Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Методы автоматизированного анализа коротких неструктурированных текстовых документов
Аннотация:В работе рассматриваются задачи автоматизированного анализа текстовых документов в органах исполнительной и законодательной власти. Выделяется группа признаков для классификации текстовых документов, приводятся их типы, методы анализа и рубрицирования. Определяется перечень типов документов, которые необходимо классифицировать. Для анализа коротких неструктурированных текстовых документов предлагается использовать метод классификации на основе весовых коэффициентов, экспертной информации, нечеткого логического вывода, для которого усовершенствована вероятностная математическая модель, разработан способ обучения и экспериментально подобрано соотношение весовых коэффициентов. Предварительно разработанный метод необходимо обучить. На этапе обучения слова тезауруса для каждой предметной области разбиваются на три типа: уникальные, редкие и общие, и в зависимости от типа словам присваиваются весовые коэффициенты. Для поддержания актуальности весовых и частотных коэффициентов предлагается использовать динамическую кластеризацию. Разработанный метод позволяет анализировать описанные документы, а также учесть динамичность тезауруса рубрик. Представлена схема работы системы автоматизированного анализа неструктурированных текстовых документов, написанных на естественном языке, различных типов: длинные, короткие, очень короткие. В зависимости от типа документа используется соответствующий метод анализа, который имеет наилучшие показатели точности и полноты при анализе текстовых документов данного типа. В качестве синтаксического анализатора используется парсер MaltParser, обученный на национальном наборе русского языка. Результатом работы всей системы можно считать базу знаний, в которую попадают все извлеченные знания и их отношения. База знаний постоянно пополняется и используется работниками исполнительной и законодательной власти для обработки поступающих запросов.
Abstract:The paper considers the problem of an automated analysis of text documents in the executive and legislative authorities. It provides a characteristics group in order to classify text documents, their types, methods of analysis and rubricating. There is a list of the types of documents that need to be classified. To analyze short unstructured text documents the authors propose to use a classification method based on weighting factors, expert information, fuzzy inference with a developed probabilistic mathematical model, a way of learning and experimentally chosen ratio of weight coefficients. The pre-developed method should be trained. During learning the thesaurus words for each domain are divided into three types: unique, rare and common. The words are allocated with weights depending on the type. In order to maintain the relevance of weight and frequency coefficients it is proposed to use dynamic clustering. The developed method allows analyzing the disclosed documents, as well as taking into account thesaurus heading agility. The paper presents a scheme of automatic classification system for unstructured text documents written in natural language. There might be various types of text documents: long, short, very short. Depending on the document type the system uses a corresponding method of analysis, which has the best indicators of accuracy and completeness of such text document analysis. MaltParser is a parser which is used here and trained on a national set of the Russian language. The result of the whole system work is a knowledge base, which includes all extracted knowledge and attitudes. The knowledge base is constantly updated and used by employees of the executive and legislative authorities to handle incoming requests.
| Авторы: Козлов П.Ю. (originaldod@gmail.com) - Смоленский филиал Национального исследовательского университета МЭИ (аспирант), Смоленск, Россия | |
| Ключевые слова: динамичный тезаурус, короткие неструктурированные тексты, автоматизированный анализ текстов |
|
| Keywords: dynamic thesaurus, short texts unstructured, analysis automated analysis of texts |
|
| Количество просмотров: 9676 |
Статья в формате PDF Выпуск в формате PDF (16.33Мб) Скачать обложку в формате PDF (0.33Мб) |
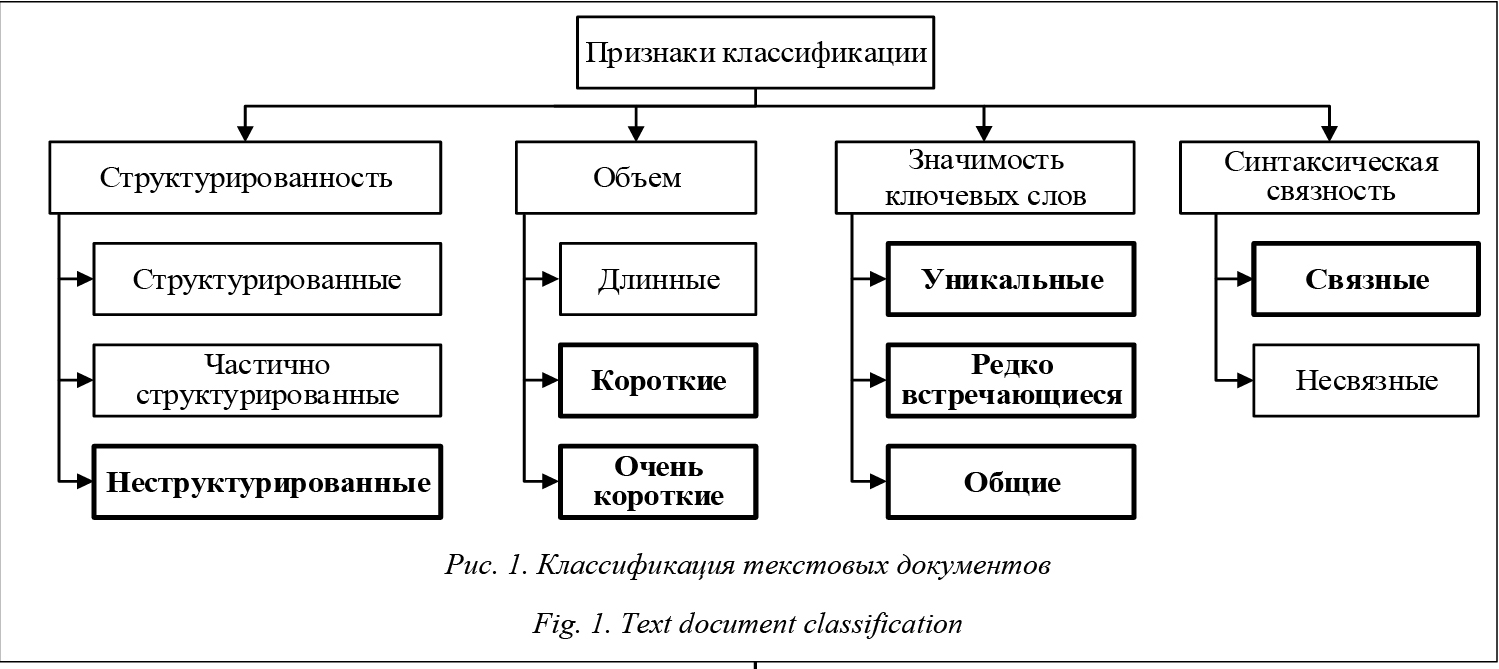
Органы исполнительной и законодательной власти становятся все более открытыми для населения, и это приводит к росту количества заявлений, жалоб и предложений. Значительная часть этих обращений поступают в электронном виде, что обусловливает необходимость их автоматизированной обработки. По каждому обращению необходимо выполнить следующие действия: - принять обращение, определить суть проблемы и специалиста для решения данной проблемы; - отправить обращение конкретному специалисту; - принять некоторые меры по решению указанной проблемы; - написать ответ с отчетом о проделанной работе. Специфика автоматизированных систем обработки текстовых документов такого рода в нестационарности тезауруса ключевых слов, которые с выходом новых правовых документов кардинально изменяются, к тому же поступающие от населения обращения являются неструктурированными и короткими, что затрудняет статистический анализ.
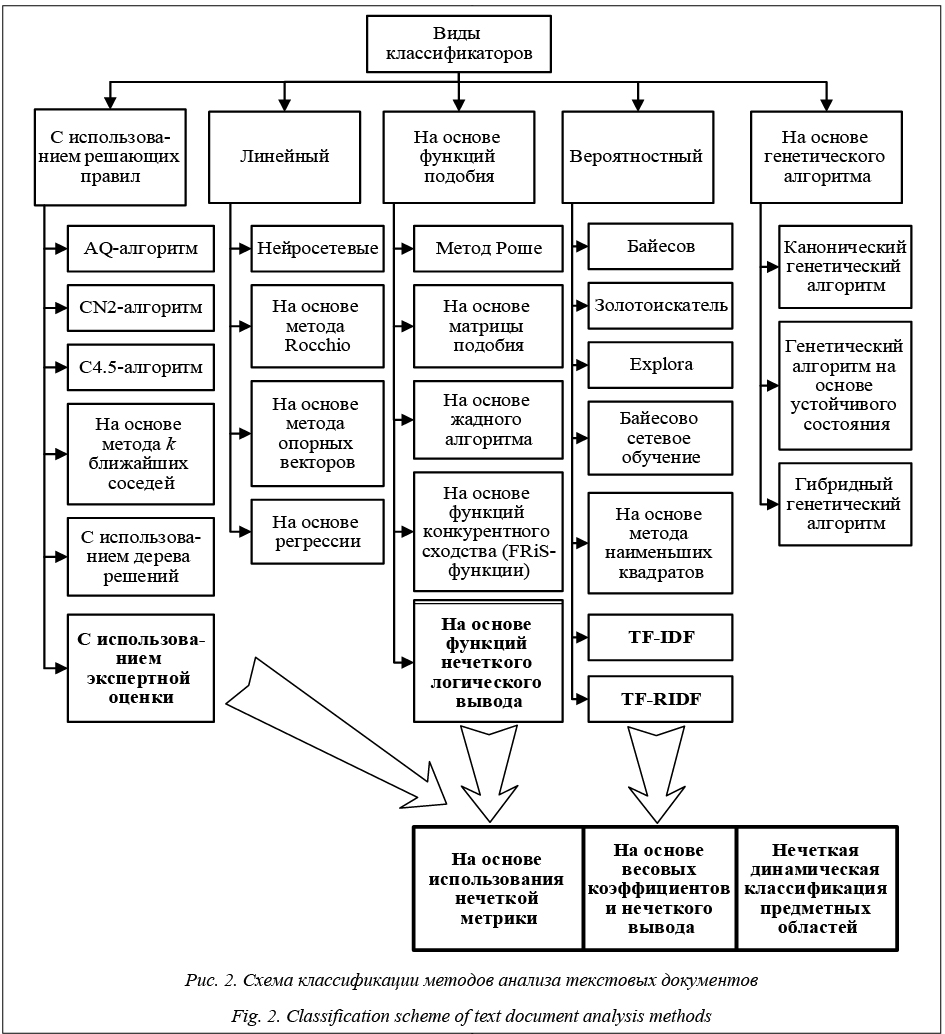
Поступающие в региональную систему обраще- ния граждан обычно относятся к типу неструктурированных, коротких или очень коротких связных текстовых документов. Эти признаки выделены на рисунке 1. Для классификации (кластеризации) текстовых документов разработано большое количество методов и алгоритмов. Рассмотрим возможности и проблемы использования известных методов для анализа документов указанного типа. Из представленных на рисунке 2 типов методов для анализа коротких неструктурированных документов при наличии динамического изменения характеристик рубрик в наибольшей степени подходят методы на основе нейросетей, вероятностные и генетические. В то же время известные варианты данных методов имеют ограничения при автоматизированном анализе обращений граждан: нейросетевые методы достаточно сложны в обучении и связаны с построением большой трудномасштабируемой сети и сложным выбором метрики [6–8]; вероятностные классификаторы на коротких и неструктурированных текстовых документах на естественном языке не дают достаточную точность и эффективность [9–12]; генетические алгоритмы трудно обучаются и тяжело перестраиваются под динами- ческие характеристики тезауруса [13]. В этой связи представляется целесообразным использование их модификаций. Идея разработанного метода на основе весовых коэффициентов состоит в следующем: - каждому слову, соответствующему предметной области, назначается вес; - по умолчанию вес всех слов принимается равным; - проводится обучение метода на некоторой первоначальной выборке документов, в ходе которого веса слов изменяются соответственно их значимости в контексте конкретной предметной области; - проводится корректировка весовых коэффициентов экспертом и на начальном этапе, и в процессе работы системы, так как известна правильность результатов анализа. Чтобы показать модифицированную статистическую часть метода, приведем пример стандартного вероятностного классификатора в виде формулы
где F(dkØ) – максимальная сумма произведения частот употребления слов на количество их употребления в k-м документе, которая определяет предметную область J; fi,j – частота употребления i-го слова в j-й предметной области; ½cik½ – количество употреблений i-го слова в k-м текстовом документе; ½dk½ – количество слов в k-м документе; Pi,j – порог употребления i-го слова в j-й предметной области. Математическую модель разработанного метода автоматической классификации можно представить в виде формулы
где W(dk) – максимальная сумма произведений весовых коэффициентов на количество употреблений в k-м документе (весовой коэффициент, в свою очередь, зависит еще от синтаксического коэффициента важности и актуальности информации); wi,j – весовой коэффициент i-го слова для j-й предметной области; ½ci,k½ – количество употреблений i-го слова в k-м документе; Ki,k – синтаксический коэффициент важности i-го слова в k-м документе (определяется синтаксической значимостью слова в предложении). В документах встречаются слова (общие), которые употребляются почти во всех предметных областях, они не несут информацию о предметной области документа. Следовательно, их веса необходимо сделать намного меньше других. Слова, встречающиеся только в одной предметной области (уникальные), являются самыми значимыми, и их веса будут значительно больше других. Еще остаются редкие слова, которые не являются ни уникальными, ни общими. Они несут некоторую информацию о предметной области, поэтому им назначаются промежуточные значения весовых коэффициентов. Алгоритм обучения проводит анализ БД ключевых слов и разбивает их на три категории: уникальные, редкие и общие. Далее эксперт выбирает нужное соотношение и значение весовых коэффициентов заданных трех типов ключевых слов. Для разграничения редких и общих слов вводится порог встречаемости: если слово встретилось в документах только одной предметной области, то это уникальные слова, если не во всех и меньше порога, то редкие, все остальные слова являются общими. В ходе экспериментов были получены оптимальные значения весовых коэффициентов и порога отбора общеупотребительных слов: вес уникальных слов = 50, редких = 10, общих = 1, а порог отбора общих слов составляет 80 %. При данных характеристиках алгоритма обучения метод показывает наилучшие результаты.
- отсутствие порога частоты употребления слов позволяет распознавать короткие предложения, содержащие большое количество сокращений, цифр и минимум одно ключевое слово; - использование весов, а не частот употребления увеличивает возможности для обучения алгоритма; - при экспертной настройке базы знаний слов предметных областей удобнее работать с весами, чем с частотами и порогами употребления; - возможность использовать слова, не принадлежащие напрямую к предметной области, но приписанные к ней с маленькими весовыми коэффициентами. Недостатки весового алгоритма по сравнению с частотным алгоритмом: - возрастает сложность процесса обучения; - отсутствие порога распознания предложения увеличивает вероятность распознавания документа, который относится к предметной области, неизвестной нашей системе; - появление уникального слова с большим весом в другой предметной области сильно увеличит шанс на ошибочное распознание документа. Проблема динамического тезауруса в разра- ботанном методе решается путем анализа сдвига кластеров предметных областей и своевременного запуска переобучения и подстройки метода. Методы динамической классификации изложены в [14–17]. Нечеткий логический вывод рассмотрен в статьях [18] и [19].
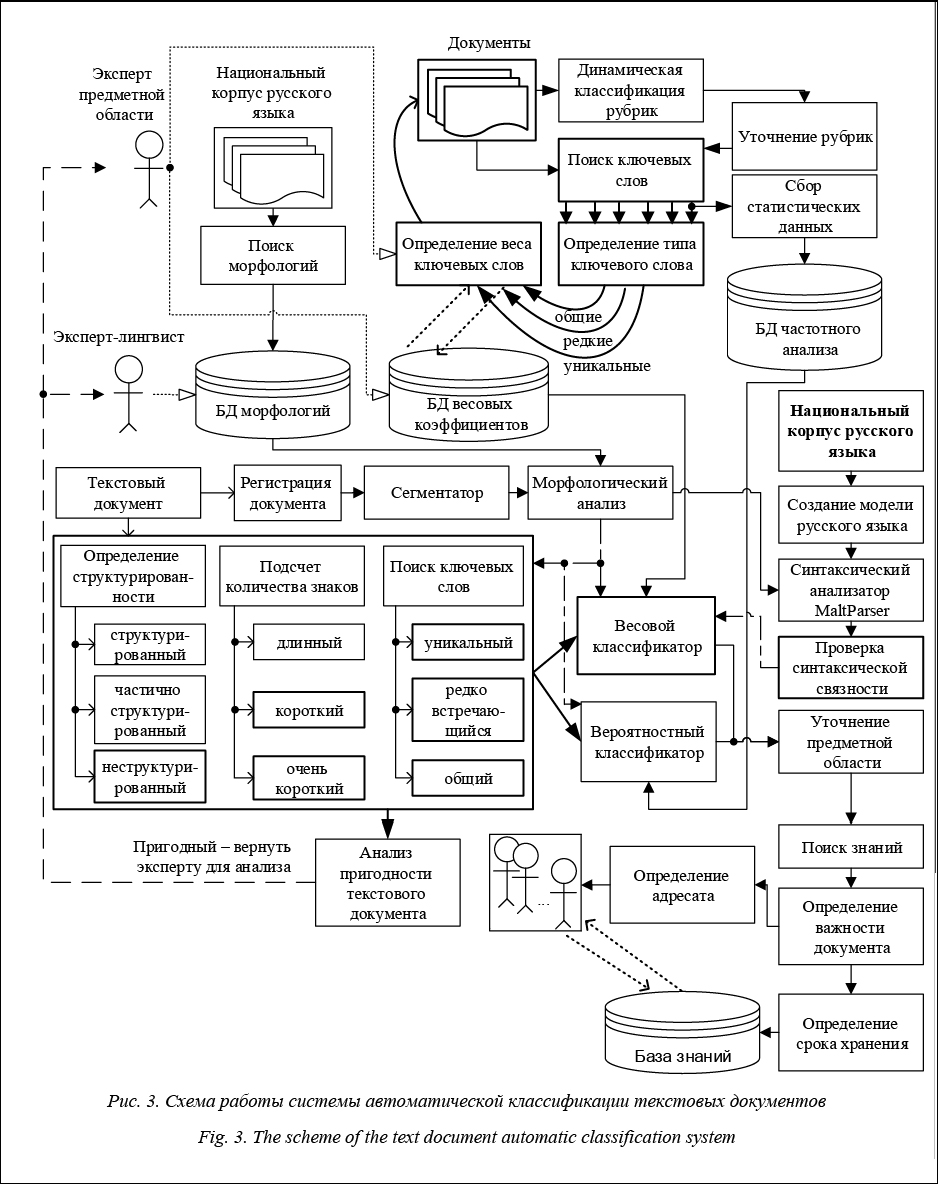
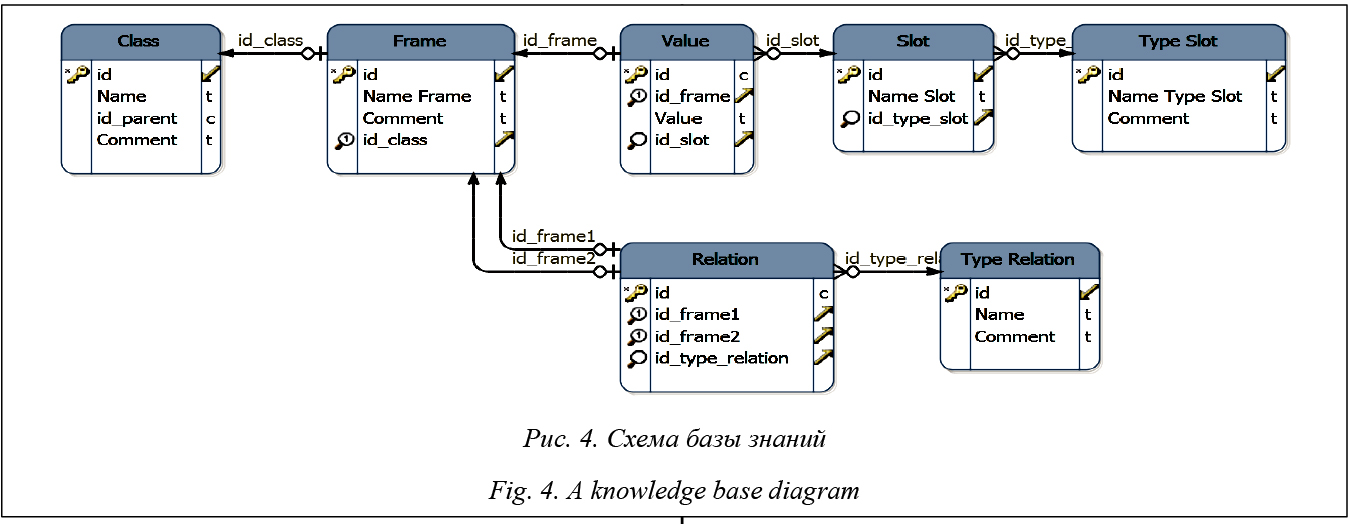
Текстовый документ поступает на вход системы и проходит следующие этапы анализа: регистрация в системе, где получает уникальный номер и озаглавливается необходимыми тэгами для дальнейшей работы; сегментация на слова, предложения, абзацы; морфологический анализ, определяющий лексические характеристики слов и морфемы; классификация документа по трем характеристикам и определение метода его анализа или обозначение документа как непригодного и возврат его экспертам для анализа (если документ короткий или очень короткий и неструктурированный, то используется разработанный метод анализа, в противном случае – вероятностный); уточнение предметной области; синтаксическая разметка документа (для разработанного метода) и проверка синтаксической связности; поиск знаний, определение важности документа и адресата, отправка документа ответственному лицу; сохранение полученных знаний в базу знаний для дальнейшего использования. База знаний реализуется в виде фреймовой реляционной БД, которая хранит извлеченные понятия и отношения между ними. На рисунке 4 представлена схема базы знаний.
Предметная область, к которой принадлежит извлеченный фрейм Frame, представлена в виде сущности Class. Relation описывает отношения между фреймами, а также задает тип отношений. Value предназначен для хранения характеристик фреймов и соотносится со слотами и их типами [20]. В качестве ПО для БД используется MS SQL Server 2008, функционала которого достаточно для реализации поставленных задач. Программирование остальных этапов анализа, за исключением MaltParser, осуществляется на Microsoft Visual C#. Для морфологического анализа предварительно составляется морфологический словарь на Национальном корпусе русского языка. Для поддержания актуальности тезауруса каждый раз происходит динамическое отслеживание рубрик и их уточнение. Основываясь на недостатках разработанного и имеющихся методов, необходимо изменить весь процесс анализа текстовых документов, как предложено на рисунке 3. Весовой метод необходимо применять только при анализе коротких текстовых документов, следовательно, добавляется этап проверки длины текстового документа, который определяет метод анализа: один из известных методов или описанный выше. Литература 1. Батура Т.В., Мурзин Ф.А., Проскуряков А.В. Программный комплекс для анализа данных из социальных сетей // Программные продукты и системы. 2015. № 4. С. 188–197. 2. Schutze H., Hull D.A., Pedersen J.O. A comparison of classiers and document representations for the routing problem. Proc. SIGIR-95, 18th ACM Inter. Conf., Seattle, USA, 1995, pp. 229–237. 3. Ng H.T., Goh W.B., Low K.L. Feature selection, perceptron learning, and a usability case study for text categorization. Proc. SIGIR-97, 20th ACM Intern. Conf. l, Philadelphia, USA, 1997, pp. 67–73. 4. Dagan I., Karov Y., Roth D. Mistake-driven learning in text categorization. Proc. EMNLP-97, 2nd Conf., Providence, USA, 1997, pp. 55–63. 5. Joachims T. Text categorization with support vector machines: learning with many relevant features. Proc. ECML-98, 10th Europ. Conf., Chemnitz, Germany, 1998, pp. 137–142. 6. Lam S.L., Lee D.L. Feature reduction for neural network based text categorization. Proc. DASFAA-99, Taiwan, 1999, pp. 195–202. 7. Ruiz M., Srinivasan P. Hierarchical text categorization using neural networks. Information Retrieval, 2002, vol. 5, no. 1, pp. 87–118. 8. Yang Y., Liu X. A re-examination of text categorization methods. Proc. of SIGIR-99, 22nd ACM Inter. Conf., Berkeley, USA, 1999, pp. 42–49. 9. Козлов П.Ю. Сравнение частотного и весового алгоритмов автоматического анализа документов // Научное обозрение. 2015. № 14. С. 245–250. 10. Lewis D.D. Naive (Bayes) at forty: The independence assumption in information retrieval. Proc. ECML-98, 10th Europ. Conf., Chemnitz, Germany, 1998, p. 415. 11. Heckerman D. A tutorial on learning with bayesian networks. Learning in graphical models, 1999, pp. 301–354. 12. de Campos L.M., Romero A.E. Bayesian network models for hierarchical text classication from a thesaurus. Inter. Jour. of Approximate Reasoning, 2009, vol. 50, no. 7, pp. 932–944. 13. Wong M.L., Cheung K.S. Data mining using grammar based genetic programming and applications. Kluwer Acad. Publ., 2002, 228 p. 14. Гимаров В.А., Дли М.И., Круглов В.В. Задачи распознавания нестационарных образов // Изв. РАН. Теория и системы управления. 2004. № 3. С. 92–96. 15. Гимаров В.А., Дли М.И., Круглов В.В. Временная изменчивость образов // Вестн. МЭИ. 2003. № 2. С. 91–98. 16. Гимаров В.А., Дли М.И., Круглов В.В. Задачи динамической кластеризации // Системы управления и информационные технологии. 2005. Т. 18. № 1. С. 18–21. 17. Гимаров В.А., Дли М.И. Нейросетевой алгоритм классификации сложных объектов // Программные продукты и системы. 2004. № 4. С. 51–55. 18. Круглов В.В., Дли М.И., Голунов Р.Ю. Нечеткая логика и искусственные нейронные сети. М.: Наука. Физматлит, 2001. 224 с. 19. Круглов В.В., Дли М.И. Интеллектуальные информационные системы: компьютерная реализация логического вывода. М.: Физматлит, 2002. 256 с. 20. Хабаров С.П. Представление знаний с применением фреймов. URL: http://www.habarov.spb.ru/bz/bz07.htm (дата обращения: 23.01.2017). |
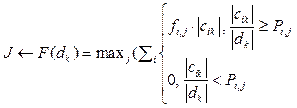 ,
,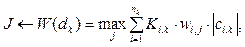
| Постоянный адрес статьи: http://swsys.ru/index.php?id=4253&page=article |
Статья в формате PDF Выпуск в формате PDF (16.33Мб) Скачать обложку в формате PDF (0.33Мб) |
| Статья опубликована в выпуске журнала № 1 за 2017 год. [ на стр. 100-105 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: