Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Программный комплекс восстановления пропущенных значений в многомерных данных на основе методов нечеткого моделирования
Аннотация:Описываются возможности нечетких систем для решения задач восстановления пропущенных значений в многомерных массивах данных. Рассмотрены нечеткая система типа синглтон и треугольная функция принадлежности лингвистического терма нечеткой системы. Приведен общий алгоритм метода эволюционной стратегии для идентификации нечеткой системы и рассмотрены два вида данного алгоритма с оценкой преимуществ и недостатков их применения. Описаны принцип параметрической идентификации нечеткой системы на основе метода эволюционной стратегии, а также требования к структуре входных данных. Приведен алгоритм восстановления пропущенных значений с применением нечеткой системы на основе метода эволюционной стратегии. Проведена экспериментальная оценка эффективности применения представленного алгоритма нечеткой системы на основе метода эволюционной стратегии для задачи восстановления пропущенных значений на сформированной тестовой выборке данных о свойствах нефти. Для тестовых данных подобраны оптимальные параметры нечеткой системы и метода эволюционной стратегии. Исследовано влияние основных параметров нечеткой системы и параметров метода эволюционной стратегии на процесс восстановления пропусков в многомерных данных.
Abstract:The article describes the features of fuzzy systems to solve the problem of restoring missing values in multi-variate data. It considers the Singleton fuzzy system and triangular membership function of the fuzzy linguistic terms. Gen-eral algorithm of an evolutionary strategy method to identify fuzzy system is provided. The article considers two types of this algorithm to assess the advantages and disadvantages of using. Principle of fuzzy system parameter identification based on the evolutionary strategy is described. The article also describes the requirements for the input data and the algorithm of re-storing missing values using fuzzy system based on the evolutionary strategy. There is the experimental efficiency evaluation of the presented algorithm of fuzzy system on the basis of the evolutionary strategy for the problem of recovering missing values. It is tested on a test set of oil properties data. Optimal parameters of fuzzy system and a method of the evolutionary strategy were selected for test data. The article investigates influence of the main parameters of the fuzzy system and metho d parameters of the evolutionary strategy on the recovery of multivariate data.
| Авторы: Перемитин Т.О. (pto@ipc.tsc.ru) - Институт химии нефти СО РАН (научный сотрудник), Томск, Россия, кандидат технических наук, Ященко И.Г. (pto@ipc.tsc.ru) - Институт химии нефти СО РАН (старший научный сотрудник), Томск, Россия, кандидат геолого-минералогических наук, Лучкова С.В. (pto@ipc.tsc.ru) - Институт химии нефти СО РАН (аспирант ), Томск, Россия | |
| Ключевые слова: эволюционная стратегия, параметрическая идентификация, функция принадлежности, база правил, синглтон, нечеткая система |
|
| Keywords: evolutionary strategy, parameter identification, fuzzy set function, rule base, singleton, fuzzy system |
|
| Количество просмотров: 10396 |
Версия для печати Выпуск в формате PDF (7.83Мб) Скачать обложку в формате PDF (1.01Мб) |
Многие исследования связаны со сбором и обработкой данных, представленных в виде таблиц наблюдений. Данные из этих таблиц используются как в различных задачах анализа, так и в задачах построения моделей прогноза. Однако часто по различным причинам некоторые значения в этих таблицах пропущены. Большинство алгоритмов не могут обрабатывать неполные данные, так как получаются неадекватные модели либо модель вообще невозможно построить. Поэтому процедура импутирования (восстановления пропущенных значений) является очень важным моментом в процессе обработке данных. Анализ преимуществ и недостатков известных алгоритмов для решения задачи восстановления пропусков в данных показал, что наиболее оптимальными являются методы, основанные на нечетких моделях. Основное преимущество таких моделей – снятие требований нормального распределения данных, их однородности и полноты. Эти требования к исходным данным должны выполняться для применения статистических методов восстановления пропущенных значений, что усложняет процесс предварительной подготовки выборки данных и замедляет анализ данных в целом. В настоящее время технология нечеткого моделирования является одной из развивающихся областей обработки данных. Применение нечетких систем в задаче импутирования вызывает ряд вопросов относительно параметров системы: как правильно выбрать параметры построения базы правил, функции принадлежности, метода эволюционной стратегии, оптимизирующей параметры нечеткой системы, и другие. Эти вопросы очень важны и являются объектом рассмотрения в данной работе. Задача параметрической идентификации нечеткой системы Нечеткое моделирование осуществляется посредством системы нечеткого вывода, которая выполняет следующие действия [1, 2]: – преобразование числовой информации в лингвистические переменные (формирование базы правил); – обработка лингвистической информации при выполнении логических операций нечеткой конъюнкции, импликации и агрегации правил; – формирование численных результатов. В работе используется нечеткая система типа синглтон, включающая n входных переменных (антецеденты) и m нечетких правил, каждое из которых имеет следующий вид: ЕСЛИ x1=A1j И x2=A2j И … И xn=Anj ТО rj, где rj – действительное число, rjÎÂ; Aij – лингвистический терм, описываемый функцией принадлежности. Нечеткая система осуществляет отображение F: Ân®Â. Заменяя оператор нечеткой конъюнкции произведением, а оператор агрегации нечетких правил сложением, получаем выходное значение F(x):
где x=[x1, …, xn]TÎÂn – значение i-го входа; mAij(xj) – функция принадлежности лингвистического терма Аij; rj – значение выходного значения (консеквента) в j-м правиле. Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили треугольная, трапецеидальная и гауссова функции принадлежности [1]. В работе для идентификации используется треугольная функция, которая определяется тройкой чисел (a, b, c). Ее значение в точке x вычисляется согласно выражению
При (b–a)=(c–b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a, b, c) [1]. Нечеткая система может быть представлена как y=f(x, θ), где θ=||θ1, …, θN|| – вектор параметров; N=k (число параметров, описывающих одну функцию принадлежности) * t (число термов, описывающих одну входную лингвистическую переменную, является задаваемым параметром нечеткой системы); y – скалярный выход системы. Например, если взять n входных переменных, определенных на t термах, и треугольную функцию принадлежности, то для модели типа синглтон вектор параметров будет следующим: qn=[a11b11c11…a1tb1tc1ta21b21c21…a2tb2tc2t…an1bn1cn1…antbntcnt], где aij, cij, bij – параметры треугольной функции принадлежности формулы (2) i-й лингвистической переменной j-го терма. Параметры, входящие в данный вектор, влияют на адекватность модели. Параметрическая идентификация рассматривается как процесс оптимизации нечеткой модели, который сводится к нахождению таких параметров нечеткой системы, чтобы ошибка вывода была минимальной. При этом оценивается качество нечеткого вывода по значениям ошибки вывода, разницы между значениями выходной переменной из таблицы наблюдений f(x) и значениями F(x), полученными нечеткой системой. Ошибку вывода необходимо минимизировать [1], для этого используются 1) среднеквадратичная ошибка (СКО):
2) средняя абсолютная ошибка (САО):
Задача параметрической идентификации заключается в определении параметров нечетких правил путем оптимизации работы нечеткой системы. Методы идентификации делятся на два типа: методы, использующие производные от параметров нечеткой системы (градиентный метод, метод наименьших квадратов и другие числовые методы [1]), и метаэвристические методы (генетический алгоритм [3], эволюционные стратегии [3–5], алгоритм муравьиной колонии [6]). В данной работе используется один из метаэвристических методов, а именно метод эволюционной стратегии. Эволюционная стратегия – это эвристический метод оптимизации в разделе эволюционных алгоритмов, основанный на адаптации и эволюции. Стратегия основана на механизмах естественного отбора и наследования. В ней используется принцип выживания наиболее приспособленных особей. Преимущества алгоритма перед другими методами оптимизации заключаются в параллельной обработке множества альтернативных решений [4, 5]. Алгоритм работает с популяцией особей (хромосом), каждая из которых представляет собой упорядоченный набор параметров задачи, подлежащих оптимизации. Основной характеристикой каждой особи является мера ее приспособленности. Общий алгоритм для эволюционной стратегии можно представить следующим набором шагов. Шаг 1. Генерируется начальная популяция P(0), устанавливается i=0. Шаг 2. Повторяется до тех пор, пока не выполнится условие остановки: – рассчитывается приспособленность каждой хромосомы из популяции P(i); – применяются генетические операторы, такие как скрещивание, мутация к родительской популяции, и производятся потомки; – отбираются хромосомы для следующего поколения P(i+1) из полученных потомков и, возможно, родителей. В настоящее время имеются разные варианты метода эволюционной стратегии [4, 5], чаще всего используют (m+l) – набор родителей и потомков и (m, l) – набор только потомков. В эволюционной стратегии (m+l) m родителей могут участвовать в воспроизводстве l потомков. Тогда (m+l)-поколение будет уменьшено до m потомков следующего поколения селекцией. Основным преимуществом данного подхода является использование произвольных адаптивных стратегических параметров. Однако есть и недостатки, а именно: поколение-родитель не даст поколения-потомка, лучшего, чем он сам. Для предотвра- щения этого недостатка был предложен метод (m, l)-стратегии, где селекция подчинена условию l>m. Предыдущие m-родители будут полностью заменены и не будут использоваться в следующем поколении. Недостатком этого алгоритма является то, что лучшие из m-родителей могут быть заменены худшими сгенерированными l-потомками и будут потеряны, а это в итоге может дать не самый корректный результат. При выборе разновидностей метода эволюционной стратегии необходимо учитывать это свойство следующего поколения [7]. Алгоритм для настройки параметров нечеткой системы модели типа синглтон методом эволюционной стратегии выглядит следующим образом. Вход: таблица наблюдений. Шаг 1. Загружаем таблицу наблюдений. Шаг 2. Задаем параметры нечеткой системы: а) количество термов; б) количество генерируемых хромосом для начальной популяции m; в) параметр функции приспособленности для построения базы правил. Шаг 3. Строим нечеткую систему: а) создаем базу правил для обучения на основе нечетких термов, равномерно распределенных по каждому входному параметру из таблицы наблюдения; б) формируем начальную популяцию хромосом Qn; в) находим консеквенты для каждого правила методом ближайшего из таблицы наблюдения для базы правил; г) рассчитываем адекватность полученной нечеткой системы. Шаг 4. Задаем параметры метода эволюционной стратегии: а) критерий остановки для идентификации параметров нечеткой системы (количество итераций); б) количество генерируемых хромосом (потомков) l из начальной популяции; в) параметры оператора скрещивания (количество точек скрещивания, алгоритм скрещивания); г) вероятность мутации; д) алгоритм селекции; е) свойства следующего поколения. Шаг 5. Запускаем идентификацию методом эволюционной стратегии. Шаг 6. Рассчитываем адекватность нечеткой системы. Если достигнуто условие выхода, переходим к шагу 7, иначе к шагу 5. Шаг 7. Вывод решения – «наилучшей» хромосомы. Выход: оптимизированная база правил; значение ошибки нечеткого вывода для «наилучшей» хромосомы. Рассмотрим особенности структуры таблиц наблюдения для использования предложенного метода в задаче импутирования (табл. 1). Таблица 1 Структура входной информации
Пусть X=(X1, X2, …, Xn) – вектор входных параметров; m – количество записей в таблице 1; Таким образом, задача восстановления пропусков в данных заключается в определении выходного значения для каждой записи с пропуском, причем в процессе восстановления участвуют только те записи, в которых нет пропущенных значений. Алгоритм восстановления пропущенных значений в общем виде можно представить как последовательность выполнения следующих шагов. Вход: таблица наблюдений с пропусками в записях. Шаг 1. Загружаем входные данные (таблицу наблюдений). Шаг 2. Задаем параметры нечеткой системы. Шаг 3. Выбираем параметры метода эволюционной стратегии. Шаг 4. Применяем эволюционную стратегию. Шаг 5. Отбираем лучшую хромосому. Шаг 6. Восстанавливаем пропуск на основе сформированной базы правил и лучшей хромосомы. Шаг 7. Проверяем условие остановки. Если достигнуто условие выхода, переходим к шагу 8, иначе к шагу 4. Шаг 8. Выводим решения. Выход: таблица наблюдений с восстановленными значениями. В качестве средства реализации программного комплекса были выбраны язык объектно-ориентированного программирования C# и среда разработки Microsoft Visual Studio 2010. В програм- мном средстве 17 вычислительных модулей, данные из которых можно в различном виде увидеть на 6 графических формах, 3 из которых отвечают за главные функции программного средства: – форма «Нечеткая система» отвечает за параметры нечеткой системы, за загрузку данных для идентификации нечеткой системы, построение нечеткой системы и нахождение оптимальных параметров, также из нее можно просмотреть результаты внутренних расчетов в разделе «просмотр»; – форма «Имитация восстановления» позволяет загрузить файл без пропусков, в котором будут искусственно создаваться пропуски в каждой записи и производиться восстановление; данная форма позволяет увидеть точность восстановления пропусков, так как нам заранее известно восстанавливаемое значение; – форма «Восстановление данных» работает с файлами, в которых есть пропуски; для каждой записи с пропуском осуществляется расчет пропущенного значения. Вычислительные эксперименты Для исследования влияния параметров нечеткой системы на точность восстановления пропущенных значений была подготовлена выборка многомерных данных из общей БД о свойствах нефтей Института химии нефти СО РАН, включающей описание более 20 000 образцов [8]. Многомерный массив представлен 141 записью (строки) и 5 характеристиками (столбцы). В полном массиве были специально сделаны пропуски. Такой подход позволяет рассчитать точность восстановления, так как можно сравнить полученный результат с искусственно пропущенными данными. Как описывалось выше, на процесс импутирования данных в первую очередь влияет параметр нечеткой системы, то есть количество лингвистических термов, от которых зависит база правил для обучения системы. По ряду тестов были получены результаты, представленные в таблице 2. Как видим, наилучшее начальное решение приходится на 6 термов, а 7 термов уже не приводят к улучшению результата. Такое поведение нечеткой системы объясняется тем, что для каждого интервала данных существует разумное количество термов, на которое следует разбивать входные интервалы переменных функцией принадлежности. Таблица 2 Исследование параметров нечеткой системы
Для наглядности приведем пример: пусть есть интервал данных от 0 до 1, тогда при равномерном разбиении на 5 и 7 термов получим результаты, представленные на рисунке. При 7 термах (см. рис. справа) видно, что «частокол» из треугольной функции принадлежности очень плотный, что в данном случае неоптимально. Это приведет к увеличению времени расчетов, так как возрастет количество правил, например, при 2 переменных по 5 термам база правил состоит из 25 правил, а при 5 переменных по 5 термам – из 3125 правил и т.д.
- алгоритм скрещивания (одноточечный, многоточечный или унифицированный); - вероятность мутации; - алгоритм селекции (турнирный отбор, случайный, рулеточный или элитарный); - соотношение начального количества хромосом m и генерируемых l; - свойство следующего поколения ((m+l) или (m, l)). В данном эксперименте использовались следующие условия: 6 термов с возможностью выхода за начальные границы. Количество итераций для расчетов равно 1 000. Как видно из таблицы 3, унифицированный алгоритм скрещивания дал лучший результат при случайном отборе, поэтому для рассмотрения остальных алгоритмов отбора использовался только унифицированный алгоритм. Наиболее точный результат в совокупности предоставил элитарный отбор, который рассмотрим более подробно. В таблице 4 представлены результаты влияния количества итераций на время вычисления. Таблица 3 Исследование параметров эволюционной стратегии
Таблица 4 Результаты влияния количества итераций на время вычисления
Из таблицы 4 видно, что увеличение количества итераций работы алгоритма уменьшает ошибку, но увеличивает время работы системы. На время работы системы также влияет количество термов: так, например, если при 6 термах время вычисления 500 итераций составляет около 48 минут, то при 7 термах уже около 90 минут. Установлено, что вероятность мутации не влияет на время вычисления, но влияет на точность работы. В таблице 5 представлен выбор вероятности мутации, для рассматриваемого примера наилучший результат дает вероятность мутации 0,15. Таблица 5 Результаты влияния вероятности мутации
В таблице 6 представлены данные анализа влияния соотношения начального количества хромосом m к генерируемым l и влияние свойства следующего поколения (m+l или (m, l)). Таблица 6 Влияние количества хромосом и свойства следующего поколения
Согласно исследованию, наименьшие ошибки расчетов получаются при комбинации (20+50) – эволюционной стратегии или (10, 30). Это подтверждает плюсы и минусы алгоритмов стратегий, описанных выше, и дает нам итоговые комбинации настроек. На следующем шаге проверяется влияние свойств функции принадлежности на точность восстановления пропущенного значения (табл. 7). Из таблицы 7 видно, что влияние свойств функции принадлежности значительно. Возрастание ошибки расчетов и времени вычисления можно объяснить тем, что комбинаций треугольников на ограниченном интервале меньше, а проверок их построения больше. Причем проверки построения имеют условия: разбиение термов должно покрывать весь заданный интервал, термы не должны перекрываться полностью и прочее. Следовательно, необходимо использовать алгоритм с разрешением выхода за начальные интервалы. Таблица 7 Влияние свойства функции принадлежности
Таким образом, установлено, что в алгоритме присутствует случайный компонент как в построении нечеткой системы, так и в ее настройке, поэтому имеем две итоговые комбинации, каждая из которых в конечном итоге может быть выигрышной (табл. 8). Таблица 8 Итоговые комбинации параметров
В заключение отметим, что в работе предложены алгоритм идентификации нечеткой системы на основе метода эволюционной стратегии для настройки параметров и алгоритм импутирования. На примере использования массива о свойствах вязких парафинистых нефтей были поставлены вычислительные эксперименты с искусственно пропущенными данными. Эксперименты показали, что для различных данных оптимальные параметры системы будут разными и в каждом случае их необходимо подбирать. Поэтому было показано, как следует выбирать параметры нечеткой системы и эволюционной стратегии. Дальнейшие исследования направлены на более детальный подход к обрабатываемым данным, например, возможность задавать количество термов для каждой переменной, что, возможно, сократит количество правил и снизит вычислительное время, следовательно, позволит обрабатывать одновременно выборки большего объема данных. Литература 1. Ходашинский И.А., Гнездилова В.Ю., Дудин П.А., Лавыгина А.В. Основанные на производных и метаэвристические методы идентификации параметров нечетких моделей // Идентификация систем и задачи управления-SICPRO'08: тр. VIII междунар. конф. М., 2009. С. 501–528. 2. Hoche S., Wrobel S. A Comparative Evaluation of Feature Set Evolution Strategies for Multirelational Boosting. Proc. 13th Int. Conf. on ILP, Szeged, Hungary, 2003, pp. 180–196. 3. Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. М.: Горячая линия, 2006. 383 с. 4. Schwefel H.P. Numerical Optimization of Computer Models. NY: John Wiley & Sons, 1981, 398 p. 5. Schwefel H.P. Evolution and Optimum Seeking. NY: John Wiley & Sons. 1995, 444 p. 6. Дудин П.А. Применение алгоритма муравьиной колонии для идентификации нечетких моделей // Студент и научно-технический прогресс. Информационные технологии: матер. XLV Междунар. науч. конф. Новосибирск: Изд-во НГУ, 2007. С. 188–189. 7. Лучкова С.О. Алгоритмы нечетких систем в задачах импутирования // Современные проблемы математики и механики: матер. III Всерос. молодеж. науч. конф. Томск, 2012. С. 329–334. 8. Козин Е.С., Полищук Ю.М., Ященко И.Г. База данных по физико-химическим свойствам нефтей // Нефть. Газ. Новации. 2011. № 3. С. 13–16. References 1. Hodashinskiy I.A., Gnezdilova V.Yu., Dudin P.A., Lavygina A.V. Based on derivative and metaheuristic methods of identification of fuzzy models. Trudy 8 mezhdunar. konf. “Identifikatsiya sistem i zadachi upravleniya” SICPRO'08 [Proc. of 8th int. conf. “System Identification and Control Problems”]. Moscow, 2009, pp. 501–528 (in Russ.). 2. Hoche S., Wrobel S. A Comparative evaluation of feature set evolution strategies for multirelational boosting. Proc. 13th int. conf. on ILP. Szeged, Hungary, 2003, pp. 180–196. 3. Rutkovskaya D., Pilinskiy M., Rutkovskiy L. Neyronnye seti, geneticheskie algoritmy i nechetkie sistemy [Neural networks, genetic algorithms and fuzzy systems]. Moscow, Goryachaya liniya Publ., 2006, 383 p. 4. Schwefel H.P. Numerical optimization of computer models. NY, John Wiley & Sons Publ., 1981, 398 p. 5. Schwefel H.P. Evolution and optimum seeking. NY, John Wiley & Sons Publ., 1995, 444 p. 6. Dudin P.A. Application of an ant colony algorithm for identification of fuzzy models. Materialy 45 Mezhdunar. nauch. konf. “Student i nauchno-tehnicheskij progress. Informatsionnye tekhnologii” [Proc. of 45th int. science conf. “A student and technological advances. Information technologies”]. Novosibirsk, Novosibirsk State Univ. Publ., 2007, pp. 188–189 (in Russ.). 7. Luchkova S.O. Mater. III Vseross. molodezh. nauch. konf. «Sovremennye problemy matematiki i mekhaniki» [Modern problems of mathematics and mechanics. Proc. of III All-Russian Youth Sc. Conf.]. Tomsk, 2012, pp. 329–334 (in Russ.). 8. Kozin E.S., Polishchuk Yu.M., Yashchenko I.G. Database with physical-chemical properties of oil. Neft. Gaz. Novatsii [OIL. GAZ. Novation]. 2011, no. 3, pp. 13–16 (in Russ.). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
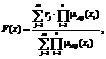 (1)
(1)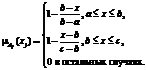 (2)
(2)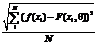 ; (3)
; (3)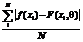 . (4)
. (4)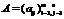 – матрица исходной информации. Исходная информация имеет пропуски, обозначенные в таблице 1 звездочками. Допускается по одному пропуску на запись, так как пропущенное значение будет выходным значением для данной записи.
– матрица исходной информации. Исходная информация имеет пропуски, обозначенные в таблице 1 звездочками. Допускается по одному пропуску на запись, так как пропущенное значение будет выходным значением для данной записи.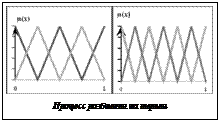 На процесс импутирования влияют параметры метода эволюционной стратегии, так как именно этим методом происходит настройка нечеткой системы или ее обучение. У эволюционной стратегии необходимо выбрать
На процесс импутирования влияют параметры метода эволюционной стратегии, так как именно этим методом происходит настройка нечеткой системы или ее обучение. У эволюционной стратегии необходимо выбрать| Постоянный адрес статьи: http://swsys.ru/index.php?id=3764&like=1&page=article |
Версия для печати Выпуск в формате PDF (7.83Мб) Скачать обложку в формате PDF (1.01Мб) |
| Статья опубликована в выпуске журнала № 1 за 2014 год. [ на стр. 86-92 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Инструментальная система для решения задач многокритериального выбора
- Демонстратор программной платформы для совместного использования алгоритмов теории свидетельств и нейронных сетей в нечетких системах
- F-Ranking: компьютерная система для ранжирования нечетких чисел
- Демонстратор программной платформы для настройки гиперпараметров нечеткой нейронной сети
- Программный комплекс для компьютерного моделирования процессов параметрической идентификации математических моделей конвективно-диффузионного переноса
Назад, к списку статей