Технология автоматизированной оценки содержательной близости текстов
| Кузнецов Л.А. (kuznetsov@stu.lipetsk.ru) - Липецкий государственный технический университет (профессор), Липецк, Россия, доктор технических наук, Кузнецова В.Ф. (kuznetsov@stu.lipetsk.ru) - Липецкий государственный технический университет (доцент ), Липецк, Россия, кандидат технических наук | |
| Ключевые слова: близость текстов., энтропия, теория информации, математическая модель текста, разложение текста, семантические компоненты, вероятностная модель, технология оценки подобия текстов, текст |
|
| Keywords: semantic similarity of text’s, entropy, information theory, mathematical text model, components expansion of text, semantic components, probabilistic model, conformance evaluation technology of texts, text |
|
|
|
|
Проблема автоматической оценки содержательной близости информационных источников, представленных на естественном языке (текстов), весьма актуальна для информационных технологий. В настоящее время в информационно-поисковых системах при классификации текстов, проверке на плагиат [1] применяются статистические подходы на основе векторно-пространственной модели текста, предложенной в работе [2]. Формальной основой этой модели является скалярное произведение векторов, которое, как известно, изменяется от нуля для ортогональных векторов до единицы для коллинеарных. Формальным представителем текста является вектор частот входящих в него слов, а мерой близости текстов – косинус угла между векторами, соответствующими сравниваемым текстам. В такой модели совершенно не используются семантические характеристики слов и словосочетаний, которые представлены в грамматиках языков и составляют их основное содержание. Поэтому при использовании данной модели фактическая близость текстов устанавливается последующим субъективным анализом. При субъективной интеллектуальной оценке содержательного подобия текстов сопоставляются содержательные характеристики объектов, их состояний, действий, условий, результатов и т.п., которые могут быть названы семантическими компонентами текста. В статье излагается оригинальная технология, позволяющая автоматизировать процесс оценки семантической близости текстовых документов. Технология базируется на формализации этапов обработки текстов, используемых по умолчанию при субъективном сопоставлении. Численные примеры иллюстрируют некоторые возможности разработанной технологии. Основная идея Технологию оценки степени семантической адекватности текстов, используемую субъективно, можно представить последовательностью следующих основных этапов. 1. Анализ содержания одного из текстов (условно эталонного) и конкретизация его содержательных аспектов. О ком (чем) в нем сообщается, что, когда, как, при каких обстоятельствах, для кого, чего и т.п. он делал, сделал и т.д. При этом выделяются наиболее существенные для последующего сравнения содержательные аспекты текста. Содержательные аспекты могут именоваться семантическими компонентами исследованного текста. 2. Исследование других текстов и извлечение из них информации по всем семантическим компонентам. 3. Неформальное сопоставление и оценка близости содержания одноименных компонентов сравниваемых текстов экспертом или группой экспертов. 4. Свертка оценок по отдельным компонентам в общую оценку семантического содержания текста. 5. Сравнение оценок содержания текстов и упорядочение их каким-либо образом по степени близости к эталонному тексту. Для автоматизации технологии оценки близости текстов необходимо разработать процедуры автоматической реализации перечисленных этапов. Для первого этапа необходимо разработать автоматические процедуры формирования спектра содержательных аспектов – семантических компонентов текста, достаточно полно отражающих содержание текста в представляющем интерес смысле. Автоматизация второго этапа требует разработки процедур автоматического разложения текстов по заданной системе семантических компонентов. В результате разложения исходный текст структурируется в виде совокупности компонентов. Автоматизация третьего этапа может базироваться на введении количественной меры наполнения семантических компонентов в сопоставляемых текстах и на процедурах автоматической оценки этой меры в разных текстах. Наличие меры содержания компонентов при необходи- мости позволяет осуществлять поэлементное сравнение текстов. Для автоматизации четвертого этапа необходима возможность соизмерения семантических компонентов текста друг с другом посредством некоторых весов. На основе весов должна формироваться общая оценка информационной меры текста по оценкам значимости отдельных компонентов, составляющих текст. Наконец, для автоматизации последнего этапа сле- дует обеспечить автоматическое сопоставление содержания текстов и формирование значения меры, отражающей близость их информационного содержания. Возможности синтеза перечисленных автоматизированных процедур открываются при формализации текста в виде вероятностной модели, для количественных исследований и характеризации которой может быть применен математический аппарат теории информации. Грамматики структурированных языков определяют их морфологическую и синтаксическую структуры и содержат вербальные правила и алгоритмы отнесения отдельных слов к конкретным компонентам структур. В настоящее время большая часть этих правил и алгоритмов реализованы в виде автоматических инструментов морфологического и синтаксического анализа текстов, позволяющих производить разбор текстов и достаточно однозначно устанавливать принадлежность конкретного слова к конкретным морфологическим и синтаксическим компонентам. Морфология структурирует слова по их принадлежности к частям речи, синтаксис определяет принадлежность слов к членам предложения. Части речи и члены предложения несут достаточно узкую и определенную семантическую нагрузку. Вопросы, используемые при отнесении слов к определенным грамматическим (морфологическим и синтаксическим) компонентам, в значительной мере отражают и их семантическую роль в тексте. Для сопоставления содержания текстов необходимо ввести систему семантических компонентов, которые отражают все содержательные представления, заключенные в текстах и существенные для оценки их близости. С помощью инструмента вопросов могут быть разработаны процедуры установления соответствия между грамматическими и семантическими компонентами и на их основе определены правила формирования семантических компонентов текста на базе грамматических компонентов. Во многих случаях они могут отождествляться. Разработанная методология автоматической оценки адекватности текстов обеспечивает формальное представление этапов описанной выше схемы субъективной оценки, базируясь на использовании грамматических характеристик естественного языка для оценки степени близости содержания текстов. Для этого текст формализуется в виде вероятностно-статистической модели, представляющей композицию единой системы семантических компонентов. На первом этапе представленной интеллектуальной технологии формируется множество семантических компонентов на основании одного из текстов, принимаемого за эталонный. Для структуризации текстов по грамматическим компонентам могут быть использованы уже существующие автоматизированные версии грамматического разбора. Дополнительно к ним в большинстве структурированных языков возможно введение формальных правил соотнесения семантических компонентов с грамматическими: морфологическими (существительными, глаголами, прилагательными и пр.) и синтаксическими (подлежащими, сказуемыми, обстоятельствами и т.д.) компонентами языка. При формализации семантические компоненты классифицируются случайными событиями. На втором этапе осуществляется автоматическое разложение текстов по определенной на первом этапе системе семантических компонентов. При этом отдельные элементы исследуемого текста – слова или составные конструкции – трактуются элементарными случайными событиями (исходами). Система семантических компонентов определяет семантическую структуру текста. Вероятности случайных событий являются их мерой. На третьем этапе схемы сопоставляются вероятности одноименных семантических компонентов в текстах. На четвертом этапе схемы определяется энтропия текстов, которая является мерой общего количества информации в конкретном случайном объекте. На пятом этапе – оценка близости семантического содержания – определяется количество взаимной информации в сопоставляемых объектах. Технология базируется на представлениях теории информации. Тексты формально представляются в виде образов вероятностно-статистической модели, определенных на множестве образующих их слов. Слова объединяются в группы – случайные события, по вероятностям которых определяется энтропия, являющаяся оценкой количества информации в вероятностных образах текстов. Количество совместной (совпадающей) информации в образах двух текстов, являющееся мерой их близости, оценивается взаимной информацией, непрерывно изменяющейся от нуля при полном несовпадении текстов до количества информации в обоих текстах при совпадении. Представление сравниваемых текстов в виде вероятностно-статистических образов [3] позволяет по единой шкале оценить количество информации в текстах, количество общей информации в текстах и количество информации, отличающей тексты, то есть содержащейся в одном и не содержащейся в другом. Принципиальным является вероятностный подход к определению семантических компонентов текста, которые могут быть представлены случайными наборами конструкций языка. Вероятностно-статистическая модель текста В теории вероятностей [4] вводится вероятностная модель, позволяющая отразить всю информацию об объекте, состояния которого являются случайными величинами. Множество реализаций, или пространство элементарных исходов W={w1, w2, …, wn}, случайной величины и их вероятности р(wi) – это полная характеристика модели. При исследовании содержания случайной величины вводится дифференциация пространства W ее элементарных исходов wi, i=1, 2, …, n, на подпространства AjÍW, j=1, 2, …, J, которые отражают содержательные особенности состояний случайной величины. Подпространства или подмножества Aj, j=1, 2, …, J, формируются из элементарных событий wi множества W={w1, w2, …, wn} с помощью операций логического сложения, умножения и отрицания и являются случайными событиями. Их система AjÎW, j=1, 2, …, J, дополненная невозможным Æ и достоверным W событиями, называется алгеброй: À={A1, A2, …, Aj, Æ, W}. (1) Вследствие того что вероятности реализаций р(wi) известны, по ним вычисляются вероятности случайных событий, составляющих алгебру:
Пространство элементарных исходов W={w1, w2, …, wn}, алгебра (1) и вероятности (2) образуют вероятностную модель случайного объекта: Mw={W, À, P(Aj)}. (3) Модель случайного объекта (3) трансформируется в вероятностно-статистическую модель информационного объекта приданием соответствующего содержания ее компонентам. В вероятностной модели текстового документа множество элементарных исходов W={w1, w2, …, wn} образуют слова, составляющие текст. Выбор слов и стиля для отражения некоторого содержания зависит от множества причин и является случайным. Индивидуальность моделируемого объекта в вероятностной модели отражается алгеброй событий À. Алгебра событий в вероятностно-статистической модели информационного объекта представляет систему семантических компонентов, суперпозиция которых отражает содержание текста. Подчеркнем, что речь идет об оценке близости семантики двух текстов, один из которых может быть условно принят за эталонный, полностью определяющий сравниваемое содержание. Система семантических компонентов, по которым раскладывается содержание текстов, определяется и формируется по содержанию эталонного с учетом задаваемой степени детализации представления. Благодаря грамматической структуризации языков и наличию инструментов автоматизации грамматического анализа текстов формирование системы семантических компонентов может быть автоматизировано. Данная система формируется на основе частей речи, членов предложения, иных конструируемых из них многословных структур, которые в совокупности позволяют отразить с требуемым уровнем детализации семантическое содержание эталонного текста. Для автоматизации формирования системы семантических компонентов текста могут использоваться существующие автоматические морфологические и синтаксические анализаторы текста. После определения семантических компонентов по ним, как по базису, раскладываются тексты и определяются вероятности компонентов. В результате формируется вероятностно-статистический образ i-го текста в виде Oi={Wi, À, P(Aij)}. (4) В (4) учтено, что множества слов, составляющих тексты, различны и, следовательно, наполнение семантических компонентов Aij и их вероятности в разных текстах различны, поэтому они снабжены индексами, идентифицирующими текст. Система семантических компонентов едина для всех сопоставляемых текстов, поэтому образы текстов (4) могут использоваться для оценки степени их совпадения. Мера семантической близости информационных объектов Инструмент для получения количественной оценки подобия информационных объектов может быть разработан на основе теории информации, в которой для оценки близости сообщений введена количественная мера информации. В [5] предложено количество информации, содержащейся в случайном объекте Mw (3), оценивать энтропией
где обозначения совпадают с использованными выше. Из (5) следует, что энтропия Hw (мера количества информации случайной величины Mw) определяется распределением ее вероятностей (2). Вследствие того что P(wi)£1 и lnP(wi)£0, для получения положительной величины в (5) используется знак минус. Образы текстов (4) позволяют оценить количество информации в каждом из них:
При сопоставлении l-го и k-го текстов образ общего вероятностно-статистического объекта формируется на объединении этих текстов, имеющем вид
В (7) используется множество элементарных событий Wlk={Wl+Wk} – объединение всех слов, принадлежащих текстам l и k. Алгебра объединенного объекта должна отражать принадлежность элементов множества wÎWlk к текстам l и k, поэтому каждый из семантических компонентов (1) разделяется на три:
компоненты определяются следующим образом:
где в Событие (8а) составляется из слов, входящих в семантические компоненты Aj текстов l и k; компонент (8б) объединяет слова, входящие в семантическую компоненту Aj текста k, но отсутствующие в тексте l; (8в) объединяет слова, входящие в семантическую компоненту Aj текста l, но отсутствующие в тексте k. Других вариантов для слов, присутствующих в двух сопоставляемых текстах, нет: P(wlkÎWlk)=1, P{wlkÏWlÇwlkÏWk}=0. Важно заметить, что система компонентов (8) подобна системе (1), поэтому ее j-е компоненты Вероятности этих j-х компонентов
На основании значений энтропии (6) для l-го и k-го текстов и их совместной энтропии (9) определяется взаимная информация текстов:
В данном контексте совместная информация может трактоваться как количество информации из текста l, содержащееся в тексте k. Вследствие симметрии (10) индексы можно поменять местами. Получаемое в соответствии с (10) количество совместной информации согласуется с интуитивными представлениями о близости содержания текстов. Чтобы убедиться в этом, можно рассмотреть два предельных варианта: 1 – полное совпадение текстов l и k, 2 – их полное несовпадение. Если тексты полностью совпадают, то в (6) Другой крайний случай получается при полном несовпадении текстов. При этом, очевидно, не будет слов, принадлежащих одновременно текстам l и k. Поэтому все компоненты (8а) приобретут нулевую вероятность ( В теории информации принято 0ln0=0 и, следовательно, Таким образом, количество взаимной информации по (10) при описанном способе определения совместных событий изменяется от нуля при полном различии текстов до количества общей информации, содержащейся в текстах, которое при полном совпадении текстов равно Технология сравнения семантического содержания объектов, опирающаяся на меру количества взаимной информации, может применяться для решения самых разнообразных задач в области обработки информации и в образовательной сфере. Побудительным мотивом разработки технологии явилось стремление создать автоматизированную систему оценки знаний [3], которая позволяла бы исключить (или по крайней мере минимизировать) человеческий фактор при полноценной проверке уровня знаний. Система оценки уровня знаний является подсистемой «Автоматизированной системы поддержки образовательной программы обучения», разрабатываемой на кафедре АСУ Липецкого государственного технического университета. В базу системы заносится учебно-методическая документация, включая специальным образом структурированные конспекты лекций, так что заголовки последнего уровня представляют вопросы для текущей проверки знаний, предпоследнего – вопросы для экзаменационных билетов, а лекционный материал под соответствующими рубриками – эталонный ответ. Перечни вопросов для текущей проверки и экзаменационные билеты формируются случайно автоматизированной системой. Ответы на них обучаемых, введенные в систему, могут оцениваться автоматически по их семантической близости эталону. Так, аттестация учебно-методического обеспечения образовательной программы бакалавра, специалиста, магистра на полноту формальной и содержательной поддержки компетенций, сформулированных в регламенте требований к качеству его подготовки по конкретному направлению или программе, представляет одно из важных практических применений технологии. Разнообразие сфер практического применения технологии обеспечивается широкими возможностями ее адаптации к специфике конкретных задач. Настройка на конкретную задачу достигается заданием соответствующей алгебры (1) или принципа ее автоматического формирования, а алгебра может включать самые различные словосочетания и позволяет сформировать статистический образ информационного объекта, отражающий его специфические аспекты. При поиске информационных объектов, близких к определенному, алгебра может формироваться автоматически на его основе. Автоматизация может опираться на частоты отдельных частей речи (членов предложения), отражаемых в образе эталонного объекта. Повысить качество семантического сравнения информационных объектов можно с помощью условных вероятностей и порождаемых ими условных энтропий, что позволит глубже детализировать формальное представление семантических аспектов исследуемых информационных объектов. Автоматизированная оценка уровня знаний требует сравнения не только объектов на естественном языке, но и информационных объектов, представленных на формальных языках, например математических выражений, формул. При определенной трансформации формального представления подобных объектов изложенная технология может быть использована для оценки степени их близости. Иллюстрация формирования и представления вероятностно-статистического образа текста Базой для экспериментов стал текст на английском языке, содержащий после исключения артиклей, частиц и междометий 174 слова. Исходный текст, называемый эталонным, позволяет пояснить еще раз содержательную трактовку элементов вероятностно-статистических образов, используемых при сопоставлении содержания текстов, и показать возможность их представления в виде обычных таблиц. Множество слов W={w1, w2, …, w174} – это первый элемент вероятностно-статистического образа эталонного текста. На этом множестве задается алгебра (1), структурирующая множество слов W={w1, w2, …, w174}, по системе семантических компонентов, являющейся аналогом алгебры событий в общем случае вероятностной модели. По эталонному тексту была определена минимальная обозримая, отражающая морфологический состав текста система семантических компонентов: À=(А1=Существительное, А2=Глагол, А3=Прилагательное, А4=Наречие, (11) А5=Числительное, А6=Неопределенное слово). Для разложения текста по компонентам (11) разработана автоматическая система (используемые численные результаты получены с помощью варианта системы, разработанной в магистерской диссертации Кондаурова А.С.). В разработанной системе использовался свободно распространяемый продукт Cognitive Dwarf [6], ориентированный на русский и английский языки. Система позволяет выполнять разбор текста со скоростью порядка нескольких килобайт в секунду. Структурированное представление образов текста (4) удобно форматировать в виде таблицы (см. табл. 1). Табличное представление соответствует структуре реляционных БД, которые для преобразования данных при изменении системы компонентов позволяют применять аппарат реляционной алгебры. В общем случае система семантических компонентов может расширяться включением дополнительных компонентов, способствующих более полному отражению содержания текста. Таблица 1 Пример табличного представления вероятностно-статистического образа текста с системой семантических компонентов (11)
Из таблицы 1 видно, что расширение числа семантических компонентов для детализации семантики текста выразится в увеличении числа ее столбцов, а изменение объема текста приведет к изменению числа строк. Эти вариации не влекут изменений в технологии представления и обработки информации. Изменение взаимной информации при заданном уровне различия текстов Исходные данные для выполнения исследования формировались следующим образом. На основе эталонного текста TЭ на английском языке был синтезирован массив его искаженных копий Tj, j=1, 2, …, 20. Для формирования копий на каждом шаге в эталонном тексте 1/20 его слов заменялась отличающимися словами из текста с другой тематикой. Первая искаженная копия, T1, получена из эталонного текста путем замены 1/20 его слов, вторая копия, T2 – заменой в эталоне 2/20 слов и т.д. Для искаженных копий Tj определялась прямая оценка их соответствия эталону в виде доли слов из эталонного текста, сохраненных в копии, по 100-балльной шкале:
где mj – число слов из эталонного текста TЭ в копии Tj; n – число слов в эталоне. Для каждой j-й копии формировался вероятностно-статистический образ Oj на множестве семантических компонентов (11). По нему вычислялась энтропия (6) образа Hj. По образу эталонного текста и копии вычислялась (9) совместная энтропия Hэj и в соответствии с (10) – количество взаимной информации между эталоном и копией Iэj. На рисунке 1 показано соответствие количества совместной информации между эталоном и копиями, определенное по (10), и заданной степенью (12) искажения эталона при формировании копии. На рисунке 1 видно, что значение совместной информации монотонно изменяется при монотонном изменении реального уровня искажения текстов, причем между ними существует линейная связь с коэффициентом линейной корреляции 0,992. Монотонность изменения количества взаимной информации позволяет упорядочивать разные информационные объекты по степени их близости к одному эталонному. Градуировка и пример практического применения информационной меры Количество взаимной информации (10) является абстрактной величиной, а в практических ситуациях может оказаться целесообразным придание мере сравнения некоторого содержательного смысла. Ярким примером является оценка знаний. Объективная и полноценная оценка знаний обеспечивается письменными экзаменами, результаты которых анонимно оцениваются компетентной экспертной комиссией. Принципиальное решение возможно при использовании автоматизированных систем, воспринимающих от обучаемых полноценные ответы и обеспечивающих их оценку на уровне хотя бы среднего преподавателя. Исходными дан Все изложения и эталонный текст были введены в базу системы. Для каждого экземпляра изложения формировался вероятностно-статистический образ и определялось количество взаимной информации IЭj между ним и образом эталонного текста. Далее осуществлялась градуировка ко- личества информации в оценках по принятой в университете 100-балльной шкале. Проградуированные оценки автоматизированной системы сопоставлялись с оценками преподавателя, и определялись характеристики адекватности (табл. 2). Таблица 2 Результаты расчета оценок изложений студентов
Градуировка сводится к установлению однозначного соответствия значений информационной меры (10) оценкам по выбранной шкале. В простейшем случае соответствие количества взаимной информации 100-балльным оценкам может быть получено в виде линейной регрессии y1=a+bx, где x – количество взаимной информации ответа и эталона, вычисляемое автоматически, а y1 – оценка по 100-балльной шкале. Для градуировки могут использоваться более сложные модели, позволяющие учесть конкретные содержательно-методические особенности дисциплин и регламентов. Приведем результаты использования для градуировки более подробной модели: Для первого варианта получена линейная регрессия y1=27,02+61,41 хj, где хj=IЭj – количество взаимной информации в эталонном тексте и j-м изложении; а y1 – автоматически формируемая по нему оценка. Во втором варианте модели пересчета информационной оценки в 100-балльную с весами aj была получена регрессия у2=0,8436 – 242,23 А1+451,27 А2+131,60 А3–262,16 А4–110,75 А5. Значения оценок у1 и у2 приведены соответственно в четвертом и пятом столбцах таблицы 2. Среднеквадратичное отклонение оценок у1 от оценок преподавателя составляет 11,04 балла, коэффициент корреляции равен 0,847. Значения 100-балльных оценок, вычисленные с использованием модели у2, показаны в 5-м столбце таблицы 2. Их среднеквадратичное отклонение от оценок преподавателя составило 6,324 балла, а множественный коэффициент корреляции достиг 0,955. Этот пример показывает возможности повышения адекватности автоматически формируемых оценок идентификацией формул перевода количества информации в баллы реальной шкалы оценок. На рисунке 2 представлено наглядное сопоставление оценок, выставленных преподавателем, и оценок у1 без взвешивания и у2 со взвешиванием частей речи, сформированных автоматически по количеству взаимной информации. Наибольший вклад в ошибку вносят две точки – 16-я и 21-я (в таблице 2 они выделены полужирным шрифтом). При детальном анализе было выяснено, что оценки, выставленные преподавателем, не в полной мере адекватны содержанию изложений. Интересно отметить, что исключение этих точек и расчет по оставшимся 20 точкам принципиально меняют результат: среднеквадратичная ошибка оценки у1 получается равной 1,593 балла, а оценки у2 – 1,248 балла. Как известно, наиболее распространенной является векторно-пространственная модель текста, в которой мерой близости текстов служит косинус угла между векторами, отражающими надлежащим образом преобразованные тексты (в авторских обозначениях): cos(TЭ, Tj)=(TЭ, Tj)/(½TЭ½´ ´½Tj½). Такая мера была вычислена для всех 22 изложений и эталонного текста и сопоставлена с оценками преподавателя. Регрессия для перевода ее значений в 100-балльные оценки имеет вид Q100= =–18,97+116,3cos(TЭ, Tj). Результаты вычислений представлены в 6-м и 7-м столбцах таблицы 2. Среднеквадратичное отклонение прогноза оценки по этой регрессии от оценки преподавателя составило 13,27 балла, а коэффициент корреляции равен 0,769. После удаления из массива проблемных 16-й и 21-й точек ошибка составила 2,155 балла. Для сопоставления ошибок, получаемых по разным технологиям, можно предположить, что ошибка является нормально распределенной случайной величиной, диапазон вариации которой оценивается 3s-м интервалом. При такой оценке возможная максимальная ошибка с использованием предлагаемой методики достигает 3,744 балла, в то время как при использовании векторно-пространственной модели – 6,466 балла.
В заключение отметим, что изложенная оригинальная методологическая основа технологии автоматизированной оценки уровня семантического подобия текстов может быть использована в автоматических системах оценки уровня подобия информационных объектов, представленных на естественном языке. Технология позволяет при оценке подобия объектов формально отразить в виде, допускающем сопоставление, их содержательную сущность, что существенно повышает адекватность формальных образов объектов их реальному содержанию. На этой основе качество автоматизированной оценки близости текстовых документов может быть доведено до уровня, обеспечиваемого экспертами. Технология открывает широкие перспективы разработки автоматизированных систем оценки знаний, которые смогут воспринимать реальные полноценные ответы учащихся на поставленные вопросы и обеспечивать автоматическую оценку уровня адекватности ответа содержанию эталонного ответа, хранящегося в БД системы. Литература 1. Christopher D., Manning, Prabhakar Raghavan & Hinrich Schütz. An Introduction to Information Retrieval, Cambridge Univ. Press, 2009, 569 p. 2. Salton G., Wong A., Yang C.S., Communications of the ACM, 1975, Vol. 18, no. 11, pp. 613–620. 3. Кузнецов Л.А. Теоретические основы автоматизированной оценки знаний // Качество. Инновации. Образование. 2010. № 11. С. 8–19. 4. Гнеденко Б.В. Курс теории вероятностей: учебник. М.: Изд-во ЛКИ, 2007. 448 с. 5. Шеннон К. Математическая теория связи. В кн.: Работы по теории информации и кибернетике; [пер. с англ.; под ред. Р.Л. Добрушина и О.Б. Лупанова]. М.: Изд-во «Иностранная литература», 1963. 6. Программный пакет синтаксического разбора и машинного перевода. URL: http://cs.isa.ru:10000/dwarf/ (дата обращения: 24.04.2011). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 . (2)
. (2)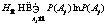 , (5)
, (5) . (6)
. (6) . (7)
. (7)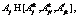 j=1, 2, …, J, (8)
j=1, 2, …, J, (8)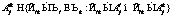 , (8а)
, (8а)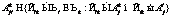 , (8б)
, (8б) , (8в)
, (8в) верхним индексом отмечен образ текста, в который входит рассматриваемое слово, а нижним – образ, в который слово не входит.
верхним индексом отмечен образ текста, в который входит рассматриваемое слово, а нижним – образ, в который слово не входит.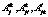 могут быть сформированы непосредственно из компонентов
могут быть сформированы непосредственно из компонентов 
 (9)
(9) . (10)
. (10)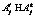 для всех j и, следовательно, Нl=Нk. Далее из (8) видно, что в этом случае содержание семантических компонентов совместного образа
для всех j и, следовательно, Нl=Нk. Далее из (8) видно, что в этом случае содержание семантических компонентов совместного образа  ). Поэтому вероятности будут равны (
). Поэтому вероятности будут равны ( ) для всех
) для всех  . Так что, при полном совпадении текстов количество взаимной информации (10) будет
. Так что, при полном совпадении текстов количество взаимной информации (10) будет  , то есть оно равно сумме ее содержания в каждом из текстов, которые полностью совпадают, поэтому
, то есть оно равно сумме ее содержания в каждом из текстов, которые полностью совпадают, поэтому  .
. для всех j), так что первая сумма в правой части (9) будет
для всех j), так что первая сумма в правой части (9) будет 
 В этом случае содержание семантических компонентов
В этом случае содержание семантических компонентов  совпадет, поэтому будут равны вероятности
совпадет, поэтому будут равны вероятности  , а из (9) следует
, а из (9) следует 
 , что соответствует содержательному смыслу оценки уровня адекватности текстов. Это является достаточным обоснованием использования количества взаимной информации в качестве меры соответствия информационных объектов, представленных на естественном языке.
, что соответствует содержательному смыслу оценки уровня адекватности текстов. Это является достаточным обоснованием использования количества взаимной информации в качестве меры соответствия информационных объектов, представленных на естественном языке. (12)
(12)
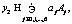 где А0=1, Aj для j=1, …, 6 – семантические компоненты (11); аj – веса семантических компонентов (в примере – частей речи), которые определялись методом наименьших квадратов по рядам значений оценок преподавателя и количеству взаимной информации.
где А0=1, Aj для j=1, …, 6 – семантические компоненты (11); аj – веса семантических компонентов (в примере – частей речи), которые определялись методом наименьших квадратов по рядам значений оценок преподавателя и количеству взаимной информации.
http://swsys.ru/index.php?id=3377&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Вероятностная модель медицинской диагностики
- Задачи информационного поиска в рамках интеллектуальной распределенной программной системы информационной поддержки инноваций
- Об одном способе представления знаний
- Визуальная оценка качества работы генератора псевдослучайных чисел для решения криптографических задач
- Оптимальная энтропийная кластеризация в информационных системах