Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Система диагностики и оценки риска остеопоротического перелома на основе интеллектуального анализа данных
Аннотация:Использование информационных технологий в медицине при диагностике различного рода заболеваний требует совершенствования методов хранения и обработки данных. Для оценки риска остеопоротического перелома используется вычислительная модель, основанная на использовании схемы байесовского вывода. Задача прогнозирования рассматривается как задача классификации, то есть как задача нахождения апостериорной вероятности принадлежности пациента к одному из двух классов исходной классификации. Фактор, определяющий возможность остеопоротического перелома, является многомерной случайной величиной, оценка характеристик которой требует хранения и обработки больших объемов информации. В статье описываются состав и архитектура программного комплекса для диагностики остеопороза и оценки риска остеопоротического перелома. Комплекс включает в себя информационную и вычислительную компоненты. Вычислительная компонента содержит методы интеллектуального анализа данных, направленного на обнаружение закономерностей и тенденций, а также на выявление взаимосвязей существующих в многомерных массивах клинических данных. Информационная компонента содержит модели выборочных данных в виде многомерных кубов, которые формируются на базе OLAP-технологий и таблиц сопряженности. Объединение информационной и вычислительной компонент образует единую модель системы. Выходные данные информационной компоненты используются в качестве входа для вычислительной компоненты, которая служит для вывода суждений в условиях неопределенности и неполной информации. Ее основу составляют методы исчисления вероятностей, байесовы и нейронные сети. Рассмотрены вопросы использования служб Analysis Services: SQL Server Data Tools (SSDT) и SQL Server Management Studio в качестве платформы для создания и анализа многомерных моделей на основе технологий Data Mining.
Abstract:The use of information technologies in medicine for diadnosis of various diseases needs improvements in data storage and processing. To assess the osteoporotic fracture risk the specialists use a computational model based on the Bayesian inference scheme. A prediction task is considered as a classification task, i.e. a task of finding the posterior probability of patient belonging to one of two original classification classes. The factor that determines the possibility of osteoporotic fracture is a multidimensional random variable. To evaluate its performance it is required to store and process large information volumes. The complex includes informational and computational components. The computational component contains methods of data mining aimed at detecting patterns and trends, as well as at identifying existing relationships in multidimensional arrays of clinical data. The informational component contains sample data models in the form of multidimensional cubes that are formed on the base of OLAP-technologies and contingency tables. Information and computer components are combined into a single system model. Data output of the information component is used as input for the computer component, which is used to display the statements under conditions of uncertainty and incomplete information. It is based on probability calculation methods and Bayesian networks. The article examines the use of Microsoft SQL Server Analysis Services as a platform to create and analyze multivariate models based on Data Mining technology.
| Авторы: Дмитриев Г.А. (kirsanich@mail.ru) - Тверской государственный технический университет (профессор), г. Тверь, Россия, доктор технических наук, Аль-Факих Али Салех Али (alfakih.ali@mail.ru) - Тверской государственный технический университет (аспирант), Тверь, Россия | |
| Ключевые слова: информационная система, медицинская диагностика, остеопороз, байесовские сети |
|
| Keywords: information system, medical diagnostics, osteoporosis, bayesian networks |
|
| Количество просмотров: 10687 |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
Одним из самых распространенных хронических прогрессирующих метаболических заболеваний костной системы, которое характеризуется нарушением микроархитектоники костной ткани и усилением хрупкости по причине нарушения метаболизма костной ткани с преобладанием катаболизма над процессами костеобразования, является остеопороз [1–3]. Это социально-значимая патология, связанная не только с широкой распространенностью у населения старше 50 лет, но и с высокой частотой его тяжелых осложнений, среди которых наиболее неблагоприятными в прогностическом плане являются остеопоротические переломы (ОП). Ранняя диагностика заболевания и определение риска перелома позволяют выявлять лиц, имеющих высокий риск ОП, и выбрать наиболее подходящий препарат и стратегию лечения. Развитие остеопороза прямо связано со снижением костной массы в единице объема и, соответственно, минеральной плотности костной ткани (МПКТ), определяющей прочность кости и ее устойчивость к чрезмерному физическому воздействию. МПКТ является важнейшим фактором, определяющим риск ОП. Для оценки МПКТ используется такой показатель, как T-критерий: Связь между низкой костной массой и повышенным риском переломов позволяет проводить инструментальную диагностику остеопороза и выявлять риск перелома, основываясь на МПКТ [1, 2]. Низкая МПКТ довольно эффективно может быть оценена с помощью целого ряда технологий, однако, как было показано, например, в [2, 3], МПКТ не в состоянии идентифицировать всех пациентов, у которых в будущем произойдет перелом. Это лишь один из факторов риска перелома, а для его более точной оценки необходимо использовать и другие, хорошо измеряемые факторы, которые давали бы дополнительную к МПКТ информацию. Кроме того, массовый скрининг на остеопороз, выполняемый путем измерения плотности костной ткани, из-за высокой стоимости исследования не является эффективным. Для выявления больных с высоким риском ОП или для предварительного скрининга тех, кому может потребоваться измерение плотности костной ткани, были разработаны такие методики, как «Вопросник для самооценки остеопороза», «Индекс риска остеопороза» [3–5]. В последнее время широкое применение нашел способ оценки риска перелома, получивший название FRAX (Fracture risk assessment tool) [6, 7]. Алгоритм FRAX дает обобщенную оценку риска перелома на основе имеющихся у пациента кли- нических факторов риска в сочетании (или без) с данными денситометрии. При прогнозировании десятилетней вероятности перелома по методике FRAX используются следующие клинические факторы риска: возраст, пол, индекс массы тела, предшествующий перелом, перелом бедра у родителей, семейный анамнез переломов, курение, прием глюкокортикоидов, ревматоидный артрит, вторичный остеопороз, злоупотребление алкоголем. Кроме того, может быть добавлен показатель минеральной плотности кости шейки бедра. Тем не менее, инструмент FRAX, как и перечисленные выше, имеет определенные ограничения. Многие из факторов риска, используемых в инструменте FRAX, такие как курение сигарет, потребление алкоголя, прием глюкокортикоидов, перенесенные ранее переломы, оказывают дозозависимое влияние на риск перелома. Для этих факторов в инструменте FRAX используют относительные риски, основанные на усредненном влиянии фактора, что снижает достоверность выводов. Также эти инструменты не содержат целый ряд других показателей костной ткани, которые дают ценную информацию о риске перелома [8]. К ним относятся биохимические показатели метаболизма костной ткани, количественные показатели оценки кости с помощью ультразвукового метода и компьютерной томографии, а также измерения МПК в других областях скелета, уровни биохимических маркеров метаболизма костной ткани, риск падений, предшествующее медикаментозное лечение и ряд других. Указанные выше недостатки делают актуальными разработки новых методов и информационных технологий оценки риска ОП, позволяющие проводить диагностику на основе мониторинговых исследований, учитывающих как общую тенденцию, так и местную специфику. Модель оценки риска ОП В системе используется модель оценки риска ОП, основанная на использовании схемы байесовского вывода [8–11]. Байесовский вывод – один из методов статистического вывода, в котором для уточнения вероятностных оценок на истинность гипотез при поступлении свидетельств используется формула Байеса:
где случайная величина Y = (y1, y2) описывает состояние пациента – наличие или отсутствие пере- лома. Набор факторов риска определяет n-мерную случайную величину X с компонентами (X1, …, Xn).
В изображенной на рисунке 1 байесовской сети вершины представляют собой случайные величины, а дуги – вероятностные зависимости, которые определяются через таблицы условных вероятностей. Таблица условных вероятностей каждой вершины содержит вероятности состояний этой вершины при условии состояний ее родителей. Задачу оценки риска перелома будем рассматривать как задачу нахождения апостериорной вероятности принадлежности пациента к одному из классов классификации – y1 или y2. Апостериорная вероятность того, что пациент принадлежит к классу y1 (то есть существует вероятность перелома), имеет вид Байесовская сеть строится на основе как экспертных оценок, так и статистических данных. Эти данные использовались и для установления взаимосвязей между случайными элементами, и для получения оценок условных вероятностей. В общем случае вид плотности распределения и его параметры не известны, поэтому используются данные случайных независимых выборок. На основе этих данных строятся таблицы априорных ве- роятностей для вершины графа Y и условных вероятностей для вершин X1 и X2:
Законы распределения случайных величин p(X1) и p(X2) вычислялись на основе дискретной логики модели множественного выбора: p(Y|(X1|X11, X12, …, X1h), (X2|X21, X22, ..., X2g)). Модель основана на анализе многомерной системы дискретных случайных величин (многомерной дискретной случайной величины) с неизвестным законом распределения. Закон распределения такой случайной величины задается в виде многомерной таблицы, в ячейках которой расположены вероятности совместного проявления событий. На основании этой таблицы могут быть вычислены все условные и маржинальные вероятности. Для оценки вероятностей неизвестного многомерного закона распределения на основе выборочных данных использовались таблицы сопряженности, имеющие структуру, аналогичную многомерной таблице, задающей закон распределения случайной величины. В качестве оценок вероятностей в таблице сопряженности использовались эмпирические частоты совместного проявления событий. Последующая обработка данных проводилась на основе логарифмической модели и методов измерения связей многовходовых таблиц сопряженности. Организация вычислений в системе диагностики и оценки риска ОП Система состоит из совокупности модулей, обеспечивающих хранение данных и их обработку. Данные анамнеза представляются в виде совокупности векторов (x1, x2, …, xn), содержащих значения различных количественных и качественных признаков по каждому пациенту. Массивы данных о состоянии M пациентов проходят предварительную обработку, которая заключается в их группировке и бинаризации. В результате этой обработки формируется таблица (см. таблицу), содержащая исходные амнестические данные по каждому пациенту для анализа. На основе исходной таблицы (см. таблицу) формируется многовходовая таблица сопряженности в виде многомерного куба. Это позволяет применить технологию OLAP (online analytical processing) для аналитической обработки информации в различных срезах. Результатом обработки многомерных кубов являются, в частности, оценки вероятностей многомерного распределения. На основе этих данных и алгоритмов настройки байесовской сети вычисляются параметры модели оценки риска ОП. Обученная таким образом модель сохраняется в библиотеке моделей и используется для оценки риска ОП для пациента в процессе дифференциальной диагностики. Массив данных Data array
В качестве инструмента разработки системы диагностики и оценки риска ОП была использована СУБД MS SQL Server, поскольку на ее базе имеется возможность хранить данные в виде многомерных кубов, создавать модели Data Mining (интеллектуального анализа данных) и применять их для поддержки принятия решений [12]. Среда MS SQL Server включает подсистему службы Analysis Service, которая содержит алгоритмы интеллектуального анализа данных и средства создания запросов к данным. Обширная библиотека алгоритмов службы Analysis Service содержит алгоритмы классификации, дерева принятия решений, регрессионного анализа, логистической регрессии, кластеризации, анализа взаимосвязей между различными атрибутами в наборе данных, анализа временных рядов нейронных сетей. Кроме того, в библиотеку алгоритмов можно включать собственные алгоритмы и связывать их с данными. Эта возможность была использована при создании программного комплекса для диагностики остеопороза и оценки риска ОП. Для этого разработанные на основе методов исчисления вероятностей и байесовых сетей алгоритмы, кратко описанные выше, были добавлены в экземпляр сервера в качестве новой функции интеллектуального анализа данных. Регистрация алгоритмов производилась путем добавления необходимых метаданных в INI-файл экземпляра службы Analysis Services.
Программный комплекс состоит из трех компо- нент: набора моделей интеллектуального анализа данных, структур интеллектуального анализа данных и клиентского приложения. Модели интеллектуального анализа данных создаются на основе алгоритмов из библиотеки экземпляра службы Analysis Service. Для создания модели сначала описывается ее структура, а затем определяются ее параметры на основе имеющихся данных. Этот процесс называется обучением. После обучения модель интеллектуального анализа данных содержит метаданные о модели, ссылку на алгоритм, который использовался для анализа данных, и результат анализа. Метаданные определяют имя модели и сервер, где она хранится, а также описание модели, включая данные, которые использовались для построения модели с привязкой к структуре интеллектуального анализа данных. Сама модель представляется стандартной структурой независимо от применяемого алгоритма и содержит свое полное описание. Обученная модель используется для вывода закономерностей и взаимосвязей, формирования прогнозов при получении новых данных и хранится в библиотеке моделей экземпляра службы Analysis Service. Источником данных как для обучения, так и для обученных мо- делей являются структуры интеллектуального анализа данных. Структура интеллектуального анализа данных является хранилищем данных, на основе которых строятся модели интеллектуального анализа. Несколько моделей могут использовать одну и ту же структуру интеллектуального анализа данных. Структура и модель интеллектуального анализа данных являются отдельными объектами службы Analysis Service. В структуре интеллектуального анализа данных хранятся сведения, определяющие источник данных. Процесс создания структуры данных включает построение модели на основе OLAP, привязку модели к БД, загрузку в нее данных и присвоение разрешений на доступ к данным. Многомерные кубы являются базовыми объектами запросов. Администрирование БД осуществляется с помощью среды SQL Server Management Studio. С ее помощью можно вносить изменения в БД. Пользовательский интерфейс системы диагностики (рис. 2) реализован в среде MS Excel, выполняющей роль клиентского приложения. Использование надстроек интеллектуального анализа для пакета Excel позволяет проводить интеллектуальный анализ данных средствами Microsoft SQL Server. Чтобы использовать средства интеллектуального анализа таблиц для Excel, необходимо создать соединение с экземпляром служб Analysis Services. Это соединение обеспечивает доступ к алгоритмам интеллектуального анализа данных и БД. При подключении к БД служб Analysis Services посредством клиентского приложения происходит подключение к многомерному кубу внутри этой БД. Описанный подход в медицинской практике для поддержки принятия решений на стадии анализа медицинских данных позволяет использовать технологию клиент-сервер при формировании БД, необходимых для разработки моделей заболевания. Клиент интеллектуального анализа данных для Excel поддерживает активное соединение с сервером, обеспечивая масштабируемость системы. Таким образом, модель интеллектуального анализа может быть размещена как на локальном компьютере, так и на удаленных серверах БД. Это важно для организации работ по компьютерной диагностике остеопороза и прогнозированию ОП в медицинских учреждениях, поскольку источниками данных могут быть как отдельные медицинские учреждения, так и группы подобных учреждений, диагностические центры. Данные также могут поступать из других источников в ходе проведения мониторинговых исследований, например, из БД Министерства здравоохранения, Всемирной организации здравоохранения, Фонда медицинского страхования и т.п. На основе рассмотренной архитектуры можно реализовывать различные варианты системы диагностики – локальные, региональные и т.д., используя единую технологию их создания. Литература 1. Cadarette S.M. et al. Development and validation of the Osteoporosis Risk Assessment Instrument to facilitate selection of women for bone densitometry. CMA Journ., 2000, vol. 162, no. 9, pp. 1289–1294. 2. Cadarette S.M. et al. Evaluation of decision rules for refer- ring women for bone densitometry by dual-energy x-ray absorptiom- etry. Journ. AMA, 2001, vol. 286, no. 1, pp. 57–63. 3. Cosman F., de Beur S.J., LeBoff M.S. et al. Clinician’s guide to prevention and treatment of osteoporosis. Osteoporos Int., 2014, vol. 25, no. 8, pp. 2359–2381. 4. Mихайлов Е.Е., Беневоленская Л.И. Эпидемиология остеопороза и переломов: руководство по остеопорозу. М.: Бином. Лаборатория знаний̆, 2003. С. 10–55. 5. Richy F. et al. Validation and comparative evaluation of the osteoporosis self-assessment tool (OST) in a Caucasian population from Belgium. QJM, 2004, vol. 97, no. 1, pp. 39–46. 6. Канис Дж.А., Оден А., Йохансон Г., Боргстром Ф., Стром О., Макклоски И.В. FRAX – новый инструмент для оценки риска перелома: применение в клинической практике и пороговые уровни для вмешательства // Остеопороз и остеопатии. 2012. № 2. С. 38–44. 7. Лесняк О.М. Новая парадигма в диагностике и лечении остеопороза: прогнозирование 10-летнего абсолютного риска перелома (калькулятор FRAX) // Остеопороз и остеопатии, 2012. № 1. С. 23–28. 8. Рассел С., Норвиг П. Искусственный интеллект: современный подход. М.: Вильямс, 2006. 1408 с. 9. Терехов С.А. Введение в байесовы сети // Нейроинформатика-2003: науч. сессия МИФИ-2003. V Всерос. науч.-технич. конф. М.: Изд-во МИФИ, 2003. Ч. 1. С. 149–187. 10. Прокопчина С.В., Ветров А.Н., Нестеров А.О. Управление инвестиционными рисками строительных организаций на основе байесовских информационных технологий // Програм- мные продукты и системы. 2014. № 1 (105). С. 212–216. 11. Еремеев А.П., Хазиев Р.Р., Зуева М.В., Цапенко И.В. Прототип диагностической системы поддержки принятия решений на основе интеграции байесовских сетей доверия и метода Демпстера–Шефера // Программные продукты и системы. 2013. № 1 (101). С. 11–16. 12. Службы Analysis Services. URL: https://msdn.microsoft.com/ru-ru/library/ms174949(v=sql.120).aspx (дата обращения: 10.04.2016). 13. Шилин Д.Е., Шилин А.Д., Адамян Л.В. Существует ли у населения России связь между риском переломов по шкале FRAX (ВОЗ 2008) и потреблением кальция? // Остеопороз и остеопатии. 2010. № 1. С. 53–54. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 , где yi – значение МПКТ у i-го индивида; my – среднее значение МПКТ в популяции; sy – стандартное отклонение. Т-критерий означает количество стандартных отклонений выше или ниже среднего показателя пика костной массы. Т-критерий уменьшается при снижении костной массы и возрастает при ее увеличении. МПКТ определяется в абсолютных единицах как значение числа стандартных отклонений между МПКТ пациента и возрастной нормой для здоровых людей такого же возраста и пола.
, где yi – значение МПКТ у i-го индивида; my – среднее значение МПКТ в популяции; sy – стандартное отклонение. Т-критерий означает количество стандартных отклонений выше или ниже среднего показателя пика костной массы. Т-критерий уменьшается при снижении костной массы и возрастает при ее увеличении. МПКТ определяется в абсолютных единицах как значение числа стандартных отклонений между МПКТ пациента и возрастной нормой для здоровых людей такого же возраста и пола. ,
,
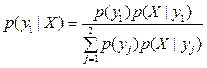 .
. ;
;  , где
, где  и
и  – значения латентных переменных; x1j, x2j – наблюдаемые значения факторных переменных. Используя p(X1) и p(X2) в качестве априорных вероятностей, находим их апостериорные значения p(X1|X11, X12, …, X1h) и p(X2|X21, X22, ..., X2g). Окончательно модель для вычисления вероятности ОП имеет вид
– значения латентных переменных; x1j, x2j – наблюдаемые значения факторных переменных. Используя p(X1) и p(X2) в качестве априорных вероятностей, находим их апостериорные значения p(X1|X11, X12, …, X1h) и p(X2|X21, X22, ..., X2g). Окончательно модель для вычисления вероятности ОП имеет вид
| Постоянный адрес статьи: http://swsys.ru/index.php?id=4201&page=article |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
| Статья опубликована в выпуске журнала № 3 за 2016 год. [ на стр. 208-212 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Система поддержки принятия решений при определении нозологической формы гепатита
- Анализ особенностей процессов управления требованиями к информационным системам государственных структур
- Интегрированная система для разработки изделий из полимерных композиционных материалов на основе методологии PLM
- Информационная система управления движением продукции на складах
- Методики оптимизации транспортно-погрузочного комплекса предприятия
Назад, к списку статей