Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Эволюционный метод ранжирования и классификации биологических объектов
Аннотация:Предлагается метод классификации биологических объектов, основанный на эволюционном подходе к решению экстремальной задачи функции многих переменных. Метод ориентирован на обработку многомерных массивов информации, особенностями которой являются высокая размерность признакового пространства и малый объем выборки объектов, и базируется на использовании принципа ранжирования объектов в многомерном пространстве относительно некоторого базового элемента, поиск которого осуществляется с помощью модифицированного генетического алгоритма. Метод реализует двойное ранжирование объектов относительно базового элемента: упорядочение объектов по классам, а также по возрастанию расстояния от базового элемента внутри классов. Принадлежность нового объекта к одному из классов определяется его рангом в упорядоченном ряду объектов обучающей выборки. Предлагаемый метод классификации не требует снижения размерности признакового пространства, что позволяет исключить потерю значимой информации и учесть внутренние связи в рассматриваемых информационных массивах. Метод обеспечивает построение иерархического класса алгоритмов, моделирующих получение решающей классификационной процедуры, используя различные типы представления базового элемента в многомерном пространстве и различные варианты упорядочения классов в формируемой последовательности объектов, и изначально ориентирован на использование параллельных вычислений. Следует отметить, что он не требует выполнения гипотез компактности и может также работать с пересекающимися классами объектов.
Abstract:Method of classification of biological objects is suggested in this article. The method is based on the evolutionary approach to the solution of the extremal problem of multivariable function. Method is aimed at processing multidimensional data arrays, which features are high dimensionality and small sample size of objects. The method is based on the ranking of the objects in multidimensional space relative to some base element. Search of this base element is carried out by a modified genetic algorithm. The method implements dual ranking of objects relative to the base element: the ordering of objects into classes, and the ordering of objects in ascending distance from the base element within classes. Belonging of the new object to one of the classes is determined by its rank in an ordered series of objects of learning sample. The proposed classification method does not require reducing the dimensionality of the feature space. This eliminates the loss of important information and allows considering internal communications in these information arrays. Method allows the construction of hierarchical class of algorithms, which models the obtaining of the decision classification procedure using different types of representations of the base element in a multidimensional space and the various options for the ordering of classes in formed sequence of objects. The method is initially aimed to be used in parallel computation. It should be noted that the method does not require performance of compactness hypotheses, and can also work with overlapping classes of objects.
| Авторы: Цыганкова И.А. (pallada-ltd@infopro.spb.su) - Учреждение Российской академии наук Санкт-Петербургский институт информатики РАН, кандидат технических наук | |
| Ключевые слова: базовый элемент., ранжирование, классификация, геномная информация, обработка данных |
|
| Keywords: base element, rankings, classification, genomic information, data processing |
|
| Количество просмотров: 12310 |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
Типичной задачей, которую необходимо решать в процессе разработки новых биологически активных веществ и методов диагностики, является классификация (распознавание) объектов по результатам анализа геномной информации. Исходная геномная информация представляет собой таблицу экспериментальных данных с набором (входных) параметров биологических объектов и целевым (выходным) параметром, определяющим принадлежность объекта к одному из классов. Следует отметить, что характерной особенностью геномных данных является высокая размерность пространства признаков, которая существенно превышает объем выборки биологических объектов. В настоящее время известно большое количество методов классификации, эффективность которых существенно зависит от специфики предметной области, в которой эта задача cформулирована, и особенностей исходной информации [1–7]. Анализ существующих методов показал, что их использование для классификации объектов по геномной информации или требует предварительного снижения размерности пространства признаков, или фактическое снижение размерности происходит уже в процессе формирования классифицирующего правила. Специфика геномной информации (перекрещивающиеся гены, рекомбинация генов и др.) делает снижение размерности признакового пространства прин- ципиально недопустимым, так как это может привести к потере значимой информации о неизвестных взаимных связях между генами, что чрезвычайно важно при создании новых методов диагностики и лекарственных средств. Поэтому разработка методов классификации по геномной информации с учетом ее особенностей является актуальной задачей, требующей дальнейшего развития. Постановка задачи В общем случае вся совокупность биологических объектов делится на несколько классов, но в большинстве случаев, на основе стратегии «один против всех» [8], классификация может быть сведена к последовательному решению задач с двумя классами. Поэтому в дальнейшем будем рассматривать задачу классификации только для двух классов. Пусть имеется конечное множество объектов Это множество разделено на два непересекающихся подмножества (класса) K0 и K1: K0={s1, s2, …, sn}, K1={sn+1, sn+2, …, sn+m}, где n – количество объектов класса K0; m – количество объектов класса K1; n+m=N – общее количество объектов множества S. Каждый объект множества описывается набором параметров (объекты – точки p-мерного пространства)
здесь Xi – вектор входных параметров объекта; yi – классифицирующий (целевой) параметр, определяющий принадлежность объекта к одному из классов. Параметры вектора Xi имеют возможность принимать значения из некоторого множества допустимых значений действительных чисел. Значения отдельных параметров xj для некоторых объектов si могут быть не определены, то есть в таблице данных есть пропущенные значения. Размерность признакового пространства Rp существенно больше объема выборки, то есть Требуется, не снижая размерности признаков, предложить метод, позволяющий с приемлемой точностью классифицировать объект q, заданный вектором Xq=(x1, x1, …, xj, …, xp). Метод классификации Рассматриваемая задача классификации является плохо формализованной в силу того, что вся информация об объектах представлена лишь набором входных и выходных параметров, о которых нельзя сколь-нибудь определенно сказать, что они полны, непротиворечивы и не искажены. В такой ситуации наиболее эффективными становятся методы [9–11], базирующиеся на эволюционном подходе к решению экстремальных задач функции многих переменных, которые в отличие от традиционных методов поиска оптимального решения ориентированы на получение приемлемого решения, лучшего по сравнению с полученным ранее или заданным в качестве начального. Для решения сформулированной задачи предлагается метод, основанный на предположении, что в многомерном признаковом пространстве Rp существует некоторый базовый элемент, относительно которого формируется ранжированная последовательность объектов, сепарирующая обучающую выборку на два класса. Метод реализует двойное ранжирование объектов относительно базового элемента: упорядочение объектов по классам и упорядочение объектов по возрастанию расстояния от базового элемента внутри классов. Тогда принадлежность объекта q к одному из классов определяется рангом tq классифицируемого объекта в упорядоченном ряду объектов обучающей выборки. Предполагается, что базовым элементом могут быть такие объекты многомерного пространства, как точка, плоскость, прямая или ломаная линия. При выборе базового элемента рассматриваются два варианта упорядочения классов в формируемой последовательности объектов: класс K0 предшествует классу K1 или класс K1 предшествует классу K0. Поиск решения предлагается проводить с использованием эволюционного подхода, реализуемого с помощью генетического алгоритма, представляющего собой итерационный вероятностный эвристический алгоритм поиска, особенностью которого является одновременное использование множества точек поиска (популяции) из пространства потенциальных решений. Поиск базового элемента при заданном типе его представления в пространстве Rp и выбранном варианте упорядочения классов в формируемой последовательности объектов по сути является самостоятельной задачей. Это позволяет достаточно легко организовать параллельную реализацию алгоритма обучения, что дает возможность оптимизировать вычислительные ресурсы и существенно сократить время поиска решения. Введем некоторые обозначения. Пусть базовый элемент будет Порядок следования классов в формируемой последовательности объектов обозначим через L:
Рассмотрим одну из возможных формализаций. Для определенности примем, что базовый элемент
где f1, f2 – оценки погрешности классификации объектов по классу K0 и классу K1 соответственно; r – количество рассмотренных вариантов решения (базовых элементов). Использование минимаксного критерия I(X*) соответствует позиции крайней осторожности при неоднозначном выборе альтернатив оценки погрешности классификации. Поиск экстремального значения критерия (1) проведем с помощью модифицированного генетического алгоритма. Принципиальным является то, что в качестве исходной популяции рассматриваются сами объекты обучающей выборки. Размер популяции фиксирован и равен объему обучающей выборки. Каждое возможное решение представлено строкой (хромосомой), которая является массивом из p действительных чисел Степень приспособленности каждой хромосомы в популяции оценивается с помощью функции приспособленности, которая является аналогом целевой функции F=max(f1, f2) Чем меньше значение этой функции, тем выше качество хромосомы. В результате процесса искусственной эволюции, включающего селекцию, скрещивание и мутацию хромосом, качество решений в популяции постепенно улучшается. Работа генетического алгоритма завершается, если функцией F достигнуто ожидаемое значение; выполнение заданного количества итераций (поколений) не приводит к улучшению уже достигнутого значения F; истекло время, отведенное на решение задачи. Преждевременный останов работы генетического алгоритма может произойти в случае вырождения популяции. Под вырождением понимается сокращение разнообразия хромосом, крайним проявлением вырождения является состояние популяции, в которой все ее члены имеют идентичные хромосомы. Алгоритм вычисления функции приспособленности (2) каждой хромосомы заключается в следующем. Вычислим расстояние между базовым элементом
Проведем ранжирование элементов выборки S по возрастанию расстояния ri от базового элемента (считая, что
Интерпретируем величины ri в последовательности (3) как ранги объектов ti=t(ri), задающие упорядочение объектов по расстоянию, и обозначим эту ранговую последовательность как
Идентифицируя каждый объект, входящий в обучающую выборку S, по его рангу ti, сформируем в соответствии с последовательностью (4) вектор Y, элементами которого являются значения классифицирующего параметра yi объектов выборки S:
В качестве границы между классами в сформированной ранжированной последовательности T будем рассматривать элемент с индексом tn, ранг которого равен количеству объектов класса K0. Тогда с учетом выбранного порядка следования классов (L=L0) слева от объекта с рангом Для определения целевой функции (2) вычислим оценки f1 и f2, характеризующие погрешности классификации объектов по классу K0 и по классу K1 соответственно. Обозначим
Здесь
и аналогично
где w(ti) – весовой коэффициент неправильно классифицируемого объекта c рангом ti, зависящий от расположения этого объекта относительно границы между классами tn и от количества объектов класса, куда он ошибочно был отнесен,
После оценки по формуле (2) качества каждой хромосомы в популяции и выбора лучшей из них принимается решение о продолжении эволюционной процедуры генерации следующего поколения либо о завершении процедуры обучения. Принадлежность классифицируемого объекта q с известными значениями входных параметров Xq=(x1, x2, …, xj, …, xp) к одному из классов определяется с помощью решающей классификационной процедуры, в которой участвуют все объекты обучающей выборки. Относительно базового элемента, найденного на этапе обучения, формируется ранжированная по расстоянию последовательность объектов обучающей выборки и объекта q, а затем определяется ранг tq классифицируемого объекта q в этом упорядоченном ряду. Решение о принадлежности объекта q классу принимается исходя из условия
Степень принадлежности h(tq) объекта q
В заключение отметим следующее. В работе предложен эволюционный метод классификации, основанный на ранжировании объектов в многомерном пространстве относительно базового элемента, поиск которого осуществляется с помощью модифицированного генетического алгоритма. Метод ориентирован на обработку многомерных массивов информации, особенностями которой являются высокая размерность признакового пространства и малый объем выборки объектов. Предлагаемый метод классификации позволяет не проводить предварительное снижение размерности признакового пространства, что, в свою очередь, дает возможность исключить потерю значимой информации и учесть внутренние связи в рассматриваемых информационных массивах. Метод обеспечивает построение иерархического класса алгоритмов, моделирующих получение решающей классификационной процедуры, используя различные типы представления базового элемента в многомерном пространстве и различные варианты упорядочения классов в форми- руемой ранжированной последовательности объектов. Он изначально ориентирован на использование параллельных вычислений, что позволяет оптимизировать вычислительные ресурсы и существенно сократить время поиска решения. Следует отметить, что разработанный метод классификации не требует восстановления пропущенных значений признаков, выполнения гипотез компактности и может работать с пересекающимися классами объектов. Литература 1. Айвазян С.А., Бухштабер В.М., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Классификация и снижение размерности. М.: Финансы и статистика, 1989. 607 с. 2. Айзерман М.А., Браверманн Э.М., Розоноэр Л.И. Метод потенциальных функций в теории обучения машин. М.: Наука, 1970. 384 с. 3. Вапник В.Н., Червоненкис А.Я. Теория распознавания образов (статистические проблемы обучения). М.: Наука, 1974. 415 с. 4. Журавлев Ю.И. Избранные научные труды. М.: Магистр, 1998. 420 с. 5. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. Новосибирск: Изд-во ин-та математики, 1999. 270 с. 6. Мазуров В.Д. Метод комитетов в задачах оптимизации и классификации. М.: Наука, 1990. 248 с. 7. Растригин Л.А., Эренштейн Р.Х. Метод коллективного распознавания. М.: Энергоиздат, 1981. 80 с. 8. Rifkin R., Klautau A. In Defense of One-Vs-All Classification. Journal of Machine Learning Research, 2004, pp. 101–141. 9. Freitas A.A. Data Mining and Knowledge Discovery with Evolutionary Algorithms. Berlin etc.: Springer, 2002. 279 p. 10. Емельянов В.В., Курейчик В.В., Курейчик В.М. Теория и практика эволюционного моделирования. М.: Физматлит, 2003. 432 с. 11. Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. М.: Горячая линия–Телеком, 2008. 452 с. |

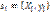 ,
,  , где
, где 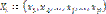 ,
,  ,
,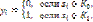
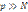 .
. , где
, где 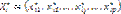 – i-й вектор параметров базового элемента; l – количество векторов
– i-й вектор параметров базового элемента; l – количество векторов 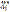 , определяющих базовый элемент в пространстве Rp. Следует отметить, что при i=1 базовый элемент является точкой или плоскостью, заданной параметрически; при i=2 – отрезком; при i=3 – ломаной из двух отрезков; при i=l – ломаной из (l–1) отрезков.
, определяющих базовый элемент в пространстве Rp. Следует отметить, что при i=1 базовый элемент является точкой или плоскостью, заданной параметрически; при i=2 – отрезком; при i=3 – ломаной из двух отрезков; при i=l – ломаной из (l–1) отрезков.
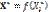 – гиперплоскость, а L=L0 –порядок следования классов. Процесс классификации объекта q включает в себя два основных этапа: этап обучения и этап распознавания. Задача обучения состоит в подборе базового элемента, относительно которого формируется ранжированная последовательность объектов, разделенных на два класса с приемлемой погрешностью. В качестве оценки качества разделения объектов на классы примем минимаксный критерий вида
– гиперплоскость, а L=L0 –порядок следования классов. Процесс классификации объекта q включает в себя два основных этапа: этап обучения и этап распознавания. Задача обучения состоит в подборе базового элемента, относительно которого формируется ранжированная последовательность объектов, разделенных на два класса с приемлемой погрешностью. В качестве оценки качества разделения объектов на классы примем минимаксный критерий вида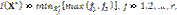 (1)
(1) , где каждый элемент хромосомы (ген) имеет ограничения
, где каждый элемент хромосомы (ген) имеет ограничения  , обусловленные нормировкой значений параметров. Селекция хромосом производится детерминированным способом с использованием элитарной стратегии и с частичной заменой наименее приспособленных хромосом на наиболее приспособленные при сохранении размера популяции. Скрещивание хромосом выполняется случайно с вероятностью Pc. Точка скрещивания разыгрывается также случайно по равномерному закону в заданном интервале. Процедура мутации выполняется на популяции потомков, образованных в результате скрещивания, и заключается в изменении значения гена в хромосоме случайным выбором числа из интервала [0, 1] с вероятностью Pm.
, обусловленные нормировкой значений параметров. Селекция хромосом производится детерминированным способом с использованием элитарной стратегии и с частичной заменой наименее приспособленных хромосом на наиболее приспособленные при сохранении размера популяции. Скрещивание хромосом выполняется случайно с вероятностью Pc. Точка скрещивания разыгрывается также случайно по равномерному закону в заданном интервале. Процедура мутации выполняется на популяции потомков, образованных в результате скрещивания, и заключается в изменении значения гена в хромосоме случайным выбором числа из интервала [0, 1] с вероятностью Pm. (2)
(2)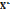 и i-м объектом выборки и обозначим его через
и i-м объектом выборки и обозначим его через  , i=1, …, n+m. Формула для вычисления расстояния ri зависит от типа базового элемента в пространстве Rp и в рассматриваемом случае, когда базовый элемент – гиперплоскость, ri имеет вид
, i=1, …, n+m. Формула для вычисления расстояния ri зависит от типа базового элемента в пространстве Rp и в рассматриваемом случае, когда базовый элемент – гиперплоскость, ri имеет вид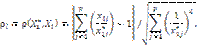
 , если
, если  ):
):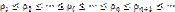
 (3)
(3)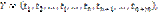
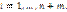 (4)
(4)
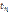 должны располагаться объекты класса K0, а справа – объекты класса K1.
должны располагаться объекты класса K0, а справа – объекты класса K1.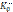 подмножество объектов класса K0, ошибочно отнесенных к классу K1, а
подмножество объектов класса K0, ошибочно отнесенных к классу K1, а 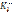 – подмножество объектов класса K1, ошибочно отнесенных к классу K0. Представим f1 и f2 в виде суммы двух слагаемых:
– подмножество объектов класса K1, ошибочно отнесенных к классу K0. Представим f1 и f2 в виде суммы двух слагаемых: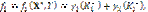

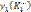 и
и  – оценки, определяющие количество неправильно классифицируемых объектов на интервалах [t1, tn] и [tn+1, tn+m] соответственно;
– оценки, определяющие количество неправильно классифицируемых объектов на интервалах [t1, tn] и [tn+1, tn+m] соответственно; 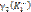 и
и  – суммарные оценки, учитывающие положение неправильно классифицируемых объектов на интервалах [t1, tn] и [tn+1, tn+m] соответственно.
– суммарные оценки, учитывающие положение неправильно классифицируемых объектов на интервалах [t1, tn] и [tn+1, tn+m] соответственно.
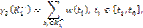

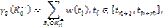
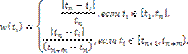
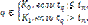
 к какому-либо классу определяется по формуле
к какому-либо классу определяется по формуле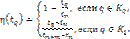
| Постоянный адрес статьи: http://swsys.ru/index.php?id=3346&like=1&page=article |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
| Статья опубликована в выпуске журнала № 4 за 2012 год. [ на стр. 217-221 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Разработка удаленного клиента для автоматизированной передачи данных в UNIX-подобных системах
- Применение методов классификации и кластеризации для повышения эффективности работы прецедентных систем
- Экспертный выбор ключевых показателей взрывных работ на карьерах
- Применение лексического анализа для решения задач автоматической классификации электронной документации
- Классификация общих шаблонов проектирования мультиагентных систем
Назад, к списку статей