Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Нечеткий фильтр калмана в структуре алгоритма решения обратных задач для экономических объектов
Аннотация:Предложен метод решения обратных задач на основе применения нечеткого фильтра Калмана, учитывающего специфику объектов экономики, такую как невозможность построить физическую модель процесса или явления. В основе алгоритма лежат переход от описания системы в форме интегрального уравнения Фредгольма I рода к форме дискретного фильтра Калмана, а также применение методов нечеткой логики для задания элементов уравнений фильтра. Рассматриваемый метод решения обратных задач опирается на данные о выходном процессе объекта, которые обычно являются результатом измерений каких-либо параметров. Наличие шума измерений приводит к дополнительному снижению точности решения, поэтому целесообразно применение такого алгоритмического средства, как фильтрация, способствующего уменьшению этого влияния. В случае экономического объекта шум измерений может трактоваться как, например, погрешности получаемых статистических данных, неточность аналитических и экспертных моделей, применяемых при трактовке результатов его функционирования. Для снижения субъективизма, вносимого в базу знаний экспертами, предлагается применение методов нечеткого кластерного анализа и адаптивных нейро-нечетких систем, позволяющих автоматически синтезировать структуру базы знаний. Средой разработки программного обеспечения выбран MatLAB, имеющий библиотеку для создания адаптивных нейро-нечетких систем (ANFIS-редактор).
Abstract:A method solving inverse problems using Kalman fuzzy filter considering specific economic facilities, such as the inability to build a physical model of the process or phenomenon has been proposed. The algorithm is based on the transition from the system description in the form of a Fredholm integral equation of the type I to the form of the discrete Kalman filter, as well as the using fuzzy logic to set the elements of filter equations. The method for solving inverse problems is based on object output process data, which is usually the result of any parameters measurement. The measurement noise results in a further decrease of the solutions accuracy. Therefore it is appropriate to use filtration which reduces this impact. As for economic object, the measurement noise can be interpreted as statistical data precision, inaccurate analysis and expert models used in the interpretation of its operating results and others. To reduce experts subjectivity contributed to the knowledge base, it is proposed to apply fuzzy cluster analysismethods and adaptive neuro-fuzzy systems methods allowing automatical synthesizing the knowledge base structure. MatLAB has been used as a software development environment, because it has a library to create adaptive neuro-fuzzy systems (ANFIS-editor).
| Авторы: Павлов Д.А. (putchkov63@mail.ru) - Филиал Московского энергетического института в г. Смоленске, г. Смоленск, Россия | |
| Ключевые слова: фильтр калмана, нечеткая логика, обратные задачи, интегральное уравнение фредгольма |
|
| Keywords: Kalman filter, fuzzy logic, inverse problems, intelligent control |
|
| Количество просмотров: 14146 |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
Новые направления и результаты исследований в области информационных технологий все более привлекают бизнес, позволяя ему за счет внедрения передовых информационных методов получать устойчивый рост прибыли как главной цели своего существования. Разработка новых алгоритмов, методов обработки данных, совершенствование и модификация имеющихся подходов с учетом изменившихся требований и возможностей вычислительной техники становятся привлекательным направлением разработок и усилий специалистов в области IT, так как позволяют привлекать значительные материальные ресурсы заинтересованных бизнес-структур. Одним из таких направлений можно считать разработку инфор- мационных систем диагностики состояний экономических систем, позволяющих по результатам анализа показателей функционирования системы сделать суждение о причинах, вызвавших такое состояние. Поиск причин в наиболее простых случаях взаимосвязи выходных и входных сигналов не вызывает трудностей (например, при связи выхода x и входа v вида x=kv причину v, вызвавшую появление x, легко определить при известном k). Однако такие ситуации встречаются редко – чаще приходится иметь дело со сложными зависимостями (так, при x=kv2 определить причину v однозначно уже не удается). С точки зрения математики обозначенная проблема диагностики может быть отнесена к классу некорректно поставленных задач, а именно, к подклассу обратных задач [1]. Задачи в обратной постановке возникают и решаются в самых различных областях: в рентгеновской компьютерной томографии, магнитно-резонансной томографии, реконструкции искаженных изображений (иконки), спектроскопии, геологоразведке. Процесс решения обратных задач опирается на данные о выходном процессе, которые обычно являются результатом измерений. Наличие шума измерений приводит к дополнительному снижению точности решения, поэтому целесообразно применение такого алгоритмического средства, как фильтрация, способствующего уменьшению этого влияния. Одна из возможных структур решения обратных задач с применением фильтра предложена в [2]. В этой структуре сделана попытка компенсировать одну из возможных некорректностей обратных задач, которая проявляется в том, что малые изменения исходных данных приводят к произвольно большим изменениям решений. Для снижения влияния этого фактора там использована искусственная нейронная сеть, на вход которой подаются данные, подвергнутые процедуре фильтрации. В качестве алгоритма фильтрации использован фильтр Калмана. Процедуру решения реализует искусственная нейронная сеть, а фильтр является обеспечивающей подсистемой, улучшающей точность решения. Рассмотрим другую структуру алгоритма решения обратной задачи, также использующую фильтрацию, но уже без применения нейронной сети. Такая структура решения позволяет использовать наибольшее количество априорной информации среди устойчивых (регулярных) методов: в методе Калмана – ковариации ошибок и математического ожидания правой части и решения, а в методе Винера – спектральные плотности мощности шумов правой части и решения [3]. Данные методы относятся к методам статистической регуляризации. Процедура регуляризации в общем случае позволяет перейти от постановки задачи, приводящей к неустойчивому решению, к постановке, дающей устойчивый результат. Объекты экономики не функционируют сами по себе, они встроены в контур управления, где роль регулятора выполняет административная надстройка, а исполнительный механизм состоит из рабочих и служащих, реализующих бизнес-процесс. В этой связи можно рассматривать задачу управления в постановке и терминах, аналогичных применяемым для технических объектов. Проявляющаяся в процессе изложения материала специфика экономического приложения методов будет оговариваться отдельно. Обозначим входной сигнал (управляющее воздействие) V, а выходной (реакция системы) x. В обратной постановке получаем задачу восстановления сигнала V по измеренному выходному сигналу x. Дискретный аналог интегрального уравнения Фредгольма I рода, связывающего сигналы x и V, позволяет перейти к постановке решения обратной задачи, характерной для фильтра Калмана [3]:
где А – матрица размером m´n; Ni – дискреты m-мерного шума измерений. В методе фильтрации Калмана делаются следующие предположения. 1. Математическое ожидание случайного вектора N равно нулю: E[N]=0, где запись E[N] означает математическое ожидание. 2. Задана симметричная положительно определенная m´n-матрица ковариации ошибок правой части: R=E[N NТ]. Каждый диагональный элемент матрицы R представляет собой квадрат среднеквадратической погрешности измерения Ni, то есть Ri=si2, а внедиагональный элемент Ri, i≠j, определяет корреляцию погрешностей Ni и Nj. 3. Задан n-вектор y=E[V] – математическое ожидание (начальное приближение, априорная оценка, прогноз) вектора V. 4. Задана симметричная положительно определенная n´п-матрица – априорная ковариация ошибок решения: M=E[(V–ψ)(V–ψ)Т]. Далее искомое решение V находится из условия минимума квадратичной формы: (AV–x)Т R-1 (AV–x)+(V–ψ)Т M-1(V–ψ)=miny . (2) Из условия (2) получается решение (апостериорная оценка V, свертка замера с прогнозом): Vоц=ψ+(M– 1+AТR-1A)-1AТR-1(N–A ψ), (3) причем апостериорная n´n-матрица ковариаций ошибок решения равна P≡E[(Vоц–V)(Vоц–V)Т]=(M-1+AТR-1A)-1. (4) Итак, если помимо N и А известны дополнительно R, ψ и М, то уточненное решение уравнения (2) согласно методу фильтрации Калмана выразится формулой (3), а уточненная матрица ковариаций ошибок решения – формулой (4). Когда имеется лишь одна реализация вектора x, требование об априорном знании ψ и М, содержащееся в методе Калмана, трудновыполнимо. Поэтому фильтр Калмана обычно применяется в том случае, когда в функции времени поступают новые реализации х, а ψ и М итеративно уточняются. Отличительной чертой объектов экономики является невозможность применения к ним физических законов и, соответственно, получения аналитических зависимостей, точно описывающих происходящие в них процессы. Объясняется это тем, что на функционирование организации, помимо законов экономики, влияет еще множество факторов: социальных, политических, случайных, вызванных природными явлениями и катаклиз- мами. В этих условиях на помощь приходят интеллектуальные методы, позволяющие найти решение в обозначенных выше условиях. В рассматриваемом подходе к решению обратных задач предлагается формировать значения матрицы А из (1), используя продукционные правила системы нечеткого вывода [4]. Нахождение Ai,j выполняется на основании процедуры нечеткого вывода с использованием базы знаний, сформированной экспертами соответствующей предметной области. База знаний заполняется набором правил вида Пi: ЕСЛИ g1 ЕСТЬ «Gj» И g2 ЕСТЬ «Gj+1» … И gk ЕСТЬ «Gj+u», ТО Ai,j ЕСТЬ «Di», (5) где g – некоторый параметр, учитываемый экспертами при формировании матрицы А; Gi – лингвистическая переменная «величина g», содержащая термы «малое значение», «среднее значение» и т.д.; k – количество учитываемых параметров g; Di – лингвистическая переменная «значение d», определяющая значение элемента Ai,j, содержа- щая термы «малое значение», «среднее значение» и т.д. Представленные выкладки демонстрируют, что калмановский алгоритм может быть приспособлен для решения обратных задач, исходная постановка которых базируется на интегральных уравнениях Фредгольма. Структура такого алгоритма представлена на рисунке 1. В отличие от структуры, приведенной в [2], здесь отсутствует искусственная нейронная сеть, так как процедуру решения выполняет сам фильтр.
Нейро-нечеткую сеть можно рассматривать как одну из разновидностей систем нечеткого логического вывода типа Сугэно. При этом функции принадлежности синтезированных систем настроены (обучены) так, чтобы минимизировать отклонения между результатами нечеткого моделирования и экспериментальными данными [5, 6]. В качестве примера использования предлагаемого алгоритма возьмем взаимосвязь таких характеристик экономического объекта, которые трудно поддаются точному расчету по бухгалтер
Общая постановка задачи звучит так: по имеющимся данным о средних объемах продаж конкурирующей фирмы, которые могут быть неточны, требуется сделать заключение о качестве обслуживания V в ней, чтобы с помощью этих сведений менеджеры компании могли принять соответствующие решения для обеспечения положительной динамики развития своей фирмы. Неточность данных может быть обусловлена рядом причин, такими как нежелание фирмы-конкурента предоставлять такие данные в свободное пользование; ошибки, допускаемые источниками информации; преднамеренные искажения информации и ряд других. Предположим, что имеются данные о средних объемах продаж за шесть фиксированных интервалов времени (например, за шесть последних месяцев) в четырех филиалах фирмы-конкурента. Целесообразно сразу привести объемы продаж к диапазону от 0 до 1, чтобы обеспечить нормирование точности расчетов. Так как оцениваемые объемы продаж находятся в диапазоне от 0 до 70 тысяч рублей (рис. 2), приведение к диапазону от 0 до 1 происходит делением абсолютных значений на 70 тысяч рублей. В результате получаем исходные данные, отраженные на рисунке 3. Реализацию алгоритма начнем с формирования матрицы А. Учитывая, что имеются четыре филиала, в матрице А будут четыре строки. Для упрощения иллюстративных расчетов количество столбцов возьмем также равным четырем. При определении элементов матрицы А будем считать, что качество обслуживания в филиалах взаимно независимо, поэтому aij=0, если i≠j, и aij≠0 при i=j. Учитывая, что объемы продаж не выходят за рамки коридора от 20 до 50 тысяч рублей, зависимость х(V) на этом интервале можно считать линейной и А(V)=A. Если для всех филиалов зависимость, показанная на рисунке 2, одинаковая, то и диагональные элементы матрицы А будут одинаковыми. Для перехода к форме (1) необходимо найти параметры шума N, а именно, среднеквадратичное отклонение si. На основании данных, отображенных на рисунках 2 и 3, определяются оценки si для филиалов. Шести реализаций для каждого филиала недостаточно для статистически корректных расчетов, но пример носит иллюстративный характер. Старт расчетов по алгоритму требует наличия априорной оценки вектора математического ожидания сигнала V, в качестве которой возьмем середину диапазона от 20 до 50 тысяч рублей для филиалов, что с учетом нормировки приводит к вектору ψТ=(0,5 0,5 0,5 0,5). Данный вектор и априорная ковариация ошибок решения M в процессе итерационной процедуры будут постоянно уточняться, поэтому их начальные значения могут быть выбраны достаточно грубо. В рассматриваемом примере моделируется ситуация, когда последовательно приходят шесть отсчетов, на основании которых формируется оценка значений V на основе наблюдаемых х. В данном случае получаем нормированный вектор xТ=(0,55 0,49 0,51 0,46) или, переходя к абсолютным значениям: (38500 34300 35700 32200). На основании этих данных, используя зависимость на рисунке 2, определяются оценки качества VТ=(4,81 4,63 4,68 4,56). Полученные значения интерпретируются менеджерами для оценки состояния системы обеспечения качества на предприятии-конкуренте и выработки соответствующих мероприятий в своей организации. На данном иллюстративном примере показан порядок применения рассмотренного подхода к решению обратных задач. Однако этот пример не позволяет провести сравнительный анализ точности данного метода с уже известными ввиду небольшого количества данных, но, как ожидается, его точность повысится за счет использования алгоритма фильтрации Калмана, что будет проанализировано во время дальнейших исследований. Предложенная структура алгоритма решения обратных задач может быть положена в основу ПО, используемого в системах поддержки принятия решений в различных отраслях экономики. Литература 1. Тихонов А.Н., Арсенин В.Я. Методы решения некорректных задач. М.: Наука, 1979. 2. Абраменкова И.В., Пучков А.Ю., Павлов Д.А. Нейро-нечеткий метод снижения чувствительности решения обратных задач к вариациям данных // Программные продукты и системы. 2011. № 4 (96). С. 72–75. 3. Сизиков В.С. Устойчивые методы обработки результатов измерений. СПб: СпецЛит, 1999. 240 с. 4. Гимаров В.А., Дли М.И., Круглов В.В. Задачи распознавания нестационарных образов // Изв. РАН. Теория и системы управления. 2004. № 3. С. 92–96. 5. Бояринов Ю.Г., Борисов В.В., Мищенко В.И., Дли М.И. Метод построения нечеткой полумарковской модели функционирования сложной системы // Программные продукты и системы. 2010. № 3. С. 26–31. 6. Мешалкин В.П., Белозерский А.Ю., Дли М.И. Методика построения комплексной математической модели управления рисками предприятия металлургической промышленности // Прикладная информатика. 2011. № 3. С. 100–120. References 1. Tikhonov A.N., Arsenin V.Ya. Metody resheniya nekorrektnykh zadach [Methods of the solution of incorrect tasks]. Moscow, Nauka Publ., 1979. 2. Abramenkova I., Puchkov A.Yu., Pavlov D. A. Neuro and indistinct method of decrease in sensitivity of the inverce tasks solution to data variations. Programmnye produkty i sistemy [Software & Systems]. 2011, no. 4 (96), pp. 72–75. 3. Sizikov V.S. Ustoychivye metody obrabotki rezultatov izmereniy [Steady methods of processing measurements results]. St. Petersburg, SpetsLit Publ., 1999, 240 p. 4. Gimarov V.A., Dli M.I., Kruglov V.V. Problems of non-stationary images recognition. Journ. of Computer and Systems Sciences Int. 2004, no. 3, pp. 92–96. 5. Boyarinov Yu.G., Borisov V.V., Mishchenko V.I., Dli M.I. A building technique for fuzzy semi-Markov model of complex system functioning. Programmnye produkty i sistemy [Software & Systems]. 2010, no. 3, p. 26. 6. Meshalkin V.P., Belozerskiy A.Yu., Dli M.I. A building technique for complex mathematical model of metallurgy industry enterprise risk management. Applied informatics. 2011, no. 3, pp. 100–120. |
 +Nj=xi , (1)
+Nj=xi , (1) Процедура формирования базы правил экспертами, безусловно, вносит определенный субъективизм в процесс решения. Однако его влияние можно значительно снизить различными способами, начиная от усреднения оценок экспертов и заканчивая применением методов статистической обработки информации, поступающей из различных источников об экономическом объекте, и методов нечеткого кластерного анализа. Применение последнего инструмента позволяет вообще избежать привлечения экспертов за счет использования систем ANFIS (AdaptiveNeuro-FuzzyInferenceSystem – адаптивная нейро-нечеткая система). ANFIS-редактор, реализованный в MatLAB [4], позволяет автоматически синтезировать из экспериментальных данных нейро-нечеткие сети.
Процедура формирования базы правил экспертами, безусловно, вносит определенный субъективизм в процесс решения. Однако его влияние можно значительно снизить различными способами, начиная от усреднения оценок экспертов и заканчивая применением методов статистической обработки информации, поступающей из различных источников об экономическом объекте, и методов нечеткого кластерного анализа. Применение последнего инструмента позволяет вообще избежать привлечения экспертов за счет использования систем ANFIS (AdaptiveNeuro-FuzzyInferenceSystem – адаптивная нейро-нечеткая система). ANFIS-редактор, реализованный в MatLAB [4], позволяет автоматически синтезировать из экспериментальных данных нейро-нечеткие сети. ским методикам. К такой взаимосвязи можно отнести зависимость среднего объема продаж х на одного работающего коммерческого предприятия за какой-либо период времени от качества обслуживания клиентов V. Объемы продаж измеряются в денежном эквиваленте, а для оценки качества обслуживания используется балльная система. Пусть количественно такую взаимосвязь, сформированную на основе экспертных оценок, отражает кривая, показанная на рисунке 2.
ским методикам. К такой взаимосвязи можно отнести зависимость среднего объема продаж х на одного работающего коммерческого предприятия за какой-либо период времени от качества обслуживания клиентов V. Объемы продаж измеряются в денежном эквиваленте, а для оценки качества обслуживания используется балльная система. Пусть количественно такую взаимосвязь, сформированную на основе экспертных оценок, отражает кривая, показанная на рисунке 2.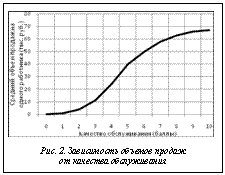 Эта кривая служит наглядным отображением набора правил (5). Зависимость учитывает тот факт, что при высоком качестве обслуживания продажи велики, но при этом наступает некоторое насыщение, когда повышение качества уже не дает той отдачи, которая наблюдалась в начале и середине шкалы качества.
Эта кривая служит наглядным отображением набора правил (5). Зависимость учитывает тот факт, что при высоком качестве обслуживания продажи велики, но при этом наступает некоторое насыщение, когда повышение качества уже не дает той отдачи, которая наблюдалась в начале и середине шкалы качества.| Постоянный адрес статьи: http://swsys.ru/index.php?id=3685&like=1&page=article |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
| Статья опубликована в выпуске журнала № 4 за 2013 год. [ на стр. 199-203 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Нейро-нечеткий метод снижения чувствительности решения обратных задач к вариациям данных
- Интервально-дифференциальные уравнения в структуре нечеткого фильтра Калмана при управлении сложными технологическими объектами
- Варианты построения алгоритма поиска решения обратных задач с применением нейронных сетей
- Основы структурно-лингвистического подхода в анализе нечетких временных рядов
- Организация адаптивной маршрутизации данных в электроэнергетических комплексах с использованием онтологических нечетких классификаторов
Назад, к списку статей