Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Применение мягких вычислений для анализа структуры базы знаний информационной системы
Аннотация:Рассматривается возможность применения генетических алгоритмов и нейронных сетей для предварительного анализа и оптимизации структуры БЗ информационной системы. Описан пример построения структуры нейронной сети. После выполнения процедуры анализа генерируются описание структуры взаимосвязей объектов анализируемой системы и ее кластерное представление, то есть на выходе получается перечень классифицированных объектов по заданному перечню признаков. Результаты исследования могут быть использованы государственными и частными организациями, вовлеченными в процесс управления научно-техническим комплексом, например, в сферах патентования, управления программами и проектами, хранением и обработкой наукометрической информации.
Abstract:The article investigates the possibility of using genetic algorithms and neural networks for preliminary analysis and optimization of the structure of the information system knowledge base. It describes an example of constructing the structure of a neural network. The structure of the links between analyzed objects and its clustering representation is described after performing of the analysis. As a result, there is a list of classified objects according to given list of features. The study can be used by public and private organizations involved in the management of scientific and technical complex. For example, in the areas of patents, program and project management, storage and processing scientometric information.
| Авторы: Гордеев Р.Н. (rgordeev@naumen.ru) - Тверской государственный университет, Тверь, Россия, кандидат физико-математических наук, Бурилин А.В. (aburilin@naumen.ru) - Тверской государственный университет (ст. преподаватель), Тверь, Россия | |
| Ключевые слова: искусственная нейронная сеть, генетический алгоритм, мягкие вычисления, прогнозирование, информационная система |
|
| Keywords: artificial network, generic algorithm, soft computing, forecasting, information system |
|
| Количество просмотров: 15857 |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
В условиях расширения спектра задач, решаемых на различных уровнях управления, актуальна проблема визуализации и управления большими массивами показателей. Важность решения возникшей проблемы и необходимость разработки соответствующих научно-методических положений были обусловлены, во-первых, резким увеличением количества обрабатываемых показателей в социально-экономической и научно-технической сферах, во-вторых, недостаточным уровнем развития традиционной методологии обработки структурированной информации, в-третьих, отсутствием инструментальных средств визуализации показателей и связей между ними.
Структура анализируемых данных В качестве источника анализируемых данных выступает информация о содержании и показателях реализации целевых программ и отдельных мероприятий, содержащихся в системе экспертиз Государственной дирекции научно-технических программ (далее – Дирекция). Для получения и анализа этой информации был разработан экспериментальный образец программного комплекса (ЭО ПК), позволяющий интегрироваться с системой экспертиз Дирекции и получать необходимые данные в режиме реального времени. Архитектура ЭО ПК приведена на рисунке 1. Анализируемые параметры ЭО ПК представлены значениями двух векторов: {V, S}, где V принадлежит множеству {0, 1}, S – множеству {«Прямая связь», «Объект», «Документ», «Иное»}, и {N, F}, где N принадлежит множеству действительных чисел R, F – множеству {«Поле связи», «Объект связи», «Приоритет», «Описание связи»}. В работе [1] проводился аналогичный анализ модели прогнозирования неисправностей вагонного оборудования. В ЭО ПК регистрируются взаимосвязи между объектами системы экспертиз по тем или иным параметрам. После проведения данной процедуры в ЭО ПК будет сформирован пул объектов, отражающих взаимосвязи объектов системы экспертиз и их свойства. Так строится таблица, содержащая данные о типах связей объектов. Возможные варианты связей объектов могут быть следующими: - прямая связь, то есть у одного объекта есть прямая ссылка на другой объект; - связь через сторонний объект, то есть в системе имеется объект, ссылающийся на пару объектов, которые в данном случае считаются связанными; - связь посредством документа; этот вид связи аналогичен предыдущему и выделен, чтобы подчеркнуть особую роль объекта «Документ», поскольку в данном случае связями считаются не только программные ссылки, но и упоминания объектов в контенте объекта «Документ»; - иной вид связи; этот вид связи не может быть определен посредством анализа данных системы и устанавливается исключительно ЛПР. Кроме того, строится таблица, детализирующая параметры связи, а именно: имена свойств объектов, посредством которых осуществляется связь; идентификаторы объектов, выступающих в роли связующих; приоритет связи (целое число от 0 до 10); описание связи, заполняемое автоматически или ЛПР. БД ЭО ПК, хранящая записи о типах связей и их наличии между объектами системы экспертиз Дирекции, оперирует параметрами и хранит данные об их значениях в определенные моменты времени. ЭО ПК периодически запускает процесс актуализации данных о значениях параметров. Описание проблемы Количество параметров ЭО ПК варьируется от 100 до 200, количество различных типов связей объектов, которые могут быть установлены ЭО ПК, превышает 500. Данный факт затрудняет эффективный интеллектуальный анализ данных в режиме реального времени [1]. В связи с этим возникает задача разработки алгоритма, позволяющего отобрать входные данные, которые будут подаваться на вход комплекса прогнозирования и принятия решений [1], устанавливающего взаимосвязи объектов в анализируемой системе экспертиз. Для установления значимых взаимосвязей между объектами системы экспертиз Дирекции требуется осуществить предварительный анализ исходных данных с целью последующего сокращения объема данных, анализируемых в модуле построения визуального представления взаимосвязей объектов в системе экспертиз Дирекции. Алгоритм отбора значимых параметров Для отбора значимых параметров предлагается решение, основанное на использовании мягких вычислений, в частности, нейронных сетей и эволюционных алгоритмов. Принцип работы алгоритма, реализованного для предварительного анализа исходных данных и решения задачи отбора входных переменных для конкретного случая прогнозирующей искусственной нейронной сети (ИНС) [2], базируется на сочетании ИНС и генетического алгоритма (ГА) [3, 4]. Главными операторами ГА являются кроссинговер, мутация, выбор родителей и селекция (отбор хромосом в новую популяцию). Вид оператора играет важную роль в реализации и эффективности ГА. Существуют основные формы операторов, чистое использование или модернизация которых ведет к получению ГА, пригодного для решения конкретной задачи [5]. Важнейшие понятия, используемые в работе данного алгоритма, – прогнозный горизонт и период основания прогноза. Прогнозный горизонт – максимально возможный период упреждения прогноза заданной точности [5]. Периодом основания прогноза считается промежуток времени, за который используют информацию для разработки прогноза [5]. Процесс выполнения ГА описывается последовательностью выполняемых операторов [6–8]: - инициализация, или выбор исходной популяции хромосом; - селекция – выбор хромосом, которые будут участвовать в создании потомков для следующей популяции; - применение генетических операторов – мутации и скрещивания (кроссинговера); - сокращение популяции до исходного размера за счет оценки качества хромосом в популяции – расчет функции пригодности для каждой хромосомы; - проверка условия остановки алгоритма; - выбор наилучшей хромосомы. Работа ГА представлена на рисунке 2. В реализованном алгоритме ГА работает с наборами векторов, сформированными из блоков срезов данных ЭО ПК с учетом значений прогнозного горизонта и периодом основания прогно- за [9]. Блок срезов данных представляет собой матрицу Начальный вектор данных формируется из блока срезов следующим образом: [V11, …, V1p, …, Vk1, …, Vkp]T. Он имеет длину, равную k·p, и представляет собой набор значений, которые могут быть поданы на вход нейронной сети для прогнозирования возможности установления взаимосвязи между объектами системы экспертиз. Перед запуском алгоритма необходимо ввести настройки работы алгоритма: количество хромосом в популяции Npop, итераций Nitr, особей Nbest, для которых будут применены генетические операторы, операций скрещивания Nc и операций мутации Nm на каждом шаге алгоритма, а также вероятности pc и pm скрещивания и мутации соответственно [10, 11]. На шаге инициализации происходит формирование исходной популяции из Npop хромосом длины k·p со случайно сгенерированными значениями генов (аллелями). Аллели в хромосомах представляются в двоичном виде и определяют, какие элементы входных векторов должны использоваться при построении и обучении ИНС: 0 – элемент не используется, 1 – элемент используется [1, 5]. Селекция заключается в расчете качества (значения функции пригодности) каждой хромосомы и выборе по рассчитанным значениям Nbest хромосом, которые будут участвовать в создании потомков для следующего поколения. Выбор хромосом в данном случае производится согласно принципу естественного отбора: чем выше качество хромосомы, тем больше вероятность ее участия в создании новых особей [5].
На этапе мутации в цикле по Nm случайным образом выбираются хромосома из потомков, созданных на этапе скрещивания, и любой ее ген, аллель которого с вероятностью pm меняется на противоположную [12]. Сокращение популяции до исходного размера Npop происходит в соответствии с качеством каждой хромосомы: чем выше качество, тем больше вероятность попадания хромосомы в новую популяцию. Полученная популяция становится текущей для следующей итерации ГА [12]. Затем производится проверка условия оста- новки алгоритма и фиксируется результат в виде хромосомы наивысшего качества либо осуществляется переход к следующему шагу генетического алгоритма, то есть к селекции. В данном случае условие остановки – достижение определенного количества итераций Nitr [12]. Апробация алгоритма на реальных данных Рассматриваемая модель взаимодействия объектов в системе экспертиз Дирекции содержит более сотни параметров, определяющих наличие взаимосвязей между объектами и их типы. Различных видов взаимосвязей было выявлено около тысячи. В качестве целевого типа взаимосвязи при построении прогноза выбрана взаимосвязь с типом «Документ» с приоритетом 1 и кодом 10. Взаимосвязь подразумевает, что в системе экспертиз существует документ, содержащий в описательной форме упоминания о паре объектов, для которых рассматривается данная взаимосвязь. В подобном случае синтаксический анализ контекста, где упоминаются эти объекты, не проводится. Такая взаимосвязь выбрана из-за большой частоты возникновения, что дает возможность использования небольших объемов данных для анализа. БД срезов значений параметров ЭО ПК обновлялась в течение всего срока подачи заявок по госпрограммам Дирекции при каждом добавлении нового документа в систему экспертиз, потенциально содержащего данные о связях объектов системы. В своем исследовании авторы используют самоорганизующиеся карты Кохонена в сочетании с нейронной сетью с обратным распространением и ГА. Самоорганизующиеся карты Кохонена в первую очередь служат для первоначального (разведывательного) анализа данных. Каждая точка данных отображается соответствующим кодовым вектором из решетки. Так получают представление данных на плоскости, карту данных. На этой карте возможно отображение многих слоев, в частности, количество данных, попадающих в узлы (то есть плотность данных), различные функции данных и т.д. Карта данных является подложкой для произвольного по своей природе набора данных. На карте данных близкие объекты имеют близкие свойства. Карта служит также информационной моделью данных. С ее помощью можно заполнять пробелы в данных [9]. Эта последняя ее способность используется авторами для решения задачи прогнозирования. Следующим слоем модели является многослойный персептрон с обратным распространением ошибки. Обучение алгоритмом обратного распространения ошибки предполагает два прохода по всем слоям сети – прямой и обратный. При прямом проходе входной вектор подается на входной слой нейронной сети, после чего распространяется по сети от слоя к слою. В результате генерируется набор выходных сигналов, который и является фактической реакцией сети на данный входной образ. Во время прямого прохода все синаптические веса сети фиксированы. Во время обратного прохода все синаптические веса настраиваются в соответствии с правилом коррекции ошибок, а именно: фактический выход сети вычитается из желаемого, в результате формируется сигнал ошибки. Этот сигнал впоследствии распространяется по сети в направлении, обратном направлению синаптических связей.
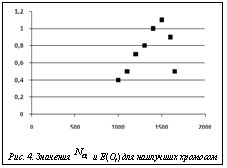
Полученные блоки срезов представлены в виде векторов X=[V11, …, V1p, …, Vk1, …, Vkp]T и поровну разделены между обучающим и контрольным наборами. В каждом из наборов содержатся векторы, образованные приводящими к установлению взаимосвязи блоками срезов, и векторы, образованные не приводящими к установлению взаимосвязи блоками срезов. Их количество в каждом наборе примерно одинаковое. Настройки работы самого ГА следующие: количество хромосом в популяции Npop=1 000; количество итераций Nitr; количество особей для создания потомков Nbest; количество операций скрещивания Nc и количество операций мутации Nm – случайно сгенерированные целые числа в промежутке от 10 до 50; вероятности pc и pm скрещивания и мутации, равные 0,5 и 0,1 соответственно. Было проведено несколько запусков алгоритма с разными значениями параметров, выбираемых случайно, в качестве конечного результата отобран лучший из достигнутых во всех запусках [1]. Функция пригодности рассчитывается следующим образом: для каждой хромосомы Oi в текущей популяции строится ИНС, проводится ее обучение на обучающем наборе векторов и оценивается качество прогнозирования на контрольном наборе. Архитектура использованной ИНС (рис. 3) включает входной слой, состоящий из нейронов, количество которых определяется числом Построенная ИНС обучается с использованием векторов из обучающего набора. При этом хромосома Oi определяет, какие из значений будут поданы на вход ИНС: используются только те элементы векторов, для которых значение аллелей в данной хромосоме на соответствующем месте равно 1. После обучения проводится проверка качества прогнозирования полученной ИНС с помощью векторов из контрольного множества. При этом отбор входных значений осуществляется аналогичным образом с учетом хромосомы Oi. Таким образом, рассчитывается внешний критерий, характеризующий качество применяемого метода по тем данным, которые не использовались в процессе обучения ИНС. В используемом алгоритме [1] в качестве внешнего критерия применяется следующий критерий ошибки на контрольных данных: Очевидно, что в данном случае чем меньше значение данного критерия, тем выше качество хромосомы. Функция пригодности имеет вид На рисунке 4 изображен график, на котором показаны значения количества единичных аллелей По результатам нескольких запусков ГА была отобрана хромосома максимального качества с функцией пригодности 0,59. После проверки работы соответствующей прогнозирующей ИНС на наборе данных, не участвовавших в отборе с помощью ГА, получен результат, определивший, что прогноз построен правильно примерно в 80 % случаев. Из них в 65 % правильный прогноз сделан в случае наличия взаимосвязи и в 90 % – в случае отсутствия взаимосвязи.
Естественно, эвристические методы имеют свои недостатки, в частности, могут приводить к потере значимой информации в процессе своей работы, поэтому требуют дополнительного контроля и постоянной подстройки управляющих параметров. В дальнейшем предполагается рассмотреть возможности применения более устойчивых к ошибкам такого рода стохастических методов выявления значимых характеристических параметров системы. Литература 1. Иванова Е.И., Сорокин С.В. Оптимизация базы данных и построение модели прогнозирования неисправностей вагонного оборудования на основе нейросетевых технологий и методов эволюционного программирования для информационной системы управления железнодорожным транспортом // Нечеткие системы и мягкие вычисления. 2012. Т. 7. № 2. С. 89–98. 2. Хайкин C. Нейронные сети. Полный курс. М.: Вильямс, 2006. 3. Кричевский М.Л. Интеллектуальные методы в менеджменте. СПб: Питер, 2005. 304 с. 4. Дубровин В.И., Субботин С.А. Оценка значимости признаков с фиксацией значений // Нейронные сети и модели в прикладных задачах науки и техники: тр. междунар. конф. КЛИН-2002. Ульяновск: УлГТУ, 2002. Т. 3. С. 101–102. 5. Панченко Т.В. Генетические алгоритмы: учеб.-методич. пособие. Астрахань: Издат. дом «Астраханский университет», 2007. 87 с. 6. Back T., Fogel D.B. Michalewicz Z. Evolutionary Computation 1. Basic Algorithms and Operators, Institute of Physics Publ., Bristol, 2000. 7. Frénay B., Doquire G., Verleysen M. Is mutual information adequate for feature selection in regression? Neural Networks, 2013, no. 48, pp. 1–7. 8. Shena C., Lib H., van den Hengela A. Fully corrective boosting with arbitrary loss and regularization. Neural Networks. 2013, no. 48, pp. 44-58. 9. Okuno H., Yagi T. A visually guided collision warning system with a neuromorphic architecture. Neural Networks, 2008, vol. 21, no. 10, pp. 1431–1438. 10. Галушка В.В., Молчанов А.А., Фатхи А.А. Применение многослойных радиально-базисных нейронных сетей для верификации реляционных баз данных // Инженерный вестник Дона. 2012. № 1. URL: http://ivdon.ru/magazine/archive/n1y2012/ 686 (дата обращения: 06.08.2013). 11. Галушка В.В., Фатхи В.А. Формирование обучающей выборки при использовании искусственных нейронных сетей в задачах поиска ошибок баз данных // Инженерный вестник Дона. 2013. № 2. URL: http://www.ivdon.ru/magazine/archive/ n2y2013/ 1597 (дата обращения: 06.08.2013). 12. Жданов В.А. Методы и алгоритмы многокритериальной оптимизации кластерных информационных систем: дис. … канд. техн. наук. М.: МГИЭТ. 2008. References 1. Ivanova E.I., Sorokin S.V. Nechyotkiye sistemy i myagkiye vychisleniya [Fuzzy Systems and Soft Computing]. 2012, vol. 7, no. 2, pp. 89–98. 2. Khaykin C. Neyronnye seti. Polny kurs [Neural networks. Full-time course]. Moscow, Vilyams Publ., 2006 (in Russ.). 3. Krichevskiy M.L. Intellektualnye metody v menedzhmente [Intelligent methods in management]. St. Petersburg, Piter Publ., 2005 (in Russ.). 4. Dubrovin V.I., Subbotin S.A. Neyronnyye seti i modeli v prikladnykh zadachakh nauki i tekhniki: Trudy mezhdunar. konf. KLIN-2002 [Neural networks and models in applied problems of science and technology]. Ulyanovsk State Tech. Univ. Publ., 2002, vol. 3, pp. 101–102 (in Russ.). 5. Panchenko T.V. Geneticheskiye algoritmy [Genetic algorithms]. Astrakhan, Astrakhanskiy Univ. Publ., 2007, 87 p. 6. Back T., Fogel D.B., Michalewicz Z. Evolutionary Computation 1. Basic Algorithms and Operators. Bristol, Institute of Physics Publ., 2000. 7. Frénay B., Doquire G., Verleysen M. Neural Networks. 2013, no. 48, pp. 1–7. 8. Shena Ch., Lib H., Hengela A. Neural Networks. 2013, no. 48, pp. 44–58. 9. Okuno H., Yagi T. Neural Networks. 2008, vol. 21, no. 10, pp. 1431–1438. 10. Galushka V.V., Molchanov A.A., Fatkhi A.A. Inzhenerny vestnik Dona [Engineering Bulletin of Don]. 2012, no. 1, available at: http://ivdon.ru/magazine/archive/n1y2012/686 (accessed 06 August 2013). 11. Galushka V.V., Fatkhi V.A. Inzhenerny vestnik Dona [Engineering Bulletin of Don]. 2013, no. 2, available at: http://www.ivdon.ru/magazine/archive/n2y2013/1597 (accessed 06 August 2013). 12. Zhdanov V.A. Metody i algoritmy mnogokriterialnoy optimizatsii klasternykh informatsionnykh system [Methods and algorithms of multiobjective optimization of cluster information systems]. Ph.D. thesis, Moscow, MIET Publ., 2008 (in Russ.). |
 В результате возникло противоречие между практической потребностью управления большими массивами показателей в среде единого информационного пространства и отсутствием соответствующего научно-технического задела, позволяющего обеспечить удовлетворение этой потребности.
В результате возникло противоречие между практической потребностью управления большими массивами показателей в среде единого информационного пространства и отсутствием соответствующего научно-технического задела, позволяющего обеспечить удовлетворение этой потребности.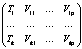 .
. На этапе скрещивания в цикле по Nc случайным образом выбираются две хромосомы из отобранных на этапе селекции, порождающие нового потомка; с вероятностью pc потомок наследует ген первого или второго родителя. Потомок включается в состав текущей популяции [12].
На этапе скрещивания в цикле по Nc случайным образом выбираются две хромосомы из отобранных на этапе селекции, порождающие нового потомка; с вероятностью pc потомок наследует ген первого или второго родителя. Потомок включается в состав текущей популяции [12].
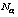 единичных аллелей в хромосоме Oi; промежу- точный слой Кохонена, формирующий группы наиболее близких векторов; многослойный персептрон, состоящий из двух рабочих слоев и выходного слоя, содержащего только один нейрон. Выходное значение нейрона рассматривается как сигнал, обозначающий наличие/отсутствие рассматриваемого типа взаимосвязи.
единичных аллелей в хромосоме Oi; промежу- точный слой Кохонена, формирующий группы наиболее близких векторов; многослойный персептрон, состоящий из двух рабочих слоев и выходного слоя, содержащего только один нейрон. Выходное значение нейрона рассматривается как сигнал, обозначающий наличие/отсутствие рассматриваемого типа взаимосвязи. , где m – количество векторов в контрольном наборе; yk – ожидаемое значение для k-го вектора в контрольном наборе; xk – значение, выданное ИНС для k-го вектора в контрольном наборе.
, где m – количество векторов в контрольном наборе; yk – ожидаемое значение для k-го вектора в контрольном наборе; xk – значение, выданное ИНС для k-го вектора в контрольном наборе.
 .
. В заключение отметим, что в результате применения описанного в работе алгоритма были получены данные о выявленных значимых параметрах при установлении взаимосвязей между объектами системы экспертиз Дирекции. Это значительно сократило объем анализируемых данных на последующих этапах процесса формирования графа представления взаимосвязей объектов системы экспертиз Дирекции и позволило ускорить работу системы визуализации в несколько раз.
В заключение отметим, что в результате применения описанного в работе алгоритма были получены данные о выявленных значимых параметрах при установлении взаимосвязей между объектами системы экспертиз Дирекции. Это значительно сократило объем анализируемых данных на последующих этапах процесса формирования графа представления взаимосвязей объектов системы экспертиз Дирекции и позволило ускорить работу системы визуализации в несколько раз.| Постоянный адрес статьи: http://swsys.ru/index.php?id=3681&page=article |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
| Статья опубликована в выпуске журнала № 4 за 2013 год. [ на стр. 176-182 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Интеллектуальная информационная система для решения задач прогнозирования неисправностей вагонного оборудования на железнодорожном транспорте
- Информационная система аналитического сценария формирования долга региона
- Технологии мягких вычислений в интеллектуальном управлении
- Интеллектуальная система прогнозирования на основе методов искусственного интеллекта и статистики
- Универсумная методика разработки АСУ предприятий
Назад, к списку статей