Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Метод секционирования и его применение при классификации разнородной информации
Аннотация:Анализ однородности имеет большой потенциал для эффективной визуализации ансамблей деревьев и аналогичных алгоритмов машинного обучения. Однако существуют как минимум два недостатка этого подхода: в случае очень большого количества учебных наблюдений могут возникнуть вычислительные проблемы и, что более важно, точность прогноза в двухмерных вложениях подчас заметно хуже, чем в оригинальном ансамбле деревьев. Послед-нее означает, что значимая информация теряется в низкоразмерных вложениях. Авторы предлагают простое расширение анализа однородности, называемое секционированием, которое зачастую решает указанные проблемы при многоклассовом ранжировании, где Y∈{1, …, K}, и может заметно улучшить точность прогнозирования.
Abstract:In our previous work we considered the analysis of homogeneity and believe that it has great potential for ef-fective visualization of ensemble of trees and similar machine learning algorithms. However, there are at least two drawbacks to this approach: the computational problems may arise if the number of training observations is very large and, more im-portantly, the accuracy of prediction in two-dimensional embeddings often much worse than in the original ensemble oftrees algorithms, this means that significant information is lostin low-dimensional embeddings. We present a simple extension analysis of homogeneity called sectioning, which often solves the above mentioned prob-lems in the case of multi-class ranking and can lead to a significant improvement in prediction accuracy.
| Авторы: Бурилин А.В. (aburilin@naumen.ru) - Тверской государственный университет (ст. преподаватель), Тверь, Россия, Гордеев Р.Н. (rgordeev@naumen.ru) - Тверской государственный университет, Тверь, Россия, кандидат физико-математических наук, Борисов П.А. () - «Интегрированные системы», Тверской государственный университет (вед. инженер-программист ), г. Тверь, Россия | |
| Ключевые слова: визуализация графов., анализ однородности, метод секционирования |
|
| Keywords: visualization of graphs, homogeneity analysis, partitioning method |
|
| Количество просмотров: 11460 |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
Ранее авторы уже анализировали однородность, сначала располагая правила, а затем наблюдения в зависимости от расположения правил (см. стр. 169–174 настоящего выпуска журнала). В данной работе сначала выделим группы, а затем разместим правила, определяющие эти группы. После вычисления расположения правил на плоскости выполним те же действия, как и в случае применения анализа однородности. Такой подход позволит увеличить скорость вычислений и главное – лучше разделять наблюдения по классам в низкоразмерных вложениях. Для группировки наблюдений по классам требуется, чтобы Ui=Ui¢ для всех i, i¢Î{1, …, n}, таких, что Yi=Yi¢. Пусть
При сделанных предположениях оптимизационная задача анализа однородности примет следующий вид:
при ограничениях
Решение можно получить аналогично тому, как это сделано для анализа однородности при помощи метода, основанного на вычислении собственных значений. Введем ряд обозначений. Положим, что
Обозначим через Тогда решение (2) будет таким:
Выражение (7) определяет расположение правил R, после чего они запоминаются (фиксируются). Далее можно действовать, как и при вычислении положения наблюдений в анализе однородности, применив выражение U=diag(GGT)-1GR для вычисления расположения отдельных наблюдений. Точность предсказания оценивается так же, как и при анализе однородности. Таким образом, алгоритм секционирования можно представить в виде следующей трехшаговой процедуры. 1. Обучить исходный метод анализа однородности на обучающей выборке наблюдений и выделить все m используемых правил в бинарную матрицу G. Произвести агрегирование строк матрицы G по признаку классовой принадлежности согласно (1), чтобы получить 2. Вычислить q-размерное вложение для правил R согласно (7). 3. Вычислить позиции отдельных наблюдений U (для обучающих или тестовых данных) согласно выражению U=diag(GGT)-1GR.
Если применить метод секционирования к примеру, приведенному авторами при анализе однородности, получим результат, изображенный на рисунке 2. В данном случае точность определения ближайшего соседа составила 17 %, что несколько лучше, чем в случае применения анализа однородности. С другой стороны, существенно улучшена скорость вычислений: теперь разложение по собственным векторам осуществляется для матрицы размером K´m, где K=8, вместо прежней матрицы размером n´m, n=692. Это также превосходит по скорости метод наименьших квадратов, применяемый в анализе однородности в качестве альтернативного подхода для вычислений. Серые точки на рисунке 2 обозначают правила (оценки экспертов), которые эксперты, принадлежащие одному из обследуемых научных центров, присвоили той или иной статье. Напомним, что все эксперты принадлежали одному из восьми научных центров.
Силовая укладка на карте Уникальной особенностью алгоритма секционирования является то, что наблюдения, принадлежащие одному классу, группируются при вычислении положения правил. Это дает свои вычислительные преимущества, но, что более важно, приводит к более хорошему визуальному представлению разделения наблюдений между классами. Тем не менее разделения по классам по-прежнему не так точны, как в случае применения случайного леса, лежащего в основе алгоритма. Основной причиной является частичное перекрытие между классами, возникающее в процессе поиска расположения правил, поскольку дисперсионное ограничение (3) не штрафует перекрытия между классами. В результате значительно ухудшается геометрическая интерпретация целевой функции (2). Минимизацию суммы квадратов расстояний между наблюдениями и правилами можно рассматривать как присоединение пружин между каждым правилом и наблюдением, которые соединены ребром. Энергия системы в этом случае пропорциональна сумме квадратов расстояний, а минимизация суммы квадратов длин ребер эквивалентна нахождению минимальной энергии и, следовательно, физически стабильного решения. В то время как целевая функция (2) имеет четкую геометрическую интерпретацию, ограничение (3) – немного менее четкую [1, 2]. Для достижения хорошего разделения между классами дисперсионные ограничения (3) не совсем подходят, поскольку в них нет штрафов для классов, занимающих одинаковое положение в (2). В большинстве задач отрисовки графа широкое распространение получили так называемые силовые алгоритмы укладки. Они просты в реализации и понятны, поскольку могут рассматриваться как моделирование некоторой физической системы (см., например, [3–5] и ссылки в них). Основная идея этих алгоритмов в том, чтобы выбрать укладку графа, минимизирующую потенциальную энергию системы, состоящей в основном из сил притяжения (пружины) и отталкивания (электромагнитное взаимодействие). В случае с методом секционирования аналогия очевидна: целевая функция (2) может рассматриваться как потенциальная энергия пружин, соединяющих правила и наблюдения в двудольном графе. В модели (2) с ограничениями (3) и (4) нет сил отталкивания, поэтому предлагается заменить слегка искусственное ограничение (3) на ограничение, моделирующее силы отталкивания между классами. В таком случае потенциальная энергия между позициями Таким образом, дисперсионное ограничение (3) заменяется ограничением следующего вида:
В этом ограничении константа 1 может быть заменена на любое другое значение, поскольку решения изоморфны относительно модуля изменения масштаба. Результаты работы силовой укладки можно видеть на рисунке 3, отражающем более четкое разделение экспертов по научным центрам и высокую предсказательную точность случайного леса. Таким образом, задачу (2) с ограничениями (8) можно записать в форме Лагранжа:
Параметр l не имеет смысловой нагрузки, а лишь масштабирует решения, поэтому произвольно можно задать значение l=1. В итоге получим следующую задачу оптимизации:
Сходимость авторского метода определяется следующим условием: считаем, что алгоритм сходится на итерации lÎ Таким образом, формально метод секционирования можно представить в виде следующих процедур. 1. Обучить исходный метод на обучающей выборке и выделить все m правил/листьев графа в бинарную матрицу-индикатор G. Провести агрегирование матрицы G согласно выражению (1). В результате получим агрегированную матрицу 2. Вычислить вложения размерности q (размерность пространства, используемого для отображения) для правил R, используя выражение (7). 3. Выполнять последовательно следующие два шага, пока алгоритм не достигнет сходимости: – провести оптимизацию K позиций – пересчитать позиции правил в соответствии с выражением 4. Центрировать позиции наблюдений при помощи выражения 5. Вычислить позиции всех наблюдений U при помощи выражения U=diag(GGT)-1GR. Подытоживая, можно отметить, что предложенный метод секционирования позволяет значительно сократить размерность задачи классификации наблюдений и их визуального представления. Кроме того, авторами разработан комбинированный алгоритм, объединяющий метод секционирования с алгоритмами силовой укладки графов, что позволяет значительно увеличить точность предсказаний первого при отображении графов в пространствах малой размерности, например на плоскостях, и значительно упростить вычислительные процедуры, используемые при разбиении наблюдений на классы и их визуализации. Литература 1. Michailidis G. and De Leeuw J., The Gifi System of escriptive Multivariate Analysis, Statistical Sc., 1998, no. 13 (4), pp. 307–336. 2. De Leeuw J., Beyond Homogeneity Analysis, Technical Report, UCLA, 2009. 3. Fruchterman T. and Reingold E., Graph Drawing by Force-Directed Placement, Software–Practice and Experience, 1991, no. 21, pp. 1129–1164. 4. Di Battista G., Eades P., Tamassia R., and Tollis I., Graph Drawing: Algorithms for the Visualization of Graphs, Upper Saddle River, NJ, Prentice Hall, 1998. 5. Kamada T. and Kawai S., An Algorithm for Drawing General Undirected Graphs, Information Processing Letters, 1989, no. 31, pp. 7–15. References 1. Michailidis G., De Leeuw J., Statistical Science, 1998, no. 13 (4), pp. 307–336. 2. De Leeuw J., Beyond Homogeneity Analysis, Technical Report, UCLA, 2009. 3. Fruchterman T., Reingold E., Software–Practice and Experience, 1991, no. 21, pp. 1129–1164. 4. Di Battista G., Eades P., Tamassia R., Tollis I., Graph Drawing: Algorithms for the Visualization of Graphs, Upper Saddle River, NJ, Prentice Hall, 1998. 5. Kamada, T., Kawai S., Information Processing Letters, 1989, no. 31, pp. 7–15. |
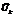 – позиция k-го класса, k={1, …, K}. Пусть также матрица-индикатор
– позиция k-го класса, k={1, …, K}. Пусть также матрица-индикатор  размером K´m будет агрегатом матрицы G, где агрегирование проводится по K классам,
размером K´m будет агрегатом матрицы G, где агрегирование проводится по K классам, . (1)
. (1) (2)
(2) , (3)
, (3) . (4)
. (4) ,
,  и
и . (5)
. (5)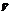 матрицу, состоящую из первых q собственных векторов матрицы
матрицу, состоящую из первых q собственных векторов матрицы 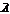 .
. , (6)
, (6) . (7)
. (7) .
. Пример визуального представления решения отображен на рисунке 1. Все статьи сгруппированы согласно их классовой принадлежности (физика, математика, информатика, биология и т.д.), а каждый класс представлен одной точкой в двухмерном вложении. Ребра в данном графе являются взвешенными, веса соответствуют частоте появления того или иного ключевого слова в группе (определяется на обучающей выборке).
Пример визуального представления решения отображен на рисунке 1. Все статьи сгруппированы согласно их классовой принадлежности (физика, математика, информатика, биология и т.д.), а каждый класс представлен одной точкой в двухмерном вложении. Ребра в данном графе являются взвешенными, веса соответствуют частоте появления того или иного ключевого слова в группе (определяется на обучающей выборке). Линии, образуемые на рисунке 2 правилами (оценками) между двумя научными центрами (например, первым и пятым или первым и шестым), свидетельствуют о том, что эти правила в основном характерны для экспертов только из этих научных центров, но не для остальных. Кроме того, заметны выбросы, то есть эксперты, которые находятся достаточно далеко от своих центров притяжения, например эксперты, классифицированные как принадлежащие пятому научному центру. Однако при детальном рассмотрении оказывается, что они производили мало оценок, а не проявляли поведение, характерное для другой группы, что сказалось на их расположении. Кроме того, следует отметить, что поведение некоторых экспертов при оценивании статей весьма схоже с поведением экспертов других научных центров.
Линии, образуемые на рисунке 2 правилами (оценками) между двумя научными центрами (например, первым и пятым или первым и шестым), свидетельствуют о том, что эти правила в основном характерны для экспертов только из этих научных центров, но не для остальных. Кроме того, заметны выбросы, то есть эксперты, которые находятся достаточно далеко от своих центров притяжения, например эксперты, классифицированные как принадлежащие пятому научному центру. Однако при детальном рассмотрении оказывается, что они производили мало оценок, а не проявляли поведение, характерное для другой группы, что сказалось на их расположении. Кроме того, следует отметить, что поведение некоторых экспертов при оценивании статей весьма схоже с поведением экспертов других научных центров. классов k и k¢ (k¹k¢) пропорциональна
классов k и k¢ (k¹k¢) пропорциональна  .
. . (8)
. (8) .
.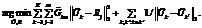 (9)
(9) Ограничение (4) может быть применено после решения (9). Приведенную задачу оптимизации можно решить методом наименьших квадратов. Сначала фиксируются позиции правил R и проводится оптимизация относительно
Ограничение (4) может быть применено после решения (9). Приведенную задачу оптимизации можно решить методом наименьших квадратов. Сначала фиксируются позиции правил R и проводится оптимизация относительно  затем фиксируются найденные значения
затем фиксируются найденные значения  позиций классов и проводится оптимизация относительно R. Последняя задача тривиальна, так как R сразу же определяется формулой
позиций классов и проводится оптимизация относительно R. Последняя задача тривиальна, так как R сразу же определяется формулой 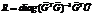 . Задача оптимизации по
. Задача оптимизации по  тогда и только тогда, когда евклидово расстояние между позициями
тогда и только тогда, когда евклидово расстояние между позициями  необходимо осуществлять пересчет позиций правил R, используя выражение
необходимо осуществлять пересчет позиций правил R, используя выражение 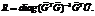

 и снова пересчитать позиции правил
и снова пересчитать позиции правил | Постоянный адрес статьи: http://swsys.ru/index.php?id=3582&page=article |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
| Статья опубликована в выпуске журнала № 3 за 2013 год. [ на стр. 175-178 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: