Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Исследование производительности ряда итерационных методов решения системы линейных алгебраических уравнений в упругопластической задаче
Аннотация:Упругопластическая задача с большими пластическими деформациями физически и геометрически существенно нелинейная. Большая часть времени ее решения методом конечных элементов затрачивается на решение системы линейных алгебраических уравнений (СЛАУ) относительно искомого вектора обобщенной скорости в узлах конечно-элементной сетки. Для сокращения времени расчетов необходимо использовать параллельные вычисления, в частности, на кластерных системах. Матрица системы несимметричная, имеет большую размерность, является ленточной и разреженной внутри ленты. Использование прямых методов для решения СЛАУ приводит к образованию заполнения внутри ленты и большим затратам как памяти, так и времени счета. На базе решения тестовой задачи сжатия параллелепипеда плоскими плитами выполнен вычислительный эксперимент на кластере «Уран» Института математики и механики УрО РАН с целью анализа производительности параллельных итерационных методов релак-сации, BiCGStab и GMRES решения СЛАУ в упругопластической задаче с большими пластическими деформациями. Рассмотрена эффективность применения параллельных предобуславливателей ILU, ILUT, ILUC, SAINV, SAAMG в методе BiCGStab. Выполнена оценка погрешности времени решения СЛАУ, вносимой стохастичностью процесса передачи данных по сети кластерной системы. Результаты вычислительного эксперимента показали, что метод релаксаций по сравнению с методами BiCGStab и GMRES требует значительно большего времени на решение СЛАУ, поэтому является неэффективным. Метод GMRES затрачивает наименьшее время на решение СЛАУ на небольшом количестве процессов, однако метод BiCGStab обладает лучшим ускорением, хорошей масштабируемостью и при использовании большого количества процессоров обеспечивает наименьшее время на решение СЛАУ. Случайное отклонение времени решения СЛАУ, вызванное стохастической задержкой сети, не превышает 5 % от среднего. Предобуславливатель ILUC является наиболее эффективным из рассмотренных по времени выполнения, однако предобуславливатель SAINV требует наименьшего количества итераций решения СЛАУ методом BiCGStab.
Abstract:An elastoplastic problem with large plastic deformations is substantially non-linear both geometrically and physically. Most of the finite element solution time is being spent solving linear system in order to find generalized speed vector in the FE grid nodes. To decrease solution time it is crucial to use parallel computations, especially cluster computers. Arising matrix is non-symmetric and has large dimension banded and sparse within band. Direct solvers create fill-in within a band and therefore induce heavy costs both in memory and computation time. We performed a computational experiment based on the test problem of parallelepiped compression with plates on “Uran” cluster located in Institute of Mathematics and Mechanics UB RAS in order to analyze the performance of SOR, BiCGStab and GMRES solvers. We estimated linear solver computation time variance that is induced by random latencies in data transfer within the cluster system. Experiment results showed that SOR requires more time than BiCGStab and GMRES thus is inefficient. GMRES is the fastest on a small nu m-ber of processors. However BiCGStab is more scalable and requires less time than GMRES when using large number of pro-cessors. Solve time deviation does not exceed 5 % from the average. An ILUC preconditioner is the most efficient one execu-tion time-wise, however a SAINV preconditioner requires the least number of BiCGStab iterations.
| Авторы: Толмачев А.В. (tolmachev.arseny@gmail.com) - Институт машиноведения УрО РАН (аспирант), г. Екатеринбург, Россия, Коновалов А.В. (avk@imach.uran.ru) - Институт машиноведения УрО РАН, г. Екатеринбург (профессор, зав. лабораторией), г. Екатеринбург, Россия, доктор технических наук, Партин А.С. (dmitriy-v-k@yandex.ru) - Институт машиноведения УРО РАН, г. Екатеринбург (старший научный сотрудник), Екатеринбург, Россия, кандидат технических наук | |
| Ключевые слова: упругопластическая задача, метод конечных элементов, итерационные параллельные методы решения слау |
|
| Keywords: elastic-plastic problem, finite element method, parallel iterative linear solvers |
|
| Количество просмотров: 11122 |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
Упругопластическая задача с большими пластическими деформациями физически и геометрически существенно нелинейная [1] и требует большого количества времени для решения методом конечных элементов на персональном компьютере. Для сокращения времени расчетов необходимо использовать параллельные вычисления, в частности, на кластерных системах.
Решение упругопластической задачи методом конечных элементов осуществляется в условиях пошагового нагружения и на каждом таком шаге состоит из трех основных этапов: 1) расчет локальных матриц жесткости для конечных элементов и формирование глобальной матрицы жесткости A и вектора b правой части системы линейных алгебраических уравнений (СЛАУ) Ax = b относительно искомого вектора обобщенной скорости в узлах конечно-элементной сетки; 2) решение СЛАУ; 3) вычисление напряженно-деформированного состояния конечных элементов в конце шага нагружения. На каждом шаге нагружения этап 1 выполняется один раз, а этапы 2 и 3 – от десяти до пятнадцати раз для удовлетворения итерационно с приемлемой точностью условию пластичности Мизеса в конце шага нагружения. При этом матрица системы уравнений остается постоянной, изменяется только ее правая часть. Производительность различных параллельных прямых методов решения СЛАУ в упругопластической задаче рассматривалась в работах [2–4]. Матрица A несимметричная, имеет большую размерность, является ленточной и разреженной внутри ленты. Использование прямых методов для решения СЛАУ приводит к образованию заполнения внутри ленты и к большим затратам как памяти, так и времени счета. Поэтому целесообразно использовать итерационные алгоритмы решения СЛАУ. Исследования эффективности различных параллельных итерационных алгоритмов решения СЛАУ проводились применительно к различным предметным областям. В работе [5] при решении задач электромагнетизма рассматривалась эффективность методов подпространств Крылова с аддитивным методом Шварца в качестве предобуславливателя. В [6] приводятся результаты решения задач гидродинамики, при этом применялся алгоритм Flexible GMRES с использованием аддитивного метода Шварца для выделения подобластей и предобуславливания. В работе [7] анализируется решение задачи Пуассона методом конечных разностей на трех различных вычислительных системах. Для решения СЛАУ использовался метод BiCGStab с алгебраическим многосеточным предобуславливателем. В работе [8] приведены результаты решения упругой задачи сжатия пружины на графических процессорах при решении системы линейных уравнений методом сопряженных градиентов. Для выделения независимых областей использовался метод дополнения Шура. Поскольку существует большое количество параллельных итерационных методов решения СЛАУ с различными предобуславливателями на кластерных системах, встает вопрос о выборе метода и предобуславливателя для решения класса задач, в частности упругопластических, который дает наибольшее ускорение и обладает наилучшей масштабируемостью. Выполненный авторами литературный обзор показал отсутствие исследований, содержащих сравнительный анализ производительности разных итерационных алгоритмов и предобуславливателей применительно к классу упругопластических задач. Целью данной работы являются исследование и сравнительный анализ эффективности итерационных параллельных алгоритмов метода релаксации [9], стабилизированного метода бисопряженных градиентов (BiCGStab) [10] и обобщенного метода минимальных невязок (GMRES) [11] для решения СЛАУ в упругопластических задачах на кластерной системе. Ранее эффективность метода релаксации исследовалась в работе [12], однако там рассматривались матрицы системы малой размерности в двухмерной упругопластической задаче. Тестовая задача сжатия параллелепипеда плоскими плитами В качестве тестовой рассматривается трехмерная задача сжатия параллелепипеда плоскими плитами из упругопластического изотропного и изотропно-упрочняемого материала с полученными в работе [13] определяющими соотношениями, удовлетворяющими закону Гука, ассоциированному закону пластического течения и условию текучести Мизеса с функцией текучести s = 400(1+50ep)0,28, где s – напряжение текучести, а ep – степень пластической деформации. Решение основывается на принципе виртуальной мощности в скоростной форме [1]. На контакте с плитами принято условие прилипания металла к плитам. Нагрузка в виде перемещения плиты прикладывается малыми шагами Dh. Шаг Dh выбран так, чтобы отношение Dh/h (h – текущая высота параллелепипеда) не превышало предела упругости по деформации, в нашем случае 0,002, что обеспечивает устойчивость вычислительной процедуры. На каждом шаге нагрузки задача рассматривается как квазистатическая, а вариационное равенство принципа виртуальной мощности в скоростной форме с помощью конечно-элементной аппроксимации сводится к СЛАУ. Использованные методы Формы хранения матрицы системы. При формировании матрицы A использовалась координатная форма хранения [9] с хранением троек из номеров строк, номеров столбцов и элементов матрицы в красно-коричневом дереве [14]. Для выполнения вычислений над матрицей она переводится в сжатую по строкам форму [9]. Использование красно-коричневого дерева позволяет выполнить преобразование из координатной в сжатую форму без сортировок за единственный обход дерева. Метод релаксации является одним из базовых итерационных методов линейной алгебры. Он основывается на методе Гаусса–Зейделя [9], в который добавлен коэффициент релаксации 0 Метод BiCGStab является вариантом метода сопряженных градиентов для несимметричных матриц. Он относится к семейству методов, основанных на подпространствах Крылова. Для уменьшения количества итераций, необходимых для достижения сходимости метода до заданной точности, использовался вариант метода с предобуславливателем [11]. Обобщенный метод минимальных невязок также относится к семейству методов, основанных на подпространствах Крылова. Его подробное описание дано в работе [11]. Предобуславливатели. Предобуславливателем называется матрица M, такая, что матрица M–1A имеет лучшую обусловленность, чем матрица A. По уменьшению количества итераций методов решения СЛАУ можно судить об эффективности различных предобуславливателей. В работе рассмотрены следующие пять предобуславливателей. · Неполное LU-разложение (ILU) [11]. Матрица A представляется в виде · Модификация метода неполного LU-разложения с отбрасыванием (ILU with threshold – ILUT) [11]. В данном предобуславливателе применяется другой порядок метода исключения Гаусса при построении неполного разложения. Производится формирование одной строки матрицы, после чего отбрасываются все элементы, кроме m наибольших. Это позволяет сохранять разреженность в матрице, получая некоторую гибкость при формировании разложения. · Модификация метода неполного LU-разложения Crout ILU (ILUC) [15]. Этот предобуславливатель по структуре похож на предобуславливатель ILUT, в нем также происходит построение строки и столбца матрицы с последующим отбрасыванием элементов аналогично предобуславливателю ILUT. Отличие алгоритма заключается в другой последовательности построения разложения. · Стабилизированный метод нахождения приближенной обратной матрицы (SAINV) [16]. В общем случае этот алгоритм гарантированно работает лишь для симметричных положительно определенных матриц, однако расхождения итерационного алгоритма в упругопластической задаче не наблюдалось. · Алгебраический многосеточный метод со сглаженной агрегацией (Smoothed Aggregation algebraic multigrid method – SAAMG) [17]. Для некоторых задач многосеточные методы являются эффективными решателями, поэтому на их основе были разработаны предобуславливатели для итерационных методов решения СЛАУ. Результаты вычислительных экспериментов Эффективность итерационных методов для решения упругопластической задачи определялась по результатам вычислительного эксперимента по сжатию параллелепипеда плоскими плитами. Вычислительные эксперименты проводились на кластере «Уран» Института математики и механики имени Н.Н. Красовского УрО РАН [18]. Он состоит из 208 вычислительных узлов, установленных в модулях с высокой плотностью упаковки. Каждый вычислительный узел оснащен двумя процессорами Intel Quad-Core Xeon, работающими на частоте 3,00 ГГц, и 16/32 Гбайта оперативной памяти. В общей сложности пользователям доступны 1 664 вычислительных ядра и 3 584 Гбайта оперативной памяти. Для передачи данных между вычислительными узлами используется высокоскоростная сеть Infiniband с пропускной способностью 20 Гбит/сек. В качестве реализаций итерационных методов решения СЛАУ была использована библиотека lis [19, 20]. Решение СЛАУ производилось до удовлетворения условия остановки ||r||/||b||<109, где r – вектор невязки; b – вектор правой части СЛАУ; ||×|| – евклидова норма вектора. Характеристики СЛАУ. Для упрощения анализа эффективности рассматриваемых методов решения СЛАУ использовалась регулярная сетка при разбиении параллелепипеда на конечные элементы. При этом получается ленточная матрица системы A с пятью ненулевыми лентами. Параметры матрицы A в зависимости от количества разбиений d по каждой координатной оси в конечноэлементной сетке приведены в таблице. Параметры матрицы в трехмерной тестовой упругопластической задаче Matrix parameters in 3D test elastoplastic problem
Здесь n – размерность матрицы; b – полуширина ленты; z – количество элементов aij в матрице, удовлетворяющих условию |aij| ³ 10–6, которое на два порядка меньше критерия остановки в методе Ньютона–Равсона, использованного при достижении условия пластичности Мизеса; d – число обусловленности матрицы. Число обусловленности матрицы определялось как отношение наибольшего к наименьшему сингулярных значений матрицы. Оценка сингулярных значений матрицы осуществлялась при помощи функции svds пакета MATLAB. Для задач с параметрами сетки d = 30, 40 и 50 сингулярные значения оценивали с использованием библиотеки SLEPc [21] с критерием останова 10-3. Для задач с параметром сетки d = 100 оценка числа обусловленности не производилась из-за большого объема матриц. Производительность методов на небольших сетках. Анализ результатов, полученных методом релаксации, показал, что при значениях коэффициента релаксации w>1 на сетках с параметром d>15 метод расходится. При значениях w<1 метод релаксации сходится, но решение СЛАУ производится значительно медленнее, чем при использовании методов BiCGStab и GMRES.
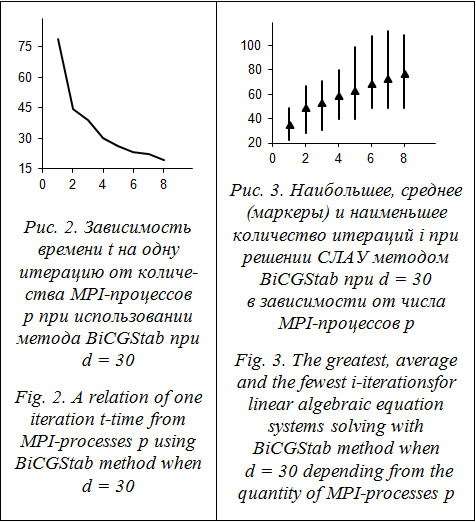
На рисунке 2 приведен график зависимости среднего по всему решению упругопластической задачи времени t, затрачиваемого на одну итерацию при использовании метода BiCGStab, от количества MPI-процессов p на задаче с сеткой d=30. На рисунке 3 показана зависимость наибольшего, среднего и наименьшего количества итераций i при решении СЛАУ методом BiCGStab при d = 30 в зависимости от числа MPI-процессов p. На всех рассмотренных сетках метод BiCGStab показал лучшее ускорение по сравнению с методом GMRES. Для сетки с параметром d = 10 (рис. 1а) у метода GMRES при использовании более 4 процессов имеет место замедление вычислений за счет затрат времени на передачу данных. В методе BiCGStab такое не происходит. Кроме этого, наблюдается скачкообразный рост ускорения в трех случаях, а именно: для сетки с d = 10 при переходе с 2 на 4 процесса, для сетки с d = 20 при переходе с 16 на 32 процесса и для сетки с d = 30 при переходе с 32 на 64 процесса. Этот эффект обусловлен тем, что матрица системы уравнений начинает полностью помещаться в процессорный кэш. Характер графика для сетки с параметром d = 40 аналогичен графику для сетки с d = 50. При этом ускорение метода BiCGStab достигало 5,8 на 64 процессах. Уменьшение времени на итерацию одновременно с увеличением количества итераций приводит к тому, что на отрезке от 1 до 8 процессов не происходит существенного ускорения (рис. 1б, в, г). Отсутствие ускорения на рассматриваемом отрезке объясняется тем, что использованная реализация предобуславливателя ILU(0) в библиотеке lis не производит, по нашему мнению, межпроцессорный обмен. Поэтому при увеличении количества процессов требуется большее количество итераций для достижения требуемой точности. При использовании более восьми процессов время на итерацию уменьшается быстрее, чем увеличивается количество итераций, поэтому общее время решения СЛАУ уменьшается. Применение других предобуславливателей может существенно повлиять на данный эффект. Метод GMRES показывает лучшее абсолютное время решения СЛАУ на всех рассматриваемых сетках на небольшом количестве процессов, однако метод BiCGStab является более масштабируемым, так как при использовании большего количества процессов у него наблюдается большее ускорение по сравнению с методом GMRES. Например, для решения СЛАУ в задаче с параметром сетки d = 40 одним процессом методу BiCGStab требуется затратить 17,5 секунды, а методу GMRES – 13,1 секунды. Однако при использовании 64 процессов методу BiCGStab требуется затратить 2,8 секунды, а методу GMRES – 3,4 секунды. Это объясняется тем, что при использовании метода BiCGStab требуется меньшее количество операций передачи данных. Применение прямых методов из работ [2, 3] для решения СЛАУ в упругопластической задаче не позволяло решать на кластере «Уран» ИММ УрО РАН задачи с параметрами сеток d > 35, поскольку для хранения матрицы жесткости требовалось много оперативной памяти. Применение разряженных схем хранения матрицы в совокупности с предобусловленными итерационными методами позволило сократить затраты на хранение матрицы жесткости и дало возможность решать задачу с большим разбиением сетки. Задержки сети. В работе [22] отмечается, что в силу сложности модели памяти современных компьютерных систем, недетерминированности времени работы сети и других факторов единственной оценкой производительности параллельных алгоритмов остается вычислительный эксперимент. Для оценки величины случайной погрешности, вносимой в процесс итерационного решения СЛАУ передачей данных, в различное время в течение недели восемь раз осуществлялся запуск решения упругопластической задачи сжатия параллелепипеда с использованием одинаковых входных данных. Для решения использовался метод BiCGStab с предобуславливателем ILUT. Во время решения производился замер чистого времени решения СЛАУ и количества итераций, потребовавшихся для достижения сходимости. На рисунке 4 показана зависимость среднего времени одной итерации t от степени деформации параллелепипеда e при решении задачи с параметром сетки d = 100 методом BiCGStab с предобуславливателем ILUT при запуске задачи восемь раз в течение недели. Степень деформации вычислялась как Жирной линией на рисунке 4 показано значение среднего времени одной итерации решения СЛАУ по всем восьми запускам. На рисунке видно, что большинство кривых находятся рядом со средним значением. Две кривые, наиболее сильно отклоняющиеся от средней кривой, соответствуют моментам наибольшей загруженности кластера. Кроме того, поскольку задача ставилась на счет не в эксклюзивном режиме, это могло привести к неоптимальному распределению вычислений на узлы кластера. На рисунке 5 для данных, приведенных на рисунке 4, показана зависимость коэффициента вариации V времени вычисления одной итерации от степени деформации e при решении упругопластической задачи с сеткой d = 100 методом BiCGStab с предобуславливателем ILUT при многократном запуске задачи в течение недели. Коэффициент вариации вычислялся по формуле
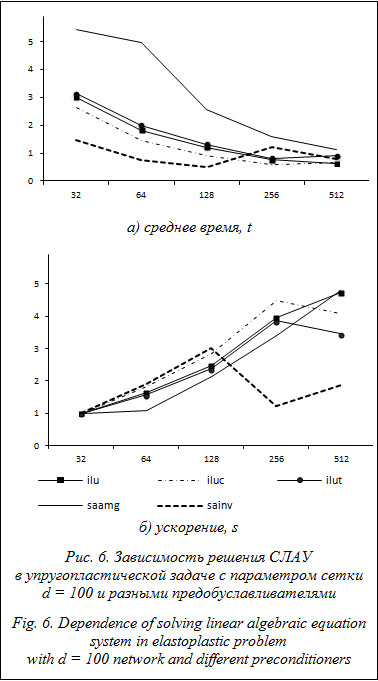
Производительность методов на больших сетках. Эффективность распараллеливания решения упругопластической задачи сжатия параллелепипеда с параметром сетки d = 100 анализировалась для метода BiCGStab с разными предобуславливателями. Выбор данного метода обусловлен его лучшей производительностью и масштабируемостью, проявленными на небольших сетках. На рисунке 6 показана зависимость среднего времени t решения СЛАУ и ускорения s по сравнению с 32 процессами от выбранного предобуславливателя и количества вычислительных процессов. Анализ результатов вычислений показал, что предобуславливатель SAAMG требует в среднем в 4 раза больше итераций для решения СЛАУ, чем остальные предобуславливатели. Предобуславливатель на основе алгебраического многосеточного метода требует значительно большего времени для решения СЛАУ, чем другие предобуславливатели при использовании одинакового количества вычислительных процессов.
Специфическое поведение предобуславливателя SAINV объясняется тем, что его реализация в использованной версии библиотеки имеет утечки памяти. Поведение ускорений согласуется с зависимостями для времени решения СЛАУ предобуславливателями SAAMG и ILU. На основании изложенного можно сделать следующие выводы. Итерационные методы позволили решать упругопластическую задачу методом конечных элементов с большим разбиением, чем прямые методы. Метод релаксаций по сравнению с методами BiCGStab и GMRES тратит значительно больше времени на решение СЛАУ, поэтому является неэффективным. Метод GMRES тратит наименьшее время на решение СЛАУ на небольшом количестве процессов, однако метод BiCGStab обладает лучшим ускорением, хорошей масштабируемостью и при использовании большого количества процессоров обеспечивает наименьшее время на решение СЛАУ. Вычислительный эксперимент по анализу задержки сети при решении тестовой упругопластической задачи показал, что случайное отклонение времени решения СЛАУ от средних значений, вызванное стохастической задержкой сети, в среднем не превышает 5 % . Предобуславливатель ILUC является наиболее эффективным из рассмотренных по времени решения СЛАУ, однако предобуславливатель SAINV требует наименьшего количества итераций решения СЛАУ методом BiCGStab. Литература 1. Поздеев А.А., Трусов П.В., Няшин Ю.И. Большие упругопластические деформации: теория, алгоритмы, приложения. М.: Наука, 1986. 234 с. 2. Коновалов А.В., Толмачев А.В., Партин А.С. Параллельное решение упругопластической задачи с применением трехдиагонального алгоритма LU-разложения из библиотеки SCALAPACK // Вычислительная механика сплошных сред. 2011. Т. 4. № 4. С. 34–41. 3. Толмачев А.В., Коновалов А.В., Партин А.С. Использование усеченного варианта алгоритма SPIKE из библиотеки Intel Adaptive SPIKE-Based Solver для решения упругопластической задачи // Вычислительные методы и программирование. 2011. Т. 12. С. 170–175. 4. Демешко И.П., Коновалов А.В. Результаты применения параллельных вычислений для решения двумерных задач прямыми методами // Физико-химическая кинетика в газовой динамике. 2008. Т. 7; URL: http://www.chemphys.edu. ru/article/106/ (дата обращения: 06.01.2014). 5. Бутюгин Д.С. Алгоритмы решения СЛАУ на системах с распределенной памятью в применении к задачам электромагнетизма // Вестн. Южно-Уральского гос. ун-та. Сер.: Вычислительная математика и информатика. 2012. № 46. С. 5–18. 6. Бутюгин Д.С., Гурьева Я.Л., Ильин В.П. [и др.]. Библиотека параллельных алгебраических решателей KRYLOV // Параллельные вычислительные технологии: тр. междунар. науч. конф. (1–5 апреля 2013 г., г. Челябинск). Челябинск: Издат. центр ЮУрГУ, 2013. С. 76–86. 7. Краснопольский Б.И. Об особенностях решения больших систем линейных алгебраических уравнений на многопроцессорных вычислительных системах различной архитектуры // Вычислительные методы и программирование: новые вычислительные технологии. 2011. № 12. С. 176–182. 8. Копысов С.П., Кузьмин И.М., Недожогин Н.С., Новиков А.К. Параллельные алгоритмы метода дополнения Шура в программной модели CUDA+OpenMP // Вестн. УГАТУ. 2013. Т. 17. № 5 (58). C. 167–177. 9. Watkins D.S. Fundamentals of Matrix Computations. John Wiley & Sons, 2004, 640 p. 10. van der Vorst H. A. BI-CGSTAB: a fast and smoothly converging variant of BI-CG for the solution of nonsymmetric linear systems. SIAM Journ. Sci. Stat. Comput., 1992, vol. 13, no. 2, pp. 631–644; DOI: 10.1137/0913035. 11. Saad Y. Iterative Methods for Sparse Linear Systems. Society for Industrial and Applied Mathematics, 2003, 547 p. 12. Акимова Е.Н., Демешко И.П., Коновалов А.В. Результаты вычислительных экспериментов решения двумерной упругопластической задачи итерационными методами на кластерной системе // Физико-химическая кинетика в газовой динамике. 2010. Т. 9; URL: http://www.chemphys.edu.ru/article/187/ (дата обращения: 06.01.2014). 13. Konovalov A.V. Constitutive relations for an elastoplastic medium under large plastic deformations. Mechanics of Solids, 1997, vol. 32, no. 5, pp. 117–124. 14. Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К. Алгоритмы: построение и анализ. 2-е изд. М.: Вильямс, 2005. 1296 с. 15. Li N., Saad Y., Chow E. Crout Versions of ILU for General Sparse Matrices. SIAM Journ. on Scientific Computing, 2003, vol. 25, no. 2, pp. 716–728. 16. Bridson R., Tang W.-P. Refining an approximate inverse. Journ. Comput. Appl. Math, 2000, vol. 123, no. 1–2, pp. 293–306. 17. Pujii A., Nishida A., Oyanagi Yo. Evaluation of Parallel Aggregate Creation Orders: Smoothed Aggregation Algebraic Multigrid Method. High Performance Computational Science and Engineering. Springer US, 2005, vol. 172, pp. 99–122. 18. Кластер «Уран». URL: http://parallel.uran.ru/node/3 (дата обращения: 23.08.2013). 19. Nishida A. Experience in Developing an Open Source Scalable Software Infrastructure in Japan. Computational Science and 1st Applications. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2010, vol. 6017, pp. 448–462. 20. Kotakemori H., Hasegawa H., Nishida A. Performance evaluation of a parallel iterative method library using OpenMP. High-Performance Computing in Asia-Pacific Region, 2005. Proc. 8th Intern. Conf., 2005, pp. 5–436. 21. Hernandez V., Roman J.E., Vidal V. SLEPc: A scalable and flexible toolkit for the solution of eigenvalue problems. ACM Trans. Math. Softw., 2005, vol. 31, no. 3, pp. 351–362. 22. Ильин В.П. Проблемы высокопроизводительных технологий решения больших разреженных СЛАУ // Вычислительные методы и программирование. 2009. Т. 10. С. 141–147. References 5. Butyugin D.S. Linear algebraic equation systems solving algorithms in the distributed memory systems applying to 7. Krasnopolskiy B.I. On the peculiarities of solving large systems of linear algebraic equations on high performance 11. Saad Y. Iterative Methods for Sparse Linear Systems. Society for Industrial and Applied Mathematics, 2003, 547 p. |
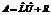 , где
, где 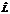 и
и 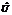 – неполные разложения матрицы; R – остаток. В работе используется вариант без образования дополнительного заполнения, называемый ILU(0).
– неполные разложения матрицы; R – остаток. В работе используется вариант без образования дополнительного заполнения, называемый ILU(0).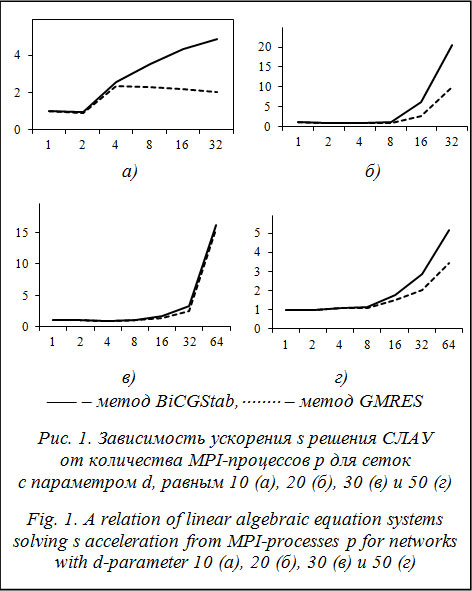
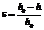 , где h0, h – начальная и текущая высота параллелепипеда соответственно.
, где h0, h – начальная и текущая высота параллелепипеда соответственно. , где s – среднеквадратическое отклонение от среднего времени одной итерации; t – среднее значение времени одной итерации по всем восьми запускам задачи.
, где s – среднеквадратическое отклонение от среднего времени одной итерации; t – среднее значение времени одной итерации по всем восьми запускам задачи.
| Постоянный адрес статьи: http://swsys.ru/index.php?id=3917&like=1&page=article |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
| Статья опубликована в выпуске журнала № 4 за 2014 год. [ на стр. 167-173 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Эффективность алгоритма LU-разложения с двухмерным циклическим распределением матрицы для параллельного решения упругопластической задачи
- Реализация некоторых приложений проекта Mantevo на платформе OpenTS DMPI
- Программы моделирования температурных полей в изделиях цилиндрической формы
- Расчет конструкций методом конечных элементов в среде математического пакета MathCAD
- Разработка программного модуля для автоматического выбора решателей систем линейных алгебраических уравнений для прочностного анализа
Назад, к списку статей