Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Препроцессорная обработка множеств прецедентов для построения решающих функций в задачах классификации
Аннотация:Рассмотрена актуальная проблема наличия ошибок в обучающих выборках, предназначенных для последующего построения по методу прецедентов решающих функций, используемых в задачах классификации новых объектов. Исследованы основные причины возникновения данных ошибок и их влияние на построение классификаторов. На основе геометрической интерпретации задачи классификации предложены методы, позволяющие не только анализировать качество обучающей выборки, но и выявлять возможные причины ошибок, содержащихся в ней, а также выполнять их коррекцию, необходимую для последующего построения эффективного классификатора. Для численного учета общих долей удаляемых и корректируемых выбросов в обучающей выборке предложено использовать соответствующие предельно допустимые пороговые величины. По ним даны рекомендации для основных предметных областей. В алгоритме анализа прецедентов использована специальная мера близости одиночного объекта к произвольному классу, аналогичная методу ближайшего соседа, но с той разницей, что соседство определяется не по одной ближайшей точке, а по нескольким. Сложность предложенных алгоритмов анализа и коррекции обучающих выборок является полиномиальной по числу точек в обучающей выборке: в первом случае квадратичная, во втором линейная. Получаемая в результате коррекции новая обучающая выборка задает более плавные границы классов в пространстве значений признаков. Вследствие этого данные множества точек в большей степени удовлетворяют гипотезе компактности и в результате дают решающие функции с более простой структурой, требующие затем меньше вычислительных операций на решение задачи классификации.
Abstract:The article considers an important problem of errors in learning samples for subsequent construction using the method of solving functions precedents in problems of new objects classification. The paper researches the main causes of these errors and their impact on the construction of classifiers. Based on the geometric interpretation of a classification problem the authors propose methods to not only analyze the quality of a training sample, but also identify possible causes of the errors contained in it, as well as perform their correction required for the subsequent construction of an effective classifier. For numerical accounting of common emission lobes, which must be removed and corrected in a learning sample, the authors propose using the corresponding maximum allowable threshold values. There are some recommendations for the main subject areas. The algorithm of precedent analysis uses a special measure of single object proximity to an arbitrary class. It is similar to the method of the nearest neighbor with the difference that neighborhood is determined by not a nearest point but several points. The complexity of the proposed algorithms for analysis and correction of training sets is polynomial according to the number of points in the the learning sample. In the first case it is quadratic, in the second case it is linear. A new corrected training set sets smoother class boundaries in the space of characteristic values. Consequently, the data set of points to a greater extent satisfy the compactness hypothesis and give decision functions with a simpler structure, which requires less computing operations to solve the problem of classification.
| Авторы: Гданский Н.И. (al-kp@mail.ru) - Московский политехнический университет (профессор), Москва, Россия, доктор технических наук, Куликова Н.Л. (kulikovanl@mpei.ru) - Национальный исследовательский университет «Московский энергетический институт» (доцент), Москва, Россия, кандидат технических наук, Крашенинников А.М. (lifehouse@list.ru) - Российский государственный социальный университет (старший преподаватель), Москва, Россия | |
| Ключевые слова: коррекция, анализ, ошибочные данные, прецедент, обучающая выборка, решающая функция, классификатор, задача классификации |
|
| Keywords: correction, analysis, erroneous data, precedent, learning sample, decision function, classifier, classification problem |
|
| Количество просмотров: 10120 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
В последнее время интенсивно развивается группа методов под общим названием Data Mining, ориентированных прежде всего на обработку массивов данных значительного размера, содержащих информацию об интересующих объектах, с целью извлечения из них сведений требуемого вида [1, 2]. Как правило, на первом этапе исследования выделяемых объектов решается задача классификации, в которой каждый такой экземпляр должен быть отнесен к какому-либо из уже известных непересекающихся классов объектов Ai из общей совокупности {A} = {A1, A2, …, Ak}. Обычно индивидуальные свойства исследуемых объектов выражают через значения их существенных характерных числовых признаков: Наряду с задачей формирования адекватного набора признаков Обработка зашумленных данных является многогранной проблемой, решаемой как в статисти- ческих методах, так и в задачах искусственного интеллекта. Предварительный анализ экспериментальных данных, имеющих вид случайной величины, сделан в [5, 6]. В работе [7] рассматриваются вопросы моделирования рассуждений на основе прецедентов и классификации в условиях таких данных в интеллектуальных системах поддержки принятия решений. В работах [8, 9] представлено несколько расчетных схем, позволяющих выделять детерминированные компоненты из временных рядов с аддитивной хаотической погрешностью. В данной статье предлагаются методы, позволяющие на основе геометрической интерпретации задачи классификации не только проанализировать качество обучающей выборки, но и выявить возможные причины ошибок, содержащихся в ней, выполнить их коррекцию, необходимую для построения эффективного классификатора. В задаче классификации объект должен быть отнесен к какому-либо из уже известных непересекающихся классов объектов, входящих в их совокупность {A} = {A1, A2, …, Ak}. Смысловой вариант определения задачи классификации нового, ранее неизвестного объекта
Ответом в задаче является номер i класса Ai, в который включается объект µ : В реальных задачах для заданной совокупности классов {A} решающая функция m формируется на основе обучения – обработки набора прецедентов (обучающей выборки) [7, 10] – совокупности пар вида Р = {рs} = {( Одним из необходимых условий успешного применения геометрического подхода к построению классификатора, основанного на соответствующей интерпретации пространства признаков U, является выполнение гипотезы компактности, по которой отдельным классам {А}, содержащим близкие по свойствам объекты, в геометрическом пространстве значений признаков U соответствуют обособленные непересекающиеся сгустки (классы), которые могут быть разделены в пространстве U достаточно простыми гиперповерхностями. Допустим, требуется разработать автоматический классификатор µ, решающий задачу (2) на основании обучающей выборки Р, представляющей собой набор проб, образцов с определенной ка- кими-либо методами из предметной области их принадлежностью к классам {А}. Ошибки в выде- лении набора числовых признаков Вспомогательные обозначения. Постановка задачи Для численного учета общей доли выбросов в выборке Р предложено использовать две пороговые величины: d0 – предельно допустимая доля удаляемых выбросов, при которой можно без ущерба для общей информативности выборки Р удалить из нее все выбросы; d1 – предельно допустимая доля корректируемых выбросов, при превышении которой выборку Р уже нельзя считать достаточно информативной для решения задачи (1)–(2). Поскольку объемы NN обучающих выборок и цели классификации существенно различаются для задач из разных предметных областей, к заданию пороговых величин d0 и d1 следует применять дифференцированный подход. Например, при NN » n×102¸ n×103 (1 £ n £ 9) в задачах дефектоскопии, обработки кадастровых и геологических данных предельно допустимое число отбрасываемых прецедентов можно принять равным n ¸ 10n, d0 = 0,01, а предельно допустимую долю ошибок d1 = (20¸30)d0 = 0,2¸0,3. При NN » n×105¸n×106 в задачах классификации компонентов тканей организмов (биотехнология, медицина) d0 = 0,001, d1 = (30¸50)d0 = 0,03¸0,05. При наличии выбросов в Р, помимо неадекватного отображения реальной картины, построение классификатора приводит к следующим негативным последствиям: - практическая невозможность полного разделения набора прецедентов по заданной совокупности классов {A}, что характерно для нейросетевых методов классификации; - слишком сложная структура классификатора, получаемого в более универсальных методах, полностью решающих задачу разделения классов. Для предотвращения данных ситуаций наиболее приемлемы либо повторное аппаратно-программное исследование реальной системы (что зачастую сложно либо вообще невозможно выполнить), либо препроцессорный анализ обучающей выборки Р с целью обнаружения выбросов с после- дующей коррекцией Р с учетом обеих основных причин возникновения выбросов – выделения набора адекватных числовых признаков Рассмотрим один из возможных путей практической реализации автоматической препроцессорной обработки обучающей выборки. Анализ прецедентов Допустим, некий объект из обучающей выборки Р задан точкой Для этого предложено использовать специальную меру R( R( + r( где 1£ j1< j2< … < js £ Nq; С целью сокращения общего числа операций при расчете минимума в расстоянии R( В том случае, когда точка R( R( При этом для всех Aq ¹ Af R( В практических расчетах минимум (или очень близкая к нему величина) в формуле (4) может достигаться не на одном классе: наряду с классом Af такая же степень близости R может достигаться и на другом классе из совокупности {A}. При этом в зависимости от последовательности анализа, а также погрешности вычислений возможно приня- тие другого класса, отличного от Af, в качестве бли- жайшего к Mk = min{R( R( где ε – достаточно малое вещественное число. При таком определении все классы равноправны при определении их близости к точке Поскольку включение объекта - квадрат евклидова расстояния e=(0,05¸0,1)n; - евклидово расстояние e=(0,2¸0,3)n; - манхэттенское расстояние e=(0,3¸0,5)n. (7) При выполнении условий (6)–(7) начальный вариант включения Соотношения (6)–(7) позволяют разработать на их основе алгоритм анализа обучающей выборки для последующего построения классификатора для совокупности классов {A}={A1, A2, …, Ak}. Он заключается в последовательном переборе всех прецедентов рs = ( В двух выходных целочисленных массивах алгоритма анализа NV и NCOR соответственно запоминаются номера s выбросов в обучающей выборке Р и номера корректирующих классов для них. Параллельно с формированием массивов NV и NCOR рассчитывается доля ошибочных начальных присвоений объектов классам (выбросов), которую обозначим через d. Выяснение принципиальной возможности кор- рекции выборки P производится путем проверки условия d £ d1, (8) где d1 – введенная выше предельно допустимая доля корректируемых выбросов. Приведем алгоритм анализа обучающей выборки, в котором применяется матрица расстояний между точками М(NN ´ NN). Исходные данные алгоритма: - число k выделенных классов в пространстве значений признаков; - массив N(k) чисел объектов в классах {N1, N2, …, Nk}; - количество s ближайших точек в классе Ak к точке - NN – общий объем обучающей выборки P; - n – число характерных признаков объектов; - массив Pr(NN´n) координат точек - массив Ncl(NN) классов объектов из P; - e – коэффициент запаса при проверке расстояний; - d1 (delta1) – предельно допустимая доля корректируемых выбросов. Решаемая задача: анализ выбросов в обучающей выборке. Выходные данные: - COR – логическая переменная, равная true, если коррекция P возможна, и false – иначе; - общее число Nв выбросов в обучающей выборке; - доля d (delta) выбросов в обучающей выборке; - массив NV (Nв) номеров выбросов в обучающей выборке; - массив NCOR(Nв) номеров корректирующих классов для выбросов в обучающей выборке. В описании алгоритма номера прецедентов обозначены через No, классов – через Nc. Описание алгоритма анализа обучающей выборки Начальные присваивания. Nв := 0; //Начальное значение числа выбросов Для No от 1 до NN { // Расчет элементов матрицы расстояний М М[No][No]:=0; для i от 1 до n { PR_No[i]:= Pr[No][i];}; для j от No+1 до NN{ для i от 1 до n { PR_j[i]:= Pr[j][i];}; М[No][ j]:= RO(n, PR_No, PR_j)М[i][No];}}; М[j][No] :=М[No][ j]; }; }; first[1]:=1; last[1]:=N[1];// Формирование массивов границ классов для Nc от 2 до k {first[Nc]:=last[Nc -1]+1; last[Nc]:= = last[Nc -1]+N[Nc];} Шаг 1. Проход по прецедентам, определение выбросов. Для No от 1 до NN { для Nc от 1 до k {//1.1.Проход по классам, расчет расстояний R(`aNo, ANc) {min:= М[No][first[Nc]];max:=min;//1.1.1.Расчет min и max расстояний для i от (first[Nc] +1) до last[Nc] {el:=М[No][i];если (elmax){max:= el;}}; }; L:=(max - min); del:=0,001*L;//1.1.2.Инициализация и расчет элементов V для i от 1 до 1000 { V[i] :=0;}; для i от first[Nc] до last[Nc] {num:=1000*( М[No][i] - min)/L; если (М[No][i] – min - del*num>0.5){num:=num+1;};V[num]:=V[num]+1; }; RO[Nc] :=0; def_s:=s; //1.1.3.Инициализация и расчет расстояния RO[Nc] для ind от 1 до 1000 { если (V[ind]>0) {val:= min + del×ind; если (def_s ³ V[ind]){num:= V[ind]; def_s:= def_s - V[ind];} иначе {num:= def_s; def_s:=0;} ; RO[Nc] := RO[Nc] + num*val; если (def_s =0){ break;}; }; }; };//Завершение прохода по классам, расчет всех расстояний до них RO[Nc] Mk:=RO[1];Nmin:=1;//1.2.Проход по классам, расчет минимума Mk и Nmin для Nc от 2 до k { если (Mk < RO[Nc]) { Mk:= RO[Nc]; Nmin:= Nc;}; }; Est:=(1+e)* Mk;//1.3.Проверка выброса, заполнение массивов NV, NCOR если (RO[Ncl[Nо]] < Est) {continue;} иначе { Nв:= Nв +1; NV[Nв]:= Nо; NCOR[Nв]:= Nmin;}; }; //Завершение Шага 1 Шаг 2. Расчет коэффициента delta: delta:= Nв / NN. Шаг 3. Определение возможности коррекции выборки: COR:=true; если (delta > delta1){COR:=false;}. Завершение работы алгоритма. Если в результате анализа выборки получено значение COR = false, необходима коррекция набора признаков Если же выполнено условие COR=true, можно считать, что в этом случае числовые признаки Оценим сложность алгоритма анализа обучающей выборки. Сложность расчета расстояний r( Коррекция обучающей выборки Предложен алгоритм коррекции обучающей выборки, учитывающий результаты анализа – долю выбросов d в Р, массивы NV и NCOR. Предварительно производится проверка условия d < d0. (9) Если оно выполнено, можно считать, что выбросы оставляют малую долю от общего числа прецедентов. В простейшем случае выбросы просто удаляются из обучающей выборки Р. Учитывая их малое число, возможен также их индивидуальный человеко-машинный анализ. Если условие (9) не выполнено, доля выбросов достаточно велика. При их отбрасывании будет потеряна значительная часть исходной информации. Вручную проанализировать их также затруднительно из-за большого объема. Поэтому в качестве реального выхода предлагается автоматизированная коррекция выбросов, отмеченных в массиве NV. Для каждого выброса ошибочный прецедент ( Приведем алгоритм коррекции обучающей выборки. Исходные данные алгоритма: - n – число характерных признаков объектов; - число классов k; - NN – общий объем обучающей выборки P; - массив Pr(NN´n) координат точек - массив Ncl(NN) классов объектов из P; - d0 (delta0) – предельно допустимая доля удаляемых выбросов; - общее число Nв выбросов в обучающей выборке; - доля d (delta) выбросов в обучающей выборке; - массив NV размерности Nв номеров выбросов в обучающей выборке; - массив NCOR размерности Nв номеров корректирующих классов для выбросов в обучающей выборке. Решаемая задача: коррекция выбросов в обучающей выборке. Выходные данные: - NNN – общий объем новой скорректированной обучающей выборки; - новый массив PrN (NNN´n) координат точек - новый массив NclN(NNN) классов объектов из скорректированной обучающей выборки. В описании алгоритма номера прецедентов обозначены через No, классов – через Nc. Начальные присваивания. NNN:=0. Шаг 1. Удаление выбросов. Если (delta £ delta0) {NoN:=1; для No от 1 до NN {Если (Ncl[No]¹NV[NоN]) {NNN:=NNN +1; NclN(NNN):=Ncl[No]; для i от 1 до n {PrN [NNN][i]:= Pr [N][i] ;} } иначе{NоN:=NоN +1;} } }; return; Шаг 2. Коррекция выбросов. NoN:=1; для No от 1 до NN { для i от 1 до n {PrN [No][i]:= Pr [No][i]; } если (Ncl[No]¹NV[NоN]) {NclN(No):=Ncl[No];} иначе{NоN:=NоN +1; NclN(No):=NCOR[No];}; }; NNN:=NN; return; Завершение работы алгоритма. Сложность алгоритма коррекции обучающих выборок оценивается величиной О(NN). Получаемая в результате коррекции обучающая выборка Р задает более плавные границы классов {А} в пространстве значений признаков, в результате чего данные множества точек в большей степени удовлетворяют гипотезе компактности. Помимо устранения противоречивости входной информации, коррекция существенно упрощает отделимость классов, то есть построение решающей функции с более простой структурой обусловливает сокращение количества вычислительных операций на решение задачи классификации (1)–(2). В заключение отметим, что предлагаемые алгоритмы анализа и коррекции обучающих выборок позволяют выявить причины противоречивости получаемой исходной информации и эффективно с вычислительной точки зрения устранить ее. Сложность алгоритма анализа квадратична по объему выборки, сложность алгоритма коррекции линейна. При необходимости алгоритмы могут быть использованы для ручного контроля уже найденных выбросов, освобождая пользователя от большого объема рутинной работы. Необходимая дополнительная настройка алгоритмов путем задания в них оптимального числа s ближайших точек при расчете расстояния от объекта до класса, а также величин коэффициентов e, d0, d1 должна учитывать метрику пространства значений признаков U и специфику класса решаемых задач. Изменение этих величин позволяет с использованием предлагаемых алгоритмов автоматически получать различные варианты обучающих выборок и соответствующих классификаторов. Из них можно выбирать оптимальные по тем или иным критериям. Выполненные на конкретных выборках расчеты позволили эффективно устранить в них выбросы и значительно упростить построение классификаторов в виде бинарных деревьев с разделяющими гиперплоскостями. Массовое практическое применение предлагаемого подхода в конкретных предметных областях (психология и социология, медицина и биотехнология, экология, материаловедение и др.) поможет не только выработать соответствующие рекомендации по выбору величин {s, e, d0, d1}, обеспечивающих построение оптимальных классификаторов, но и, возможно, создать его специализированные модификации. Литература 1. Барсегян А., Куприянов М., Холод И., Тесс М., Елизаров С. Анализ данных и процессов. СПб: БХВ-Петербург, 2009. 512 с. 2. Witten I.H., Frank E. Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann Publ., 2005, 524 p. 3. Гданский Н.И., Крашенинников А.М., Рысин М.Л. Построение сложных классификаторов для объектов в многомерных пространствах // Инженерный вестник Дона, 2013. № 2; URL: http://ivdon.ru/ru/magazine/archive/n2y2013/1611 (дата обращения: 08.09.2015). 4. Гданский Н.И., Крашенинников А.М. Общий метод построения кусочно-линейной разделяющей поверхности для множеств объектов, заданных точками в пространстве // Изв. МГТУ МАМИ. 2013. Т. 4. № 1 (15). С. 165–171. 5. Мандель И.Д. Кластерный анализ. М.: Финансы и статистика, 1988. 176 с. 6. Hastie T., Tibshirani R., Friedman J.H. The elements of statistical learning: Data mining, inference, and prediction. NY: Springer Verlag, 2001, 738 p. 7. Варшавский П.Р., Еремеев А.П. Моделирование рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений // Искусственный интеллект и принятие решений. 2009. № 2. С. 45–57. 8. Крянев А.В., Лукин Г.В. Математические методы обработки неопределенных данных. М.: Наука, 2006. 308 с. 9. Выделение детерминированных компонент из зашумленных данных. URL: http://do.gendocs.ru/docs/index-241588.html (дата обращения: 08.09.2015). 10. Вапник В.Н. Восстановление зависимостей по эмпирическим данным. М.: Наука, 1979. 448 с. |
 = {х1, х2, …, хn}. При этом каждому исследуемому объекту с номером s взаимно-однозначно соответствует своя точка
= {х1, х2, …, хn}. При этом каждому исследуемому объекту с номером s взаимно-однозначно соответствует своя точка  = = {a1s, a2s, …, ans} в n-мерном пространстве значений признаков U, на котором введена некоторая мера r. Такой подход позволяет геометрически иллюстрировать методы классификации в n-мерных метрических пространствах. В частности, в работах [3, 4] для построения классификатора предложено использовать специальное бинарное дерево решений, у которого в качестве узловых правил используются гиперплоскости в U, нормальные к межцентровым векторам разделяемых множеств.
= = {a1s, a2s, …, ans} в n-мерном пространстве значений признаков U, на котором введена некоторая мера r. Такой подход позволяет геометрически иллюстрировать методы классификации в n-мерных метрических пространствах. В частности, в работах [3, 4] для построения классификатора предложено использовать специальное бинарное дерево решений, у которого в качестве узловых правил используются гиперплоскости в U, нормальные к межцентровым векторам разделяемых множеств. ÎU относительно выделенной на U совокупности классов {A} заключается в выяснении включения
ÎU относительно выделенной на U совокупности классов {A} заключается в выяснении включения  ® {A}. (2)
® {A}. (2) cls)}, где
cls)}, где  , которая изначально включена в класс Af Ì {A}. Требуется проверить правомерность включения точки
, которая изначально включена в класс Af Ì {A}. Требуется проверить правомерность включения точки  ) + r(
) + r( ) +…
) +… )}, (3)
)}, (3) ¹
¹ 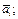 (r = 1, …, s).
(r = 1, …, s).
 ) с точностью до 0,05 % с кодированием их целыми числами от 0 до 1 000, которые используются в качестве индексов вспомогательного линейного массива V(1001). Для быстрого выполнения такого упорядочения надо использовать блочную (карманную, корзинную) сортировку.
) с точностью до 0,05 % с кодированием их целыми числами от 0 до 1 000, которые используются в качестве индексов вспомогательного линейного массива V(1001). Для быстрого выполнения такого упорядочения надо использовать блочную (карманную, корзинную) сортировку.
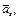 cls), для каждого из которых вначале рассчитываются все расстояния {R(
cls), для каждого из которых вначале рассчитываются все расстояния {R(
| Постоянный адрес статьи: http://swsys.ru/index.php?id=4146&like=1&page=article |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
| Статья опубликована в выпуске журнала № 2 за 2016 год. [ на стр. 41-46 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Система назначения персонифицированного лечения по аналогии на основе гибридного способа извлечения прецедентов
- Алгоритм анализа трафика в корпоративных компьютерных сетях на основе статистики экстремальных значений
- Логический анализ корректирующих операций для построения качественного алгоритма распознавания
- Основы структурно-лингвистического подхода в анализе нечетких временных рядов
- Программа расчета пропускной способности гибких производственных ячеек
Назад, к списку статей