: T. Kistler, M. Franz. Continuous Program Optimization: A Case Study. ACM Transactions on Programming Languages and Systems, Vol. 25, No. 4, July 2003). Когда пользователь впервые запускает приложение, компонент загрузки и генерации кода транслирует представление этой программы в машинный код. Для того чтобы ускорить процесс запуска, на этой стадии оптимизация приложения не выполняется. Компонент профилирования обеспечивает сбор данных о динамике выполнения приложения. Он собирает различные частотные характеристики, а также данные о наиболее часто используемых значениях параметров при вызовах функций. Компонент управления средой реоптимизации (выполняющийся в рамках низкоприоритетного потока) периодически опрашивает базу данных профилирования об изменениях профилей отдельных приложений и формирует очередь приложений для реоптимизации. Приложения в очереди упорядочиваются в соответствии с ожидаемым эффектом от их реоптимизации и передаются на вход компонента оптимизации. По завершении оптимизации очередного приложения, загруженный код этого приложения замещается оптимизированным кодом. Подобная схема допускает использование разных методов профилирования и представлений программ, содержащих достаточно информации для ее оптимизации. Такой подход избавляет разработчиков приложений от необходимости создавать и поддерживать тестовые задачи и не требует сложной схемы сборки приложений. Он также обеспечивает адаптацию кода программы к реальной динамике ее выполнения. С другой стороны, использование динамической реоптимизации требует наличия специальной довольно сложной среды выполнения. К тому же, она может противоречить требованиям надежности, поскольку код приложения изменяется непосредственно во время выполнения. По этим причинам он неприменим, в частности, для встроенных систем. Адаптивный подбор последовательностей оптимизирующих преобразований. Суть этого подхода заключается в индивидуальном подборе последовательностей оптимизирующих преобразований для отдельных участков кода, поскольку не существует универсальной последовательности, которая обеспечивала бы наилучший результат для любого участка кода. К приложениям для встроенных систем зачастую предъявляются жесткие требования по производительности и/или энергопотреблению. Обычно имеются ограничения и на размер кода. В таких условиях оправдано применение достаточно сложных и трудоемких средств компиляции, позволяющих приблизить генерируемый код по указанным характеристикам к программам, написанным на языке ассемблера. К числу таких средств относится метод адаптивного подбора оптимизирующих последовательностей, позволяющий при помощи какой-либо стратегии перебора сопоставить каждому участку программы некоторую последовательность оптимизаций (из фиксированного набора) так, чтобы получить достаточно хороший по заданным характеристикам код. Поскольку пространство перебора слишком велико, обычно не ставится задача полного перебора для нахождения точного оптимума; как правило, применяют алгоритмы генетического перебора, «жадные» алгоритмы или перебор «по градиенту» и ограничивают время поиска решения. В качестве участков адаптивной компиляции могут выступать базовые блоки, функции, циклы или гнезда циклов. Как правило, среда адаптивной компиляции предоставляет интерактивную оболочку, позволяющую пользователю управлять процессом компиляции. Реализации этого подхода различаются наборами адаптивно применяемых оптимизирующих преобразований и некоторыми другими характеристиками. В адаптивной компиляции используется широкий набор оптимизаций, включающий все их виды, реализованные в базовом компиляторе, в том числе оптимизации циклов (см.: K.D. Cooper, A. Grosul, T.J. Harvey, S. Reeves, Devika Subramanian, Linda Torczon and Todd Waterman. ACME: Adaptive Compilation Made Efficient. 2005). В ряде работ применяются относительно узкие множества оптимизаций, например, только преобразования нижнего уровня, ориентированные на специфику целевого процессора, или только оптимизации циклов. Для оценки эффективности сгенерированного кода программа выполняется на целевом процессоре с замером числа выполненных инструкций. Хотя адаптивная компиляция в чистом виде не опирается на данные профилирования, их использование может быть полезным. Так, профиль частоты выполнения базовых блоков используется для экономии времени, затрачиваемого на оценочные прогоны вариантов генерируемого кода. Программа выполняется всего один раз с получением профиля, а эффективность ее вариантов, полученных с применением различных оптимизирующих последовательностей, оценивается на основе данных о частоте выполнения базовых блоков. Профиль можно было бы также учитывать при выборе множества оптимизаций для различных участков программы, что фактически означает интеграцию обычной оптимизации по профилю с переборной адаптивной компиляцией. Разумно было бы также варьировать интенсивность перебора оптимизирующих последовательностей для различных участков программы с учетом частоты их выполнения. Данные профилирования – важный источник информации для компилятора при принятии решений о целесообразности и параметрах различных оптимизаций. Повышение эффективности кода в результате применения оптимизаций по профилю может составлять в среднем 10–20 %, а для отдельных программ эффект может быть значительно выше. В настоящее время ведутся активные исследования в области оптимизации по профилю, в частности, по динамической реоптимизации приложений по профилю. В сфере компиляции для встроенных систем развиваются переборные методы адаптивной компиляции, позволяющие подбирать оптимизирующие последовательности индивидуально для различных участков программы. В связи с этим интеграция традиционной оптимизации по профилю с переборными методами адаптивной компиляции представляется интересным направлением исследований. |
 детектор выравнивания – позволяет определить ожидаемое выравнивание адресного выражения.
детектор выравнивания – позволяет определить ожидаемое выравнивание адресного выражения.http://swsys.ru/index.php?id=324&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Зарубежные базы данных по программным средствам вычислительной техники
- Методы поисковой адаптации на основе механизмов генетики, самообучения и самоорганизации
- Правила построения автоматизированных информационных систем экспертной оценки и согласования
- Программные средства автоматизации приборостроительного производства изделий радиоэлектронной аппаратуры
- О выборе числа процессоров в многопроцессорной вычислительной системе