Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Система автоматического распознавания речи на татарском языке
Аннотация:В настоящей работе описывается система распознавания речи на татарском языке. В рамках системы предложен и реализован подход к построению модуля автоматического транскрибирования текстов, разработанный на основе выделенных правил звуковых изменений в татарском языке. Данные акустические правила были использованы благодаря их формальному представлению, полученному в разработанной программной системе. Кроме того, для реализации алгоритма распознавания речи были созданы два уровня анализа: акустический (уровень фонем) и лингвистический (уровень слов). На первом уровне были разработаны акустические модели 57 выделенных фонем татарского языка, каждая из которых базируется на аппарате скрытых марковских моделей. Для обучения каждой из указанных статистических моделей был образован речевой корпус общей продолжительностью 5 часов. Дополнительно был создан и применен алгоритм автоматической фонемной аннотации данного корпуса. В конечном итоге на базе разработанных программных средств и статистических моделей реализован алгоритм распознавания речи. Был проведен эксперимент по распознаванию слов татарского языка, по результатам которого предлагаемая система распознавания продемонстрировала 92-процентное качество распознавания на записях тестового корпуса.
Abstract:The paper describes speech analysis system for the Tatar language. An approach to creating automatic phonetic transcription system for Tatar texts has been developed and implemented. This system is based on acoustic rules for the Tatar language. These acoustic rules have been converted to a formalized form using developed programming tool. The two levels analysis procedure has also been developed in order to create speech recognition algorithm, these levels are: acoustic (phonemes) level, linguistic (words) level. Phonemes level consists of acoustic models for 57 Tatar phonemes, each of this phonemes is represented by a hidden Markov model. To train each of specified statistical model 5 hours speech corpus has been recorded. Additionally, an algorithm to automatically create phoneme-level annotation of this corpus has been developed and applied. Finally, a Tatar speech recognition algorithm has been implemented based on developed programming tools and acoustic models. In total, the proposed system has shown 92% word recognition correctness in test speech subcorpus.
| Авторы: Хусаинов А.Ф. (khusainov.aidar@gmail.com) - Казанский (Приволжский) федеральный университет (аспирант, научный сотрудник), Казань, Россия, Сулейманов Д.Ш. (khusainov.aidar@gmail.com) - Казанский (Приволжский) федеральный университет (профессор), г. Казань, Россия, доктор технических наук | |
| Ключевые слова: скрытые марковские модели, анализ речи, фонетическая транскрипция, татарский язык, корпус звучащей речи, распознавание речи |
|
| Keywords: hidden Markov models, speech analysis, phonetic transcription, Tatar language, speech corpus, speech recognition |
|
| Количество просмотров: 11605 |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
Развитие и широкое внедрение информационных технологий делает актуальной задачу развития более совершенных видов человеко-машинных интерфейсов. Одним из подходов к решению данной задачи является использование речи в качестве канала взаимодействия человека с компьютером. Для практической реализации этого подхода необходимо наличие средств как автоматического анализа (распознавание произнесенного текста, идентификация диктора, его эмоций, языка, возраста), так и синтеза речи. Решается совокупность данных задач с помощью речевых технологий, основными направлениями которых являются автоматическое распознавание речи, синтез речи, идентификация и верификация языка, идентификация и верификация диктора, распознавание эмоций диктора и тематики разговора. В данной работе рассматривается подход к решению одной из подзадач автоматического распознавания речи, а именно распознавание речи на татарском языке. Система автоматического распознавания речи является одним из ключевых элементов комплексных систем анализа речи, она может использоваться как самостоятельно, например в системах диктовки, так и в качестве вспомогательного модуля при решении задач определения языка говорящего, распознавании тематики разговора. Поставленная задача распознавания татарской речи решается в четыре этапа: 1) проектирование и создание корпуса звучащей татарской речи одного диктора; 2) разработка и реализация правил транскрибирования татарских текстов; 3) создание акустических моделей фонем татарского языка; 4) программная реализация системы распознавания речи. Звуковой корпус В качестве исходного материала при создании моделей фонем языка используется корпус звучащей речи. При этом необходимо наличие аннотации корпуса, включающей в себя текстовую и/или фонетическую разметку всех речевых фрагментов. Однако ручное фонетическое аннотирование – дорогостоящий и длительный процесс, требующий наличия множества квалифицированных фонетистов, что делает затруднительным создание данного типа разметки для корпуса татарской речи. Альтернативным решением может быть подход под названием phoneme alignment, который позволяет в параллельном режиме осуществлять как фонетическую разметку корпуса, так и обучение моделей фонем. Данный подход был использован в работе, а для его применения создана текстовая аннотация записанных голосовых файлов. На основе текстового корпуса, состоящего из 25,5 млн слов, построена статистика их частотности. Первые 10 788 самых часто употреблямых слов были выбраны для озвучивания в речевом корпусе. Запись звуковых фрагментов осуществлялась со следующими параметрами: формат файла WAV PCM, частота дискретизации 22 kHz, 16 бит на отсчет. Созданный корпус имеет параметры, представленные в таблице. Основные характеристики звукового корпуса
Акустические особенности татарского языка Для дальнейшего анализа необходимо перейти от текстового представления озвученных слов к их фонемной транскрипции. Для этого решаются следующие подзадачи: выделение значимых особенностей татарской речи, определение фонемного алфавита, построение правил транскрибирования, основанного на фонемном алфавите. В качестве основных базовых элементов языка, отличающихся в акустическом плане, а также способных оказывать влияние на смысл слова, было выбрано 57 фонем. На основе определенного инвентаря фонем выявлены акустические закономерности татарского языка. Приведем некоторые из выявленных правил: – аккомодация (в зависимости от первой гласной в слове используются либо все твердые, либо все мягкие согласные), например, «бар» – BA2R, «бер» – B1ER1; – уменьшение огубленности фонемы А от начала к концу слова, например, «балалар» – BA2LA1LAR; – замена некоторых звонких согласных, идущих рядом с глухим согласным, на парные им глухие, например, «тозсыз» – TOSSYS; – представление буквы Я в качестве пары J (й) и AA (ә), например, в случае, если перед ней идет буква И: иясе – IJAAS1E. Для создания автоматической системы транскрибирования было разработано АРМ фонетиста, которое предоставляет возможность создания формализованной записи правил. Форма создания и редактирования правил транскрибирования представлена на рисунке.
Вторым типом правил служат относительные правила, которые позволяют обрабатывать различные контексты следования тех или иных фонем, например, сочетание фонем Z-S заменяется на сочетание S-S, как, например, в слове «тозсыз» (T-O-S-S-I-Z). Общее количество созданных правил равняется 37. Акустические модели фонем Созданные на подготовительном этапе обучающий корпус речи и система транскрибирования позволяют реализовать алгоритм обучения акустических моделей фонем. Данный алгоритм носит название forced alignment и не требует наличия вручную фонетически аннотированного корпуса. Для реализации алгоритма использовался инструмент HTK Toolkit (http://speech.ee.ntu.edu.tw/ courses/DSP2011spring/hw2/HTKBook-3.4.1.pdf), созданный в Кембриджском университете, а в настоящее время принадлежащий компании Microsoft. Каждая фонема была смоделирована скрытой марковской моделью, состоящей из трех состояний, с ограничениями на переход на более ранние состояния. Каждое из трех состояний моделировалось, в свою очередь, смесью гауссовских распределений [1]. Процесс обучения акустических моделей производился итерационно: итерация увеличения количества гауссовских распределений в смеси сопровождалась двумя итерациями переобучения на данных обучающего корпуса. Проведенные исследования позволили выявить оптимальное количество распределений в смеси для каждой акустической модели, равное 31. Распознавание татарской речи Для проведения экспериментов по распознаванию речи было решено использовать тестовую часть созданного речевого корпуса. Таким образом, языковая модель при тестировании представляла собой список слов, каждое из которых обладало равной априорной вероятностью произнесения. Для всех слов была автоматически создана фонетическая транскрипция, которая послужила основой для объединения статистических моделей отдельных фонем в модели слов. На этапе распознавания с помощью алгоритма Витерби рассчитывались наиболее вероятная последовательность произнесенных фонем языка, а затем вероятности соответствия найденной последовательности моделям слов языка. Слово, соответствующее модели с максимальной вычисленной вероятностью, принималось в качестве результата распознавания. Для оценки качества работы созданной системы распознавания использовались две характеристики – Corr и Acc, которые рассчитываются по следующим формулам:
По результатам работы системы на тестовом корпусе величина Corr оказалась равной 91,99 %, а значение Acc – 88,22 %. Существующая разница между данными показателями отражает наличие небольшого количества лишних слов, когда одно произнесенное в звуковом файле слово было распознано как два и более. Стоит отметить, что величина Corr при распознавании фонем составила 63 %, что позволяет говорить о качестве работы системы, сопоставимом с существующими для других языков образцами систем [2]. На базе созданных программных средств распознавания речи были разработаны приложения для распознавания фонем и слов татарского языка. Пользовательский интерфейс системы распознавания фонем состоит из кнопок, отвечающих за начало и окончание записи файла, кнопки, запускающей процесс распознавания, и двух текстовых полей, отображающих текущее расположение аудиофайла и результат проведенного распознавания. Приложение распознавания слов татарского языка также предоставляет возможность записи речевого фрагмента с помощью микрофона и загрузки звуковых файлов. Форма приложения отображает и информацию о текущем выбранном устройстве записи звука, текущем аудиофайле (или об их количестве), текущем файле со списком произнесенных слов. Текстовый файл со списком произнесенных слов может быть загружен в систему для обеспечения возможности расчета качества проведенного распознавания. Рассчитанные характеристики Corr и Acc в таком случае отображаются в соответствующих текстовых полях данных. Кроме того, на экран выводятся результаты распознавания слов в текущих файлах. В заключение необходимо отметить, что построение и реализация алгоритма автоматического транскрибирования татарских текстов, а также создание аннотированного корпуса звучащей татарской речи позволили реализовать программный модуль автоматического распознавания речи на татарском языке. Применяемый при создании моделей фонем аппарат скрытых марковских моделей показал хорошее качество обучения. В рамках проведенных экспериментов по распознаванию слов татарского языка построенная система показала 92-процентное качество распознавания, что позволило использовать ее при создании пользовательского интерфейса для распознавания речи с возможностями записи речевого фрагмента с микрофона. Литература 1. Gales M., Young S. The Application of Hidden Markov Models in Speech Recognition. Foundations and Trends in Signal Processing, 2007, vol. 1, iss. 3, pp. 195–304. 2. Lopes C., Perdigao F. Phone recognition on TIMIT database. Speech technologies. InTech Publ., 2011, pp. 285–302. References 1. Gales M., Young S. The application of hidden markov models in speech recognition. Foundations and trends in signal processing. 2007, vol. 1, iss. 3, pp. 195–304. 2. Lopes C., Perdigao F. Phone recognition on TIMIT database. Speech technologies. InTech Publ., 2011, pp. 285–302. |
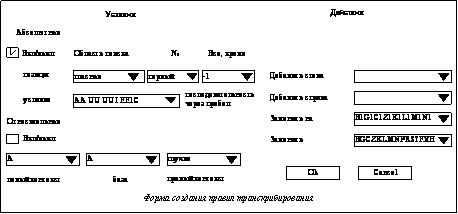 Правила могут быть двух типов: абсолютные и относительные. Абсолютные правила оперируют конкретным расположением той или иной фонемы в слове и позволяют заменять их другими. Примером данного типа правил может служить изображенное на рисунке правило аккомодации: область поиска ограничивается первой гласной, в качестве условий поиска задается список гласных переднего ряда, в случае выполнения указанного условия производятся замены, описанные в правой части экранной формы «Действия», а именно все согласные (перечисленные в поле «Заменить») заменяются на свои мягкие пары (указанные в поле «Заменить на»).
Правила могут быть двух типов: абсолютные и относительные. Абсолютные правила оперируют конкретным расположением той или иной фонемы в слове и позволяют заменять их другими. Примером данного типа правил может служить изображенное на рисунке правило аккомодации: область поиска ограничивается первой гласной, в качестве условий поиска задается список гласных переднего ряда, в случае выполнения указанного условия производятся замены, описанные в правой части экранной формы «Действия», а именно все согласные (перечисленные в поле «Заменить») заменяются на свои мягкие пары (указанные в поле «Заменить на»).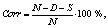 где N – общее число слов; D – число пропущенных при распознавании слов; S – число неправильно распознанных слов;
где N – общее число слов; D – число пропущенных при распознавании слов; S – число неправильно распознанных слов;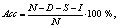 где I – число лишних слов.
где I – число лишних слов.| Постоянный адрес статьи: http://swsys.ru/index.php?id=3705&page=article |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
| Статья опубликована в выпуске журнала № 4 за 2013 год. [ на стр. 301-304 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Эффективность алгоритмов сопоставления персональных данных
- Алгоритм оценки значения остаточных рисков угроз информационной безопасности с учетом разделения механизмов защиты на типы
- Программный комплекс для интерпретации невербальной информации путем анализа образцов речи или электроэнцефалограммы
- Программная система для разработки многоязычного тезауруса
Назад, к списку статей