Трехтактная кластеризация динамичных интернет-ресурсов с применением DOM-моделей
| Мороховец Ю.Е. (MorokhovetsYY@mpei.ru) - Национальный исследовательский университет «Московский энергетический институт» (доцент), Москва, Россия, кандидат технических наук, Зейн А.Н. (ZeynAN@mpei.ru) - Национальный исследовательский университет «Московский энергетический институт» (аспирант), Москва, Россия | |
| Ключевые слова: степень принадлежности, кластер, евклидово расстояние, характеристический вектор, dom-модель, динамический компонент, кластеризация, интернет-ресурс |
|
| Keywords: ownership level, cluster, euclidean distance, characteristic vector, dom, dynamic component, clusterization, internet resource |
|
|
|
|
Сайты или отдельные страницы сайтов, содержащие текстовую информацию, представляющую интерес для интернет-пользователей (ИП), называются интернет-ресурсами (ИР). ИР индексируются с помощью специальных методов, и ссылки на них выдаются как результат поисковых запросов ИП. К сожалению, большинство найденных ИР часто не содержат информацию, отвечающую поисковым интересам пользователей. Одним из подходов к решению этой проблемы является классификация ИР с применением методов кластерного анализа [1]. В последнее время произошли значительные изменения в средствах реализации ИР: стали применяться языковые кодировки содержимого текста (Unicode Transformation Format UTF-8 и UTF-16, Windows 1250 и 1251 и др.), Java-скрипты (JavaScript – JS), использующие технологию асинхронных интерактивных интерфейсов (Asynchronous JavaScript and XML – AJAX), и, конечно, каскадные таблицы стилей (Cascading Style Sheets – CSS). Внедрение современных технологий сделало ИР более адаптивными и интерактивными, а значит, и более динамичными. Главная страница любого новостного сайта (например news.mail.ru) является ярким примером динамичного ИР. В разные моменты времени большая часть компонентов DOM-модели ИР [2] меняет свое текстовое содержание. HTML-теги могут представлять всего лишь каркасную основу для браузеров, так как их текстовое содержание инкапсулировано в DOM-модели и может динамически изменяться с каждой новой загрузкой в браузер или после наступления определенных событий. С точки зрения кластерного анализа появление динамических компонентов ИР – JS-скриптов и CSS – привело к серьезным изменениям в поведении кластерных структур ИР. Для статического HTML-кода достаточно единожды провести кластеризацию заданного множества ресурсов, и полученная структура долгое время останется неизменной. HTML-страницы, содержащие исключительно статические компоненты, легко поддаются классификации методом частоты слов (Term Frequency – TF) [3], так как они могут быть рассмотрены как обычные текстовые документы [4]. Для динамичных ИР все зависит от текстового содержания динамических компонентов DOM-модели – кластеры перестают быть неподвижными. Они могут меняться как качественно (перемещение центров кластеров), так и количественно (изменение числа и размеров кластеров). Как можно добиться хорошей степени кластеризации ИР при наличии динамических компонентов? Какие меры необходимо принять для снижения (или устранения) динамических эффектов в кластерной структуре при кластеризации ИР? Данная статья посвящена решению задачи кластеризации ИР с динамическими компонентами, предполагающей использование особенностей их DOM-моделей. Предлагаемая методика в отличие от представленной в [5, 6] позволяет автомати- чески определять и устранять влияние динами- ческих компонентов ИР на их кластерную структуру. Экспериментальное исследование динамики кластерных структур Исследование динамики кластерных структур основывается на наблюдении за ИР. Пусть T = {t0, t1, …, tk, …} – упорядоченное по возрастанию множество дискретных моментов времени. Наблюдение за ИР начинается в момент времени t0, а в моменты времени tk производится обработка результатов наблюдения, полученных в интервалах (tk-1, tk), k ³ 1. Наблюдение осуществляется за ИР, образующими множество R = {r1, …, ri, …, rnof(R)}, где nof – функция, возвращающая в качестве значения число элементов в конечном множестве-аргументе. Рассмотрим произвольный момент времени tk, k ³ 1. В ходе наблюдения за ИР ri Î R в момент времени tk формируется словарь терминов ресурса Vri(tk), включающий nof(Vri(tk)) терминов. Этот словарь по определенным правилам получается из словаря Vri(tk-1) и новых уникальных терминов – результатов наблюдения за ИР ri в интервале (tk-1, tk). Из словарей терминов ресурсов Vri(tk) формируется такой глобальный словарь терминов V(tk) = ={v1(tk), …, vj(tk), …, Следует отметить, что nof(Vri(t0)) = 0 и для любого tk Î T nof(Vri(tk)) ³ nof(Vri(tk–1)). Аналогично для глобального словаря терминов – nof(V(t0)) = 0 и для любого tk Î T nof(V(tk)) ³ nof(V(tk–1)). В момент времени tk для каждого ИР ri Î R строится характеристический вектор wi(tk) = = {wi,1(tk), …, wi,j(tk), …, На основе характеристических векторов ресурсов из R с помощью какого-либо известного алгоритма кластеризации строится кластерная структура ИР, соответствующая моменту времени tk – C(tk) = {c1(tk), …, cm(tk), …, Кластерную структуру C(tk) будем называть стабильной, если для любого момента времени tk* > tk V(tk*) = V(tk) притом, что nof(C(tk*)) = =nof(C(tk)), и для любого кластера cm(tk*)Î C(tk*) выполняются следующие соотношения: Rm(tk*) = = Rm(tk), d(zm(tk*), zm(tk)) £ e, где d(zm(tk*), zm(tk)) – евклидово расстояние между центрами m-го кластера в моменты времени tk* и tk, а e – произвольное число, намного меньшее радиуса кластера в момент времени tk. Множество ИР R назовем статичным, если в процессе наблюдения за ним в некий момент времени tk Î T будет построена стабильная кластерная структура C(tk). В противном случае множество R будем называть динамичным множеством ИР. Интерес представляют последствия расширения исходного статичного множества наблюдаемых ИР за счет добавления к ним нового, в общем случае динамичного ИР, то есть вызовет ли это нестабильность кластерной структуры ИР или структура останется стабильной, а новый ресурс будет добавлен в один из имеющихся кластеров. Пусть R – стабильное множество ИР, наблюдаемых до момента времени t0 включительно, r Ï R – добавляемый ИР. В произвольный момент времени tk Î T, k ³ 1, указанный ИР можно представить характеристическим вектором w(tk) =(w1(tk), …, wj(tk), …, где wj(tk) – вес j-го поискового термина из глобального словаря терминов V(tk), равный числу вхождений этого термина в текст ресурса r в течение временного интервала (tk-1, tk); nof(V(tk)) – размер характеристического вектора ИР, равный числу слов в глобальном словаре терминов в момент времени tk. Числовые координаты wj(tk), 1 £ j £ nof(V(tk)), расположены в характеристическом векторе в том же порядке, что и термины в словаре V(tk). Переход от вербального представления результатов к числовому происходит за счет позиционного кодирования терминов и подсчета числа их вхождений в текст ИР. Для оценки стабильности кластерной структуры используем следующие метрики. 1. Степень принадлежности bm(tk) ресурса r к кластеру cm(tk) Î C(tk) в произвольный момент времени tk:
где nof(C(tk)) – число кластеров в кластерной структуре C(tk); 2. Приращение кардинальности характеристического вектора ИР: Dnof(V(tk)) = nof(V(tk)) – nof(V(tk–1)), где nof(V(tk)) ³ nof(V(tk–1)) для двух непосредственно следующих друг за другом моментов дискретного времени. Разработанная система анализа тестового содержания интернет-ресурсов показала, что многократный анализ содержания одного и того же ИР в разные моменты времени может привести к формированию совершенно разных характеристических векторов. Сформированные в разные моменты времени tk¢ ¹ tk² характеристические векторы w(tk¢) и w(tk²) могут отличаться как качественно (изменяется число вхождений терминов в текст), так и количественно (изменяется значение кардинальности векторов характеристик). Результаты анализа текстового содержания одной из новостных страниц сайта news.mail.ru приведены в таблице 1. Здесь в заголовках столбцов стоят термины из глобального словаря, в строках – моменты дискретного времени tk, а в ячейках – число вхождений терминов в текст наблюдаемого ИР wj(tk). Параметр nof(V(tk)) указывает размер глобального словаря терминов или, что то же самое, кардинальность характеристического вектора w(tk). Данные таблицы 1 были использованы для расчета частоты употребления терминов в тексте ИР. Результаты зафиксированы в таблице 2. В ее ячейках представлены значения частоты употребления терминов fj(tk) в соответствующие моменты времени. Через nof(Vr(tk)) обозначено общее число терминов в тексте ИР.
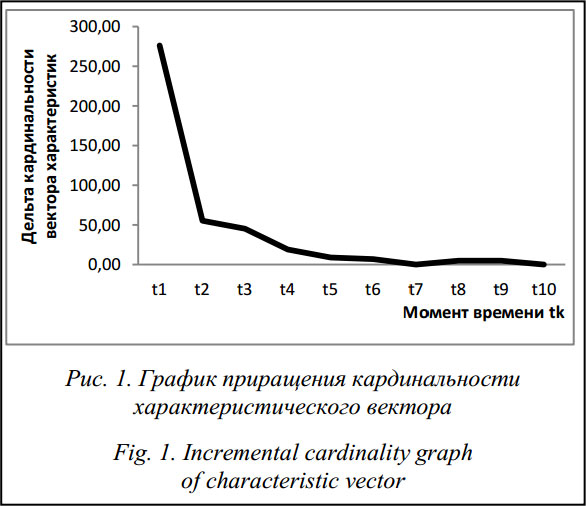
Анализ данных, приведенных в таблицах 1 и 2, позволяет сделать следующие выводы. 1. С увеличением числа наблюдений кардинальность вектора w(tk) возрастает и стремится к некому предельному значению. Использование классических методов кластеризации для динамических векторов w(tk) приводит к снижению качества результатов кластерного анализа, так как с каждым наблюдением появляются лишние координаты – увеличивается размерность пространства, в котором проводится эксперимент, усложняются расчеты. 2. Снижается значение частоты употребления слов, так как fj(tk) обратно пропорционально общему числу терминов nof(Vr(tk)), содержащему как статические термины основного теста ИР, так и динамические. 3. Формируются три множества терминов, из которых состоит исследуемый объект: - множество терминов с постоянным числом вхождений VA = {vj | wj(tk) = const и wj(tk) ¹ 0 для любого момента времени tk Î T}; термины, принадлежащие к этому множеству, можно отнести к статическим компонентам ИР; - множество терминов с переменным числом вхождений, появившихся хотя бы один раз, VB = = {vj | wj(tk) ¹ const и wj ¹ 0 для любого момента времени tk Î T}; термины, принадлежащие к этому множеству, относятся как к статическим, так и к динамическим компонентам ИР; - множество терминов, имеющих хотя бы одно нулевое число вхождений, VC = {vj | существует tk Î T, для которого wj = 0}; термины, принадлежащие к этому множеству, относятся к динамическим компонентам ИР. Указанные множества позволяют определить статические и динамические компоненты ИР. После формирования множеств VA, VB и VC можно вычислить иерархический путь этих компонентов в DOM-модели, а затем автоматически исключить их из всех страниц исследуемого ИР. По данным таблицы 1 (столбец nof(V(tk))) можно построить график приращения кардинальности характеристического вектора Dnof(V(tk)), показанный на рисунке 1.
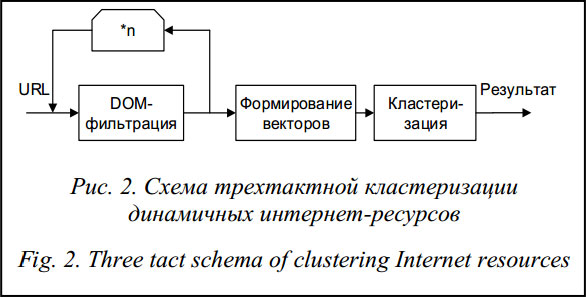
Из рисунка 1 видно, что система достигает стабильного состояния за конечное число наблюдений N » 5. Эта величина может быть использована в качестве признака насыщения глобального словаря терминов. Для разных страниц одного и того же сайта N можно считать константой. Варьирование элементов и кардинальностей характеристических векторов напрямую влияет на степень принадлежности исследуемых объектов к кластерам [4]. Если поставить задачу определения принадлежности исследуемого объекта в разные моменты времени tk Î T, можно будет наблюдать за его перемещением между сформированными кластерами: в целом меняется кластерная структура, а в частности – принадлежность исследуемых объектов к конкретным кластерам. Из этого следует, что классические методы кластеризации текстовых документов [4] нельзя применить к динамичным объектам, поэтому необходим новый, более совершенный механизм кластеризации ИР с динамическими компонентами. Метод трехтактной кластеризации динамических ИР с обратной связью Для кластеризации ИР с динамическими компонентами предлагается использовать метод трехтактной кластеризации ИР, схема реализации которого показана на рисунке 2.
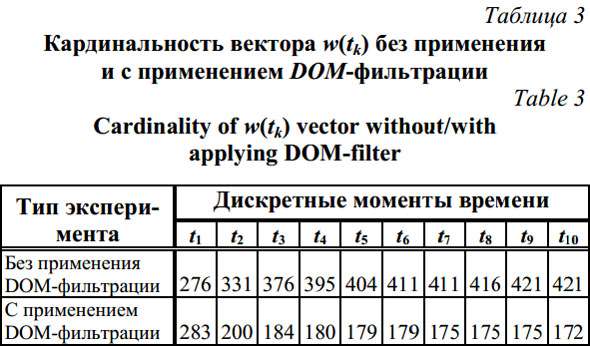
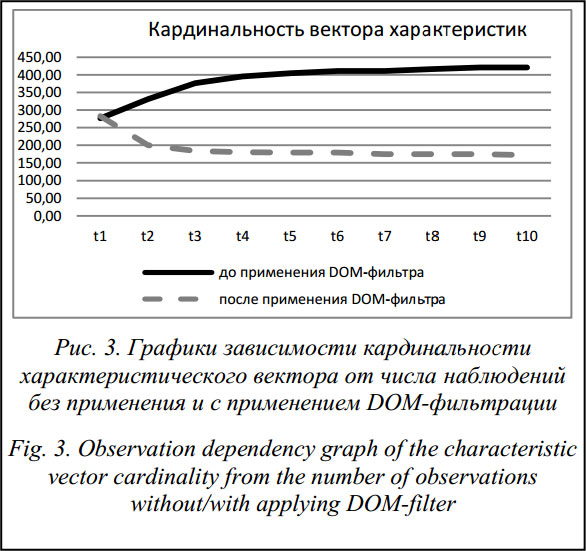
На вход схемы поступают URL-адреса интернет-страниц – объектов кластеризации. Задачей первого блока является DOM-фильтрация: выявление компонентов DOM-модели страницы с динамическими признаками и их удаление. Второй блок отвечает за формирование характеристического вектора на основе анализа исключительно статических компонентов DOM-модели интернет-страницы. Третий блок осуществляет непосредственно кластеризацию объекта. Предложенная схема кластеризации имеет ряд преимуществ по сравнению с классическими методами кластеризации [4]. Во-первых, снижаются вычислительные затраты, что связано с уменьшением размеров характеристических векторов w(tk). Во-вторых, повышается точность результата кластеризации, так как сразу выделяются «мусорные» динамические компоненты страниц, которые перестают участвовать в кластеризации. Снижается уровень шума, повышается стабильность кластерной структуры. При первом поступлении в систему, в момент времени t1, исследуемый ИР «расщепляется» на отдельные DOM-компоненты и формируется характеристический вектор w(t1). При повторном наблюдении, в момент времени t2, после формирования вектора w(t2) и его сравнения с вектором w(t1) выделяются основные динамические компоненты. Например, для новостных страниц сайта news.mail.ru после повторного наблюдения выделяются более 60 % всех динамических компонентов, а после третьего наблюдения процент их обнаружения вырастает до 80 %. Для более сложных сайтов число наблюдений растет (например, для сайта rbc.ru число необходимых наблюдений может достичь 10 и более итераций). Учитывая сказанное, в блоке фильтрации предусмотрена обратная связь, которая срабатывает до тех пор, пока приращение кардинальности характеристического вектора Dnof(V(tk)) не становится близким к нулю. Прогонка интернет-страниц через DOM-фильтр, анализ их содержания без и с его применением позволили получить зависимости для характеристического вектора ИР (табл. 3, рис. 3).
Из рисунка 3 следует, что без применения DOM-фильтрации число элементов в характеристическом векторе возрастает по мере увеличения числа наблюдений, а в случае его применения оно уменьшается.
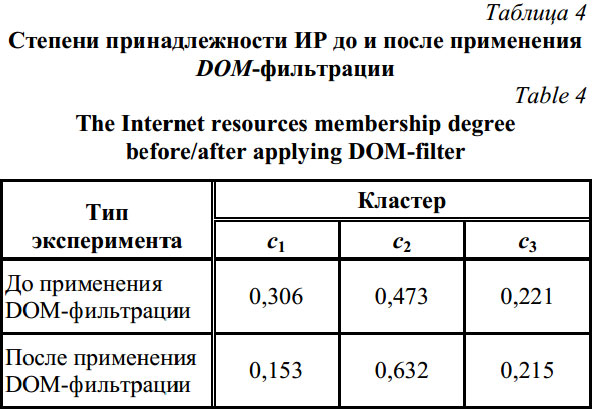
Исследуемый ИР покидает блок DOM-фильтрации, обладая высокой степенью статичности, и попадает на следующий блок, задача которого – формирование вектора w(tk). На вход блока формирования поступает характеристический вектор ИР с минимальным числом динамических компонентов. Результаты сравнения векторов, построенных без применения и с применением DOM-фильтрации, могут сильно отличаться в зависимости от степени статичности ИР (см. табл. 3). На последнем этапе исследуемый объект попадает в блок кластеризации, функция которого состоит в кластерном анализе и формировании кластерной структуры поступающих объектов одним из известных методов. В эксперименте был использован итерационный алгоритм кластеризации с расчетом центров кластеров – метод k-средних [7, 8]. Применение DOM-фильтрации для кластеризации ИР с динамическими компонентами улучшает значения их степеней принадлежности к релевантным кластерам (табл. 4).
Применение трехтактной схемы кластеризации приближает исследуемый ИР к кластеру c2, повышает значение степени принадлежности ресурса к релевантному кластеру примерно на 25 %. Степень принадлежности ресурса к другим, менее релевантным кластерам кластерной структуры уменьшается. В заключение можно сделать следующие выводы. Экспериментальный анализ динамичных ИР, в качестве которых выступили новостные сайты, выявил низкую степень их принадлежности к кластерам в соответствующих кластерных структурах, что делает эти кластерные структуры нестабильными. Причина в наличии интерактивных динамических компонентов ИР, которые периодически обновляют свое содержание. Для увеличения стабильности кластерной структуры предложено использовать DOM-фильтр, повышающий степень принадлежности ИР к кластерам и снижающий кардинальность их характеристических векторов. Основанный на DOM-фильтрации метод трехтактной кластеризации ИР обеспечивает стабильность формируемых кластерных структур, его можно применять для анализа любых современных ИР. Литература 1. Разделяй и властвуй: кластерные поисковики // UPGRADE твой компьютерный еженедельник. 2008. URL: http://www.upweek.ru/razdelyaj-i-vlastvuj-klasternye-poiskoviki.html (дата обращения: 10.02.2014). 2. XML Document Object Model (DOM) // Microsoft developer network: библиотека разработчика. URL: http://msdn.microsoft.com/ru-ru/library/hf9hbf87(v=vs.110).aspx (дата обращения: 10.02.2014). 3. Robertson S. Understanding Inverse Document Frequency: on theoretical arguments for IDF // Journ. of Documentation, 2004, vol. 60, no. 5, pp. 503–520. 4. Гулин В.В. Сравнительный анализ методов класси- фикации текстовых документов // Вестн. МЭИ. 2011. № 6. С. 100–108. 5. Айвазян С.А., Бухштабер В.М., Енюков Е.С., Мешалкин Л.Д. Прикладная статистика. М.: Финансы и статистика, 1989. 607 с. 6. Chakarbarti S. Mining the web: discovering knowledge from hypertext data. San Francisco: Morgan Kaufmann Publishers, 2003. 344 c. 7. Гимаров В.А., Дли М.И., Битюцкий С.Я. Задачи нестандартной кластеризации состояния нефтехимического оборудования // Нефтегазовое дело. 2004. № 2. С. 203–207. 8. Чубукова И.А. Data Mining: учеб. пособие. М.: Инт-УИТ: БИНОМ. Лаборатория знаний, 2006. 382 с. References 1. Divide and rule: cluster search engines. UPGRADE: web journ. 2008. Available at: http://www.upweek.ru/razdelyaj-i-vlastvuj-klasternye-poiskoviki.html (accessed February 10, 2014). 2. XML Document Object Model (DOM). Microsoft developer network: biblioteka razrabotchika [Microsoft developer network: developer library]. Available at: http://msdn.microsoft.com/ ru-ru/library/hf9hbf87(v=vs.110).aspx (accessed February 10, 2014). 3. Robertson S. Understanding inverse document frequency: On theoretical arguments for IDF. Journ. of Documentation. 2004, vol. 60, no. 5, pp. 503–520. 4. Gulin V.V. A comparative analysis of text documents classification methods. Vestnik MEI [Bulletin of MEI]. MEI Publ. house, 2011, no. 6, pp. 100–108 (in Russ.). 5. Ayvazyan S.A., Bukhshtaber V.M., Enyukov E.S., Meshalkin L.D. Prikladnaya statistika [Applied statistics]. Moscow, Finansy i statistika Publ., 1989, 607 p. 6. Chakarbarti S. Mining the web: discovering knowledge from hypertext data. San Francisco, Morgan Kaufmann Publ., 2003, 344 p. 7. Gimarov V.A., Dli M.I., Bityutskiy S.Ya. Transient clustering tasks for petrochemical equipment state. Neftegazovoe delo [Oil and Gas Business]. 2004, no. 2, pp. 203–207. 8. Chubukova I.A. Data Mining. Study guide. Moscow, INTUIT, Binom, Laboratoriya znanniy Publ., 2006, 382 p. |
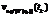 }, что V(tk) = =
}, что V(tk) = =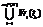 .
. }, где wi,j(tk) – число вхождений термина vj(tk) Î V(tk) в текстовый контент ИР ri в интервале наблюдения (tk-1, tk).
}, где wi,j(tk) – число вхождений термина vj(tk) Î V(tk) в текстовый контент ИР ri в интервале наблюдения (tk-1, tk).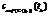 }. Кластер cm(tk) может быть представлен парой cm(tk) = = áRm(tk), zm(tk)ñ, где Rm(tk) Í R – множество ИР, отнесенных к m-му кластеру в момент времени tk, zm(tk) – центр кластера cm(tk).
}. Кластер cm(tk) может быть представлен парой cm(tk) = = áRm(tk), zm(tk)ñ, где Rm(tk) Í R – множество ИР, отнесенных к m-му кластеру в момент времени tk, zm(tk) – центр кластера cm(tk).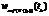 ),
),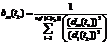 и
и 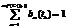 ,
,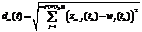 – евклидово расстояние между ресурсом r и центром m-го кластера кластерной структуры ИР.
– евклидово расстояние между ресурсом r и центром m-го кластера кластерной структуры ИР.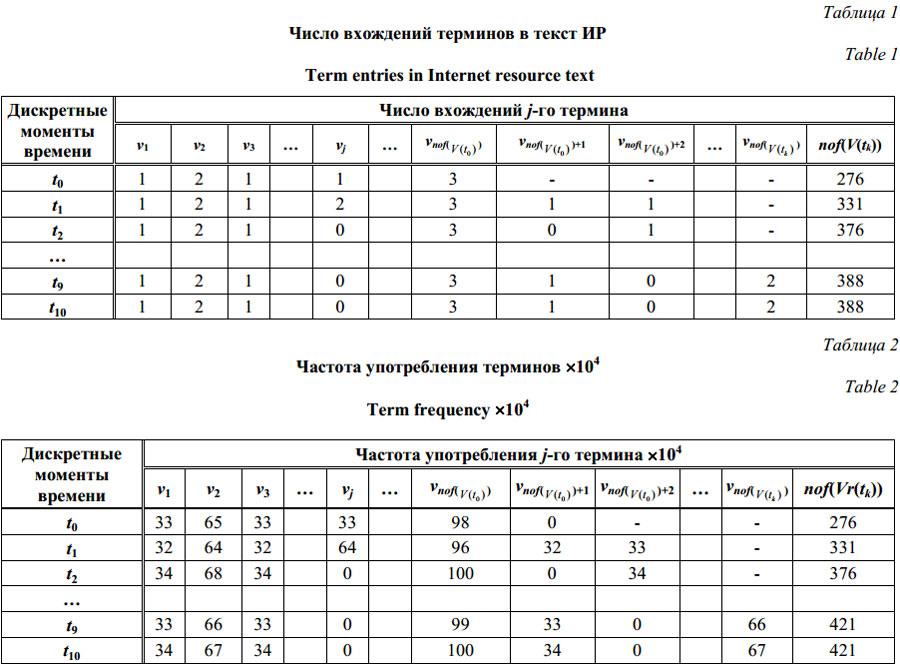
http://swsys.ru/index.php?id=3861&lang=%E2%8C%A9%3Den&like=1&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Метод автоматического синтеза нечетких регуляторов
- Кластеризация документов интеллектуального проектного репозитария на основе FCM-метода
- Применение технологии CUDA для обучения нейронной сети Кохонена
- Информационно-коммуникационная технология комплексного управления деятельностью студентов
- Комплекс проблемно-ориентированных программ анализа микрофотоизображений текстуры нанокомпозитов «FRA_VA_T»