Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Система синтеза учебных тестов на основе формальных грамматик
Аннотация:Рассматривается метод генерации обучающих тестов и тестовых заданий, использующий продукционный формализм на основе канонических исчислений Поста. Поддерживаются контекстно-свободные, контекстно-зависимые и произвольные грамматики по классификации Хомского. Описание правил в грамматике осуществляется в традиционной нотации Бэкуса–Наура. Расширения синтаксиса позволяют использовать объекты мультимедиа (изображения, аудио- и видеофайлы), вычисляемые формулы (синус, косинус, умножение, деление и т.д.) и форматирование текста. Возможно создание различных типов тестов. Экспорт тестовых заданий поддерживается в различных форматах: RTF, HTML, SSI, BIN. Имеются как печатные форматы, так и исполняемые в обучающих системах. Созданная система синтеза поддерживает многопоточную генерацию и удобный редактор правил грамматик. При этом система позволяет проводить учебные занятия по изучению формальных грамматик.
Abstract:The article considers the method of generating training tests and test tasks using production formalism based on the canonical Post calculations. There are following Chomsky classification grammars: context-free, context-sensitive and arbitrary grammar. The description of grammar rules are in traditional notation Backus–Naur Form. Syntax extending allows using multimedia objects (images, audio and video files), calculated formula (sine, cosine, multiplication, division, etc.) and text formatting. Different types of tests creation is possible. Tests export is supported in a variety of formats: RTF, HTML, SSI, BIN. There are printed formats and executable formats in training systems. Synthesis system supports multi -threaded generation and convenient grammar editor. This system allows providing trainings with formal grammars studying.
| Авторы: Швецов А.Н. (smithv@mail.ru) - Вологодский государственный технический университет (профессор), Вологда, Россия, доктор технических наук, Мамадкулов Ю.О. (yusuf444@mail.ru) - Вологодский государственный технический университет (ассистент), г. Вологда, Россия, Сорокин С.И. (sonvin@inbox.ru) - Вологодский государственный технический университет (ассистент ), г. Вологда, Россия | |
| Ключевые слова: система, дистанционное обучение, тестовые задания, бнф, исчисления поста, грамматика |
|
| Keywords: system, distance education, tests, bnf, post calculations, grammatics |
|
| Количество просмотров: 13731 |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
Автоматизация обучения является очень важной задачей. Имеется множество разработок компьютерных учебных комплексов с различными методами тестирования и обучения. Эти методы могут быть как простыми, реализованными на основе простых шаблонов и жестких структур, так и сложными – на основе адаптивных систем с нейронными сетями и применением онтологий [1]. При обсуждении данного вопроса мало внимания уделяется работе специалиста, составляющего курсы обучения [2]. Для решения проблем автоматизации труда преподавателя по составлению учебного материала был разработан эффективный метод синтеза учебных материалов, применяемый в инструментальной интеллектуальной программной системе (ИИПС). Для описания метода синтеза учебных тестов используется продукционный формализм на основе канонических исчислений Поста [3]. Продукции наряду с фреймами, формальными логическими моделями и семантическими сетями являются наиболее популярным средством представления знаний в интеллектуальных системах, которые, с одной стороны, близки к логическим моделям, что позволяет организовывать на них эффективные процедуры вывода, а с другой – более наглядно, чем классические логические модели, отражают знания. В продукциях отсутствуют жесткие ограничения, характерные для логических исчислений, что дает возможность изменять интерпретацию элементов продукции [4]. В нашей стране продукционные системы и исчисления развивались С.Ю. Масловым, Н.А. Шаниным, В.Е. Кузнецовым, М.И. Кратко. Разработанный метод является вариантом практического приложения канонических исчислений Поста к построению произвольного типа тестовых заданий, инвариантных к ПО и виду изучаемой технической дисциплины. Общая структура генерируемых тестов может быть представлена формулой Вопросы каждого типа необходимо распределить по подтипам так, чтобы один и тот же подтип по возможности не повторялся в данном тесте. Поэтому строим исчисление вида K=(A, P, A0, p), где A – алфавит исчисления; P – алфавит переменных; A0 – аксиома исчисления; p – множество правил вывода. Алфавит исчисления A={NÈZ}, где N – алфавит нетерминальных символов; Z – алфавит вспомогательных символов. В множество N включены нетерминалы Vi, обозначающие структуру вопрос-ответ i-го типа, и Õi, обозначающие множество правил вывода для i-го типа и нетерминалы подтипов PVi, j,…, y, возможно, с индексной последовательностью произвольной длины. Алфавит Z={|, (, ), [, ], #, i, j, …, y}. Алфавит переменных P={p, q, j, ai, rij, rb, re}. Символы алфавитов интерпретируются следующим образом: | – элементарный конструктивный элемент, используемый для организации унарных счетчиков; (, ) – скобки для обозначения состояния счетчика; [, ] – скобки для обозначения элементов множества правил вывода; # – разделитель для формирования структуры посылок и следствий; i, j, …, y – индексная последовательность, показывающая уровень и тип вложенности подтипа; p – левая часть последовательности подтипов; q – правая часть последовательности подтипов; j – переменная, обозначающая текущее состояние счетчика подтипов; ai – переменная, обозначающая начальное состояние счетчика подтипов; rij – переменная, обозначающая исключаемое правило из множества Pi; rb, re – оставшиеся правая и левая (относительно rij) части множества Pi . Аксиома исчисления A0 будет иметь вид
где Pi={ri1, ri2, …, rifi}, fi – количество правил вывода для типа i. Структура Vi│(ai)[Pi], расположенная между разделителями #...#, обозначает, что в генерируемый тест будет включено аi заданий, генерируемых в соответствии со структурой вопрос-ответ i-го типа, при этом аi может быть больше, меньше или равно fi. Множество правил вывода p построено с исключениями примененных правил из множеств Pi. Начало раскрытия типа i моделируется правилами вида Процесс применения правил должен продолжаться до тех пор, пока не будет исчерпано либо Vi|(j), либо множество [Pi]. Это означает, что fi В результате применения подобных правил для всех типов в A0 (от 1 до k) получается слово вида p1#p2#…#pk. Далее при необходимости можно сформировать подтипы следующего уровня, применяя правила вывода вида Вывод конкретного предложения из подтипа PVi,j,y описывается формальной грамматикой, записанной в традиционной нотации Бэкуса–Наура. Классификация грамматик происходит по иерархии Хомского, ИИПС поддерживает три класса из этой иерархии: контекстно-свободные, контекстно-зависимые и произвольные грамматики. Контекстно-свободные грамматики – самый простой из рассматриваемых типов. Левая часть правила должна содержать один нетерминал, правая является произвольной. Например: ::=abc
::=d Данная грамматика породит строку abdc. Контекстно-зависимые грамматики – в левой части, помимо одного нетерминала, может присутствовать контекст из терминальных символов справа или/и слева. Контекст в правой части правила описывать не надо, так как при подстановке система автоматически сохраняет контекст левой части. Например: ::=abeec ee::=d Данная грамматика породит строку abedec. Произвольные (неограниченные) грамматики – левая и правая части правила неограниченные, кроме одного условия: в левой части должен присутствовать хотя бы один нетерминал. Например: ::=abeztc ezt::=eddzt Данная грамматика породит строку abeddztc. При генерации обучающих тестов анализ и подстановка в правилах контекстно-зависимых и произвольных грамматик происходят в следующем виде. Слева направо просматривается правая часть правила на наличие нетерминалов путем сравнения значений левых частей правил (фронт правил) с нетерминалом и его контекстом, при этом ищется наибольшее покрытие контекста нетерминалов. Например, имеется следующая грамматика: ::=abee45fgr ee::=d ::=12 В итоге получится строка abede45f12gr. В первом случае произошла подстановка правила с наибольшим именем, а не с наименьшим, во втором – подстановка правила без контекста. Формальные грамматики различных типов предоставляют мощное средство синтеза обучающих тестов. Для повышения скорости создания тестов и качества наполнения тестовых заданий дополнительно были разработаны расширения синтаксиса правил грамматик, которые позволили работать со следующими объектами: – мультимедиа-объекты – в тексте правил можно указывать путь до изображений, аудио- или видеоданных, которые будут вставлены в итоговый результат генерации; такие объекты ограничиваются символом # и могут также содержать элементы грамматики (нетерминалы) для более гибкого управления данным типом объектов; – вычисляемые выражения – математические формулы, которые можно использовать прямо в правилах грамматик; формулы могут строиться из нескольких правил и рассчитываться во время генерации, что увеличивает интеллектуальность тестов и повышает гибкость создания различных материалов, а также состоять из простых операций (сложение, вычитание, деление и т.д.), различных функций (sin, cos и т.д.), цифр, нетерминалов и иметь порядок расчета; данный объект выделяется символом $; – стили форматирования – объект, с помощью которого можно задавать параметры отображения определенной единицы учебного материала; стили форматирования отвечают за цвет символов и фона, стили начертания текста (жирный, курсив), шрифты, размеры изображений, выравнивание объектов и т.д.; символ & ограничивает строку, содержащую именованные параметры со значениями стилей; – символы – строка обычных символов (текстовые и служебные), которые должны быть добавлены в содержание получаемого материала без изменений; символ @ ограничивает текстовую строку, а символ % определяет номер символа из кодовой таблицы символов. Для облегчения разработки тестов в среде ИИПС была реализована структура файлов-хранилищ грамматик, позволяющая хранить несколько грамматик одного или разных типов в едином контейнере. Эта структура подразумевает наличие общего заголовка и нескольких информационных секций. Общий заголовок содержит информацию о теме группы грамматик, авторе, примечания и т.д. Информационные секции содержат группы (листы) грамматик различных типов, которые, в свою очередь, содержат группы правил, поделенные на разделы: тип грамматики, заголовок материала, тело материала, пояснительная часть, результирующая часть и т.д. Такая структуризация и разнородность грамматик позволяют оптимизировать работу специалиста с системой. При генерации тестов можно использовать несколько файлов-хранилищ грамматик для получения большего количества разных вариантов генерации. Кроме правил грамматик, на процесс синтеза влияют и общие параметры генерации: – глубина рекурсии – в правилах грамматик поддерживается рекурсия для получения большего количества вариантов генерации; рекурсию можно ограничить для предотвращения неконтролируемого разрастания содержимого тестов; – выборка с памятью – определяет, как осуществлять отбор вариантов, описанных в правых частях правил грамматик; динамическая выборка при раскрытии нетерминалов каждый раз заново определяет выбор вариантов, при выборке с памятью (статическая выборка) – выбор вариантов при раскрытии одноименных нетерминалов осуществляется на основе первого выбора этого нетерминала; – параметры смешивания – определяют порядок смешивания заданий, как варьировать количество вариантов ответа на задания, группировать тесты, добавлять заголовки и пр. Помимо вышеописанной группы параметров, имеются настройки экспорта сгенерированных данных, которые позволяют задать выходные форматы файлов, то есть то, что должно получиться по окончании процесса генерации. ИИПС дает возможность создавать учебные материалы в следующих форматах. · Текстовый (rtf) – документ word с форматированием текста и с рисунками; необходим для подготовки печатной версии создаваемых учебных материалов и для возможности дальнейшего редактирования. · Гипертекстовый документ (html) – как и предыдущий формат, содержит форматирование и мультимедиа-данные; необходим также для печатной версии, но при этом обладает большой платформонезависимостью (поддерживается многими ОС), простотой использования и предназначен в основном только для режима просмотра без редактирования. · Гипертекстовый интерактивный документ (html и ssi) – состоит из двух документов. Первый из них – web-документ (Html), имеющий, помимо текста с форматированием и рисунками, элементы для взаимодействия с содержимым теста (кнопки, поля ввода, элементы выбора); необходим для прохождения теста непосредственно в интернет-браузере с последующей отправкой результатов на проверяющий сервер, где лежит соответствующий ssi файл. Этот файл является вторым генерируемым файлом, он содержит информацию о верных ответах и пояснения к этим ответам. · Интерактивный файл (usf) – наиболее полноценный формат экспорта тестов, содержит все элементы форматирования текста, помимо изображения, содержит все мультимедиа-объекты (помимо изображений, видео- и аудиоданные) и интерактивные элементы управления; кроме этого, имеет интеллектуальные технологии обратной связи с тестируемым объектом. Данный формат необходим для обеспечения процесса тестирования в отдельном программном комплексе с контролем результатов и процесса выполнения. · Бинарный файл (txt, bin, bmp и любое произвольное расширение) – содержит практически чистые данные без обертки их в структуру произвольного формата; используется для генерации произвольных бинарных данных (изображения, неформатированный текст и т.д.), при этом специалист должен знать формат создаваемого файла (см. рис.). Пользователь при использовании среды ИИПС должен придерживаться следующего алгоритма действий. Сначала создается грамматика, на основе которой предполагается синтезировать тесты и задания. В грамматике определяются структура и содержимое тестов, в том числе все внешние объекты. Далее, если планируется использовать не только один контейнер грамматик, определяется набор файлов-хранилищ грамматик, по которым будет происходить синтез заданий. После этого задаются общие параметры генерации. Последним шагом будет указание выходных форматов получаемого материала. Среда ИИПС позволяет получать как печатные версии тестов, так и компьютерные интерактивные. Кроме того, после генерации система способна множество раз синтезировать разнообразные тесты на одном наборе файлов-хранилищ.
Данная система является очень гибкой, что позволяет легко интегрировать ее в различные среды и программные комплексы, в том числе имеется опыт интеграции в интеллектуальный агентно-ориентированный учебный комплекс [5], где для этой системы отводилась роль универсального и мощного генератора учебных заданий. В дальнейшем систему можно расширить и использовать формальные грамматики для генерации не только учебного материала, но и моделей поведения интеллектуальных агентов. Система генерации учебного материала на основе формальных грамматик упрощает и автоматизирует создание большого количества неповторяющихся и разнообразных тестов и тестовых заданий. Литература 1. Голосов А.О., Полотнюк И.С., Филиппович А.Ю. Информационные технологии в образовании: преимущества интеграционного подхода // Проблемы теории и практики управления. 2006. № 8. С. 64–68. 2. Brusilovsky P., Kobsa A., Neidl W. (eds.), The Adaptive Web: Methods and Strategies of Web Personalization. Lecture Notes in Computer Science, Springer-Verlag, Berlin Heidelberg NY, 2007, Vol. 4321, pp. 3–53. 3. Маслов С.Ю. Теория дедуктивных систем и ее применения. М.: Радио и связь, 1986. 136 с. 4. Сергушичева А.П., Швецов А.Н. Синтез интеллектуальных тестов средствами формальной продукционной системы // Математика/Компьютер/Образование: сб. науч. тр. М.–Ижевск, R&C Dynamics, 2003. Вып. 10. Ч. 1. С. 310–320. 5. Сорокин С.И., Мамадкулов Ю.О., Швецов А.Н. Интеллектуальная система генерации учебных тестов на основе формальных грамматик: сб. тез. Всерос. конф. по результ. проект., реализованных в рамках ФЦП «Научные и науч.-педагогич. кадры инновационной России» на 2009–2013 гг. М., 2010. С. 76–78. |
 , где Bi={bi1, bi2, …, biai} – подмножество вопросов i-го вида; ai – количество вопросов i-го вида в подмножестве Bi;.
, где Bi={bi1, bi2, …, biai} – подмножество вопросов i-го вида; ai – количество вопросов i-го вида в подмножестве Bi;. 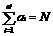 – общее количество вопросов в данном тесте.
– общее количество вопросов в данном тесте. ,
, , которых будет fi экземпляров для каждого типа i. Далее используются правила вида
, которых будет fi экземпляров для каждого типа i. Далее используются правила вида  , которых также будет fi экземпляров для каждого типа i, причем переменная p хранит последовательность подтипов (…)(PVi,j)(…).
, которых также будет fi экземпляров для каждого типа i, причем переменная p хранит последовательность подтипов (…)(PVi,j)(…). , где PVi,j,y – y-й подтип подтипа PVi,j. Такое построение можно осуществить для любого уровня вложенности.
, где PVi,j,y – y-й подтип подтипа PVi,j. Такое построение можно осуществить для любого уровня вложенности. Как видно из вышеизложенного, ИИПС дает возможность быстро создавать множество разнообразного учебного материала, при этом среда позволяет делать тесты, учебные материалы и даже данные произвольного формата. Рассматриваемая среда разработки применяется при подготовке бакалавров и магистров в таких дисциплинах, как «Системное программное обеспечение», «Интеллектуальные информационные системы», «Системы искусственного интеллекта и принятия решений». ИИПС в данных курсах применяется и для синтеза учебного материала, и для обучения.
Как видно из вышеизложенного, ИИПС дает возможность быстро создавать множество разнообразного учебного материала, при этом среда позволяет делать тесты, учебные материалы и даже данные произвольного формата. Рассматриваемая среда разработки применяется при подготовке бакалавров и магистров в таких дисциплинах, как «Системное программное обеспечение», «Интеллектуальные информационные системы», «Системы искусственного интеллекта и принятия решений». ИИПС в данных курсах применяется и для синтеза учебного материала, и для обучения.| Постоянный адрес статьи: http://swsys.ru/index.php?id=3489&page=article |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
| Статья опубликована в выпуске журнала № 2 за 2013 год. [ на стр. 181-185 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Некоторые технологические аспекты создания учебно-тренировочных средств подготовки командиров и специалистов Военно-морского флота
- Разработка метода принятия решения о выборе системы дистанционного обучения для медицинского образования
- Автоматическая генерация заданий по результатам анализа использования их банка в интеллектуальной обучающей системе
- Система управления бизнес-процессами и административными регламентами
- Программный комплекс для представления и преобразования дискретных структур знаний
Назад, к списку статей