Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Высокопроизводительный блок интерфейса RapidIO для создания многоядерных микропроцессоров с виртуальными каналами RapidIO
Аннотация:Одним из основных направлений повышения производительности вычислительных систем является создание многоядерных и многопроцессорных систем. Современные многопроцессорные системы, как правило, строятся на базе коммуникационных сред. К наиболее распространенным высокопроизводительным средам относятся сети HyperTransport, PCIExpress, ASI, RapidIO, VXS, StarFabric, Ethernet 10 Gb, InfiniBand, Myrinet. Коммуникационные среды создаются на внутрикристальном, модульном, межмодульном и межмашинном уровнях. Стандарт RapidIO ориентирован на создание трех последних сред и, таким образом, позволяет значительно унифицировать многопроцессорные системы. Для дальнейшей унификации с целью повышения надежности и снижения трудозатрат на разработку необходима унификация модуля обмена между ядром микропроцессора и внешней средой. В статье рассматривается унифицированный блок (блок RIO-AXI) перехода с внутрипроцессорной шины AXI на внешнюю шину RapidIO, позволяющий создавать как многоядерные процессоры, так и коммутаторы с коммуникационной средой RapidIO.
Abstract:One of the main methods of improving computing systems performance is the development of multi-core and multiprocessor systems. Modern multiprocessor systems are usually based on the communication environment. The most popular high-performance network environments are: HyperTransport, PCI Express, ASI, RapidIO, VXS, StarFabric, 10GB Ethernet, InfiniBand, Myrinet. A communication environment is created on chip level, module level, inter-module level and inter-machine level. The RapidIO standard is focused on creating the last three environments and thus we can unify a multiprocessor system. For further unification we need to develop the module of the exchange between the microprocessor’s core and the external environment in order to improve the reliability and reduce labor effort. The article discusses a unified adapter block (RIO-AXI) for a transition from on-chip AXI bus to the external RapidIO bus to create as multicore processors as well as switches with RapidIO environment. Chip production technology improvement and increase in the number of transistors in the chips until 2003 has led to permanent growth of microprocessor frequency up to 3–4 GHz. However, further increase in frequency has caused a substantial increase of power consumption and heat dissipation, which is impossible to withdraw from crystals using standard means. Increased productivity has been achieved by expenses on complicated architecture of microprocessor cores, additional functions, coprocessors and, most importantly, by creating multi-core microprocessors and multiprocessor systems. Therefore, a high-performance communication environment is emphasized. RapidIO communication environment is one of the most promising. The RapidIO standard is designed specifically to meet critical requirements of real-time applications, which are: low latency, determinism, reliability and scalability, reduction of power consumption, size and weight.
| Авторы: Козлов Н.А. (kozlov_n@cs.niisi.ras.ru) - ФНЦ НИИСИ РАН (младший научный сотрудник), Москва, Россия, Аспирант , Бобков С.Г. (bobkov@cs.niisi.ras.ru) - Научно-исследовательский институт системных исследований РАН, г. Москва (директор), г. Москва, Россия | |
| Ключевые слова: виртуальный канал, многоядерный процессор, rapidio, коммутатор |
|
| Keywords: virtual channel, multi-core processor, RapidIO, switch |
|
| Количество просмотров: 9752 |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
Основным показателем производительности вычислительной системы является производительность микропроцессора. Д. Паттерсон и Дж. Хеннесси [1] определили производительность микропроцессора как
Как видим, производительность зависит от трех характеристик: частоты, частоты на инструкцию и количества инструкций. Более того, время работы процессора (CPU) в равной степени зависит от каждой из них: увеличение на 10 % одной дает общий прирост тоже в 10 %. К сожалению, сложно изменить один из этих параметров отдельно от остальных, поскольку основные технологии, определяющие каждую характеристику, взаимозависимые: частота определяется технологией изготовления микропроцессора, частота на инструкцию – архитектурой микропроцессора, количество инструкций – системой команд и технологией компиляции. Улучшение технологических норм изготовления кристаллов микросхем и увеличение числа транзисторов в микросхемах примерно до 2003 г. тоже вызывало постоянный рост частоты микропроцессоров вплоть до 3–4 ГГц. Однако дальнейшее повышение частоты обусловило существенное повышение потребления питания и, соответственно, повышение тепловыделения, которое невозможно отвести от кристаллов стандартными средствами [2]. Повышение производительности стало достигаться за счет усложнения архитектуры ядра микропроцессора, включения дополнительных функ- ций, сопроцессоров и, главное, за счет создания многоядерных микропроцессоров и многопроцессорных систем [2]. В связи с этим на первый план стала выдвигаться задача создания высокоэффективной коммуникационной среды. Одной из наиболее перспективных сред является коммуникационная среда RapidIO (RIO). Стандарт RIO разрабатывался специально для удовлетворения важнейших требований приложений реального времени: обеспечения малых задержек, детерминизма, надежности и масштабируемости, снижения энергопотребления, размеров и веса, обусловленного требованиями встроенных систем. Высокие показатели по скорости передачи и надежности привели к тому, что RIO начинает использоваться и для построения серверов, прежде всего серверов с плотной упаковкой. Кроме того, стандарт RIO позволяет унифицировать коммуникационную среду на модульном, межмодульном и межмашинном уровнях [3], что существенно удешевляет систему и упрощает ПО. Для дальнейшей унификации и снижения затрат на разработку предложен блок (блок RIO-AXI) перехода с внутрипроцессорной шины AXI на внешнюю шину RIO, позволяющий создавать как многоядерные процессоры, так и коммутаторы с коммуникационной средой RIO. Унифицированный блок межпроцессорного обмена На рисунке 1 приведена структурная схема организации обмена процессорного ядра (ЦПУ) с внешней коммуникационной средой через каналы RIO. К процессорному ядру подключено оперативное запоминающее устройство (ОЗУ).
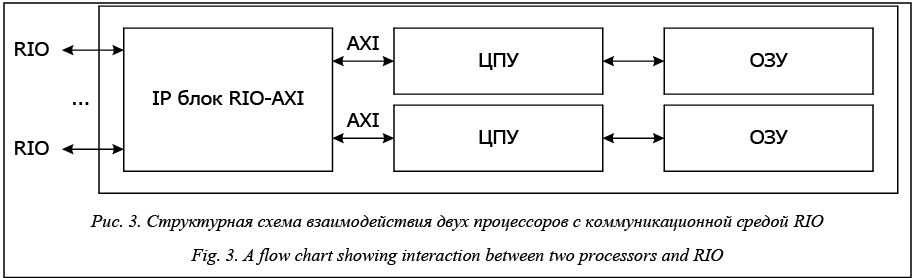
На рисунке 2 приведена структурная схема блока межпроцессорного обмена. Схема состоит из следующих основных блоков: порты RIO, блок коммутации RIO и блок преобразования пакета RIO в пакет AXI. Блок преобразования состоит из блоков приема запроса и выдачи ответа RIO, коммутатора запросов, блока регистров, контроллера шины AXI и еще трех контроллеров: контроллера дверных замков, почтовых ящиков (контроллер сообщений) и транзакций ввода-вывода RIO. Во время работы внешнее обращение поступает в порт RIO, далее пакет в зависимости от настроек таблицы маршрутизации передается в один из выходных портов. При обращении к процессору (попадании в порт 5) пакет RIO преобразуется в пакет AXI и затем поступает в процессор. С точки зрения программной модели, внутри микросхемы находится одно RIO-устройство. Решение задачи построения блока межпроцессорного обмена для двух ядер Одной из основных задач унификации среды является связь между двумя ядрами процессора на одном кристалле с сохранением доступа к периферийным устройствам (рис. 3). Рассмотрим характеристики, свойства и трудозатраты на реализацию блока межпроцессорного обмена для двух процессоров. Наиболее очевидными являются два варианта исполнения этого блока: подключение к одному порту RIO с использованием коммутатора AXI; подключение к порту RIO с созданием виртуальных каналов.
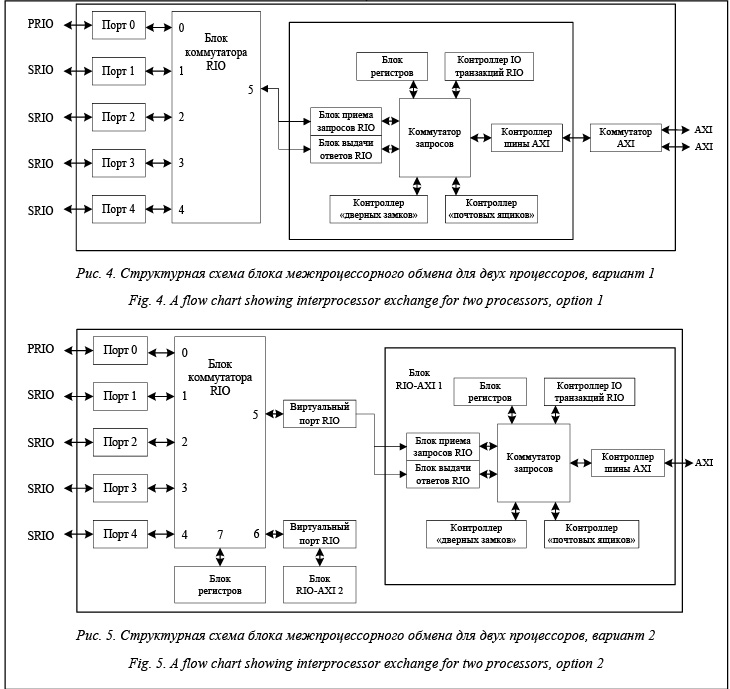
Первый вариант предполагает структуру, изображенную на рисунке 4. Рассмотрим затраты на разработку аппаратной части. Для реализации этой схемы необходимо разработать коммутатор AXI. Далее при работе с одним портом RIO нужно разделить пакеты между двумя процессорами. Это можно реализовать через разделение адресного пространства, через контроллер сообщений или тип пакета. Для такого разделения необходимо значительно изменить контроллер сообщений. На изменение программной части требуется значительное изменение работы с разделением адресного пространства с двумя процессорами, находящимися на одном порту RIO. К достоинствам такого подхода можно отнести отсутствие дублирования контроллеров, к недостаткам – появление дополнительной задержки при прохождении пакета через AXI-коммутатор по сравнению со схемой, по которой происходит взаимодействие с одним ядром.
Для реализации второго способа соединения процессоров (рис. 5) необходимо сделать следующие изменения аппаратной части: подключить блок регистров к блоку коммутации, незначительно изменить структуру блока регистров AXI, подключить второй блок преобразования пакета RIO в пакет AXI. В программной модели обозначенная структура будет определена как три устройства RIO, с каждым из которых можно работать независимо от другого: коммутатор RIO, блок RIO-AXI 1, блок RIO-AXI 2. При таком соедине- нии соблюдается преемственность кода, все име- ющиеся наработки с внесением незначительных изменений можно применить к новому блоку. Недостаток состоит в дублировании внутреннего содержания блока преобразования пакета RIO в AXI, достоинство – в сохранении задержки передачи на том же уровне, что и в унифицированном блоке с одним процессором. Как видим, реализация второго варианта не только менее трудозатратна, но и обладает меньшими задержками при передаче пакета, являющимися одним из основных параметров таких систем. Таким образом, при относительно небольшом числе ядер данное решение оптимально. Принятие разработчиком решения должно основываться на оптимизации трудоемкости проекта, производи- тельности, потребляемой мощности и числе транзисторов (площади) для данных вариантов. С учетом этих параметров выбран второй вариант. Рассмотрим выбранную схему соединения процессоров. Схема состоит из трех блоков (рис. 5). Первый блок – это 8-портовый коммутатор, к которому подсоединен 1 порт PRIO, 4 порта SRIO, блок регистров и 2 виртуальных порта RIO. К первому виртуальному порту подключен блок RIO-AXI 1, который состоит из коммутатора запросов AXI, блока приема запросов и выдачи ответов RIO, блока регистров и трех контроллеров: дверных замков, почтовых ящиков и транзакций ввода-вывода RIO. Блок RIO-AXI 2 полностью аналогичен блоку RIO-AXI 1. Опишем процесс передачи сообщения между процессорами, находящимися на одном кристалле. Примем, что таблица маршрутизации сконфигурирована. В начале передачи первый процессор, подключенный по AXI к блоку RIO-AXI 1, заполняет поля в блоке регистров. Во время этой операции в блок регистров AXI пишутся адрес, данные, тип пакета, возможное число переходов и другие служебные поля. После этого пакет поступает в блок преобразования из интерфейса AXI в интерфейс локальной шины. Затем пакет поступает в блок преобразования из локальной шины в интерфейс RIO – блок выдачи ответов RIO. После этой передачи пакет поступает на виртуальный канал RIO, а затем в 5-й порт коммутатора и передается в 6-й в соответствии с таблицей маршрутизации. После появления пакета на 6-м порту коммутатора описанная операция выполняется в обратном порядке, за исключением передачи данных из виртуального канала в блок приема ответов RIO и выхода пакета из блока RIO-AXI 2 на интерфейс AXI ко второму процессору. В случае передачи на соседний кристалл операция аналогична описанной, за исключением конфигурации таблицы маршрутизации. Структура ядра коммутатора Рассмотрим ядро коммутатора RIO. Коммутатор относится к классу коммутаторов со входной буферизацией [4] (Input-Queued Switch). Он может работать в двух режимах: приоритетной передачи пакетов и циклическом [5] (Round-robin). Если установлен циклический режим, то при передаче из нескольких входных портов N в один выходной пакеты передаются по очереди от порта n = 1 до N. Если коммутатор работает в режиме приоритетной передачи и несколько входных портов передают пакет в один выходной, то первым передается наиболее приоритетный пакет. Пакеты с равным приоритетом передаются в циклическом режиме. Поскольку рассматриваемый коммутатор относится к классу коммутаторов со входной буфериза- цией, существует проблема блокировки головного пакета (HoL, Head-of-Line) [6]. Она решена путем перемещения блокирующего пакета на случайное место в очереди. При этом перемещении выполняется также перемещение более приоритетных пакетов в начало очереди. Данная архитектура коммутатора является оптимальной благодаря простоте реализации и хорошим временным характеристикам, а именно, низкой задержке прохождения пакета и, как следствие, низким аппаратным затратам. Недостатком такого решения является отсутствие алгоритма, находящего максимальные паросочетания (MWM, MaximumWeightMatching) [7], из-за чего выходные порты ядра коммутатора могут простаивать, понижая максимальную пропускную способность в случае неравномерного распределения номера порта назначения и длины пакетов. Блок межпроцессорного обмена с интерфейсами RIO и AXI Как было показано ранее, данную схему IP блока RIO-AXI реализовать достаточно просто при наличии всех его составных частей. Рассмотрим достоинства созданного IP-блока. · Возможность использования стандартного интерфейса передачи сообщений (Message Passing Interface, MPI), позволяющего процессорам обмениваться сообщениями, параллельно выполняя одну задачу [8]. Основной механизм – передача сообщений между процессорами. · Низкая задержка передачи пакета. Задержка при передаче пакета между портами RIO, состоящая из задержки приемопередатчика (преобразование последовательного кода в параллельный 26 нс), преобразования в порту RIO (получение RIO-пакета из параллельного кода, одно преобразование 156 нс), буферизации во входных очередях (21 нс) и коммутации (14 нс) между портами, составляет 400 нс для технологии проектирования 250 нм. · Масштабируемость. Возможно соединение 5 кристаллов без дополнительных элементов (см. рис. 6). Chip означает отдельный кристалл, CPU – ядро одного процессора, Switch–IP – ядро RIO-AXI. При помощи дополнительных коммутаторов возможно соединение до 256 процессоров. Возможно соединение и более сложных многоядерных схем, например тороидальной сети (рис. 7).
· Совместимость с имеющимся ПО. Имеющиеся наработки ПО совместимы с этим IP-ядром, сохраняется модель контроллера передачи сообщений (message controller). · Однородность доступа к процессору на одном и нескольких кристаллах. Для программиста обращение к процессору на одном кристалле выглядит так же, как и обращение к другому кристаллу. · Дублирующий режим. В некоторых надежных системах существует требование выполнения операций процессорами в дублирующем режиме. Использование разработанного ядра позволяет поддерживать этот режим. · Возможность дальнейшего развития. При необходимости блок можно расширить, увеличив количество портов коммутатора. В результате увеличивается количество периферийных портов или виртуальных каналов RIO для подключения процессоров. Программные наработки при этом также сохраняются. После сборки и отладки проекта были проведены исследования временных параметров – измерение задержки при передаче пакетов от одного процессора к другому. Измерения задержки были выполнены на модели и составили порядка 400 нс. Полученные значения говорят о низкой задержке передачи пакета. С учетом поправки на рабочую тактовую частоту эта задержка сопоставима с задержкой, полученной авторами при тестировании многопроцессорного взаимодействия [9]. Таким образом, в результате проделанной работы определены возможные варианты создания унифицированных блоков каналов RIO, проведена оптимизация и разработан блок, обеспечивающий высокую производительность различных многопроцессорных систем. Литература 1. Patterson D.A., Hennessy J.L. Computer architecture: a quantitative approach. 4th ed. Morgan Kaufmann Publ. Elsevier Science (ref.), 2011, 676 p. 2. Бобков С.Г. Высокопроизводительные вычислительные системы. М.: Изд-во НИИСИ РАН, 2014. 299 с. 3. Бобков С.Г., Задябин С.О. Перспективные высокопроизводительные вычислительные системы промышленного применения на базе стандарта RapidIO // Электроника, микро- и наноэлектроника: сб. науч. тр. 11-й Рос. науч.-технич. конф. (2009, г. Н. Новгород); [под ред. В.Я. Стенина]. М.: Изд-во МИФИ, 2009. С. 114–121. 4. McKeown N., Mekkittiku A., Anantharam V., Walrand J. Transactions on Communications, Aug. 1999, vol. 47, no. 8, pp. 1260–1267. 5. Silberschatz A., Galvin P.B., Gagne G. Process Scheduling. Operating System Concepts (8th ed.). John Wiley & Sons Publ. (Asia), 2010, 194 p. 6. Bennett J.C.R., Partridge C., Shectman N. Packet reordering is not pathological network behavior. Dec. 1999, pp. 789–798. 7. Ерзин А.И. Введение в исследование операций: учеб. пособие. Новосибирск: Изд-во НГУ, 2006. С. 54–66. 8. Оленев Н.Н. Основы параллельного программирования в системе MPI. М.: Изд-во ВЦ РАН, 2005. 5 с. 9. Devashish P. Supercomputing Clusters with RapidIO Interconnect Fabric Ethernet Summit. 2015, April 14–16, 2015, p. 4. |
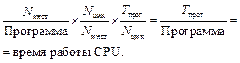



| Постоянный адрес статьи: http://swsys.ru/index.php?id=4074&like=1&page=article |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
| Статья опубликована в выпуске журнала № 4 за 2015 год. [ на стр. 87-92 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Алгоритм обеспечения исключительного доступа к коммутатору RapidIO
- Поддержка протокола MPI в ядре ОС Linux для многопроцессорных вычислительных комплексов на базе высокоскоростных каналов RapidIO
- Тестирование памяти в многопроцессорных системах
- Способы инициализации многопроцессорной системы
- Способы повышения эффективности отладки и тестирования многопроцессорных систем
Назад, к списку статей