Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Верификация на основе симуляции с нахождением и исправлением ошибок для C-дизайнов
Аннотация:Процесс верификации программного обеспечения позволяет удостовериться, соответствует ли дизайн своей спецификации. Анимация спецификации дает возможность реализовать верификацию на основе симуляции. Для локализации и исправления ошибки в случае неудачной верификации необходим доступ к структуре отлаживаемого дизайна. Для этого дизайн должен быть разобран в подходящий вид, в модель. Это минимально необходимые требования к инструменту, который сможет автоматически находить и исправлять ошибки в отлаживаемом дизайне. Для локализации и исправления ошибок в дизайне также требуется реализация алгоритма симуляции модели. В данной статье представлены различные алгоритмы симуляции. Обычно применяется симуляция модели напрямую, когда модель дизайна симулируется с целью получения выводов из вводов, но такой подход не оправдывает себя, так как в этом случае функциональность языка программирования дизайна должна быть практически полностью заново реализована для симуляции. Автор описывает альтернативный подход – симуляция модели дизайна с помощью языка программирования дизайна. Он более оправдан, не требует повторной реализации функциональности, уже имеющейся в языке программирования дизайна, а также позволяет с легкостью реализовать алгоритм динамической нарезки для локализации ошибок. Представлены результаты локализации ошибок с использованием алгоритма динамической нарезки и без него.
Abstract:Process of software design verification makes sure if design holds its specification, existence of the specification that is possible to animate allows to perform simulation-based verification. In order to locate and repair errors if verification fails, we have to have access to the structure of the debugged design. For this purpose the design should be parsed into suitable representation – into the model. Both algorithms: Error Localization process and Error Correction process of the design require model simulation. This article presents different simulation algorithms. Simulation of the model is usually applied directly, when the design model is simulated with the goal to obtain the outputs from the inputs, but this approach is not always suitable, because in this case the functionality of the programming language design should be almost completely re-implemented for simulation. An alternative approach described in this article – design model simulation using design programming language functionality. It is more reasonable and does not require re-implementation of the functionality already available in design programming language. This approach also makes possible implementation of the algorithm of dynamic slicing for Error Localization and Error Correction.
| Авторы: Урмас Репинский (urrimus@hotmail.com) - Таллиннский технологический университет, г. Таллинн (ассистент ), Таллинн, Эстония | |
| Ключевые слова: отладка., автоматическое исправление ошибок, исправление ошибок, диагностика ошибок, верификация на основе симуляции |
|
| Keywords: debug, C design, automatic error correction, error correction, error localization, simulation-based verification |
|
| Количество просмотров: 8139 |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
Дигитальная система (дизайн) – это черный ящик, в которм есть входы и выходы и скрытая внутренняя структура. Чтобы иметь возможность отлаживать систему, она должна быть представлена как белый ящик, то есть иметь подходящий разобранный вид. Разобранное представление системы сохраняется в соответствующей структуре, так называемой модели дизайна, которая позволяет отслеживать процессы во время выполнения системы и вносить изменения в ее структуру. Эти свойства модели необходимы для автоматической отладки системы – верификации, локализации и исправления ошибок. При локализации ошибок наблюдается след выполнения программы системы. Чтобы определить место в системе, ответственное за ошибку, требуется полный доступ к любой части ее модели для внесения соответствующих исправлений. Возможность устанавливать точки наблюдения в исследуемый дизайн позволяет тестировать любую часть дизайна, что необходимо для локализации ошибок. Это минимальные обязательные требования к инструменту, который сможет автоматически находить и исправлять ошибки в отлаживаемом дизайне [1]. С другой стороны, модель может рассматриваться как интегрированная среда разработки (ИСР) для реализации алгоритмов нахождения и исправления ошибок, то есть любая функциональность, которая может быть реализована, полностью зависит от свойств модели. Для отладки дизайнов, написанных на языке C, разработан инструмент FORENSIC (FOrmal Repair ENgine for SImple C), реализованный в рамках проекта FP7 DIAMOND [2] и удовлетворяющий всем требованиям к инструменту, перечисленным выше. FORENSIC предназначен не только для отладки, но и для разработки ПО и находится в открытом доступе в сети Интернет [3]. В составе инструмента автором реализованы алгоритм нахождения ошибок, выполняющий диагностику на основе модели, и алгоритм исправления ошибок, осуществляющий исправление на основе мутаций. Эти алгоритмы позволяют отлаживать довольно часто встречающиеся в реальных дизайнах простые ошибки, такие как неправильная арифметическая операция или ошибка в одном знаке в цифре. Алгоритм динамической нарезки позволяет повысить точность диагностики. Не менее важна проблема правильного представления исследуемого дизайна для верификации на основе симуляции. Одно из решений – использование формальных спецификаций, другое, более практичное – использование С-тестовых случаев [4]. В данной работе рассмотрены С-тестовые случаи, или С-исходный код без ошибки. Реализованные в рамках проекта DIAMOND алгоритмы позволяют считать FORENSIC инструментом, применимым как для научных исследований, так и для создания реальных приложений и автоматической отладки ошибок, что позволит сократить время разработки и, следовательно, затраты на нее. Верификация дизайна По статистике, около 70 % времени, отведенного на разработку проекта, занимает верификация дизайнов. Существуют две ее парадигмы – верификация на основе симуляции и формальная верификация. Основное их отличие в том, что для первой необходимы тестовые векторы, а для второй нет. Парадигма верификации на основе симуляции включает четыре компонента: дизайн, тестовые векторы, эталонные выводы и механизм сравнения. Дизайн симулируется с тестовыми векторами, и результат сравнивается с эталонными выводами. Основной принцип верификации на основе симуляции показан на рисунке 1. Формальная верификация разделяется на две категории – проверка эквивалентности (определяется, являются ли две реализации функционально эквивалентными) и верификация свойства (определяется, всегда ли имеется определенное свойство у реализации) [4]. Во время формальной верификации решение о том, являются ли реализации неэквивалентными, однозначно в отличие от верификации на основе симуляции, при которой результат зависит от выбора тестовых векторов для симуляции. В данной работе описано использование верификации на основе симуляции. Из парадигмы верификации на основе симуляции следует, что спецификация должна иметь формат, позволяющий проводить анимацию и получать эталонные выводы. Спецификация должна описывать дизайн на языке С и быть легко реализируемой. Требования к спецификации Как следует из рисунка 1, для проведения верификации на основе симуляции необходимы эталонные выводы, которые могут быть получены при анимации спецификации, оформленной в надлежащем формате. В общем, спецификация – это документ, однозначно определяющий технические требования к предметам, материалам или сервисам. Спецификация в системном проектировании и в разработке программ – это описание системы, которая будет создана, руководство, необходимое тестерам для верификации. Кроме того, спецификация используется для верификации на основе симуляции.
В случае неформальных спецификаций присутствует так называемый человеческий фактор, поскольку инженер верификации самостоятельно создает тестовые сценарии и гарантирует, что дизайн соответствует своей спецификации. С другой стороны, более целесообразно, а иногда и экономически выгоднее использовать формальные спецификации. При этом инженер верификации может следовать спецификации без написания дополнительного тестового кода или даже автоматически сравнивать эталонные выводы с выводами, полученными в процессе симуляции дизайна. Задача инженера во втором случае более ясна и может быть автоматизирована с помощью инструментов для автоматической верификации, и FORENSIC – один из них. Устранение влияния человеческого фактора на процесс верификации дизайнов может играть решающую роль в индустрии разработки ПО. Спецификации можно разделить на две категории – определенные и неопределенные. Спецификации, которые можно анимировать, выводы которых зависят только от входов и никакие дополнительные допущения не используются, являются определенными [6]. В инструменте FORENSIC реализована верификация с исправлением ошибок на основе симуляции С-дизайнов и использован наиболее подходящий, по мнению автора, формат спецификации для такой системы – С-тестовые случаи, или С-исходный код без ошибки. Для подобной спецификации дополнительная реализация анимации может быть заменена такой же симуляцией, какая применяется для верификации, что облегчает реализацию инструмента, а также позволяет задействовать одних и тех же специалистов для создания дизайна и спецификации, так как, кроме знания языка программирования, никакие дополнительные знания не требуются. Спецификации, созданные на языках программирования высокого уровня (Java, C, C++), уже используются в индустрии ПО [4]. Язык, на котором реализована спецификация, называется языком верификации. Реализации и функциональные компоненты FORENSIC FORENSIC – реализация алгоритмов верификации на основе симуляции с локализацией и исправлением ошибок. Две различные реализации алгоритмов представлены на рисунке 2: на 2а показана основная реализация алгоритмов инструмента FORENSIC, а на 2б – более экономная. Отличие их в том, что в первом случае реализована симуляция отлаживаемого дизайна с целью получения выводов, а во втором такой независимой симуляции нет, реализация более экономная, потому что и для получения выводов, и для диагностики, и для исправления ошибок требуется симуляция дизайна, и эти симуляции можно совместить. С другой стороны, реализация на рисунке 2а использует симуляцию исходного С-дизайна, а не симуляцию модели, что упрощает структуру инструмента. Но если дизайн разобран верно, без ошибок, выводы симуляции модели и дизайна должны быть идентичными.
· Вводы-выводы – данные, необходимые для работы инструмента. На рисунке 2 контур блока – сплошная тонкая линия. · Структуры данных, где сохраняется информация во время выполнения инструмента. Основная структура данных – модель инструмента FORENSIC. · Функциональность, такая как внешний интерфейс, внутренний интерфейс, алгоритмы симуляции и анимации, алгоритмы локализации и исправления ошибок. Функциональность может быть дополнительно изменена или расширена, проект FORENSIC и исходные коды находятся в открытом доступе в сети Интернет. Определение модели. Для верификации дизайна и последующей локализации (диагностики) и исправления ошибок модель, которая является подходящим описанием дизайна как белый ящик, должна быть разработана и реализована. В инструменте FORENSIC модель обрабатываемого дизайна – специальный случай направленного графа – гамак. Определение 1. Диаграф – это структура , где N – множество вершин, E – множество ребер, принадлежащих N×N. Если (n, m) принадлежит E, то n – непосредственный предок m и m – непосредственный преемник n. Путь из вершины n к вершине m является списком длиной k таких вершин p0, p1, ..., pk, что p0=n1, pk=n2, и для всех i, 1≤i≤k–1, (pi, pi+1) принадлежит E. Определение 2. Направленный граф – это структура , где – диаграф, n0 принадлежит N и существует путь из n0 ко всем остальным вершинам, принадлежащим N; n0 называется начальной вершиной. Определение 3. Гамак-граф – это структура H=, которая удовлетворяет свойству, что и являются направленными графами. Обратим внимание, что, как обычно, E-1={(a, b)|(b, a) принадлежат E}; ne – конечная вершина [7]. Гамак является частным случаем направленного графа. Основное различие между ними в том, что гамак имеет одну конечную вершину, а направленный граф не обязан подчиняться этому требованию. Алгоритм симуляции. Диагностика или локализация ошибок начинаются, если дизайн не соответствует своей спецификации, если выводы дизайна не согласуются с эталонными выводами и верификация (процесс, определяющий соответствие дизайна своей спецификации) требует симуляции дизайна. Диагностика сама по себе тоже требует симуляции модели как наиболее важного и трудоемкого компонента любого инструмента, который имел бы возможность находить ошибки в дизайне. Поэтому детально опишем реализованную в FORENSIC методологию симуляции. Симуляция модели, являющейся гамаком, реализована в инструменте с использованием С-функциональности. Преимущество использования функциональности языка С для симуляции модели С-дизайна над симуляцией С-модели заключается в следующем. Если использовать прямую симуляцию модели для получения выходных значений, то все логические операторы модели, присутствующие в дизайне, должны быть реализованы для симуляции и все значения переменных во время симуляции должны где-то сохраняться. Типы переменных могут быть различными – ссылки, массивы, сложные структуры данных и т.д. – практически модель хранения данных языка программирования С должна быть rе-реализована, что трудоемко и проблематично. Если же проводить симуляцию, используя С-функциональность, модель можно записать в исполняемый файл, инструментировать ее необходимыми операторами, а результат симуляции записать в файл, который будет доступен после симуляции. Это не требует rе-реализации С-функциональности и позволяет получать любые необходимые данные о симуляции модели. При этом не теряется какая бы то ни было функциональность, но в результате имеется более быстрая симуляция, что критично, так как симуляция – наиболее важный компонент диагностики на базе модели и верификации на основе симуляции в общем. Кроме того, данная методология позволила реализовать механизм динамической нарезки для диагностики. Такие же принципы можно применить и для симуляции Java- или VHDL-дизайнов. Диагностика на основе модели. Определение 4. Активированные вершины Na, принадлежащие N во время симуляции с вводами iÎI графа гамак H=, – это вершины, которые принадлежат активированному пути P из вершины n0 к вершине ne. Активированный путь P из вершины n к вершине m – список k – p0, p1, ..., pk, такой, что p0=n1, pk=n2, и для всех i, 1≤i≤k–1, (pi, pi+1) принадлежит E. Алгоритм 1. Диагностика на основе модели. Модель верифицируется на основе симуляции – симулируется с вводами I и для каждого ввода iÎI выводы симуляции сравниваются с выводами эталонных выводов анимации спецификации. Если верификация не удалась, то есть выводы не соответствуют эталонным, для всех соответственных активированных вершин симуляции Na увеличивается failed-счетчик, иначе увеличивается passed-счетчик. После симуляции алгоритмы ранжирования применяются к счетчикам и активированные вершины сортируются в соответствии с рангом. Выявленные в результате диагностики вершины с высоким рангом – это кандидаты на исправление. Алгоритм динамической нарезки – техника, которая применяется после каждой симуляции с вводом iÎI и позволяет удалить из активированного пути компоненты, не влияющие на результат симуляции. Эти компоненты могут быть константой или кодом дизайна и т.д. Определение 5. Слой динамической нарезки включает в себя активированные вершины NsÎN гамак-графа H=, имеющие влияние на результат симуляции. Вершины, находящиеся не в слое Для выявления таких вершин потребуются определения изменяемых и используемых переменных в компоненте – вершине гамак-графа. Определение 6. Пусть V – множество переменных, существующих в дизайне P и в модели H дизайна P, которая является гамак-графом H=. Тогда для каждой вершины nÎN имеются два множества, каждое из которых принадлежит V: REF(n) – множество переменных со значениями, используемыми в n, DEF(n) – множество переменных со значениями, изменяемыми в n [8]. Алгоритм 1. Динамическая нарезка. Во время исполнения данного алгоритма вычисляются используемые глобальные переменные gREF на момент обработки каждого активированного компонента модели или активированной вершины nÎNаÎN гамак-графа H=. Выполнение алгоритма осуществляется от конечной активированной вершины ne к начальной n0. На начало симуляции gREF=Æ. Если компонент n – это С-функция или условие, то используемые переменные REF(n) в компоненте добавляются в множество глобальных используемых переменных gREF=gREFÚREF(n). Точки наблюдения могут быть последними исполняемыми компонентами в модели, и переменные, которые выводятся точками, записываются в множество глобальных используемых переменных gREF, так как точки наблюдения assert(...) или FORENSIC_...() – функции, что верно. Если компонент n – присвоение, то используемые переменные REF(n) в компоненте добавляются в множество глобальных используемых переменных тогда и только тогда, когда изменяемые переменные DEF(n) принадлежат множеству глобальных используемых переменных gREF, иначе компонент находится не в слое, не имеет влияния на результат симуляции и может быть удален из списка активированных вершин. Определяемые переменные DEF(n) удаляются из списка глобальных используемых переменных, так как они переопределяются: DEF(n)ÎgREF & gREF=(gREF – DEF(n)) ÚREF(n) Ù (gREF–DEF(n)), и n не в слое. Пример реализации алгоритма динамической нарезки показан на рисунке 3.
Исправление ошибок. После окончания локализации можно попытаться исправить ошибку(и) в дизайне. Во внутреннем интерфейсе на основе симуляции FORENSIC реализован алгоритм исправления ошибок на основе мутаций.
Алгоритм исправления ошибок на основе мутаций заключается в следующем: компоненты – вершины гамак-графа H= мутируются и далее исправленная модель верифицируется на основе симуляции для проверки факта исправления мутацией ошибки. Если симуляция удалась, ошибка найдена и исправлена, если нет, мутируется очередной компонент или применяется следующий тип мутаций. Мутации, реализованные в алгоритме исправления ошибок на основе мутаций back-end на базе симуляции FORENSIC, следующие. · Мутации в операторах – операторы в кандидатах на исправление мутируются с операторами из той же группы операторов. · Основные мутации констант. Это добавление 1 к константе (C®C+1), удаление 1 от константы (C®C–1), установление константы на ноль (C®0) и отрицание константы (C®–C). · Мутации в цифрах констант. Значения 0, ..., 9 заменяют каждую цифру десятичного значения константы по очереди. Мутация применяется ко всем константам независимо от того, каким числом является ее значение – целым или с плавающей запятой. · Округление цифр с плавающей запятой. Цифры с плавающей запятой (в С++ float и тип double) заменяются округленными (округление применяется вверх и вниз). Для мутаций в операторах операторы поделены на следующие группы. · Арифметические операторы: плюс (+), минус (–), умножение (*), деление (/), модуль (%). · Операторы присваивания: присваивание (=), присваивание плюс (+=), присваивание минус (–=), присваивание умножение (*=), присваивание деление (/=), присваивание модуль (%=). · Операторы сравнения: меньше (<), больше (>), равно (==), не равно (!=), меньше равно (£), больше равно (³). · Логические операторы: логическое И (&&), логическое ИЛИ (||). · Операторы смещения битов: смещение битов налево (<<), смещение битов направо (>>), битовое И (&), битовое ИЛИ (|), битовое ИЛИ-исключающее (^). · Операторы смещения битов с присваиванием: смещение битов налево с присваиванием (<<=), смещение битов направо с присваиванием (>>=), битовое И с присваиванием (&=), битовое ИЛИ с присваиванием (|=), битовое ИЛИ-исключающее с присваиванием (^=). · Унарные арифметические операторы: унарный плюс (+), унарный минус (–). · Операторы повышения/понижения: повышение до (++x), повышение после (x++), понижение до (– –x), понижение после (x– –). · Унарные логические операторы: логическое НЕТ (!), битовое дополнение (~). На основе мутаций невозможно исправить сложные ошибки, но этот алгоритм имеет свои преимущества. Классы ошибок, поддерживаемые алгоритмом исправления ошибок на основе мутаций, часто встречаются в реальных программах, кроме того, алгоритм относительно быстрый и надежный. Экспериментальные данные Эксперименты для проверки работоспособности системы были проведены с использованием дизайнов, разработанных Исследоватальским центром Сименс и доработанных Мэри Жан Харрольд и Грегг Ротермель [9]. Данные дизайны написаны на языке С и, следовательно, подходят для исправления с помощью FORENSIC. Описание дизайнов. Дизайны – это С-программы с разными функциональностями: tcas – логические/арифметические вычисления; print_tokens, print_tokens2 – обработка текста; replace – обработка текста; schedule, schedule2 – использование С-структур и объединений; tot_info – арифметические вычисления. Более детальное описание дизайнов приведено в таблице 2. Таблица 2
Результаты экспериментов исправлений на основе мутаций для tcas-дизайна представлены в таблице 3.
Экперименты для остальных дизайнов аналогичны. Сводка экспериментальных результатов отражена в таблице 4. Сравнение экспериментальных результатов В работе [10] представлены эксперименты исправлений на основе мутаций с использованием дизайнов [9]. В таблице 5 результаты из [10] сравниваются с экспериментальными результатами с использованием FORENSIC. Из таблицы можно заключить, что FORENSIC back-end на основе симуляции в среднем исправляет на 35,88 % ошибок больше. Итак, необходимо отметить, что процесс разработки ПО сложен и затратен. Любой инструмент, упрощающий этот процесс и уменьшающий затраты, полезен. FORENSIC – попытка разработки такого инструмента. На момент релизации в январе 2012 г. верификация и исправление ошибок поддерживались только для С-дизайнов, алгоритмы нахождения и исправления еще не стандартизированы, не определен формат спецификаций, но любые аспекты программы при необходимости могут быть модернизированы. В проект несложно включить также поддержку С/С++ и SystemC-дизайнов. Когда использование спецификаций будет автоматизировано, подобные инструменты станут предметами первой необходимости в процессе разработки программ. В заключение следует перечислить основные свойства инструмента FORENSIC. 1. Выбор модели представления кода – важный аспект инструмента, структура представления влияет на функциональность. Таблица 4
Таблица 5
Примечание: А – количество дизайнов, исправленных в [10]; В – количество дизайнов, исправленных с помощью FORENSIC back-end на основе симуляции; С – всего дизайнов; D – количество дизайнов, исправленных с использованием FORENSIC дополнительно к [10], (B-A)*100/C, %. 2. Формат спецификаций отлаживаемого дизайна должен поддерживать анимацию. 3. Алгоритм диагностики может быть простым, как диагностика на основе мутаций. Различные алгоритмы диагностики могут применяться, если в дизайне не одна, а несколько ошибок. 4. Алгоритм исправления ошибок должен поддерживать исправление максимального количества типов ошибок, и следовательно, алгоритм исправления ошибок может быть сложным, то есть состоять из нескольких алгоритмов, примененных один за другим. 5. Симуляция и анимация – это функциональности, которые занимают наибольшее количество времени. Использование С-функциональности для симуляции и анимации является наиболее разумным подходом, позволяющим получать максимальную надежность и скорость. Кроме того, С-функциональность для симуляции дает возможность реализовать динамическую нарезку для диагностики. Литература 1. Chepurov A., Jenihhin M., Raik J., Repinski U., Ubar R. High-level design error diagnosis using backtrace on decision diagrams. 28th Norchip Conf., Tampere, FINLAND, 2010. 2. Diamond FP7 Project. URL: http://fp7-diamond.eu/ (дата обращения: 4.05.2012). 3. University of Bremen, Faculty of Computer Science. URL: http://www.informatik.uni-bremen.de/agra/eng/forensic.php (дата обращения: 4.05.2012). 4. William K. Lam: Hardware Design Verification. Simulation and Formal Method- Based Approaches. Prentice Hall. Profession Technical Reference, 2005, pp. 1–23. 5. Jadish S. Lecture notes on Design & Analysys of Accountuing Information Systems, URL: http://www.albany.edu/ acc/courses/acc681.fall00/681book/681book.html (дата обращения: 02.03.2012). 6. An approach to animating Z specifications, Xiaoping Jia, Computer Software and Applications Conf., COMPSAC-95. Proceedings., Nineteenth Annual International, 1995, pp. 108–113. 7. Kas'janov V.N. Distinguishing Hammocks in a Directed Graph, Soviet Math. Doklady, 1975, Vol. 16, no. 5, pp. 448–450. 8. Mark Weiser, Program Slicing, IEEE Transactions on Software Engineering, 1984, Vol. SE-10, no. 4, pp. 352–357. 9. Bug Aristotle Analysis System – Siemens Programs, HR Variant, URL: http://pleuma.cc.gatech.edu/aristotle/Tools/subjects/ (дата обращения: 02.03.2012). 10. Debroy V. and Wong W.E. Using Mutation to Automatically Suggest Fixes for Faulty Programs, Software Testing, Verification and Validation (ICST), 3rd International Conf., 2010, pp. 65–74. 11. Kang J., Seth S.C., Yi-Shing Chang, Gangaram V. Efficient Selection of Observation Points for Functional Tests. Quality Electronic Design, ISQED-2008, 9th International Symposium on, 2008, pp. 236–241. |
 Спецификация может быть формальной или неформальной. В процессе разработки информационных систем для бизнеса неформальные спецификации, использующие графическое моделирование, применялись со второй половины 1970-х годов. В последнее время были разработаны языки формальных спецификаций (Larch, VDM, Z, FOOPS и OBJ). Сегодня использование спецификаций находится на начальной стадии, но будет играть значительную роль в ближайшем будущем. Такие спецификации – это попытка математически описать структуру, функции и поведение информационных систем [5].
Спецификация может быть формальной или неформальной. В процессе разработки информационных систем для бизнеса неформальные спецификации, использующие графическое моделирование, применялись со второй половины 1970-х годов. В последнее время были разработаны языки формальных спецификаций (Larch, VDM, Z, FOOPS и OBJ). Сегодня использование спецификаций находится на начальной стадии, но будет играть значительную роль в ближайшем будущем. Такие спецификации – это попытка математически описать структуру, функции и поведение информационных систем [5].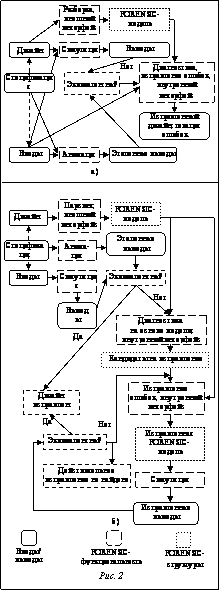 Компоненты реализаций FORENSIC разбиты на несколько групп, которые отвечают за различную функциональность.
Компоненты реализаций FORENSIC разбиты на несколько групп, которые отвечают за различную функциональность. =N–Ns, могут быть удалены из активированного пути для симуляции с вводом i без изменения результата симуляции.
=N–Ns, могут быть удалены из активированного пути для симуляции с вводом i без изменения результата симуляции.![Подпись: Таблица 1
Класс ошибки Примеры Поддержка back-end
на основе симуляции FORENSIC
AOR (arithmetic operator replacement) ADD (+), SUB(-), MULT(*), DIV(/), MOD(%) Да
ROR (relational operator replacement) EQ(==), NEQ(!=), GT(>), LT(<), GE(³), LE(£) Да
LCR (logical connector replacement) AND (&&), OR(||) Да
ASOR (assignment operator replacement) (+=), (-=), (=) Да
Мутация целого числа 500→550, 740→700, 1→2, a[0]→a[1], n=0→n=1 Частично
Мутация числа с плавающей запятой 0,0→0,1, 0,0→1,0 Частично
Неверный индекс массива a[i-1]→a[i], a[i+1]→a[i], a[3]→a[4], a[var]→a[0] Частично
+1 добавлен/отсутствует r=i→r=i+1, f(a, b, c+1)→f(a, b, c), if(i)→if(i+1) Частично
Мутация константы (константа замене-на другой константой) TRUE→FALSE Нет
Мутация числа с плавающей запятой 2,5066282→2,50663
EPS→EPS-0,000001 Частично
Код отсутствует/Код добавлен /* && (Cur_Vertical_Sep>MAXALTDIFF);
missing code */ Нет
Функция заменена константой Inhibit_Biased_Climb()→Up_Separation Нет
Изменение логики Brackets removed Частично
Ошибка в операторах ввода-вывода fprinf, getch Да](uploaded/image/2012-4/image774.gif) Важно заметить, что переменные в дизайне могут быть различных типов, например, составными или частью составной переменной, поэтому использование имен для сохранения переменных в множествах REF(n), DEF(n) или gREF(n) непрактично. Гораздо удобнее сохранять уникальный адрес переменной, который может быть получен, если симуляция модели для диагностики и, следовательно, для динамической нарезки производится с использованием С-функциональности. Именно использование симуляции с использованием С-функциональности позволило практически реализовать алгоритм динамической нарезки.
Важно заметить, что переменные в дизайне могут быть различных типов, например, составными или частью составной переменной, поэтому использование имен для сохранения переменных в множествах REF(n), DEF(n) или gREF(n) непрактично. Гораздо удобнее сохранять уникальный адрес переменной, который может быть получен, если симуляция модели для диагностики и, следовательно, для динамической нарезки производится с использованием С-функциональности. Именно использование симуляции с использованием С-функциональности позволило практически реализовать алгоритм динамической нарезки. Ошибки в дизайне делятся на множество классов, и различные методы исправления ошибок исправляют разные ошибки. Примеры ошибок в дизайне приведены в таблице 1.
Ошибки в дизайне делятся на множество классов, и различные методы исправления ошибок исправляют разные ошибки. Примеры ошибок в дизайне приведены в таблице 1.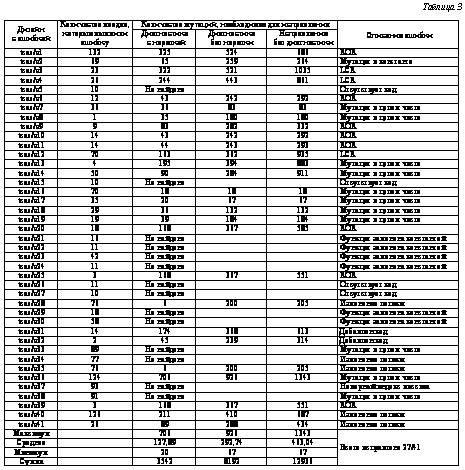
| Постоянный адрес статьи: http://swsys.ru/index.php?id=3348&page=article |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
| Статья опубликована в выпуске журнала № 4 за 2012 год. [ на стр. 229-237 ] |
Назад, к списку статей