Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Применение байесовской сети в задаче классификации структурированной информации
Аннотация:В статье представлен алгоритм классификации структурированных текстовых документов, основанный на байесовской сети доверия. Перечислены различные методы преобразования структурированной текстовой информации в унифицированное представление, удобное для последующей классификации. Предлагаемый алгоритм классификации допускает использование двух различных подходов к оценке параметров классифицирующей модели: метод максимального правдоподобия, обеспечивающий меньшую точность классификации, и аппроксимация условных вероятностей, обеспечивающая большую точность. Работа алгоритма демонстрируется на примере классификации стандартного набора документов Wikipedia XML Corpus. Результаты тестирования предложенного алгоритма классификации в сочетании с различными методами оценки параметров модели и методами преобразования структурированной информации показали, что модель с оценкой весов методом аппроксимации условных вероятностей имеет наилучшие результаты в сравнении с другими методами, участвовавшими в тестировании. Отличительной особенностью описанного в статье алгоритма является возможность использования в модели классификации различных оценок параметров в зависимости от требуемой точности классификации и скорости работы алгоритма.
Abstract:The paper presents a text categorization algorithm based on the Bayesian network. It also lists various methods of converting structured text information into a unified representation convenient for subsequent classification. The proposed categorization algorithm allows using two different approaches to the parameters estimation of the classifier model: the maximum likelihood method (less accurate classification) and approximation of the conditional probabilities providing greater accuracy. The algorithm is demonstrated on the example of the Wikipedia XML Corpus standard set documents classification. The test of the proposed categorization algorithm has been carried out using combination of a variety of methods to assess the model parameters and the methods of converting structured text data. The results show that the model using the approximation of conditional probabilities method of weights estimation have the best results in comparison with the other methods used in testing. A distinctive feature of the algorithm described in the article is using different parameter estimates in a classification model depending on the required classification accuracy and speed of the algorithm.
| Авторы: Виноградов С.Ю. (sergey.u.vinogradov@gmail.com) - Тверской государственный технический университет (аспирант ), г. Тверь, Россия, Аспирант | |
| Ключевые слова: информационный, классификация текстов, сети байеса, интеллектуальный анализ данных |
|
| Keywords: information retrieval, text categorization, bayesian networks, data intelligent analysis |
|
| Количество просмотров: 16491 |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
Экспоненциальный рост объемов информации обусловил первоочередное значение задачи эффективного доступа к ней. В свою очередь задача обеспечения эффективного доступа к неструктурированной информации напрямую связана с задачей классификации текстов. Для решения последней разработано множество эффективных методов, наилучшие из которых показывают точность классификации, сравнимую с выполненной человеком-экспертом [1]. К таким методам относятся, например, метод опорных векторов, метод логистической регрессии и др. Однако данные методы имеют ряд существенных недостатков, в частности, высокую сложность разработки классифицирующего алгоритма, высокую вычислительную сложность, сложность обновления функций обучения [2] и т.д. Существуют классифицирующие алгоритмы, лишенные подобных недостатков, например наивный классификатор Байеса. Этот классификатор обладает простой и быстрой обучающей процедурой, которую легко модифицировать под новые данные. Однако данный метод полагается на предположение об условной независимости переменных, что во множестве случаев может оказаться неприемлемым. В данной статье предлагается идея развития простых классифицирующих алгоритмов, которая заключается в применении байесовской сети доверия. Модель классификатора Фактически наивный классификатор Байеса можно рассматривать как классификатор, основанный на байесовской сети, структура которой содержит связи от переменной класса к переменным атрибутам (рис. 1). Модифицируем наивный классификатор Байеса и преобразуем его в байесовскую сеть, обладающую следующими свойствами: · каждый термин tk из обучающего множества термов ассоциируется с двоичной переменной Tk, принимающей значения из множества · существуют n двоичных переменных Ci, принимающих значения из множества Структура сети фиксирована, связи направлены от узлов Tk к узлам Ci, если термин tk находится в обучающем наборе терминов, принадлежащих классу ci. Таким образом, получаем двухуровневую сеть, в которой узлы-термины являются причинами, а узлы-классы следствиями, при общем количестве связей Количественно предлагаемая модель классификатора (рис. 2) характеризуется условными вероятностями p(Ci|pa(Ci)), где pa(Ci) – множество родителей узла Ci (то есть множество терминов документа, принадлежащих классу ci) и pa(Ci) – множество перестановок в родительском множестве. Поскольку количество перестановок имеет экспоненциальную зависимость от мощности родительского множества, для упрощения последующих вычислений вероятностей необходимо уменьшить количество переменных. Для этого воспользуемся канонической моделью noisy or gate [3], которая позволит линеаризовать экспоненциальную зависимость. Таким образом, условные вероятности в модели noisy or gate будут определены следующим соотношением:
где R(pa(Ci))={TkÎPa(Ci)|tkÎpa(Ci)}, то есть R(pa(Ci)) – это подмножество родителей Ci, имеющих значение tk в перестановке pa(Ci); w(Tk, Ci) –вес, представляющий вероятность того, что появление единственной причины Tk вызывает следствие (классификацию по классу ci). Вычисление весов в приведенной модели можно произвести несколькими способами. Простейшим из них, очевидно, является оценка w(Tk, Ci) как p(ci| tk), то есть условная вероятность того, что заданный класс ci представлен термином tk. Методом максимального правдоподобия определяем
Значения p(ci| tk) и
Каждый термин, имеющий вхождение в заданный классифицируемый документ dj, в предложенной модели сети представляется переменной Tk, имеющей значение tk (то есть p(tk½dj)=1, если tkÎdj), в свою очередь, все прочие переменные Th (не связанные с терминами, входящими в документ dj) имеют значение Сочетание предложенной сетевой топологии и канонической модели noisy or gate позволяет произвести очень эффективные вычисления апостериорных вероятностей:
Чтобы учесть количество вхождений njk термина tk в документ dj, реплицируем узел Tknjk раз. Таким образом, выражение для апостериорной вероятности приобретает вид
Представление документов Для тестирования описанного классификатора требуется определить унифицированный способ представления информации. Очевидной и наиболее простой формой представления электронной информации является плоский текст. Следовательно, необходимо определить методы преобразования структурированного документа в неструктурированный. Использование плоского текста обеспечит независимость от применяемого классификатора, а в результате комбинирования различных методов преобразования с различными классификаторами получим множество различных классификационных процедур. Для иллюстрации предложенных трансформаций используем небольшой XML-документ, содержащий начало романа Ф.М. Достоевского «Игрок»: <book> <title>Игрок</title> <author>Федор Михайлович Достоевский</author> <contents> <chapter>Первая</chapter> <text> Наконец я возвратился из моей двухнедельной отлучки. Наши уже три дня как были в Рулетенбурге… </text> </contents> </book> Далее предлагаются различные подходы к преобразованию структурированного документа в неструктурированный. Метод 1. «Только текст». Это наивный подход, заключающийся лишь в удалении структурной разметки документа. Примененный к приведенному выше XML-документу, метод даст следующий документ: Игрок Федор Михайлович Достоевский Первая Наконец я возвратился из моей двухнедельной отлучки. Наши уже три дня как были в Рулетенбурге… Этот подход следует рассматривать как базовый метод, лишающий документ всей структурной информации. Однако можно повысить точность классификации, используя более сложные методы преобразования. Метод 2. «Добавление». Метод привносит в плоский текст конечного документа структурную информацию исходного документа. Для этого структурные метки преобразуются в дополнительные термины документа. При этом различные структурные термины можно получить, производя преобразование структурных меток в атомарные термины, опираясь на глубину относительной вложенности меток. Например, метод «Добавление» с глубиной вложенности 2, примененный к данному примеру, даст следующий документ: book book_title Игрок book_author Федор Михайлович Достоевский book_contents contents_chapter Первая contents_text Наконец я возвратился из моей двухнедельной отлучки. Наши уже три дня как были в Рулетенбурге… Метод 3. «Тегирование». В данном подходе, подробно описанном в [4], предлагается рассматривать несколько вхождений термина в документ как вхождение различных терминов, если термин появлялся в контексте различных структурных меток. Для моделирования предлагаемого условия каждый термин тегируется структурной меткой, в контексте которой он находится в документе. Данные, полученные в результате применения настоящего метода, могут быть сильно разрежены. Однако данный метод позволяет получить огромный словарь для документа, в исходном виде не содержащего большое количество терминов. В предлагаемом примере после обработки данным методом получен следующий плоский документ: title_Игрок author_Федор author_Михайлович author_ Достоевский chapter_Первая text_Наконец text_я text_возвратился text_из text_моей text_двухнедельной text_отлучки. text_Наши text_уже text_три text_дня text_как text_были text_в text_Рулетенбурге… Метод 4. «Без текста». Этот метод позволяет использовать только структурные элементы документа, он эквивалентен методу «Добавление» с последующим изъятием из документа неструктурных терминов. Для приведенного примера применение данного метода с неограниченной глубиной вложенности структурных меток даст следующий результат: book book_title book_author book_contents book_contents_chapter book_contents_text. Метод 5. «Дублирование текста». Все перечисленные методы преобразуют структурированный документ, не используя какое-либо априорное знание о документе. То есть данные методы не опираются на информацию о виде структурных меток документа и не предпринимают в зависимости от этого определенных шагов. В следующем подходе каждой структурной метке присваивается целое неотрицательное значение пропорционально значимости информации, помеченной данной меткой (чем выше число, тем значимее информация). Это число используется при дублировании терминов, увеличивающем частоту вхождения терминов, помеченных определенной меткой. Для приведенного примера предположим, что меткам присвоено следующее множество значений: title: 1, author: 0, chapter: 0; text: 2. Следует заметить, что значение, равное 0, трактуется как отсутствие терминов, помеченных данной меткой в конечном документе. В результате получим следующий плоский текст: Игрок Наконец Наконец я я возвратился возвратился из из моей моей двухнедельной двухнедельной отлучки отлучки. Наши Наши уже уже три три дня дня как как были были в в Рулетенбурге Рулетенбурге… Данный подход очень гибок, а также обобщает некоторые другие, в частности метод «Только текст» (достаточно присвоить 1 всем структурным меткам текста). Основным недостатком метода является необходимость некоторого априорного знания о тексте, чтобы можно было построить таблицу значений дублирования перед непосредственной обработкой текста. Программная реализация и эксперимент Предложенная модель реализована на языке программирования C++ c использованием библиотеки Asynchronous Agents Library (AAL), построенной на новой модели акторов с интерфейсами передачи сообщений. Это позволило реализовать модель с большим акцентом на потоках данных и максимально эффективно использовать задержки в ожидании данных. Представим результаты тестирования классификатора, полученные на основе классификации набора XML документов Wikipedia XML Corpus [5]. Тестовый набор был сформирован из 96 000 документов, извлеченных из Wikipedia XML Corpus, а затем разделен в равной пропорции на тестовый и тренировочный поднаборы. Количество категорий классификации – 23.
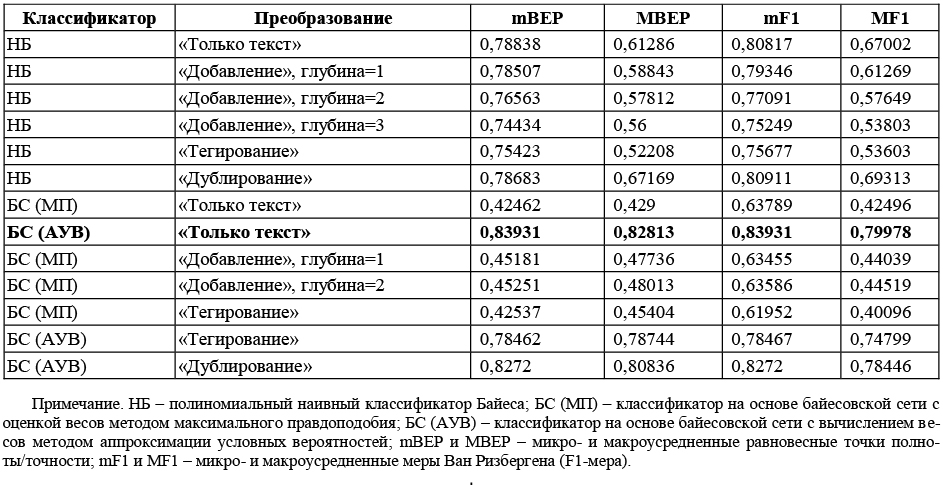
Наравне с предложенным классификатором тестировался полиномиальный наивный классификатор Байеса. Результаты классификатора на основе байесовской сети приведены в таблице для двух версий предложенной модели с оценкой весов методом максимального правдоподобия (МП) и с применением аппроксимации условных вероятностей (АУВ). Как видим, лучшие результаты показал классификатор на основе предложенной модели байесовской сети с оценкой весов аппроксимацией условных вероятностей в комбинации с методом преобразования структурированного документа «Только текст». Более простая версия классификатора с оценкой весов методом максимального правдоподобия показала неудовлетворительные результаты. Очевидно, что метод преобразования текста «Дублирование» улучшает результаты наивного байесовского классификатора, хотя в целом этот классификатор показал невысокие результаты по макрооценкам качества. Также можно заметить, что использование методов преобразования «Добавление» и «Тегирование» не улучшили результаты ни одного из тестируемых классификаторов. На основании изложенного можно сделать следующие выводы. Предложен подход к решению задачи классификации неструктурированных документов с использованием байесовской сети доверия; оценку весов в предложенной модели возможно выполнять двумя различными способами: с применением метода максимального правдоподобия (что дает меньшую точность) и с применением аппроксимации условных вероятностей (с большей точностью). В эксперименте наилучшие результаты показала предложенная модель с оценкой весов методом аппроксимации условных вероятностей. Литература 1. Dumais S.T., Platt J.C., Heckerman D. and Sahami M., Inductive Learning Algorithms and Representations for Text Categorization, CIKM, 1998. 2. Platt J., Probabilistic outputs for Support Vector Machines and comparisons to regularized likelihood methods, in Advances in Large Margin Classifiers, MIT Press, 1999. 3. Jensen F.V., An Introduction to Bayesian Networks, UCL Press, 1996. 4. Bratko A., Filipic B., Exploiting structural information for semi-structured document categorization. Information Proc. and Management, 2006, no. 42 (3). 5. Denoyer L. and Gallinari P., Wikipedia XML Corpus., SIGIR Forum, 2006. |
 и представляющей соответствующий узел в сети;
и представляющей соответствующий узел в сети;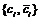 и представляющих соответствующий узел сети.
и представляющих соответствующий узел сети. , где nti – количество терминов из обучающего подмножества, принадлежащих классу ci.
, где nti – количество терминов из обучающего подмножества, принадлежащих классу ci. (1)
(1)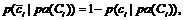 (2)
(2)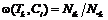 . (3)
. (3)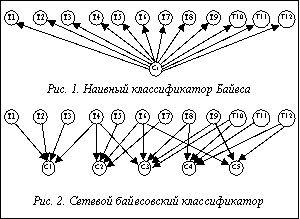 Более точным способом вычисления w(Tk, Ci) является вычисление вероятности
Более точным способом вычисления w(Tk, Ci) является вычисление вероятности 
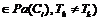 . Однако эта вероятность не может быть вычислена напрямую, поэтому используем аппроксимацию
. Однако эта вероятность не может быть вычислена напрямую, поэтому используем аппроксимацию (4)
(4) также определяются посредством метода максимального правдоподобия. Тогда для весов w(Tk, Ci) получим выражение
также определяются посредством метода максимального правдоподобия. Тогда для весов w(Tk, Ci) получим выражение (5)
(5) (то есть p(th½dj)=0, \" thÏdj). Тогда, вычислив для каждого узла Ci апостериорную вероятность p(ci|dj), присвоим документ dj классу с наибольшей апостериорной вероятностью.
(то есть p(th½dj)=0, \" thÏdj). Тогда, вычислив для каждого узла Ci апостериорную вероятность p(ci|dj), присвоим документ dj классу с наибольшей апостериорной вероятностью. (6)
(6) (7)
(7)
| Постоянный адрес статьи: http://swsys.ru/index.php?id=3483&page=article |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
| Статья опубликована в выпуске журнала № 2 за 2013 год. [ на стр. 155-158 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Создание комплекса программ на основе пространственной схемы взаимодействия объектов
- Сравнение нейросетевых моделей для классификации текстовых фрагментов, содержащих биографическую информацию
- Прогнозирование угроз в сложных распределенных системах на основе интеллектуального анализа больших данных автоматизированных средств мониторинга
- Формальные методы установления авторства текстов и их реализация в программных продуктах
- Метод частотно-морфологической классификации текстов
Назад, к списку статей