Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Методы автоматического построения онтологий
Аннотация:В статье рассматривается процесс автоматического построения онтологии предметной области по входному набору текстовых документов. В частности, рассматриваются процессы, аналогичные системам Biperpedia, BOEMIE Project и т.п. В работе освещены основные этапы автоматической генерации онтологии, а именно процесс извлечения объектов предметной области, концептов, то есть терминов, объединяющих множество объектов, а также процесс извлечения семантических отношений и правил для онтологии. Для каждого процесса представлены алгоритмы, решающие задачу соответствующего шага генерации онтологии. В рамках процесса извлечения объектов предметной области рассмотрены алгоритмы извлечения именованных сущностей, генерации регулярных выражений на основе генетических алгоритмов. Предложен процесс построения шаблонов извлечения объектов на базе методов поиска частотных цепочек символов по аналогии с поиском частотных шаблонов последовательностей. В статье описаны основные шаги извлечения концептов предметной области и рассмотрены алгоритмы для определения его основных атрибутов. Содержится описание методов извлечения семантических отношений на базе лексико-синтаксических шаблонов. Предложен подход к данной задаче с точки зрения поиска ассоциативных правил по аналогии с алгоритмами поиска частотных шаблонов. Наконец, в работе предложены три метода оценки качества работы всего процесса автоматического построения онтологии: метод на основе золотого стандарта, метод ручной оценки и косвенный метод через оценку качества использующего онтологию ПО. Рассмотрены положительные и отрицательные стороны того или иного метода оценки. Предложен компромиссный подход для оценки качества модели, учитывающий достоинства и недостатки каждого из описанных.
Abstract:The article describes an automatic domain ontology generation process using input text corpora. In particular, it describes the processes similar to Biperpedia, BOEMIE Project systems, etc. This paper includes a description of basic steps of automatic ontology construction, specifically a domain-object extraction process, concept (i.e. terms that combine an object set) extraction process, as well as the process of semantic relations and rules extraction. This paper reviews algorithms for each steps of an ontology construction process. There is a named entity recognition task and regular expression generation based on a genetic programming approach for a domain-object extraction process. The authors propose an idea of using a sequential pattern mining approach for term sequences extraction for an object identification process. The paper contains a description of basic steps of a concept extraction task and a review of a concept attributes extraction task. The article also describes a lexico-syntactic pattern approach for a domain semantic relation extraction process. The authors propose an approach to this task based on association rules mining like in a frequent pattern mining approach. The paper includes three methods of ontology learning evaluation, specifically: a golden sample method, a human evaluation method and an indirect method using client-application evaluation. The paper describes positive and negative aspects of each method and proposes a compromise to estimate the quality of a model.
| Авторы: Платонов А.В. (avplatonov@corp.ifmo.ru) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (Университет ИТМО) (аспирант), Санкт-Петербург, Россия, Полещук Е.А. (eapoleschuk@corp.ifmo.ru) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (Университет ИТМО) (аспирант), Санкт-Петербург, Россия | |
| Ключевые слова: извлечение семантических отношений, извлечение именованных сущностей, онтология |
|
| Keywords: semantic relation extraction, named entity recognition, ontology |
|
| Количество просмотров: 12602 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
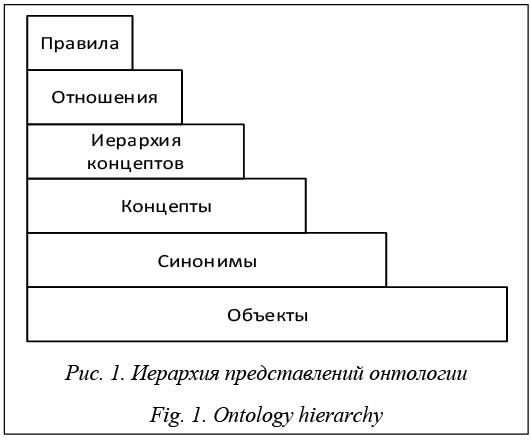
Онтологии наравне с семантическими сетями представляют собой удобную абстракцию для отображения знаний в некоторой предметной области [1]. Однако процесс составления такой структуры данных очень трудоемок, так как требует от составляющего ее человека непредвзятости в суждениях относительно предметной области, а также внимания к мелочам, чтобы не допустить неточ- ностей и противоречий в получаемой базе знаний. Неудивительно, что в машинном обучении становится популярной задача так называемого обу- чения онтологии (Ontology Learning) – задача автоматического построения онтологии предметной области по некоторой обучающей выборке. Автоматическое построение онтологий по некоторому набору текстовых документов пол- ностью определено концептуальной структурой самой онтологии. Это процесс, состоящий из нескольких этапов, на каждом из которых проис- ходит извлечение из текста фактов или их пост- обработка для формирования какой-то части онтологии, будь то термины или объекты, концепты или же отношения между ними. На рисунке 1 показана иерархия представлений онтологии, на основе которой она и строится [2].
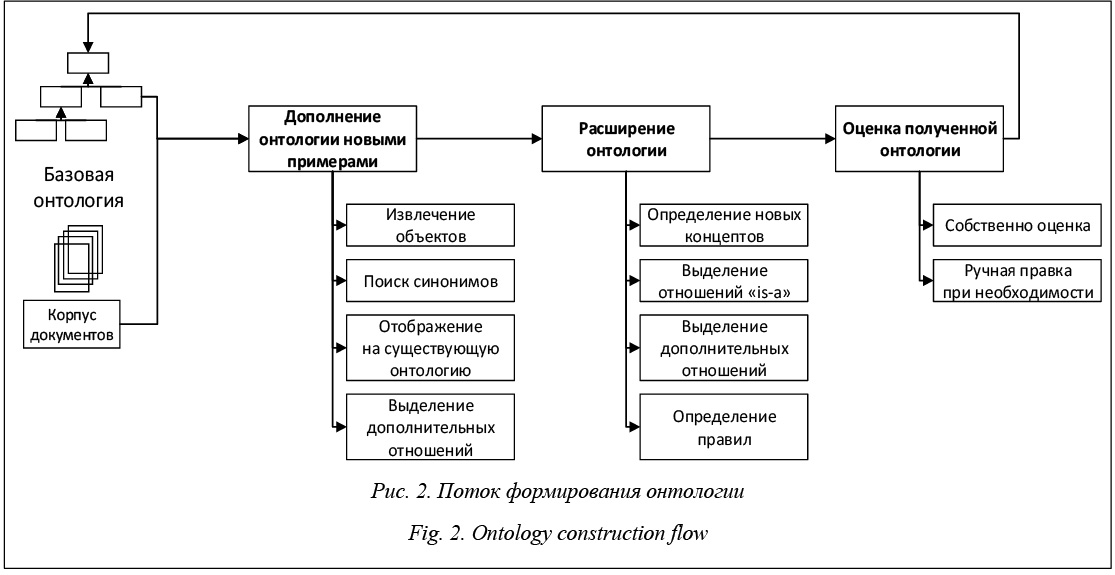
Поясним, почему иерархия выглядит именно так. В основе онтологии лежат концепты и соответствующие им объекты. Объекты, которые представляют собой конкретные примеры концептов, являются фундаментом для объединения их в один концепт как родительский узел в иерархии онтологии. Прежде чем выделять собственно концепты, объекты следует исследовать на наличие между ними синонимии или кореферентности, если мы говорим об извлечении подобных знаний из текстовых документов. Полученные кластеры синонимов могут абстрагироваться до концептов с указанием отношения «is-a» между объектом и концептом. Важными элементами онтологии являются собственно иерархия концептов и дополнительные отношения между ними. Иерархия строится на базе отношения типа «is-a», а дополнительные бинарные отношения позволяют указывать дополнительную семантику в онтологии. Набор правил внутри онтологии представляет собой надстройку над всеми основными компонентами онтологии и в простейшем виде формируется уже у интерпрета- тора онтологии (например у человека), представляя собой набор высказываний наподобие «если X является автором программы Y, то X написал код Z программы Y». В соответствии с этой структурой организован процесс генерации онтологии на основе множества документов, состоящий из следующих этапов [3]: идентификация и извлечение объектов, кластеризация объектов на группы синонимичных объектов, поиск соответствия кластеров существующим концептам или генерация нового концепта, выделение отношений наследования между концептами, выделение вспомогательных отношений и определение правил на получившейся онтологии. Необходимо понимать, что при составлении онтологии в автоматическом или полуавтоматическом режиме очень важен процесс оценки результатов работы алгоритмов. Все этапы формирования онтологии вместе с ее оценкой можно свести к схеме, представленной на рисунке 2 [2]. Обратите внимание на цикличность алгоритма: исходная, возможно, пустая онтология дополняется новыми объектами, концептами и отношениями, оценивается и затем уже используется как база для дальнейшего расширения. Такой подход часто используется [2, 4, 5] и позволяет извлечь максимум информации из входного корпуса документов. Извлечение объектов Процесс извлечения объектов из текстовых документов для пополнения онтологии может быть разделен на два этапа.
2. Отображение полученных объектов на известные словари и базы знаний для определения их концепта. Объекты, которые не были отнесены ни к одному из имеющихся концептов, могут стать кандидатами на новые концепты в шаге расширения онтологии. Для второго этапа работы алгоритма полезно применять словари синонимов, алгоритмы разрешения кореферентности и алгоритмы поиска с опечатками в словарях. Так, например, в работе [4] в качестве такого словаря используется Wikipedia, а алгоритм разрешения синонимии основан на полученном ранее онтологическом графе и исходит из того, что слова, применяемые в одном контексте, будут иметь более короткие пути в онтологическом графе. Таким образом, если в анализируемом тексте встречается объект с несколькими значениями, алгоритм находит их все в онтологическом графе и от каждой найденной вершины строит пути до вершин, соответствующих терминам и объектам в окружающем исходный объект тексте. Среди полученных подграфов выбирается граф с минимальным диаметром, и именно из него выбирается термин для разрешения синонимии. Первый этап извлечения объектов можно выполнить несколькими способами. Среди наиболее популярных выделим несколько групп. Первая группа алгоритмов – статистические методы извлечения именованных сущностей. Примером может служить работа [6]. Изначальная постановка задачи звучит следующим образом: исходная строка подвергается токенизации, и далее производится классификация цепочек символов. Данный подход описан в [7], и для его реализации используются факторы, основанные на n-граммах, а также на свойствах символов в извлекаемой строке (их регистр, наличие знаков препинания и т.п.). Среди открытых библиотек можно выделить [8, 9]. Вторая группа – методы, основанные на грамматиках. Наиболее простым и близким примером являются регулярные выражения [10], с помощью которых можно извлекать довольно сложные цепочки символов, представляющих собой, например, дату и время, телефон, URL и т.п. Более сложным примером использования грамматик для задач извлечения объектов может служить недавно разработанный продукт [11]. Основным преимуществом методов данной группы является то, что грамматика – это человекочитаемый текстовый документ, который легко понимать, расширять и исправлять при наличии ошибок извлечения, в отличие от методов первой группы, в которых единственный источник изменения их поведения – изменение обучающей выборки. Однако грамматики чаще всего составляются вручную, что затрудняет их использование при необходимости извлекать множество разнотипных объектов. Логично, что в связи с этим появляется множество методов генерации грамматик. В частности, для регулярных выражений используются генетические алгоритмы [12, 13], методы, основанные на словарях шаблонов [14]. Однако анализ данных работ показывает, что данные методы пока подходят лишь для узкого круга задач. Так, например, в работе [14] алгоритм используется для увеличения точности уже существующего шаблона, а в работах [12, 13] используется узкий круг примеров (телефоны и URL) с обучающими выборками, смещенными в сторону простых однотипных объектов. В третью группу можно объединить методы, основанные на извлечении часто встречающихся цепочек токенов. К группе таких методов можно отнести алгоритмы наподобие GSP [15], Prefix- Span [16] или SPAM [17]. Каждый объект в обучающей выборке можно представить в виде последовательности токенов, причем каждый токен может сопровождаться дополнительными тэгами, обозначающими часть речи, морфологические характеристики слова. Такое описание токена вместе с его тэгами можно объединить в множество, которое в терминах Frequent Pattern Mining называется транзакцией, тогда вся цепочка токенов, преобразованная таким образом, может рассматриваться с позиции как раз алгоритмов Sequential Pattern Mining [15–17]. Применяя эти алгоритмы к преобразованным обучающим примерам, в качестве результата можно получить частотные шаблоны, которые затем напрямую преобразовать в грамматики и уточнить, например, методом, описанным в [14]. Отличительной особенностью данных методов является их гибкость: достаточно добавить несколько классов тэгов, чтобы расширить возможности такого анализа. Так, например, добавив к терму часть речи, род, падеж, число, составляющие его классы символов [10], названия словарей, в которых он встречается, и список синонимов, можно перейти из плоскости только лексического анализа в морфологический и графематический анализ. Определение концептов Несмотря на то, что задача определения концептов является важнейшей в процессе построения онтологии, количество работ, посвященных данной тематике, незначительно [2]. Согласно [3], определение концептов состоит из следующих двух этапов: извлечение определения концепта и извлечение множества объектов концепта. Определение концепта можно сформулировать в двух формах: информирующее определение, то есть текстовое, человекочитаемое определение некоторого термина (как, например, в толковых словарях), и вспомогательное определение – множество синонимов концепта, шаблоны извлечения его объектов, то есть все то, что позволит определить концепт как кластер объектов с множеством правил, объединяющих их. Информирующее определение можно сформировать, определив найденный концепт как синоним существующего, и сослаться на статью в толковом словаре, или как в [18]. Множество объектов концепта определяется на этапе извлечения объектов при наличии собственно концепта в текущей онтологии и его вспомогательного описания. В работе [5] используется дополнительный способ вспомогательного описания в виде примеров текстов, в которых встречается концепт. Такие примеры использования концепта в текстах полезны с точки зрения гипотезы Хариса [19] и позволяют найти часто встречающиеся термины и фразы вблизи концепта, так что при наличии таковых рядом с извлеченным объектом можно предположить, что объект относится к данному концепту. Если же для извлеченного объекта не находится соответствующий концепт, то он сам становится кандидатом в концепты. В работе [2] данная ситуация создания концепта регулируется экспертом. Извлечение отношений и правил Первая важная группа отношений для онтологии – отношения типа «is-a», то есть отношения, задающие иерархию концептов. Популярным методом извлечения отношений подобного рода является метод, основанный на лексико-синтаксических шаблонах [2, 4, 5, 20, 21]. В таких шаблонах отношения задаются в виде строк подобно «NP – это NP», «NP является NP» и т.п., где NP – обозначение словосочетания. Также для решения данной задачи можно использовать методы синтаксического анализа и, получая дерево синтаксического разбора, извлекать из него необходимые отношения. В работе [2] предложено развитие метрики силы отношения между двумя терминами на базе [22]. Данная метрика может быть предложена как альтернатива первым двум методам. Она позволяет кластеризовать между собой объекты в анализируемом тексте и при использовании иерархической кластеризации получать практически уже готовые иерархии объектов. Процесс извлечения других семантических отношений не отличается от процесса извлечения иерархических отношений. Шаблоны вида «Adj NP», где Adj – прилагательное, позволяют получать свойства объектов, попадающих под шаблон NP. Шаблоны формата «NP V NP», где V – это глагол, – отглагольные отношения, например, предложение «Александр написал этот текст» определит отношение «написал» между Александром и некоторым текстом. Интересная задача извлечения временных отношений вместе с решением предложена в работе [23] – в ней дается понятие сценария, определяющего последовательность событий, между которыми есть отношения предшествования. Одной из проблем в автоматическом извлечении отношений является то, что одни и те же отношения могут иметь различное написание, то есть имеет место проблема парафраз. Так, например, отношения «X является автором Y» и «X написал Y» – это по сути одно и то же отношение. С точки зрения разработки системы автоматического построения онтологий интересным решением кажется идея, предложенная в [24]. Суть работы – расширение гипотезы Хариса [19] до отношений так, что теперь рассматривается гипотеза о схожем семантическом значении отношений, часто встречающихся в одном контексте, то есть в схожем наборе терминов. На основе этой идеи можно реализовать алгоритм кластеризации отношений в группы отношений-синонимов. Что касается автоматического определения правил при построении онтологий, к сожалению, работ по данной тематике мало. Наиболее близкой является все то же исследование [24], когда получаемые кластеры отношений дают возможность определить правила наподобие «если X является автором Y, то X написал Y». Однако, очевидно, это неполноценное решение проблемы извлечения правил. В некотором роде схожей задачей занимается область анализа данных, посвященная поиску частотных шаблонов (Frequent Pattern Mining) [15], в рамках которой рассматривается задача извле- чения частотных правил типа «если в рассматри- ваемой T1 есть элементы X, то с вероятностью P в ней также будут элементы T2». Однако данные методы требуют адаптации под задачу автоматического определения правил для построения онтологии. Методы оценки качества Финальным этапом итерации автоматического построения онтологии является ее оценка, поскольку странно использовать алгоритм машинного обучения и не выполнять какую-либо оценку качества его работы. Однако задача оценки качества онтологии является нетривиальной. Было разработано несколько методов оценки качества онтологии [2]: метод на базе золотого стандарта, ручная оценка онтологии, косвенная оценка онтологии через другие приложения. Метод золотого стандарта предполагает разработку некоторой «идеальной» онтологии по набору документов, из которой затем удаляются некоторые концепты, объекты и отношения, после чего запускается алгоритм построения онтологии и результат сравнивается с золотым стандартом. Сравнение отдельных терминов, объектов или концептов можно выполнить при помощи расстояния Левенштейна, полноту и точность извлечения отношений – непосредственно по их подсчету на золотом стандарте. Данный метод прост с точки зрения его реализации и простоты оценки с помощью него, однако обладает рядом недостатков. Во-первых, сам золотой стандарт составляется человеком, поэтому в процессе его составления невозможно избежать субъективности. Следовательно, не факт, что построенная алгоритмом в чем-то отличная онтология является ошибкой – возможно, человек что-то недосмотрел или необъективно построил какую-то часть онтологии. Во-вторых, золотой стандарт сам по себе может быть недостаточно полным, в то время как алгоритм построит более полную онтологию и, как следствие, получит заниженную оценку его точности. В любом случае требуется разбор спорных случаев сравнения экспертами. Оценка онтологий экспертами выполняется на основе набора критериев, которыми могут быть, например, минимальность онтологии, ее консистентность, полнота, правильность построения иерархии. При введении шкалы оценивания (например десятибалльной) оценка представляет собой процесс заполнения анкеты, результаты которой затем усредняются по всем экспертам, и получается финальная оценка. Данный метод при наличии достаточно большого количества экспертов и точной формулировке критериев позволяет избежать фактора субъективности при оценке онтологии. Однако, безусловно, основной его проблемой является большое количество ручной работы. Косвенный метод оценки онтологии через использующее его приложение, например поисковую систему, позволяет перенести оценку онтологии в уже исследованную плоскость. Так, например, полнота и точность поиска с использованием построенной онтологии могут косвенно говорить о ее качестве. С точки зрения реализации данный метод вообще не требует каких-либо затрат, однако надо понимать, что точность такой оценки будет самой минимальной, так как на качество работы системы в целом может влиять огромное количество факторов, кроме самой онтологии. Оценка таким методом может рассматриваться как нижняя граница оценки качества алгоритма построения онтологии. Очевидно, что процесс оценки должен представлять собой некоторую золотую середину между предложенными методами. Например, можно построить золотой стандарт и выполнить на нем первичное оценивание. Если оценка окажется неудовлетворительной, выполнить ручное оценивание случаев несовпадения с золотым стандартом и при необходимости исправить ошибки в алгоритме или в результате оценки. Наконец, при использовании онтологии в большой системе выполнить оценку качества системы в целом и, зная оценку с предыдущих этапов оценивания, оценить вклад онтологии в потерю качества всей системы. Подводя итог, отметим, что в работе был сделан обзор базовых методов машинного обучения, используемых для задачи обучения онтологии (Ontology Learning). Рассмотрены основные алгоритмы, используемые такими системами, как BOEMIE Project [2], Kosmix [4] или Biperpedia [5], для задач извлечения объектов предметной области, концептов и отношений. Также была предложена альтернатива статистическим методам извлечения объектов предметной области на базе подхода, используемого в Sequential Pattern Mining, который позволяет рассматривать задачу извлечения объекта с точки зрения как лексического анализа, так и графематического и морфологического. Литература 1. Bessmertny I. Knowledge visualization based on semantic networks. Program Comp. Soft, 2010, vol. 36, no. 4, pp. 197–205. 2. Petasis G., Karkaletsis V., Paliouras G., Krithara A. and Zavitsanos E. Ontology population and enrichment: state of the art – knowledge-driven multimedia information extraction. Springer, 2011, pp. 134–166. 3. Buitelaar P., Cimiano P. and Magnini B. Ontology learning from text: methods, evaluation and applications. Journ. Frontiers in Artificial Intelligence and Applications, 2007, vol. 123, p. 180. 4. Gattani A., Doan A., Lamba D.S., Garera N., Tiwari M., Chai X., Das S., Subramaniam S., Rajaraman A. and Harinarayan V. Entity extraction, linking, classification, and tagging for social media. Proc. VLDB Endow, 2013, vol. 6, no. 11, pp. 1126–1137. 5. Gupta R., Halevy A., Wang X., Whang S.E. and Wu F. Biperpedia: an ontology for search applications. Proc. VLDB Endow, 2014, vol. 7, no. 7, pp. 505–516. 6. Nugumanova A. and Bessmertny I. Applying the latent se- mantic analysis to the issue of automatic extraction of collocations from the domain texts, in knowledge engineering and the semantic. St. Petersburg, Springer, 2013, pp. 92–101. 7. Jurafsky D. and Martin J.H. Speech and language processing. An introduction to natural language processing, computational linguistics, and speech recognition. Upper Saddle River N.J., Pearson Prentice Hall, 2009, pp. 727–734. 8. Apache OpenNLP developer documentation, 2014. URL: https://opennlp.apache.org/documentation/1.6.0/manual/opennlp. html#tools.namefind.recognition (дата обращения: 28.02.2016). 9. The stanford natural language processing group. Stanford named entity recognizer, 2015. URL: http://nlp.stanford.edu/software/CRF-NER.shtml (дата обращения: 28.02.2016). 10. Фридл Дж. Регулярные выражения. М.: Символ-Плюс, 2006. 598 с. 11. Yandex, Томита-парсер, 2015. URL: https://tech.yandex.ru/tomita/ (дата обращения: 28.02.2016). 12. Bartoli A., Davanzo G., De Lorenzo A., Mauri M., Med- vet E. and Sorio E. Automatic generation of regular expressions from examples with genetic programming, Moore J.H., Soule T. (Eds.). Proc. 14th Intern. Conf., 2012, p. 1477. 13. Barrero D.F., Camacho D. and Moreno M.D. Automatic web data extraction based on genetic algorithms and regular expressions, Cao L. (Ed.), Data mining and multi-agent integration, Springer, 2009, pp. 143–154. 14. Li Y., Krishnamurthy R., Raghavan S., Vaithyanathan S. and Jagadish H.V. Regular expression learning for information extraction. Proc. Conf. on Empirical Methods in Natural Language Processing (EMNLP '08), 2008, pp. 21–30. 15. Aggarwal C.C. and Han J. Frequent pattern mining. Cham, Springer, 2014, pp. 261–282. 16. Pei J., Han J., Mortazavi-Asl B., Pinto H., Chen Q., Dayal U. and Hsu M.-C. PrefixSpan: mining sequential patterns efficiently by prefix-projected pattern growth. Proc. 17th IEEE Intern. Conf. 2001, pp. 215–224. 17. Ayres J., Flannick J., Gehrke J. and Yiu T. Sequential PAttern mining using a bitmap representation. Zaïane, Goebel, et al. (Eds.). Proc. 8th ACM SIGKDD Intern., 2002, pp. 429–435. 18. Velardi P., Cucchiarelli A. and Petit M. A taxonomy learning method and its application to characterize a scientific web community. IEEE Trans. Knowl. Data Eng., 2007, vol. 19, no. 2, pp. 180–191. 19. Harris Z.S. Distributional structure. Journ. WORD, 1954, pp. 146–162. 20. Fader A., Soderland S. and Etzioni O. Identifying relations for open information extraction. Proc. Conf. on Empirical Methods in Natural Language Processing, 2011, pp. 1535–1545. 21. Hasegawa T., Sekine S. and Grishman R. Discovering relations among named entities from large corpora. Proc. . 42nd Annual Meeting on Association for Computational Linguistics (ACL '04), 2004, 415 p. 22. Yang H. and Callan J. A metric-based framework for automatic taxonomy induction. Proc. of the Joint Conf. of the 47th Annual Meeting of the ACL and the 4th Intern. Joint Conf. on Natural Language Processing of the AFNLP, 2009, vol. 1, pp. 271–279. 23. Kasch N. and Oates T. Mining script-like structures from the web. Proc. of the NAACL HLT, 2010, pp. 34–42. 24. Lin D. and Pantel P. DIRT – discovery of inference rules from text. 7th ACM SIGKDD Intern., 2001, pp. 323–328. |
| Постоянный адрес статьи: http://swsys.ru/index.php?id=4147&like=1&page=article |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
| Статья опубликована в выпуске журнала № 2 за 2016 год. [ на стр. 47-52 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Информационная поддержка распределенной разработки программного обеспечения на основе онтологии
- Семантический анализ научных текстов: опыт создания корпуса и построения языковых моделей
- Метаданные мультимедийных ресурсов и онтологии
- Построение онтологии на основе нереляционной базы данных для интеллектуальной системы поддержки принятия решений медицинского назначения
- Динамическая генерация пользовательского интерфейса мобильного медицинского приложения на основе онтологического подхода
Назад, к списку статей