Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Методы и средства анализа информативности признаков при обработке медицинских данных
Аннотация:Многие современные лечебные учреждения располагают информационными системами для хранения различных медицинских данных о здоровье пациентов, которые используются врачами для распознавания (диагностики) патологических процессов. Однако при анализе медицинских данных, обнаружении закономерностей в этих данных и их извлечении приходится сталкиваться с проблемой размерности. Размерность хранимых данных, определяемая числом различных признаков, описывающих состояние здоровья пациента, весьма велика и порой достигает нескольких десятков и сотен показателей. Поэтому проблема снижения размерности признакового пространства и выделения наиболее информативных признаков весьма актуальна для медицинских информационных систем. В статье сформулирована задача отбора информативных признаков как задача комбинаторной оптимизации, вычислительная сложность которой составляет O (2n), где n – исходное число исследуемых признаков. Приведено обобщение данной задачи с учетом возможности конструирования новых признаков на основе исходных. Представлен краткий обзор базовых методов сокращения признакового пространства, таких как метод главных компонент и метод экстремальной группировки признаков. Подробно рассмотрены и исследованы статистические методы оценки информативности признаков, используемые в медицинской диагностике: метод накопленных частот, метод Шеннона и метод Кульбака. Применение данных методов продемонстрировано на примере диагностики заболевания почек. Описан разработанный комплекс программ InformSigns, в котором реализованы все указанные статистические методы. InformSigns предоставляет врачу удобный интерфейс для оценки информативности признаков, описывающих состояние здоровья пациентов. Данный комплекс может быть встроен в специализированные медицинские информационные системы для диагностики различных патологических процессов.
Abstract:Many modern hospitals have information systems for storing medical data about their patients’ health. These data are for doctors to recognise (diagnose) pathological processes. However, experts face a problem of dimension in medical data analysis, detection of regularities in these data and their extraction. The dimension of stored data is determined by the number of different features that describe the health of the patient is very large and sometimes reaches several tens or hundreds of factors. Therefore, reducing the dimensionality of the feature space and selection of the most informative features is important for medical information systems. The article describes the problem of selection of informative features as a problem of combinatorial optimization. Its computational complexity is O (2n), where n is the initial number of features. The generalization of this problem with regard to the possibility of designing new factors based on the source features. The article gives a brief review of basic methods of sign space reduction, such as a principal component analysis and a method of extreme group of features. It also reviews statistical methods for estimating informative features used in medical diagnostics: the method of cumulative frequency, Shannon’s and Kullback’s methods. The application of these methods is demonstrated for diagnosing kidney disease. The article describes the program InformSigns, which implements all the statistical methods. InformSigns gives doctors a convenient interface for estimating informative features describing patients’ state of health. This complex can be integrated in specialized medical information systems for diagnostics of various pathological processes.
| Авторы: Быкова В.В. (bykvalen@mail.ru) - Сибирский Федеральный университет (профессор), Красноярск, Россия, доктор физико-математических наук, Катаева А.В. (kataeva_av@mail.ru) - Краевая клиническая больница (инженер-программист), Красноярск, Россия | |
| Ключевые слова: программное обеспечение для здравоохранения, оценка информативности признаков, методы отбора и конструирования признаков, анализ медицинских данных |
|
| Keywords: software for health care provision, estimation of informative features, methods of selection and extraction feat, medical data analysis |
|
| Количество просмотров: 11272 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
Применение современных информационных технологий в медицине способствует накоплению огромных объемов медицинских данных, хранимых и обрабатываемых с помощью медицинских информационных систем (МИС). Эти данные содержат в себе медицинские знания, которые можно извлекать и использовать для принятия решений, например, при распознавании (диагностике) патологических процессов. При анализе медицинских данных, обнаружении закономерностей в этих данных и их извлечении приходится сталкиваться с проблемой размерности. Размерность хранимых данных, определяемая числом различных признаков, описывающих состояние здоровья пациента, весьма велика и порой достигает нескольких десятков и сотен показателей. Поэтому проблема снижения размерности признакового пространства и выделения наиболее информативных признаков весьма актуальна для МИС. Существует несколько обстоятельств, обусловливающих возможность перехода от большего числа исходных показателей состояния пациента к существенно меньшему числу наиболее информативных признаков. Это прежде всего дублирование информации вследствие наличия связей между признаками, низкая информативность отдельных признаков, взвешенное суммирование некоторых признаков и конструирование обобщенных призна- ков. Информативность признака является поня- тием относительным. Одна и та же система признаков может быть информативной для решения одной задачи распознавания и неинформативной для другой. Так, при дифференциальной диагностике заболевания почек диагностически значимыми будут одни признаки, а при диагностике бронхиальной астмы другие. Признаком (Feature) принято называть некоторый показатель или определенную характеристику объекта произвольной природы. Набор признаков рассматриваемого множества объектов называется признаковым пространством, а совокупность значений признаков, относящихся к одному объекту, – признаковым описанием этого объекта [1-3]. В задачах медицинской диагностики объектами являются пациенты, а в качестве признаков выступают показатели состояния их здоровья. Различают следующие типы признаков. Количественные признаки – это признаки, измеренные в некоторой числовой шкале. Качественные (порядковые, балльные) признаки используются для выражения терминов и понятий, не имеющих числовых значений (например тяжесть заболевания), измеряются в порядковых шкалах. Номинальные признаки – это признаки, измеренные в шкале наименований (например группа крови, пол). При анализе таких признаков каждую отметку номи- нальной шкалы считают отдельным самостоятельным признаком, принимающим одно из двух зна- чений: 1 («да») или 0 («нет») [1, 2]. Количественное выражение качественных и номинальных признаков в анализе данных часто называют шкалированием [4]. После шкалирования к качественным и номинальным признакам можно применять различные методы численного анализа, включая статистические. В работе рассматриваются методы снижения размерности признакового пространства, а также статистические методы анализа информативности признаков при обработке медицинских данных на примере дифференциальной диагностики заболевания почек. Считается, что изначально признаки могут быть разнотипными, однако на этапе анализа их информативности они уже отшкалированы и представлены в количественном виде. Постановка задачи сокращения признакового пространства и обзор существующих методов решения Пусть W - множество объектов, X = {х1, х2, ..., хn} - конечное множество количественных признаков этих объектов. Для всякого объекта w Î W известно его признаковое описание {х1(w), х2(w), ..., хn(w)} – n-мерный вектор, причем i-я координата этого вектора равна значению i-го признака. Совокупность признаковых описаний объектов из заданной выборки объектов A Í W задана в виде матрицы размера |A|´n, называемой таблицей «объект - признак». Пусть I(Z) - мера информативности подмножества признаков Z Í X, определенная на A. Требуется среди всех различных подмножеств множества X выбрать некоторое такое подмножество Z* Í X, что
В теории распознавания образов поставленная задача называется FEATURES SELECTION (селекция признаков) [3-5]. Задача FEATURES SELECTION является вычислительно сложной, поскольку при |X| = n перебор всех различных подмножеств Z Í X требует O (2n) времени. Задача FEATURES SELECTION может быть обобщена путем определения преобразования Z = F(X), позволяющего из X формировать новое пространство признаков Z, |Z| < |X|. В такой постановке задача называется задачей FEATURES EXTRACTION (извлечение или конструирование признаков) [3]. При решении FEATURES EXTRACTION формируются новые признаки на основе уже имеющихся в X. Самое простое преобразование Z=F(X) – это линейное преобразование. Тот или иной вариант конкретизации FEATURES SELECTION или FEATURES EXTRACTION заключается в задании меры информативности, а для FEATURES EXTRACTION и класса допусти- мых преобразований Z = F(X), что приводит к конкретному методу решения. Основными способами решения задачи FEATURES EXTRACTION являются методы факторного анализа и метод экстремальной группировки признаков. Факторный анализ позволяет выделить обобщенные признаки (факторы), каждый из которых представляет сразу несколько исходных признаков. Один из методов факторного анализа – метод главных компонент [5, 6]. Суть его состоит в поиске линейных комбинаций признаков из X и в конструировании на их основе меньшего по мощности пространства признаков Z Í X, информативность которого равнозначна информативности X в целом. Как показывает практика, использование метода главных компонент оказывается наиболее результативным, когда все признаки х1, х2, ... , хn Î X однотипны и измерены в одних и тех же единицах. В противном случае полученные линейные комбинации исходных признаков трудно интерпретируемы. В методе экстремальной группировки по матрице «объект – признак» выборки A вычисляется корреляционная матрица и множество X разбивается на группы так, чтобы внутри одной группы признаки были сильно скоррелированы, а между группами наблюдалась относительно слабая корреляция. Далее осуществляется замена каждой группы признаков одним равнодействующим признаком. Недостатком данного метода является невозможность определения оптимального числа групп [5]. В том случае, когда требуется лишь оценить значимость отдельных независимых признаков на основе заданной меры информативности, широко используются статистические методы: метод накопленных частот, метод Шеннона и метод Кульбака [4, 6]. Выбор этих методов обусловлен следующими причинами: данные методы основаны на достаточно простых алгоритмах вычисления меры информативности, результаты применения этих методов легко интерпретируются. Именно эти особенности существенны для различных категорий пользователей МИС, большинство из которых не являются специалистами в области анализа данных и IT-технологий. Кроме того, данные методы составляют математический базис многих алгоритмов решения задачи FEATURES SELECTION, направленных на сокращение полного пе- ребора всех различных подмножеств Z Í X в (1). Разработан целый спектр таких алгоритмов [7]. Наиболее известный из них алгоритм AdDel, который сводится к последовательному выполнению процедур добавления (Addition) наиболее информативных и исключения (Deletion) наименее информативных признаков. Помимо этих алгоритмов, возможен также выбор наиболее значимых признаков экспертами-медиками на основе вычис- ленных оценок информативности признаков. Следует заметить, что оценка информативности признаков всегда зависит от того, что от чего нужно отличать, то есть от списка распознаваемых образов [4]. Чаще всего эти образы задаются разбиением выборки A на две обучающие выборки – A1 и A2. В данном случае FEATURES SELECTION сводится к решению следующей частной задачи: для заданных обучающих выборок A1, A2 и меры информативности I(x) требуется вычислить I(x) для каждого признака х Î X и указать те признаки, которые в наибольшей степени, согласно I(x), объясняют различие между A1 и A2. Рассмотрим особенности решения этой задачи методом накопленных частот (МНЧ), методами Шеннона и Кульбака. Метод накопленных частот Суть МНЧ заключается в следующем. Пусть имеются два набора значений признака х Î X, принадлежащие двум матрицам «объект – признак» обучающих выборок A1 и A2. Далее не будем делать различия между выборками и соответствующими им матрицами «объект – признак». По двум наборам значений признака x строятся эмпирические распределения и подсчитываются накопленные частоты как суммы частот от начального до текущего интервала распределения. Мерой информативности признака х служит модуль максимальной разности накопленных частот:
где M1 j – накопленная частота для j-го интервала выборки A1; M2 j – накопленная частота для j-го интервала выборки A2; (q+1) – число интервалов. Продемонстрируем алгоритм вычисления меры информативности (2) на примере дифференциальной диагностики заболевания почек. Рассмотрим следующее множество исходных признаков: X = {Возраст пациента, Длина почки, Ширина почки, Толщина почки, (3) Толщина паренхимы, Скорость кровотока, Ускорение артериального потока}. Пусть заданы обучающие выборки А1 и A2, отражающие результаты измерения этих параметров для двух состояний – «Здоровая почка» и «Имеются множественные кисты» соответственно. Результаты этих измерений взяты из работы [8] и представлены в таблице 1. Детальное описание расчетов покажем на примере признака x = «Возраст пациента». Построим эмпирические распределения признака х по каждой выборке. Для этого вычислим минимальное и максимальное значения этого признака и размах для всех данных таблицы 1: xmin=21, xmax=74, xmax– xmin=53. Зададим количество интервалов распределения так, чтобы размах значений признака примерно нацело делился на число q. В данном случае q = 5. Теперь найдем величину D интервала распределения по формуле
Вычислим границы каждого j-го интервала: dj= xmin+j×D, j=0, 1, ..., q. (5) Для построения эмпирического распределе- ния признака х по выборке Аk (k = 1, 2) необходи- мо найти количество mk j попаданий значения данного признака в каждый интервал исходя из соотношения dj - 1 < x ≤ dj. Далее накопленную частоту Mk j для j-го интервала вычисляем следующим образом:
Для исходных данных из таблицы 1 результаты всех вычислений по формулам (4)–(6) приведены в таблице 2. Таблица 1 Исходные данные для расчета меры информативности Table 1 Initial data for calculating informativeness
Подставляя значения последнего столбца таблицы 2 в формулу (2), получаем окончательный результат: мера информативности исследуемого признака x = «Возраст пациента» равна 3 и отвечает диапазону возраста 52,8 < x ≤ 63,4. Таблица 2 Результаты расчета по МНЧ информативности признака x = «Возраст пациента» Table 2 The calculation results for the cumulative frequency method x = “Age of the patient”
Меры информативности всех признаков исходного множества (3), вычисленные по МНЧ, приве- дены в таблице 3. Таким образом, согласно задан- ным обучающим выборкам А1, A2 и мере информативности (2), наиболее значимыми признаками для дифференциальной диагностики заболевания почек являются «Длина почки», «Возраст пациента», «Ускорение артериального потока». Таблица 3 Значения мер информативности всех признаков по МНЧ Table 3 The values of informativeness of all features
Метод Шеннона В методе Шеннона в качестве меры информативности признака x рассматривается средневзвешенное количество информации, которое свойственно анализируемому признаку. Информативность признака x вычисляется по формуле
Обозначения, используемые в формуле (7): q – количество градаций признака; k = 1, 2 – номер обучающей выборки; Рi – вероятность попадания значения признака в i-ю градацию:
где mi k - частота появления значения признака в i-й градации для выборки Ak; N - общее число признаковых описаний объектов, входящих в А1 и A2; pi k - вероятность появления значения признака в i-й градации:
Результаты вычислений по формулам (7)–(9) для исходных данных из таблицы 1 и признака х = «Возраст пациента» представлены в таблице 4. Подставляя значения последнего столбца таблицы 4 в формулу (7), получаем I(x) = 0,9. Таблица 4 Результаты расчета по методу Шеннона меры информативности признака x = «Возраст пациента» Table 4 The calculation results of the x = “Age of the patient” according to Shannon’s method
Заметим, что метод Шеннона дает оценку информативности исследуемого признака в виде нормированной величины, которая принимает зна- чения от 0 до 1. Это следует из формулы (7), поскольку значения вероятностей pi k находятся в интервале от 0 до 1, а логарифм от таких значений меньше нуля. Об информативности признака x в этом случае говорят, что, чем ближе I(x) к 1, тем выше информативность x и, наоборот, чем ближе I(x) к 0, тем ниже информативность x. Меры информативности всех признаков исходного множест- ва (3), вычисленные по методу Шеннона, приведены в таблице 5. Таблица 5 Значения мер информативности всех признаков по методу Шеннона Table 5 The values of the informativeness of all features for Shannon’s method
Согласно заданным обучающим выборкам А1, A2 и мере информативности (7), наиболее значимые признаки при дифференциальной диагностике заболевания почек - это «Скорость кровотока», «Ускорение артериального потока», «Возраст пациента». Метод Кульбака В данном методе в качестве меры информативности признака х рассматривается величина, называемая дивергенцией Кульбака и отражающая расхождение между выборками A1 и A2 следующим образом:
где q – количество градаций признака; рi k – вероятность попадания значения признака в i-ю градацию:
где mi k - частота появления значения признака в i-й градации выборки Ak. Для исходных данных из таблицы 1 и признака х = «Возраст пациента» результаты вычислений по формулам (10)–(11) представлены в таблице 6. Согласно формуле (10) имеем I(x) = 1,8. Таблица 6 Результаты расчета по методу Кульбака меры информативности признака x = «Возраст пациента» Table 6 The calculation results of the x = “Age of the patient” according to Kullback’s method
Метод Кульбака дает оценку информативности исследуемого признака в виде величины, которая принимает значения от 0 до 2. В этом случае считают, что, чем ближе I(x) к 2, тем выше информативность x и, наоборот, чем ближе I(x) к 0, тем ниже информативность x. Меры информативности всех признаков исходного множества (3), вычисленные по методу Кульбака, приведены в таблице 7. Таблица 7 Значения мер информативности всех признаков по методу Кульбака Table 7 The values of informativeness of all features by Kullback’s method
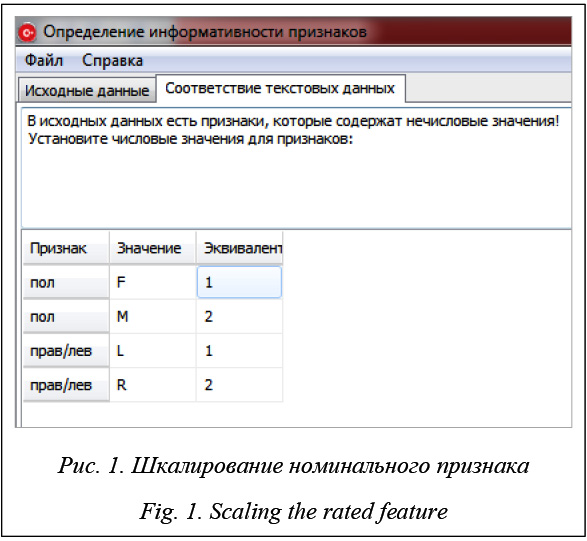
Из таблицы 7 следует, что метод Кульбака определяет тот же набор информативных признаков, что и метод Шеннона. Сравнение таблиц 3, 5, 7 позволяет сделать следующие выводы: рассмотренные методы не противоречат друг другу и дают близкие наборы наиболее информативных признаков на одних и тех же обучающих выборках, результаты методов Шеннона и Кульбака в основном совпадают. Приведенные выше расчеты были выполнены в предположении, что все признаки из множества (3) являются независимыми. Для проверки этого предположения была осуществлена попытка группировки признаков с помощью статистического пакета для социальных нужд IBM SPSS (Statistical Package for the Social Sciences) [9, 10]. Эксперименты показали, что признаки из таблицы 1 не подлежат группировке. Программная реализация методов анализа информативности признаков Рассмотренные выше методы анализа информативности признаков реализованы в виде комплекса программ InformSigns на языке программирования С++ в среде Embarcadero RAD Studio XE8. Исходными данными для InformSigns является матрица «объект – признак», имеющая вид таблицы 1 и разделенная на две выборки. Для ввода исходных данных имеется интерфейс, вид которого представлен на рисунке (см. http://www.swsys.ru/uploaded/ image/2016_2/2016-2-dop/2.jpg). Возможен также ввод исходных данных из внешнего файла формата Microsoft Excel. При наличии в матрице «объект–признак» качественных или номинальных признаков комплекс программ InformSigns позволяет выполнить шкалирование, то есть установить соответствие между текстовым или номинальным значениями признака и его числовым эквивалентом. Пример шкалирования номинального признака «Пол» представлен на рисунке 1. В программном комплексе InformSigns предусмотрено несколько вариантов вывода результатов: в виде таблицы значений информативности, круговой диаграммы и гистограммы. Для табличных данных возможен вывод результатов во внешний файл формата Microsoft Excel. Графическое представление данных позволяет наглядно оценить полученные значения информативности всех признаков для каждого метода отдельно, а также для всех трех методов одновременно. Пример вывода результатов таблиц 3, 5, 7 в виде круговых диаграмм представлен на рисунке 2.
Рассмотренные в работе методы оценки информативности признаков являются наиболее простыми и понятными для алгоритмизации и применения. Результаты их использования хорошо интерпретируемы. Программная реализация данных методов не является трудоемкой и не влечет за со- бой значительных вычислительных ресурсов. Именно поэтому они могут успешно исполь- зоваться при решении задач диагностики патоло- гических процессов в различных лечебных учреждениях. Следует отметить, что МНЧ, методы Шеннона и Кульбака реализованы в некоторых универсальных программных средствах анализа данных. Однако для освоения и применения этих программных инструментов требуется профессиональная подготовка в области IT-технологий. Если в качестве пользователя выступает врач, то целесообразно применение узкоспециализированных медицинских информационных систем, к которым можно отнести InformSigns. Комплекс программ InformSigns в настоящее время успешно используется в учебном процессе Красноярского государственного медицинского университета имени профессора В.Ф. Войно-Ясенецкого на кафедре медицинской информатики и инновационных технологий. Применение InformSigns подтвердило эффективность и полезность реализованных в системе методов сокращения признакового пространства для решения задач медицинской диагностики по независимым признакам. Дальнейшее развитие программного комплекса InformSigns направлено на реализацию методов выявления скрытых зависимостей между данными, привязку к БД конкретных МИС и патологиям. Литература 1. Колесникова С.И. Методы анализа информативности разнотипных признаков // Вестн. Томского гос. ун-та: Управление, вычислительная техника и информатика. 2009. № 1 (6). С. 69–80. 2. Колесникова С.И., Янковская А.Е. Оценка значимости признаков для тестов в интеллектуальных системах // Изв. РАН. Теория и системы управления. 2008. № 6. С. 135–148. 3. Воронцов К.В. Машинное обучение: курс лекций. 2010. URL: http://www.machinelearning.ru (дата обращения: 04.04.2016). 4. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. Новосибирск: Изд-во ИМ СО РАН, 1999. 270 с. 5. Ким Д.О., Мьюллер Ч.У., Клекка У.Р. Факторный, дискриминантный и кластерный анализ. М.: Финансы и статистика, 1989. 215 с. 6. Айвазян С.А., Бухштабер В.М., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Классификация и снижение размерности: справочник. М.: Финансы и статистика, 1989. 250 с. 7. Загоруйко Н.Г., Кутненко О.А., Борисова И.А. Выбор информативного подпространства признаков (Алгоритм GRAD) // Математические методы распознавания образов: докл. 12-й Всерос. конф. М., 2005. С. 106-109. 8. Хитрова А.Н. Дифференциальная диагностика кист почечного синуса и гидронефрозов методом комплексного ультразвукового обследования: дис. ... канд. мед. наук, 1996. 9. Бююль А., Цефель П. SPSS: искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей. СПб: ДиаСофтЮП, 2005. 608 с. 10. Дюк В.А., Эмануэль В.Л. Информационные технологии в медико-биологических исследованиях. СПб: Питер, 2003. 528 с. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
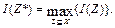 (1)
(1)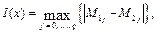 (2)
(2)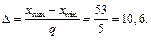 (4)
(4)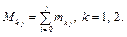 (6)
(6) . (7)
. (7)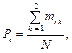 (8)
(8)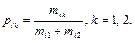 (9)
(9)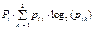
 , (10)
, (10)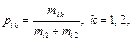 (11)
(11)

| Постоянный адрес статьи: http://swsys.ru/index.php?id=4165&page=article |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
| Статья опубликована в выпуске журнала № 2 за 2016 год. [ на стр. 172-178 ] |
Назад, к списку статей