Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Информационная система анкетирования «Апофаси»
Аннотация:В статье описывается ПО, реализующее обработку и анализ данных экспертных опросов для получения прогнозной оценки реакций социально-экономических систем на возможные управляющие воздействия. Существующие программные продукты сбора и обработки данных имеют «упущения» при расчете прогнозной оценки реакций социально-экономических систем, основанной на обработке и анализе информации, полученной в ходе экспертного опроса. Следствием этих недостатков является низкая информативность данных, так как зачастую обрабатывается семантически эквивалентная информация, присутствует большое количество пустых значений показателей в таблицах гиперкубов, отсутствует возможность проведения анализа данных, не предусмотренного планом анкетирования, не учитывается степень уверенности эксперта в каждом из вариантов ответа, а также недостаточно полно и точно взвешиваются мнения экспертов, имеющие несколько различающихся по степени уверенности прогнозных оценок реакции системы на возможные управляющие воздействия. С целью устранения перечисленных недостатков разработан процессный подход к процедуре анкетирования, отличающийся от существующих наличием дополнительной обработки результатов экспертного оценивания при проведении их многомерного анализа с целью принятия управленческих решений.
Abstract:The article describes the software that implements data processing and analysis of expert interviews for predictive estimate of economic and social systems reactions on the possible control actions. Existing software prod-ucts for data collecting and processing have drawbacks when calculating the predictive estimate of economic and so-cial systems reactions based on processing and analyzing data obtained from the expert interview. As a result, there is low information awareness because of frequent processing of semantically equivalent information, a large quantity of empty rated values in the hypercube tables. That’s why there is no possibilit y to perform data analysis which is not foreseen by a questionnaire plan. What’s more important, the expert’s confidence in each answer choice is not taken into consideration. Moreover experts’ opinions are not fully analyzed because they can be different in confidence level of predictive estimate for system reaction to the possible management actions. In order to eliminate the mentioned di s-advantages, a processing approach to the questionnaire procedure has been developed. This approach is different b e-cause it includes processes of extra analyzing of the expert estimation results with multivariate analysis to take the best managing decision.
| Авторы: Камаев В.А. (kamaev@cad. vstu.ru) - Волгоградский государственный технический университет, Волгоград, Россия, доктор технических наук, Меликов А.В. (AlexeyV.Melikov@yandex.ru) - Пензенский артиллерийский инженерный институт им. Главного маршала артиллерии Н.Н. Воронова МО РФ (преподаватель), Пенза, Россия, кандидат технических наук | |
| Ключевые слова: информационная система анкетирования, многомерная модель данных, теория графов, хранилище данных, социально-экономическая система, прогнозная оценка, теория нечетких множеств, экспертная информация |
|
| Keywords: questionnaire informational system, multidimensional data model, the theory of counts, data warehouse, economic and social system, predictive estimate, fuzzy sets theory, expert information |
|
| Количество просмотров: 11796 |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
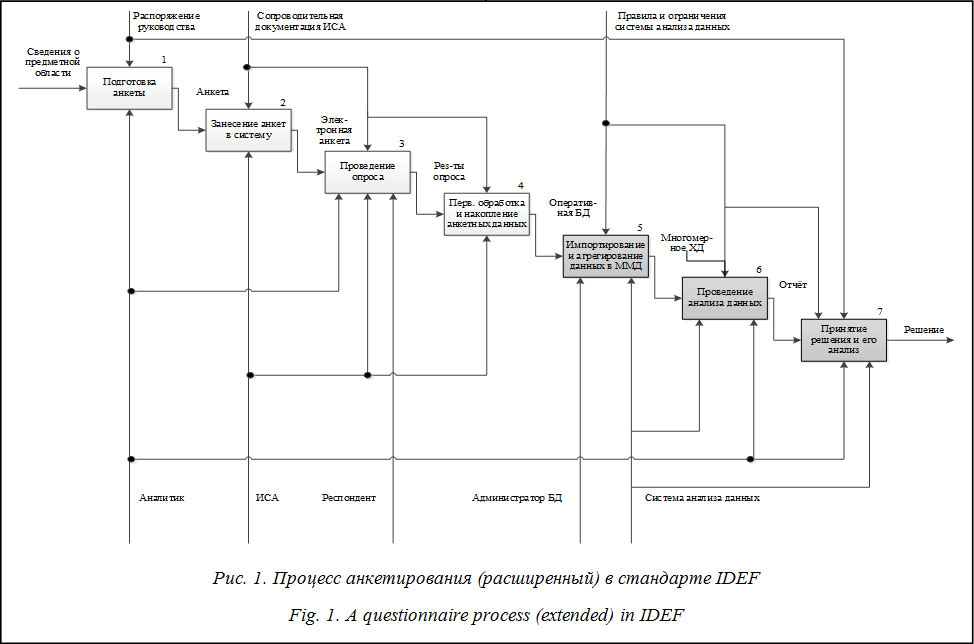
Предлагаемая информационная система анкетирования (ИСА) «Апофаси» представляет собой ПО для получения прогнозной оценки реакций социально-экономической системы (СЭС) (Свид. о регистр. электронного ресурса № 17686 от 14.12.2011 г., авторы: Меликов А.В., Макарычев П.П.) на возможные управляющие воздействия с использованием web-технологий в режиме удаленного доступа [1].
Сложность управления СЭС обусловлена сильным влиянием случайных факторов на объект управления (ОУ), малой изученностью реакций ОУ на конкретные управляющие воздействия, наличием значительного синергетического эффекта, а также трудностями в организации мониторинга поведения таких систем. Кроме того, в СЭС присутствует антропогенный фактор, имеющий по своей природе нестатистический характер. Все это не позволяет в должной мере изучать процессы, происходящие в СЭС, методами математической статистики, затрудняет оценку репрезентативности выборки и исследование поведения системы при изменении параметров прогнозируемого объекта, что в совокупности приводит к значительным погрешностям получаемых прогнозных оценок в задачах управления СЭС. Поэтому при управлении СЭС используют методы экспертного оценивания (ЭО), следовательно, от того, какими способами были проведены сбор и обработка экспертной информации (ЭИ), будет зависеть достоверность полученной прогнозной оценки реакций СЭС на возможное управляющее воздействие. На основании анализа существующих программных продуктов сбора и обработки данных («Analysis Services» и «Excel» компании Microsoft, «Data Mining» компании Oracle, «Deductor» компании BaseGroup и web-сервисов, таких как «ProstOpros» и «WebAnketa») были выявлены недостатки в обработке и анализе ЭИ, следствием которых является низкая информативность данных, так как не учтена степень уверенности эксперта в каждом из вариантов ответа; недостаточно полно и точно взвешены мнения экспертов, имеющие несколько различающихся по степени уверенности прогнозных оценок реакции СЭС на возможные управляющие воздействия [2].
В связи с предложенным процессным подходом к процедуре анкетирования возникла необходимость разработки математической модели преобразования данных экспертных опросов из исходной БД в агрегированные данные хранилища, позволяющей обработать данные в иерархиях, изначально не предусмотренных при сборе ЭИ [3], что, в свою очередь, повысит достоверность прогнозной оценки реакций системы и, как следствие, улучшит управление СЭС в целом.
Одним из условий эффективной организации данных является снижение занимаемого объема памяти на дисковом пространстве ЭВМ. Вес гиперкуба G – его размерность, помноженная на количество конкретных для него показателей: VG = k1 ´ k2 ´ …´ kn ´ m, где m – количество определенных для гиперкуба показателей g; ki – количество значений по измерению fi (i = 1, 2, …, n). При снижении количества пустых (нулевых) значений показателей, то есть при увеличении плотности гиперкуба, модель организации данных становится улучшенной. Пусть один из показателей в срезе гиперкуба равен 0. Тогда имеет место следующее разложение исходного гиперкуба, которое записывается в виде суммы нескольких гиперкубов меньших размерностей:
В результате получается, что суммарный вес разложения меньше веса исходного гиперкуба. Для достижения максимального улучшения модели данная процедура проводится итерационно по другим измерениям гиперкубов до исчезновения срезов, вырожденных по показателю [5]. При построении моделей запросов формируются схемы отношений, описывающие одну таблицу хранилища данных (ХД). Посредством объединения атрибутов однотипных схем отношений задается произвольная совокупность многоместных отношений, выраженных в специфической структуре, называемой C-системой (S[XYZ]), которая описывает структуру ХД. В применении к описанию структуры ХД построенной модели C-система имеет вид
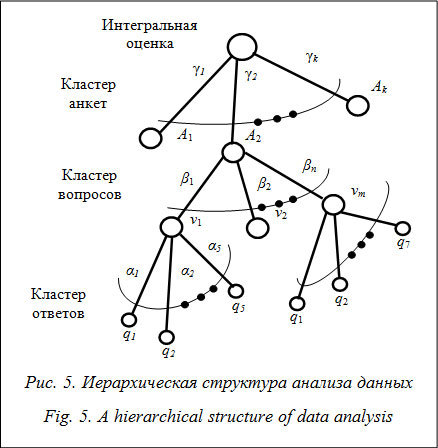
Такое представление многомерной модели данных, во-первых, обеспечивает их надежное и компактное хранение в сложных информационных структурах и возможность выделения значимой информации в процессе обработки данных, что в совокупности повышает эффективность обработки ЭИ и, как результат, достоверность прогнозной оценки реакций СЭС, во-вторых, способствует проектированию на ее основе адаптивной, интегрируемой и динамичной ИСА. После обоснования многомерной логической схемы данных в информационной системе была разработана методика анализа данных, собранных в ходе экспертного опроса, на основе теории нечетких множеств. Методика учитывает степень уверенности эксперта в каждом из вариантов ответа и позволяет получить более полную и точную взвешенную обобщенную прогнозную оценку реакций СЭС на возможные управляющие воздействия. Она состоит из следующих шагов: получение интегральной оценки, получение ЭИ, определение степени компетентности экспертов, получение обобщенного мнения экспертной группы, получение однозначного количественного результата опроса [7]. Остановимся на наиболее интересных моментах разработанной методики анализа данных. Итак, на шаге 1 применяется метод анализа иерархий [8]. Преимуществом применения иерархической структуры для анализа данных являются возможности разделения проблемы на составные задачи и фокусирования на интерпретации результатов отдельно анализируемой составляющей (рис. 5).
Каждому вопросу P ставится в соответствие лингвистическая переменная Однако сформировать группу экспертов одинаковой компетентности на практике весьма трудно. В связи с этим необходимо определить степень компетентности каждого эксперта и учесть ее при анализе ЭИ и получении обобщенной прогнозной оценки [9]. Таблица 1 Ответ k-го эксперта на целевой i-й вопрос анкеты Table 1 The answer of k-th expert for the objective i-th question
Примечание: жирным шрифтом выделена высокая вероятность повышения показателя эффективности наполовину. На шаге 3 для выявления вспомогательных характеристик в инструментарий экспертного опроса включается соответствующее множество дополнительных вопросов Для повышения точности прогнозной оценки реакций СЭС рассчитывается уровень компетентности экспертов для каждого дополнительного вопроса анкеты, включенного в инструментарий экспертного опроса, то есть определяются веса влияния каждой характеристики на компетентность эксперта. Проверка отличия характеристик экспертов осуществляется с помощью дисперсионного анализа (F-критерий), проводимого перед применением метода K-средних. Таким образом выявляются значимые характеристики экспертов в каждом кластере. Если p(F) меньше уровня значимости a, то нулевая гипотеза отвергается, в противном случае принимается (табл. 2). Таблица 2 Значимые характеристики экспертов Table 2 Experts significant features
При получении весов влияния характеристик на компетентность экспертов используется модифицированный метод нестрогого ранжирования, с помощью которого определяются обобщенные на случай предпочтения/безразличия атрибуты по отношению друг к другу веса Фишберна, обозначенные через Fbi:
Шаг 4 сводится к получению обобщенного мнения экспертной группы. В результате опроса множества всех экспертов Таблица 3 Пример обработки нечетких оценок группы экспертов Table 3 An example of processing fuzzy values of an expert group
Примечание: * – «размывание» нечеткой количественной меры. На шаге 5 получается однозначный количественный результат опроса. Для его получения выбирается элемент В действительности разработана математическая модель определения компетентности экспертов, позволяющая рассчитывать уровень компетентности опрашиваемого для каждого вопроса анкеты в отдельности, что способствует повышению эффективности обработки данных и точности прогноза; и методика представления ЭИ, учитывающая степень уверенности эксперта в каждом из вариантов ответа и позволяющая получить более полную и точную взвешенную обобщенную прогнозную оценку реакций СЭС на возможные управляющие воздействия. Основываясь на построенной модели обработки данных, авторы спроектировали и реализовали ХД для Microsoft SQL Server 2008. Программные средства сбора информации, которые имеют трехуровневую архитектуру, были разработаны с использованием платформы Java EE и фреймворка Struts. Процессы извлечения, преобразования и загрузки данных реализованы как исполняемые скрипты языка php. Процедуры обработки и анализа данных реализованы с использованием математического пакета Matlab. С помощью системы компьютерной алгебры Maple была смоделирована и реализована процедура получения прогнозной оценки в задаче управления СЭС. Пользовательский интерфейс ИСА написан по технологии ASP.NET. С помощью разработанных програм- мных средств автоматизированы процессы сбора, хранения, обработки и анализа данных экспертного опроса, а также получения обобщенной прогнозной оценки мнений экспертной группы.
Реализованное ПО в виде ИСА «Апофаси» успешно внедрено в Пензенском государственном университете для управления системой менеджмента качества, в администрации Железнодорожного района г. Пензы для управления деятельностью органов местного самоуправления и в ЗАО ПФК «Аттика» (г. Волгоград) для принятия управленческих решений, способствующих сокращению времени простоя технологического оборудования и повышению эффективности производства. Литература 1. Афонин А.Ю., Макарычев П.П. Система анкетирования на основе Web-технологий // Изв. вузов. Поволжский регион. Технические науки. 2010. № 3 (15). С. 49–56. 2. Меликов А.В. Обработка и анализ экспертной информации для управления социально-экономическими системами: дис…канд. техн. наук. Волгоград: Изд-во ВолгГТУ, 2013. 136 с. 3. Камаев В.А., Заболотский М.А., Полякова И.А., Тихонин А.В. Когнитивный анализ качества подготовки специалистов в вузах // Современные наукоемкие технологии. 2005. № 6. С. 26–27. 4. Редреев П.Г. Разработка и исследование обобщенной табличной модели данных со списочными компонентами: автореф…канд. физ.-мат. наук. Челябинск: Изд-во ЮУрГУ, 2011. 16 с. 5. Меликов А.В. Применение теории множеств для организации данных исходной реляционной базы данных // Прикаспийский журнал: управление и высокие технологии. 2011. № 4 (16). С. 16–22. 6. Алексеев В., Таланов В. Графы и алгоритмы // ИНТУИТ. 2006; URL: http://www.intuit.ru/studies/courses/101/ 101/info (дата обращения: 11.10.2013). 7. Камаев В.А., Меликов А.В. Анализ анкетных данных и оценки прогнозного решения на их основе к задаче управле- ния // Изв. ВолгГТУ. 2012. № 15 (102). С. 90–96. 8. Саати Т. Принятие решений. Метод анализа иерархий. М.: Радио и связь, 1993. С. 78–87. 9. Баранов Л.Г., Птушкин А.И., Трудов А.В. Нечеткие множества в экспертном опросе // Социология. 2004. № 19. С. 9–15. 10. Ажмухамедов И.М. Нечеткая когнитивная модель оценки компетенций специалиста // Вестн. Астраханского гос. тех. ун-та. 2011. № 2. С. 186–190. References | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
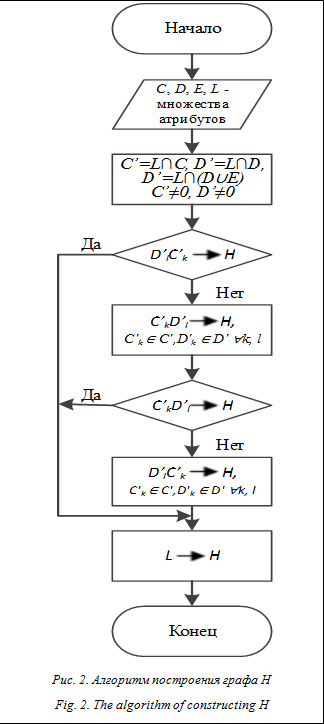
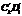 , а для многозначной зависимости, где атрибуты из C располагаются в иерархии выше атрибутов из D È E, так как при существовании двух кортежей, совпадающих по C, существуют еще два кортежа с тем же значением C, добавляется дуга
, а для многозначной зависимости, где атрибуты из C располагаются в иерархии выше атрибутов из D È E, так как при существовании двух кортежей, совпадающих по C, существуют еще два кортежа с тем же значением C, добавляется дуга  . Таким образом, в граф H добавляют- ся вершины для атрибутов из множества L, отсутствующих в схеме иерархий в качестве вершин (рис. 2) [4].
. Таким образом, в граф H добавляют- ся вершины для атрибутов из множества L, отсутствующих в схеме иерархий в качестве вершин (рис. 2) [4].
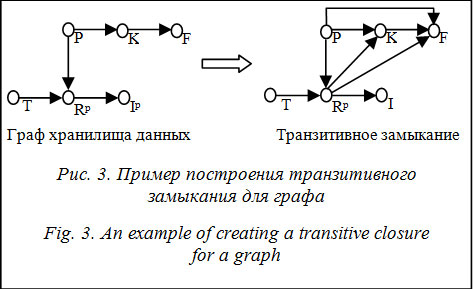
 , где F, K, P, R, T – измерения. В результате транзитивного замыкания (рис. 3) получается:
, где F, K, P, R, T – измерения. В результате транзитивного замыкания (рис. 3) получается:
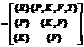 .
.

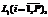 значениями которой являются варианты ответов
значениями которой являются варианты ответов  , где J i – количество вариантов ответа на i-й вопрос. Значение лингвистической переменной описывается в виде нечеткого множества, которое задается на базовом (четком) множестве действительных чисел
, где J i – количество вариантов ответа на i-й вопрос. Значение лингвистической переменной описывается в виде нечеткого множества, которое задается на базовом (четком) множестве действительных чисел 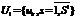 , где s – весь возможный диапазон оценок лингвистической переменной Li. Результат сопоставления каждой оценки из вышеприведенного множества с количественным показателем степени уверенности – значение функции принадлежности, задаваемой вектором-строкой:
, где s – весь возможный диапазон оценок лингвистической переменной Li. Результат сопоставления каждой оценки из вышеприведенного множества с количественным показателем степени уверенности – значение функции принадлежности, задаваемой вектором-строкой: 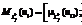
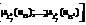 .
. Каждому вопросу Dn ставится в соответствие множество дополнительных ответов
Каждому вопросу Dn ставится в соответствие множество дополнительных ответов  Для преобразования ответов экспертов на дополнительные вопросы в количественные коэффициенты компетентности каждому
Для преобразования ответов экспертов на дополнительные вопросы в количественные коэффициенты компетентности каждому 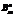 -му варианту ответа на Dn-й вопрос ставится в соответствие положительный коэффициент
-му варианту ответа на Dn-й вопрос ставится в соответствие положительный коэффициент 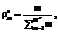
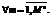 Величина данного коэффициента зависит от номера варианта ответа на дополнительный вопрос. В результате выбор k-м экспертом однозначно определяет некоторый коэффициент из множества
Величина данного коэффициента зависит от номера варианта ответа на дополнительный вопрос. В результате выбор k-м экспертом однозначно определяет некоторый коэффициент из множества  , который обозначается через
, который обозначается через  . Эта величина зависит от всех ответов на дополнительные вопросы. Влияние уровня компетентности эксперта на нечеткую количественную меру реализуется путем выполнения операции «размывания» по следующему правилу:
. Эта величина зависит от всех ответов на дополнительные вопросы. Влияние уровня компетентности эксперта на нечеткую количественную меру реализуется путем выполнения операции «размывания» по следующему правилу: 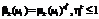 .
.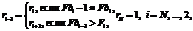
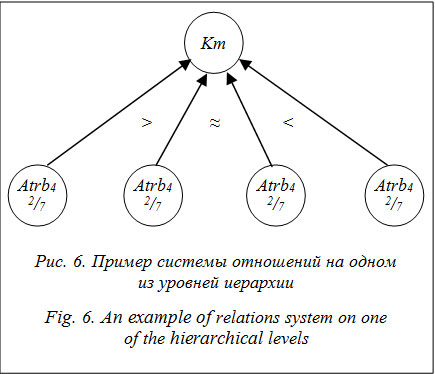
 где Atrbi и Atrbj – атрибуты i-й и j-й вершин одного уровня иерархии. Наложение системы отношений предпочтения/безразличия на фрагмент графа показано на рисунке 6 [10].
где Atrbi и Atrbj – атрибуты i-й и j-й вершин одного уровня иерархии. Наложение системы отношений предпочтения/безразличия на фрагмент графа показано на рисунке 6 [10].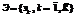 для каждого i-го вопроса анкеты получается K нечетких количественных мер
для каждого i-го вопроса анкеты получается K нечетких количественных мер 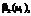 которые учитывают степени компетентности опрашиваемых экспертов. Нечеткое множество, характеризующее обобщенное мнение группы экспертов, определяется как пересечение нечетких мнений экспертов, имеющее функцию принадлежности,
которые учитывают степени компетентности опрашиваемых экспертов. Нечеткое множество, характеризующее обобщенное мнение группы экспертов, определяется как пересечение нечетких мнений экспертов, имеющее функцию принадлежности, 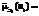
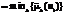 . Применяя конъюнкцию к нечетким множествам, соответствующим ответам экспертов, получаем обобщенную нечеткую оцен- ку, представленную множеством наименьших операндов по результатам экспертного опроса (табл. 3).
. Применяя конъюнкцию к нечетким множествам, соответствующим ответам экспертов, получаем обобщенную нечеткую оцен- ку, представленную множеством наименьших операндов по результатам экспертного опроса (табл. 3). , имеющий максимальное значение степени принадлежности к полученному обобщенному нечеткому множеству мнений группы экспертов:
, имеющий максимальное значение степени принадлежности к полученному обобщенному нечеткому множеству мнений группы экспертов:  Применяя дизъюнкцию к элементам нечеткого множества обобщенной оценки, получим однозначный количественный результат экспертного опроса, соответствующий максимальному значению операнда, который указывает на конкретный элемент базового множества Ui.
Применяя дизъюнкцию к элементам нечеткого множества обобщенной оценки, получим однозначный количественный результат экспертного опроса, соответствующий максимальному значению операнда, который указывает на конкретный элемент базового множества Ui.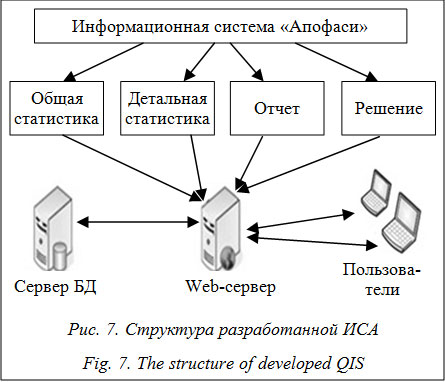
| Постоянный адрес статьи: http://swsys.ru/index.php?id=3927&page=article |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
| Статья опубликована в выпуске журнала № 4 за 2014 год. [ на стр. 222-228 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Возможности реализации темпоральной базы данных для интеллектуальных систем
- Об организации бесперебойной сети для передачи коротких сообщений в случае чрезвычайных ситуаций
- Алгоритмы и программа верификации функциональных моделей
- Определение весовых коэффициентов для аддитивной фитнес-функции генетического алгоритма
- Метод обнаружения веб-роботов на основе анализа графа пользовательского поведения
Назад, к списку статей