Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Реализация прецедентного модуля для интеллектуальных систем
Аннотация:В статье рассматриваются актуальные вопросы применения прецедентного подхода в современных интеллектуальных (экспертных) системах, в частности, в системах поддержки принятия решений, ориентированных на помощь ЛПР при управлении сложными объектами и процессами в условиях наличия различного рода неопределенности в исходных данных и экспертных знаниях. Применение механизмов правдоподобных рассуждений и прецедентного подхода (CBR – Case-Based Reasoning) направлено на расширение возможностей и сферы применения интеллектуальных систем в условиях неопределенности и сокращение времени на поиск решения. Для реализации прецедентного подхода авторы предлагают использовать сетевую (онтологическую) модель представления прецедентов и гибридный алгоритм извлечения прецедентов, базирующийся на теории структурного отображения и методе ближайшего соседа. Кроме того, в статье обсуждается возможность оптимизации (сокращения) базы знаний (базы прецедентов) системы, основанной на прецедентах (CBR-системы), с использованием методов кластеризации. Предложена архитектура CBR-системы, базирующаяся на предложенной модели представления прецедентов и алгоритмах извлечения и оптимизации базы прецедентов (накопленного системой опыта). Описаны особенности программной реализации основных модулей прототипа CBR-системы в среде программирования MS Visual Studio 2010 с использованием редактора онтологий Protégé под операционную систему MS Windows. Оценка эффективности предлагаемого подхода и разработанных программных средств в составе прототипа CBR-системы была проведена на нескольких тестовых базах из наборов данных, предлагаемых кафедрой информатики и вычислительной техники Калифорнийского университета (UCI Machine Learning Repository).
Abstract:The paper considers important problems of applying a case-based approach in modern intellectual (expert) sys-tems. In particular, in decision support systems focused on assistance to a decision maker when managing complex objects and processes under uncertainty in input data and expert knowledge. Using the mechanisms of plausible reasoning and Case-Based Reasoning (CBR) is directed to expanding the scope of application of intelligent systems under uncertainty as well as reducing time to find solutions. To implement a case-based approach, the authors propose a network (ontological) representation model of cases and hy-brid case retrieving algorithm which is based on the structural mapping theory and the nearest neighbor method. In addition, the paper discusses the possibility of optimizing (reducing) a knowledge base (use case base) of a case-based system (CBR system) using clustering methods. The article proposes CBR system architecture based on the proposed case-representation model and retrieving and opti-mization algorithms for a precedent base (accumulated experience of the system). The authors describe the features of soft-ware implementation of the basic modules of CBR-system prototype in MS Visual Studio 2010 using the Protégé ontology editor for MS Windows. Effectiveness evaluation of the proposed approach and developed software has been carried out on several test data sets offered by the Department of Computer Science, University of California (UCI Machine Learning Re-pository).
| Авторы: Зо Лин Кхаинг (zo.lin2010@mail.ru) - Национальный исследовательский университет «МЭИ» (аспирант ), г. Москва, Россия, Ар Кар Мьо (arkar2011@gmail.com) - Национальный исследовательский университет «МЭИ» (аспирант), Москва, Россия, Варшавский П.Р. (VarshavskyPR@mpei.ru) - Национальный исследовательский университет «МЭИ» (доцент), г. Москва, Россия, кандидат технических наук, Алехин Р.В. (r.alekhin@gmail.com) - Национальный исследовательский университет «МЭИ» (ассистент), Москва, Россия | |
| Ключевые слова: методы кластеризации, структурная аналогия, прецедентный подход, правдоподобные рассуждения, интеллектуальные системы |
|
| Keywords: methods of clustering, structural analogy, case-based reasoning approach, plausible reasoning, intelligent systems |
|
| Количество просмотров: 15563 |
Версия для печати Выпуск в формате PDF (4.84Мб) Скачать обложку в формате PDF (0.35Мб) |
Прецедентный подход широко применяется при решении целого ряда задач в области искуственного интеллекта, в частности, для моделирования человеческих рассуждений [1] и конструирования интеллектуальных систем (ИС), ориентированных на использование аппарата нетрадиционных логик и методов правдоподобных рассуждений (например, индуктивных методов, методов на основе аналогий и прецедентов) [2].
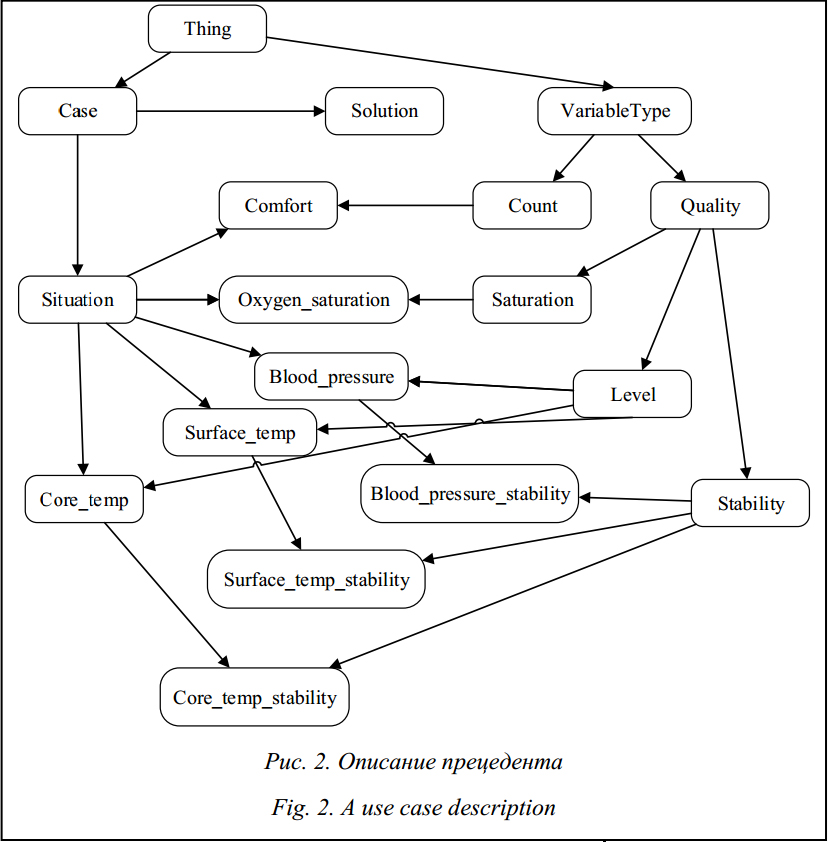
Методы рассуждения на основе прецедентов (CBR – Case-Based Reasoning) и CBR-системы успешно используются в различных областях человеческой деятельности (в медицине, технике, юриспруденции и др.), прецедентный подход активно применяется в динамических ИС, в системах экспертного диагностирования, поддержки принятия решений (ИСППР), машинного обучения, в информационно-поисковых системах при решении задач прогнозирования, обобщения накопленного опыта, поиска решения в малоизученных предметных областях и т.д. [1, 3]. CBR-методы основываются на накоплении опыта и последующей адаптации решения известной задачи к решению новой. Прецедентный подход позволяет упростить процесс принятия решений в условиях жестких временных ограничений и при наличии различного рода неопределенностей в исходных данных и экспертных знаниях. Прецедентный подход Данный подход базируется на понятии прецедента, определяемого как случай, имевший место ранее и служащий примером или оправданием для последующих случаев подобного рода. Как правило, CBR-методы включают в себя четыре основных этапа, образующих так называемый CBR-цикл [4]: – retrieve – извлечение наиболее соответствующего (подобного) прецедента (или прецедентов) для сложившейся ситуации из библиотеки прецедентов (БП); – reuse – повторное использование извлеченного прецедента для попытки решения текущей проблемы (задачи); – revise – пересмотр и адаптация в случае необходимости полученного решения в соответствии с текущей проблемой (задачей); – retain – сохранение вновь принятого решения как части нового прецедента. Последние два этапа в CBR-цикле могут исключаться и выполняться экспертом или ЛПР. Это связано с необходимостью при формировании БП использовать только достоверную информацию или информацию, подтвержденную экспертом. Таким образом, можно минимизировать количество прецедентов в БП CBR-системы и повысить степень их достоверности. В общем случае модель представления прецедента включает описание ситуации, решение для данной ситуации и результат применения решения: CASE = (Situation, Solution, Result), где Situation – ситуация, описывающая данный прецедент; Solution – решение (например диагноз и рекомендации ЛПР); Result – результат применения решения, который может включать список выполненных действий, дополнительные комментарии и ссылки на другие прецеденты, а также в некоторых случаях обоснование выбора данного решения и возможные альтернативы. Различия способов представления прецедентов заключаются в разных способах описания указанных компонент. В большинстве случаев достаточно простого параметрического представления в виде набора параметров с конкретными значениями и решения: CASE = (x1, x2, …, xn, R), где x1, …, xn – параметры ситуации, описывающей данный прецедент (x1ÎX1, x2ÎX2, …, xnÎXn), n – количество параметров; R – решение (диагноз и рекомендации ЛПР), а X1, … , Xn – области допустимых значений соответствующих параметров [1]. В некоторых случаях такого представления бывает недостаточно, так как имеются ограничения, связанные с выразительными возможностями параметрической модели представления прецедентов. При параметрическом представлении трудно обеспечить учет зависимости между параметрами прецедента (например, временные зависимости или причинно-следственные). Одним из возможных способов решения этой проблемы является представление прецедентов на основе сетевой модели представления знаний с использованием онтологического подхода. Представление прецедентов с помощью онтологии Среди специалистов в области компьютерной лингвистики наиболее устоявшимся (классическим) считается определение онтологии как спецификации концептуализации [5]. Определение онтологии как формального представления предметной области, построенного на базе концептуализации, предполагает выделение ее трех взаимосвязанных компонентов: таксономии терминов, описаний смысла терминов, а также правил их использования и обработки. Таким образом, модель онтологии О задается тройкой: O = (Х, R, Ф), где Х – конечное множество концептов (понятий, терминов) предметной области, которую представляет онтология; R – конечное множество отношений между концептами; Ф – конечное множество функций интерпретации, заданных на концептах и (или) отношениях [5]. Выбор онтологии для представления прецедентов обусловлен рядом важных достоинств, отличающих ее от других моделей представления знаний. Использование онтологии для представления прецедентов позволяет задать сложную структуру прецедента, включающую данные разных типов, и обеспечить естественность представления структурированных знаний и достаточно простое обновление их в относительно однородной среде. Последнее свойство особенно важно для ИСППР, ориентированных на открытые и динамические предметные области. Онтология содержит знания по предметной области, которые используются для поддержки CBR-цикла, а также задает структуру прецедента и обеспечивает его хранение. Знания о предметной области и модель прецедентов описываются в виде иерархии концептов онтологии, а каждый прецедент из БП – в виде иерархии экземпляров концептов, связанных отношениями языка описания онтологий для Semantic Web (OWL). Метод извлечения прецедентов Существует целый ряд методов извлечения прецедентов и их модификаций [1], например, метод ближайшего соседа, метод извлечения прецедентов на основе деревьев решений, метод извлечения прецедентов с использованием нейросетевых моделей, метод извлечения с учетом применимости прецедента и др. Для определения степени сходства прецедентов, представленных с помощью онтологии предметной области, предлагается использовать метод извлечения на основе теории структурного отображения (SMT – Structure Mapping Theory) [6]. Теория структурного отображения позволяет формализовать некоторый набор неявных ограничений, которыми пользуется человек, оперируя такими понятиями, как сходство, аналогия и подобие. Согласно SMT, предполагается, что аналогия является отображением знаний одной области (базы) в другую область (цель), базирующимся на системе отношений между объектами базовой области и объектами целевой области, а также то, что человек (ЛПР) предпочитает оперировать некоторой целостной системой взаимосвязанных глубинных отношений, а не простым набором поверхностных и слабосвязанных фактов. Процесс поиска решения на основе аналогий согласно SMT включает три основных этапа. 1. Определение потенциальных аналогов. Имея целевую ситуацию (цель), определить другую ситуацию (базу), которая является аналогичной или подобной целевой ситуации. 2. Отображение и вывод. Построить отображение, состоящее из соответствий между базой и целью. Это отображение может включать дополнительные знания (факты) о базе, которые могут быть перенесены в цель. 3. Оценка качества соответствия. Оценить полученное соответствие, используя такие структурные критерии, как число подобий и различий, степень структурного соответствия, количество и тип новых знаний, полученных по аналогии из кандидатов заключения. Рассмотрим механизм структурного отображения (SME – Structure Mapping Engine), базирующийся на SMT. Этот механизм предназначен для моделирования поиска решений на основе аналогий и прецедентов, он позволяет сформировать наиболее общие соответствия (Gmaps) для структурированных представлений базовой и целевой областей, а также обеспечивает оценку полученных соответствий. Входными данными для алгоритма SME являются структурные представления базовой и целевой областей. Алгоритм SME реализует четыре этапа. 1. Построение локальных соответствий (гипотез соответствия – MH). Определение соответствия между элементами базовой и целевой областей с помощью правил: - если два отношения имеют одинаковое имя, создается гипотеза соответствия; - для каждой гипотезы соответствия между отношениями проверяются их соответствующие аргументы: если их количество и тип совпадают, создается гипотеза соответствия между ними. Далее определяется оценка правдоподобия локальных соответствий с помощью следующих правил и коэффициентов, задаваемых экспертом: CF1 – величина, на которую необходимо увеличить оценку правдоподобия MH, если имена базового и целевого элементов совпадают; CF2 – величина, на которую необходимо увеличить оценку правдоподобия MH, если хотя бы базовый элемент имеет родительское отношение – отношение более высокого уровня: - увеличивается оценка правдоподобия для соответствия на CF1, если базовый и целевой элементы имеют одинаковые имена; - увеличивается оценка правдоподобия для соответствия на CF2, если хотя бы у базового элемента имеется родительское отношение. 2. Построение глобальных соответствий (Gmaps). Формирование систем соответствий, которые используют совместимые пары объектов (1:1), называемые Emaps. 3. Построение кандидатов заключения (Inferences). С каждым множеством Gmaps связывается множество (возможно, пустое) кандидатов заключения Inferences – факты, которые присутствуют в базовой области, но изначально не присутствуют в соответствующей целевой. 4. Оценка глобальных соответствий (SES). Получение оценки для глобальных соответствий Gmaps, которая зависит от оценок правдоподобия локальных соответствий MH. Таким образом, в результате выполнения алгоритма формируются наиболее общие соответствия Gmaps, включающие следующие составляющие: - соответствия – множество парных соответствий между базовой и целевой областями; - кандидаты заключения – множество новых фактов, которые, предположительно, могут содержаться в целевой области; - оценка глобальных соответствий – числовая оценка качества Gmaps. Для извлечения прецедентов предлагается использовать оригинальную двухэтапную процедуру извлечения и определения сходства прецедента и текущей ситуации [7]: – определение сходства прецедента с текущей ситуацией на основе онтологии предметной области и формирование парных соответствий с помощью алгоритма на базе SMT; – определение сходства прецедента и текущей ситуации по методу ближайшего соседа с учетом полученных парных соответствий. На первом этапе сравниваются по структуре описания ситуации прецедента и текущей ситуации. Цель данного этапа – определить возможные парные соответствия между прецедентом и текущей ситуацией и оценить их сходство. На втором этапе для оценки близости текущей ситуации (T) и прецедента (C) используется метод ближайшего соседа. Для каждого парного соответствия в выбранной метрике определяется расстояние dTC между текущей ситуацией и прецедентом. Для определения значения степени сходства Sim(T, C) необходимо найти максимальное расстояние dmax в выбранной метрике, используя границы диапазонов параметров (xiнач и xiкон, i = 1, …, n). В результате получим множество прецедентов, и каждому из них будут сопоставлены две оценки сходства с текущей ситуацией, которые могут быть выражены в процентах: – оценка на основе онтологии предметной области: – оценка по методу ближайшего соседа: Sim(T, C) = 1 – dTC/dmax, где dTC – расстояние между текущей ситуацией и прецедентом; dmax – максимальное расстояние в выбранной метрике. Исходя из этих данных, ЛПР может выбрать наиболее подходящий прецедент и получить решение для текущей ситуации. Оптимизация базы прецедентов В процессе функционирования CBR-системы увеличивается количество прецедентов в БП, то есть CBR-система обучается (накапливает опыт) и в результате способна качественнее решать поставленные перед ней задачи, но при этом значительно увеличиваются временные затраты, требуемые для поддержания CBR-цикла. В таком случае целесообразно оптимизировать БП. Это можно сделать несколькими путями, например, сократить БП или обобщить накопленную информацию (прецеденты). Возможно сокращение БП за счет применения методов классификации и кластеризации прецедентов [8]. В работе рассмотрен подход к оптимизации БП на основе кластеризации с последующим удалением всех прецедентов в каждом кластере, кроме его центрального представителя. Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры). Если данные выборки представить как точки в признаковом пространстве, задача кластеризации сведется к определению «сгущений точек». Все кластеры должны объединять прецеденты с одинаковым диагнозом. Характеристиками кластера можно назвать два признака: внутренняя однородность и внешняя изолированность. Кластеризация позволит представить БП в более прозрачном виде для пользователя с сохранением распределения диагнозов и существенно сократить время поиска решения. Недостатком этого способа является потеря точности на границах кластеров. Для решения задачи оптимизации БП CBR-сис- темы с помощью кластеризации в работе предлагается использовать алгоритм k-средних [8]. Реализация прототипа CBR-системы Предлагаемый подход реализован в прототипе CBR-системы (рис. 1). Программная реализация прототипа CBR-системы выполнена с использованием языка C# и среды программирования MS Visual Studio 2010, а также редактора онтологий Protégé (http://protege.stanford.edu).
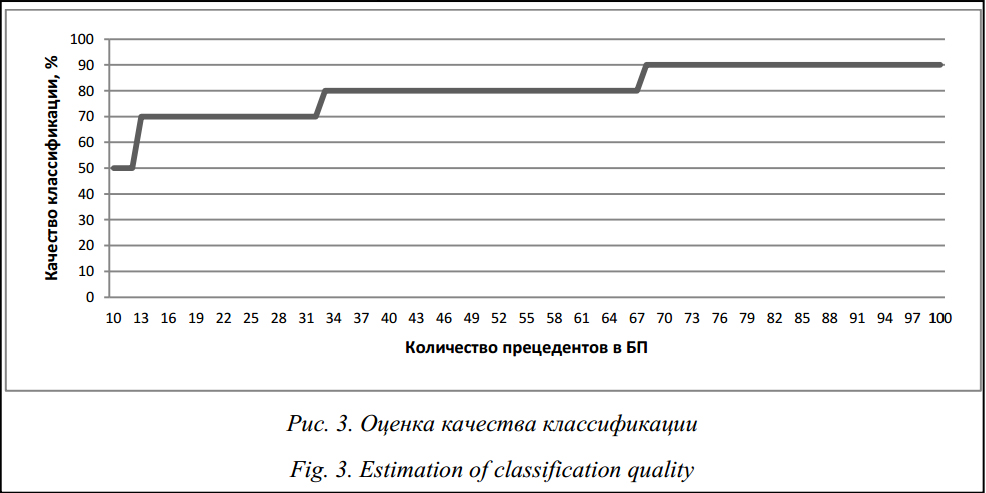
В данном случае поставленную задачу экспертного диагностирования можно свести к задаче классификации, то есть необходимо отнести текущую ситуацию к одному из известных прецедентов. Прототип CBR-системы позволяет вычислить оценки сходства текущей ситуации и прецедентов из БП [7]. ЛПР имеет возможность выбрать наиболее подходящий прецедент, исходя из двух оценок сходства по структуре (на основе онтологии предметной области и метода SMT) и по методу ближайшего соседа. Для оценки возможности оптимизации БП системы с помощью кластеризации был рассмотрен пример на основе набора данных из хранилища UCI Machine Learning Repository (http://archive. ics.uci.edu/ml/datasets/User+Knowledge+Modeling). Общее количество примеров в БД из репозитория – 258; они были разбиты на экзаменационную выборку (10 примеров), начальную выборку (10 прецедентов, изначально внесенных в БП системы) и оставшиеся примеры, использованные при тестировании прототипа CBR-системы для генерации новых прецедентов. Для начальной выборки из 10 прецедентов с помощью экзаменационной выборки была выполнена оценка качества классификации, соответствующая 50 %. Затем в процессе функционирования прототипа CBR-системы БП пополнялась новыми прецедентами, формируемыми на основе неиспользованных примеров из репозитория. При этом выполнялась проверка, и, если новый прецедент ухудшал качество классификации, он удалялся из БП и сохранялся в базу неудачных прецедентов (БНП). Таким образом, было накоплено 100 прецедентов в БП системы, 14 неудачных прецедентов в БНП, а полученная оценка качества классификации CBR-системой с БП из 100 прецедентов возросла до 90 % (рис. 3).
Таким образом, в работе рассмотрены основные понятия и особенности прецедентного под- хода, методы поиска решения на основе преце- дентов. Реализована возможность представления прецедентов на основе сетевой (онтологической) модели представления. Предложен метод поиска решения на основе прецедентов с использованием онтологии предметной области, теории структурного отображения и метода ближайшего соседа. Рассмотрена возможность оптимизации БП CBR-системы и предложен вариант оптимизации БП системы на основе кластеризации с использованием алгоритма k-средних. Разработана архитектура и выполнена программная реализация базовых модулей прототипа CBR-системы. Рассмотрен пример использования разработанного прототипа для решения задачи экспертной диагностики на основе прецедентов с использованием реальных наборов данных из хранилища (репозитория) UCI Machine Learning Repository. Литература 1. Варшавский П.Р., Еремеев А.П. Моделирование рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений // Искусственный интеллект и принятие решений. 2009. № 2. С. 45–57. 2. Вагин В.Н., Головина Е.Ю., Загорянская А.А., Фоми- на М.В. Достоверный и правдоподобный вывод в интеллектуальных системах. 2-е изд. М.: Физматлит, 2008. 3. Варшавский П.Р., Зо Лин Кхаинг, Аркар Мьо. Применение методов поиска решения на основе прецедентов в информационных поисковых системах // Программные продукты и системы. 2013. № 3. С. 114–119. 4. Aamodt A., Plaza E. Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches. Artificial Intelligence Communications. IOS Press, 1994, vol. 7, № 1, pp. 39–59. 5. Гаврилова Т.А., Хорошевский В.Ф. Базы знаний интеллектуальных систем. СПб: Питер, 2000. 6. Falkenhainer B., Forbus K., Gentner D. The Structure-Mapping Engine: Algorithm and examples. Artificial Intelligence, 1989, vol. 41, pp. 1–63. 7. Алехин Р.В., Варшавский П.Р. Реализация прецедентного модуля для интеллектуальной системы поддержки принятия решений // XIV национ. конф. по искусственному интеллекту с междунар. участием КИИ-2014: сб. тр. Т. 2. Казань: Изд-во РИЦ «Школа», 2014. С. 5–13. 8. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. Н.: Изд-во ИМ СО РАН, 1999. |
 , где k – количество соответствий; LSi – оценка правдоподобия для i соответствия; SESmax – оценка для случая, когда каждый элемент в базовой области имеет родительское отношение и в качестве базовой области выбирается целевая;
, где k – количество соответствий; LSi – оценка правдоподобия для i соответствия; SESmax – оценка для случая, когда каждый элемент в базовой области имеет родительское отношение и в качестве базовой области выбирается целевая;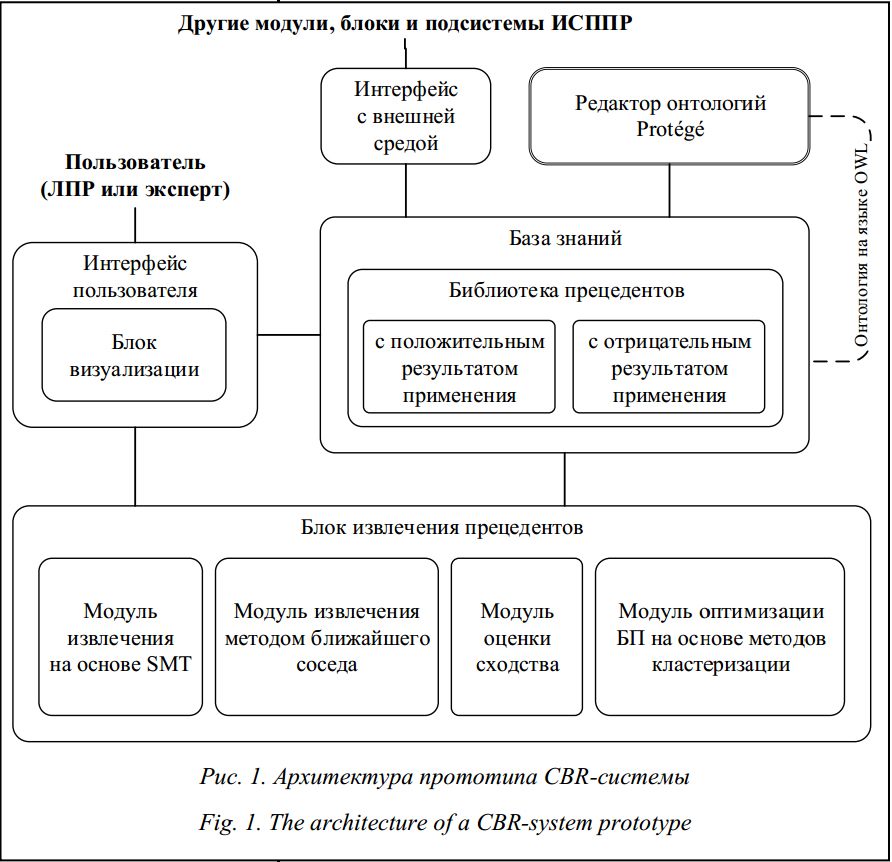
| Постоянный адрес статьи: http://swsys.ru/index.php?id=3993&like=1&page=article |
Версия для печати Выпуск в формате PDF (4.84Мб) Скачать обложку в формате PDF (0.35Мб) |
| Статья опубликована в выпуске журнала № 2 за 2015 год. [ на стр. 26-31 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Программная система дедуктивного логического вывода
- Прецедентный подход для оценки влияния молний на системы уличного освещения с использованием онтологий
- Облачная платформа IACPaaS для разработки оболочек интеллектуальных сервисов: состояние и перспективы развития
- Абдуктивный вывод versus дедукция
- Становление и развитие научной школы искусственного интеллекта в Московском энергетическом институте
Назад, к списку статей