Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Методика и программное средство защиты кода от несанкционированного анализа
Аннотация:Рассматривается вопрос защиты ПО от несанкционированного исследования. Уделено пристальное внимание существующим техникам защиты кода, алгоритму анализа инструкций, промежуточному языку их описания, а также методике декомпиляции бинарного кода и возможности ее применения в сфере информационной безопасности. Основная цель заключается в разработке эффективного алгоритма анализа бинарного кода. Для ее достижения необходимо создать эффективный механизм анализа низкоуровневых команд и их алгоритмического представления, провести апробацию полученной методики. Авторами предлагаются алгоритм полиморфной генерации кода, а также архитектура и интерфейс разработанного ПО с описанием полученных результатов. Итогом работы стала эффективная методика декомпиляции и алгоритмического представления линейных участков бинарного кода, апробированная на решении такой задачи, как защита ПО от несанкционированного анализа. Полученные результаты позволяют говорить об эффективности предложенной методики. Количество операций на участке кода, входных и выходных ресурсов, а также результирующих формул возросло, что непременно приведет к росту ресурсов, требуемых для исследования данного участка кода, и таким образом повысит защищенность бинарного кода от исследования.
Abstract:The article consider, relevant issue in software protection against unauthorized analyze. In the article authors analyze the existing equipment of binary code protection, descript algorithm of machine instruction analyze with the design of the intermediate language that descript such instructions. The article describes about technique of binary code decompilation and its application possibility in information security sphere. The main object of this work is to develop an efficient algorithm for the binary code analyze. To achieve this goal it is necessary to solve a number of tasks: to develop an effective mechanism for the low-level command analyze with algorithmic representations and conduct testing of the resulting methods. In the second part describes the mechanism of polymorphic code generation, architecture and software interface with the result description. The result was an effective method of reverse engineering and algorithmic representations of binary code linear plots, tested with such tasks as: software protection against unauthorized analysis and analysis of obfuscated code threats. The results show the effectiveness of the proposed technique because increased: the number of operations in the code area, input and output resources and resulting formulas which will inevitably lead to increase resources required to explore this part of the code, and it’s increase the code security against research.
| Авторы: Шудрак М.О. (mxmssh@gmail.com) - Сибирский государственный аэрокосмический университет им. М.Ф. Решетнева, г. Красноярск (аспирант ), Красноярск, Россия, Лубкин И.А. (mxmssh@gmail.com) - Сибирский государственный аэрокосмический университет им. М.Ф. Решетнева, г. Красноярск (аспирант ), Красноярск, Россия | |
| Ключевые слова: декомпиляция., бинарный код, полиморфизм, защита программного обеспечения |
|
| Keywords: decompilation, binary code, polymorphism, software protection |
|
| Количество просмотров: 11170 |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
Сегодня активно развиваются системы и методы защиты программного кода от несанкционированного исследования. Однако одновременно совершенствуются и методы преодоления защиты таких систем, следствием чего являются денежные потери организаций, заинтересованных в защите программного кода. В основе практически любого метода преодоления систем безопасности ПО лежит предварительное исследование кода, отвечающего за его защиту. Цель такого исследования в том, чтобы восстановить алгоритм защиты, выделить его слабые стороны или недокументированные возможности для его последующей модификации и (или) автоматизации процесса преодоления. Такое преодоление гарантированно достигается за определенное время вследствие конечности программы, а время, за которое злоумышленник преодолеет систему, зависит от его квалификации и сложности системы защиты [1]. Этой ситуации способствует широкий выбор (более 100 наименований) инструментов для исследования программного кода. Цель данной работы заключалась в повышении защищенности программного кода от несанкционированного исследования (анализа). Для ее достижения необходимо решить следующие задачи: проанализировать существующие методики защиты программного кода; разработать алгоритм анализа машинных инструкций; спроектировать промежуточный язык представления машинных инструкций; разработать прототип программного средства, способного к полиморфной генерации кода. На сегодняшний день существует несколько методов защиты программного кода: – обфускация – внесение запутывающих преобразований в исходные коды программ, написанных на языках высокого уровня; – шифрование – криптографическое закрытие защищаемого кода на том или ином этапе эксплуатации системы; – антиотладка – защита кода от средств отладки и исследования; – полиморфизм – генерация различных версий бинарного кода одного алгоритма; чаще всего технологию полиморфизма для защиты бинарного кода используют компьютерные вирусы, чтобы защитить собственный код; для исследования таких объектов, как правило, используются специально разрабатываемые для каждого кода алгоритмы анализа [2]. Описание методики Технология полиморфной генерации бинарного кода позволяет проводить запутывающие преобразования с бинарным кодом защищаемого объекта. В рамках данной работы производится встраивание (вставка запутывающих инструкций между инструкциями защищаемого кода) запу- тывающего кода в бинарный код защищаемого объекта. Такое встраивание позволяет увеличить время, за которое злоумышленник сможет восстановить алгоритм защиты, за счет усложнения исследуемого кода. Для разработки полиморфного генератора, способного к встраиванию в произвольный участок кода, необходим не только учет задействованной памяти и регистров на участке кода, но и анализ данного участка кода. Цель такого анализа заключается в восстановлении алгоритма для рассматриваемого участка кода. В свою очередь, для анализа бинарного кода необходим определенный уровень абстракции от машинного кода к человеку. Подобный уровень абстракции достижим, если для анализа кода использовать методику декомпиляции бинарного кода (в классическом понимании под декомпиляцией понимают трансляцию бинарного кода в относительно эквивалентный код на языке высокого уровня). Таким образом, процесс полиморфной генерации бинарного кода можно условно разделить на два этапа – анализ запутываемого кода и генерация инструкций на основе проведенного анализа. Анализ бинарного кода является нетривиальной задачей, поскольку в процессе компиляции исходного кода программы теряется важная, с точки зрения анализа, информация. Таким образом, для декомпиляции бинарного кода нет необходимости представлять машинный код на языке высокого уровня, требуется восстановить алгоритм работы участка кода (обеспечить соответствующий уровень абстракции) для последующего его запутывания.
Методика интерпретации инструкций, предложенная авторами данной статьи [3], рассматривает инструкции как совокупность элементарных операций над ресурсами, где в качестве ресурса могут выступать регистры, память или регистры флагов процессора. Все операции в рамках методики были сгруппированы в базовый набор операций: сложение и вычитание (+ и –); умножение (*); целочисленное деление (/); взятие остатка от деления (%); логическое «И»; логическое «ИЛИ»; логическое «Исключающее ИЛИ»; циклический битовый сдвиг влево (<<); циклический битовый сдвиг вправо (>>); доступ к отдельным битам ([]); запись в память по некоторому адресу ([<–); чтение из памяти по некоторому адресу (<–]); логическое «НЕ»; перенос информации от одного ресурса к другому (Транзит); обозначение константы (Const); обозначение группы специальных инструкций, которые нецелесообразно расщеплять на элементарные операции (Special). Для отображения информации об инструкции предлагается следующая схема: ресурс, соответствующий регистру, обозначается фигурными скобками, в которые заключен его номер; ресурс оперативной памяти обозначается квадратными скобками, в которые заключен адрес ресурса; номер такого ресурса выносится за скобки; результат отделяется знаком «=»; операции и константы записываются как есть. Такая форма записи позволяет представлять инструкции в виде математических формул. Например, инструкции add eax,ecx и inc eax запишутся в виде R2=R1+R0; R3=R2+1, что наглядно показывает процесс преобразования информации для участка машинного кода. Согласно предлагаемому алгоритму декомпиляции, за этапом интерпретации следует сборка. Идея такого процесса в том, что ресурс-источник одной операции может выступать в роли приемника в другой операции, устанавливая таким образом связь между операциями на участке кода. Развивая методику сборки, для установки связи между операциями было предложено использовать аппарат синтаксических деревьев с целью описания преобразований ресурсов. В таком дереве узлы представляют собой операторы из базового набора операций, описанного выше, а листья соответствуют ресурсам или константам. Рассмотрим следующий пример для описания предложенного аппарата: R2=R0+R1; R4=R2*R3.
Таким образом, для формирования итогового выражения необходимо осуществить рекурсивный проход по дереву вида {левый лист, узел, правый лист}. Выход из узла дерева формирует скобки в итоговом выражении. Такие деревья необходимо формировать для каждого выходного ресурса. Для определения выходных ресурсов можно использовать несколько утверждений. 1. Выходным называется ресурс, который не является промежуточным. 2. В качестве выходных ресурсов можно рассматривать ресурсы памяти (в том числе стек программы), регистры общего назначения, так как чаще всего они являются выходными ресурсами при вызове функций. В процессе полиморфной генерации бинарного кода встает задача учета ресурсов процессора для обеспечения неизменности алгоритма работы участка кода, на котором производится генерация. Для учета ресурсов процессора необходимо учитывать не только регистры и флаги процессора, но и регистры, которые используются для адресации памяти (например mov[eax],3), так как их изменение в некоторых случаях может привести к нарушению алгоритма работы участка кода. Таким образом, для учета ресурсов процессора необходимо учитывать их изменение после каждой инструкции. Для учета ресурсов процессора используется битовая маска регистров общего назначения, в результате для генерации кода можно использовать только те регистры, чей флаг не взведен. Также стоит отметить, что регистры со взведенным флагом нельзя использовать как приемник информации, а в качестве источника информации для других регистров их использование оправдано, поскольку такая пересылка информации не вносит изменения в алгоритм работы участка кода. Общий алгоритм полиморфной генерации кода изображен на рисунке 3.
Рассмотрим общий алгоритм генерации инструкции (рис. 4). На этапе генерации кода производится выбор инструкции из множества поддерживаемых генератором инструкций, выбор ресурса-приемника и ресурса-источника информации, где ресурс-приемник формируется исходя из данных о задействованных ресурсах. Следует отметить, что инструкция может оперировать как одним, так и двумя (и более) ресурсами. Если инструкция оперирует одним ресурсом, нужно установить, изменяется ли ресурс этой инструкцией в процессе выполнения. Этапу компиляции инструкции предшествует этап генерации инструкции, на выходе из которого формируется следующая, важная с точки зрения компилятора информация: код операции, ресурсы-приемники и источники информации. Для трансляции сгенерированных ранее инструкций в бинарный код необходимо учитывать то, как процессор интерпретирует команды. Рассмотрим формат инструкций архитектуры x86 (рис. 5). Заметим, что, кроме поля кода операции, все остальные поля являются необязательными, то есть в одних командах могут присутствовать, а в других нет.
Для реализации полиморфного генератора были использованы как существующие [4], так и оригинальные разработки. Для оценки качества полиморфного генератора и визуализации разработан интерфейс ПО, включивший в себя дизассемблер и оригинальный декомпилятор, позволяющий наглядно продемонстрировать те действия, которые реализует полиморфный генератор в бинарном коде защищаемого объекта. Рассматривая структуру разработанного программного комплекса (рис. 6), необходимо отметить, что она имеет модульную архитектуру и создавалась с учетом возможности использования модулей отдельно друг от друга. Помимо самого программного средства, была разработана и заполнена БД, а также реализована СУБД для решения задачи поддержки новых инструкций.
Таким образом, описываемая методика была реализована в виде программного средства, которое представляет собой анализатор программного кода, полиморфный генератор кода, СУБД и БД, содержащие соответствие инструкций их алгоритмам. При использовании разработанного програм- много средства в защищаемом коде появляется избыточность: количество операций увеличивается с 12 до 46, выходных ресурсов – с 5 до 8. Поэтому для анализа защищенного кода злоумышленнику потребуется больше ресурсов (в большей степени временных). Полученные результаты позволяют говорить об эффективности предложенной методики. Количество операций на участке кода, количество входных и выходных ресурсов, а также результирующих формул возросло, что непременно приводит к росту ресурсов, требуемых для исследо- вания данного участка кода, и, следовательно, к повышению защищенности бинарного кода от исследования. Литература 1. Золотарев В.В. Метод исследования программных средств защиты информации на основе компонентной модели информационной среды // Изв. ЮФУ: Технич. науки. 2008. Вып. 8. С. 87–94. 2. Буинцев Д.Н. Метод защиты программных средств на основе запутывающих преобразований. Дис… канд. техн. наук. Томск, 2006. 3. Кукарцев А.М., Лубкин И.А. Методика защиты программного кода от несанкционированной модификации и исследования посредством его хеширования // Вестн. СибГАУ. 2008. Вып. 1. С. 56–60. 4. Hacker Disassembler Engine. URL: http://vx.netlux.org (дата обращения: 23.01.2012). |
 Соответствующий уровень абстракции может быть получен путем декомпиляции программного кода. Рассмотрим алгоритм работы декомпилятора подробно (рис. 1).
Соответствующий уровень абстракции может быть получен путем декомпиляции программного кода. Рассмотрим алгоритм работы декомпилятора подробно (рис. 1). В результате будем иметь итоговое выражение R4=(R0+R1)*R3. А синтаксическое дерево примет вид, представленный на рисунке 2.
В результате будем иметь итоговое выражение R4=(R0+R1)*R3. А синтаксическое дерево примет вид, представленный на рисунке 2.

 Таким образом, для компиляции инструкции необходимо сгенерировать значения тех полей, которые требуется использовать в инструкции, и расположить в бинарном коде согласно архитектуре x86.
Таким образом, для компиляции инструкции необходимо сгенерировать значения тех полей, которые требуется использовать в инструкции, и расположить в бинарном коде согласно архитектуре x86.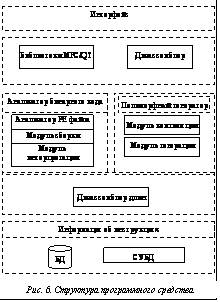 Такая структура ПО позволяет обеспечить переносимость всей разработки на различные платформы, а также использовать модули программного средства для других задач, отличных от полиморфной генерации бинарного кода, и переносить их (за исключением СУБД) на другие платформы (например UNIX и т.п.).
Такая структура ПО позволяет обеспечить переносимость всей разработки на различные платформы, а также использовать модули программного средства для других задач, отличных от полиморфной генерации бинарного кода, и переносить их (за исключением СУБД) на другие платформы (например UNIX и т.п.).| Постоянный адрес статьи: http://swsys.ru/index.php?id=3337&page=article |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
| Статья опубликована в выпуске журнала № 4 за 2012 год. [ на стр. 176-180 ] |
Назад, к списку статей